AI无法培养出老舍,却能让顶级名师不再是稀缺资源

AI 时代的到来,让传统的教育行业站上了前沿技术应用的风口,国民教育市场这块大蛋糕正被垂涎瓜分。
经历了被称为“在线教育元年”的 2016 年,2017 年在线教育的浪潮依然澎湃。“鲸准数据”显示,2017 年教育领域的融资数量超过 450 起,入场的投资机构近 200 家,其中不乏顶级投资机构:红杉、经纬、华平、GGV、招商局、远翼资本、IDG、鼎晖、云锋基金等。
其中,覆盖时间长、用户规模大(超 1.8 亿)且是刚性需求的 K12(kindergarten through twelfth grade,即幼儿园到高中毕业),是最有爆发力的细分赛道之一。2017 年,K12 领域 AI+ 创业公司的融资堪称数字接力赛,亿级美元的融资层出不穷:学霸君 2017 年 1 月获得 1 亿美元 C 轮融资;猿辅导 5 月获得 1.2 亿美元 E 轮融资;8 月份作业帮获得 1.5 亿美元 C 轮融资;不到一周,VIPKID 就刷新了前者记录,获得 2 亿美元 D 轮融资。
在资本推动的教育 AI 浪潮中,AI 教育技术究竟发展到什么阶段?加上了人工智能的教育,究竟发生了什么变化?就此,我们采访了学霸君首席科学家陈锐锋。
更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
AI 对教育赛道的入侵,基本上是打着“扫除知识盲点”、“实时反馈沟通”以及“因材施教”的大旗。在实际产品中,拍照搜题、在线辅导和 STEAM 教育等是 K12 赛道最常见的落地模式。
目前,贴上“因材施教”等标签的公司很多,操作思路也大同小异:借助 AI 等技术,拆解不同学科的知识点,在较短时间内检测出学生对知识点的掌握程度;在对学生情况充分了解后,进行个性化推荐。不过,从技术角度来说,要实现 K12 学习的个性化匹配并不容易。
想用 AI 来打通某个行业,前提是大量优质数据和强大的计算机能力,教育行业也不例外。个性化的前提,是对学生数据的采集和处理,随后才能进行模型训练,提出解决方案。
收集庞大且高质量的数据并不容易。拿学霸君来说,其收集数据的过程经历了多个阶段。2012 年,公司以拍照搜题技术起家,其移动端拍照搜题 app“学霸君”借助图像识别等技术将学生拍的照片转化为题目,同时,基于此前积累的题库资源,可以为这些题目匹配相应答案。
围绕此前构建的诸多技术壁垒,学霸君拍照搜题 app 为其带来了一定的 C 端流量:9000 万注册用户,超过 100 亿答题搜索,这些都成为其沉淀的重要基础数据。
2016 年 12 月,学霸君推出在线一对一辅导产品“君君辅导”(现已更名学霸君 1 对 1),在此前纯工具性的拍照搜题中加入了教师。“这个阶段的困难在于大规模直播技术的壁垒:在个人对数百万学生的实时答疑中,为了保证某些通用技术差的区域网络能始终不卡、不断,我们需要定义自己的数据格式来有效传输视频、手写笔迹、课件等数据,在网络传输协议上做定制开发等。”陈锐锋称。
相比前两次相对具体的难点和目标,学霸君第三个阶段的目标显得有些抽象:“实现教育公平,让老师教得更好,学生学得更好”。公司为此推出了以“智能笔 + 本 +Pad”套装,结合包含教师端、学生端和题库等在内的“AI 学智慧教育平台”,提供给 B 端(包括学校和机构等)。在这三个阶段,关于公司收集的数据及其背后的技术迭代,陈锐锋在采访中进行了解读:
AI 前线:从拍照搜题、学霸君 1 对 1 到 AI 学教育平台,中间有哪些数据和技术迭代?
陈锐锋:我们早期在做拍照搜题时,题目只要能看懂,有参考价值,基本上就可以了。在一对一阶段,因为是一个老师对一个学生,它的精度也不需要像入校级别的 AI 学教育平台精度那么高。
但到了入校级别、需要布置作业的 AI 学平台,是一个老师对一帮学生,很难像一对一那样针对性地描述疏漏、细节以及相应的不足。所以我们要求入校级别的数据精度要非常高,这对我们的题库提出了很高要求,导致我们早期搜集的题库,不一定能在 B 端里直接用。为了迭代这样的技术,我们在题库的重新加工上,提出了整套的数据生产方案,以保证应用的题库是高度可靠的。这其中综合应用了录入、数据生产以及自动解题中的题目修正等技术,以保证题目的高精度和比较精确的知识点标签。目前我们的核心题库文字正确率要求是达到 99.99%。
AI 前线:目前收集到的是哪些层面的数据?不同阶段的数据来源有哪些不同?
陈锐锋:目前收集到的数据包括内容数据和行为数据。相对内容数据,行为数据更难收集,因为后者必须发生行为才能进行搜集,每次行为的发生成本是很高的。比如说我们要收集写字这个行为,要开发相应的硬件作为数据收集终端。
我们收集时主要有几个渠道。最初,我们有教育机构,这块的积累给我们提供了最基础的题库,通过不断加工这部分数据,我们有了部分内容数据。这其中的加工需要 OCR 技术和人工矫正技术等。有了内容数据后,我们开始收集行为数据,比如在用户问问题的行为中,我们可以了解到他们喜欢问哪些问题;在答疑中,我们可以了解学生怎样问问题,怎么听老师的讲解;另外还有学生的手写数据等。
在学校中,老师在教师 Pad 上布置作业,学生端 Pad 即时显示题目,学生用智能笔在本上作答。这个过程中,结合了摄像头和感压芯片的“智能笔”成为收集学生书写习惯等数据的重要工具,包括学生每天写作业的时间,某道题写了多久,写第几步时有所犹豫等数据都被全面地记录在平台里,系统由此可以判断学生的学习风格,归纳出“学霸”、“中等程度”等学生类型。
通过“智能笔”获得的数据,包括每一笔的力度、从起始点到最后一点握笔到抬笔的时间、过程顺序等。比如,笔不断穿越某个 20 秒前写的字,快速地和其笔划进行交集,这意味着这个字正在被涂改。在书写时有挣扎,反映学生写时不确定,大量涂改意味着他可能不明白。这些特征都可以有逻辑地提取出来。目前 AI 学智慧教育平台已在安徽、广东、福建、西藏、上海、深圳等省市的近百所学校试点,并成功帮助试点班级实现提分。
经过几个阶段的产品落地,目前我们收集到的数据主要包括:早期教育机构积累的题库数据;学生拍照和答疑数据;学生手写行为数据和人工精标性数据。这些数据的背后,是各项技术的“组合拳”:包括“拍照搜题”中的图像和文字识别技术;“学霸君 1 对 1”中的手写识别技术以及“AI 学平台”中的自适应学习体系、个性化推荐等。
AI 前线:对任何 AI 公司来说,精标性数据都非常重要。学霸君在收集精标性数据上是怎么做的?
陈锐锋:我们的精标性数据中,最典型的就是手写数据。学生写的没有成人那么规范,所以通过传统模型,手写数据的精度上不去。
为了解决学生手写中因为涂改、写作不规范等导致的数据精度不足,我们或让成人在数据层中模拟写大量数据,然后对此进行搜集;或在学生手写数据基础上,让成人进行二度标注。这里面有部分自动化,也有人工手写标签。
对标注团队的要求,会因为不同数据而有所不同。如果是标注题目的话,要求标注人必须有教学经验,否则其标注的标签让人不敢确信。如果只是简单标注文字,那标注人只要有基础文化就可以。其他的,要看具体问题。
AI 前线:现在精标注的数据量大概有多少?
陈锐锋:目前我们的精标注数据足够训练我们相应的问题。
AI 前线:目前针对同一学科中的不同科目,数据的收集和模型训练是独立的吗?还是说某些部分可以复用?
陈锐锋:未来应该会有更多复用的技术,但目前这个阶段更多还是把不同的知识点拆开做针对性的处理。比如说几何题和应用题,它所涉及的技术还是相当不一样。尤其是立体几何,它需要图形的解析和重构,这一块在计算题里是不太出现的。不过计算题里的一些符号,背后有一些计算,这些模块在其他地方或也可以用。目前,在解题里,我们更多是根据垂直领域做针对性的调优,但在识别领域则更多是复用以前的一些技术:比如说化学式的识别,实际上可以复用公式识别的一些技术;立体几何或平面几何,在写出来的部分,可以用其他领域的一些识别模型;从印刷体模型到手写体模型,我们可以复用一部分深度学习的模型,再加入能反映手写文字笔画顺序形态的一部分针对性网络。
在陈锐锋看来,应试教育的考试范围和知识点相对固定。这意味着,理论上学生只要掌握了知识点对应的题型,就能拿到较好分数。
但在浩如烟海的题库里,如何找出那些你真正需要写的题目?
此前,选择题目的任务主要落在老师身上。除了将知识框架进行细分,在判断学生水平的基础上,给出适合的练习和指导方案成了老师的核心竞争力。这种判断力是评价老师好坏的重要标准。
不过,在传统教学模式中,老师的这种判断更像是老中医,依靠感觉搭脉,这种主观性导致“老师布置的 2/3 题目可能都是非必要的”。AI 要做的,是让学校在教学进度管理中,用数字化替代感觉。就像“去医院量血压、验血、做 CT 一样,体检结果会清晰地告诉你,对知识掌握了多少,离 985、211 还有多远。”
如何让机器实现这种判断,首先要对学生进行自适应诊断。比如说立体几何课上,老师想出些练习题给学生,首先要了解什么样的题目适合练习以及学生水平如何,随后才能进行推荐。
在陈锐锋看来,传统教学的自适应问题在于:每个学期只有两到三次考试,“评估层级获取的频次太低”。二是学生有了错题后,很难向其提供更深层次能举一反三的类型题。第三,对学生错题的反馈间隔太长。对此,学霸君借助 AI 学智慧教育平台一一解决问题,陈锐锋对具体细节进行了解读。
AI 前线:公司目前最重要的业务版块——AI 学智慧教育平台最初是怎么搭建起来的?它背后的架构是什么样的?
陈锐锋:AI 学智慧教育平台的搭建,最初是从 C 端往 B 端转的时候,在题库技术、识别技术和推荐技术的基础上,做成的一套包括智能笔、平板和部分软件的 B 端产品。它背后的架构,一是数据层,即我们最早从 C 端获得的调优过的数据层;中间是模型层,包括推荐和知识图谱;外化的一层则是全新的界面交互。
AI 前线: AI 学智慧教育平台背后有哪些技术模块?它们分别是如何运作的呢?
陈锐锋:这里面的技术,简单来说,就是数据识别技术和推荐技术。背后的模块主要有两个维度,第一个是考试维度和作业维度,这是学生发生行为的交互场景。第二个维度包括课前、课中和课后。其中,课前有备课系统,我们的技术可以帮助老师准备上课材料,比如帮助老师选题或帮助其准备讲课 PPT。这里面有几个模块,其中之一是选题推荐系统,核心技术包括自然语言及个性化推荐等。
对老师来说,AI 选题系统能在课前帮助其备课,比如有针对性地向其推荐上课内容;在课堂练习中,老师对 PPT 内容进行讲解,如果想多讲几道题,可以在课堂中实时接入我们题库的大数据系统。通过触发推荐系统,获得想讲知识点的相关题目。讲完后,根据学生内容的对错,对第二轮要讲的内容进行调整,让学生做第二轮的练习。第二轮练习是基于第一轮的错误情况筛选出来的。
在课后,系统可以对学生练习内容进行个性化推荐,还能实现实时批改,高效收录错题等。同时,老师可以在后台看到学生学习和作业数据,了解课堂中哪些知识还没被掌握,进行有针对性的讲解和答疑。
对学生而言,在个性化推荐下,每个人打开 Pad 做作业时,作业可能都不相同。上课认真听的学生,正确率很高,作业可能相对较少。错题较多的学生,其系统可能会提示他把某块知识补一补。
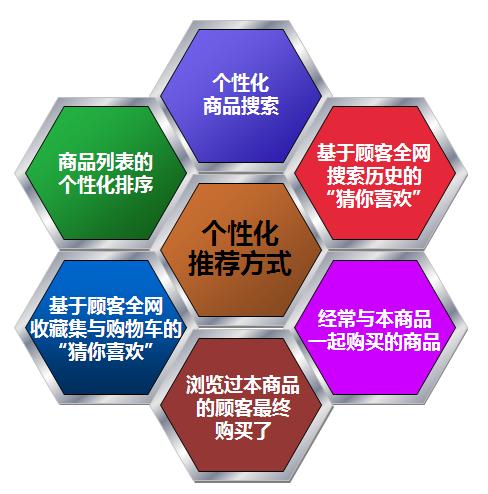
AI 前线:个性化推荐似乎是 AI 学智慧教育平台中非常重要的部分,它背后的算法经历了怎样的迭代?
陈锐锋:总体来说迭代经历了三个阶段。第一是完全脱离行为、只基于内容,且只基于知识点进行推荐。例如,你出一套题,系统只会在这道题的知识点下面,给你推荐同样知识点的题目。它的算法体现在,有大量题目没有知识点,只有一个题干,系统需要根据题干预测一个知识点给他。这个阶段相对比较糙。
第二个阶段还是没有考虑行为,但它会将知识点逻辑相关的考点算法和步骤,一次性地推荐给学生,这个阶段比第一个阶段更深入一点,背后有更深层次的语义和逻辑关联。第三个阶段,系统会把行为关联起来,根据过去的错对题情况,结合条件反应理论和记忆曲线,综合给学生推荐相应题目。
目前我们的算法主要包括三个层级。一是基于回归神经网络的行为预测,基于学生以前做的题目预测未来做题的对错情况。二是条件反应理论,即大量题被做时,系统会对所有题进行难度曲线评估。三是知识图谱,即把所有题目的上下层关联起来。一道题错了,系统不一定会再推荐同样的题目给你,而可能会给你推荐上下沿的知识点。因为有时候学生不是不懂这个知识点,而是前面的知识点就有缺陷,有了知识图谱后,系统就可以更全局地和学生互动。
AI 前线:您曾经说过,自动解题是实现个性化推荐的基础。自动解题背后有哪些技术构成?
陈锐锋:自动解题意味着将题目步骤进行拆解,转换成计算机能理解的形式语言。同时计算机对题目难度进行推理,让不同水平的学生做适合自己的题目。
一道题出现的时候,可能是纯文本,可能带些公式,首先要把它变成机器可以理解和解码的形式语言和描述环境。在此基础上,通过自然语言分析可以抽取出题目的条件和问题,然后基于条件和问题找出最佳解题路径,形成序列。随后,将解题路径翻译成人可以看懂的过程,即最终的解题结果。
基于解题结果和题库原有的答案与学生的作业进行比对,可以判断对错。这些错误被系统记录下来,就形成了不同学生的画像。
AI 前线:人工智能教育的崛起,对传统教育会有什么冲击?会不会让老师失业?
陈锐锋:不会,它会成为老师的帮手。此前,教育的不公平主要是因为教育资源不均衡,我们系统的价值是给每个孩子一个能随时关注其学习情况的机器人老师。在此基础上,真正的老师生产力获得进一步解放,可以将精力更多放到和学生的交流沟通上,对学生真正的知识薄弱点进行专攻等。
机器人可以告诉老师某个知识点有问题,但它是没办法代替老师进行讲解的。当数据汇集到老师那儿,一个优秀的老师会根据数据让学生有针对性地做题、有针对性地听课,而不是盲目地做题和听课。
“通过 AI,不能培养一个老舍,但可以培养出一个写 B 类文的高考学生。”在面向高考的 K12 教育赛道,AI+ 教育的产品研发,目前更多还停留在如何更好地向学生灌输知识,提高学习成绩这些层面上。
在具体应用中,相比人文学科,AI 和理工类学科的结合更加紧密。这一方面是因为理科类数据相对更庞大,“数学问题是学生关注最多的,在所有学科中占比接近 40%。语文虽说大家也关注,但查一个拼音或成语,不一定非要用人工智能。”陈锐锋称,另外,“理科逻辑推演较强、客观题较多,是 AI 很好的测试样本”。
相较而言,因为很多题型没有标准答案,同时过于注重思辨,人文学科在和 AI 的结合上难度更大,但这并不意味着毫无机会。“文科可以拆分,比如说古诗词、错别字等都可以用 AI 来训练;而作文、阅读理解等现阶段较难用 AI 来作自适应训练,但可以用 AI 来推荐参考学习辅助备考。”陈锐锋称。
“比如,考虑到高考作文打分有非常强的加分点和减分点,可以通过手写识别标出加分点和失分点,甚至未来可以实现自动作文打分。如果能做到自动作文打分和老师打分相差不超过 5 分,对学生自我验证作文程度相当有帮助。”据陈锐锋透露,学霸君 2018 年将在文科方向增加发力。
但不管是文科还是理科,对于成绩和应试的强调,始终是目前教育 AI 的关键。这种唯成绩论是否会带来技术异化,让人忽略对其他能力和品德培养的挖掘,成为部分人的担忧。
在陈锐锋看来,AI 的确很难替代需要情感沟通的学习场景。比如父母看着孩子写作业这个场景,或许可以通过监视器进行替代,但其中的感情交流互动完全不可同日而语。这也是 AI 的局限性。
回顾 2017 年,陈锐锋透露,因为现有教育与技术深入结合的可参照成功模板有限,公司在技术和业务上需要探索新路。目前其团队超过 700 人,技术人员超过 300 名,核心的产品研发重点关注教育行为数据的收集、知识库的构建和自适应学习在 B 端和 C 端的应用。
他认为,目前 AI+ 教育已经取得了部分成果,但总的来说仍处于刚开始的阶段。“让机器根据一部分题目的文字的内容提取题目的条件和问题,并给出解题步骤已经有初步效果。但如果要给出更详细的知识点,还需要继续完善和优化深度学习模型。”未来,AI+ 教育可以努力的空间还有很多。

陈锐锋,学霸君首席科学家,新加坡国立大学博士,2013 年入职学霸君,担任技术研究负责人职务,组建智能计算团队,主攻文字识别、图像算法和数据挖掘方向。带领团队在国内率先开创同时适应自然场景、复杂版式图像拍照识别引擎,为搜题及 1V1 实时答疑业务奠定了技术基础。同时,将基于深度学习的文本挖掘技术引入产品,实现高效而智能化的知识导航。

如果您觉得内容优质,记得给我们「留言」和「点赞」,给编辑鼓励一下!
今日荐文
点击下方图片即可阅读

看完文章,想更深入了解人工智能?
“AI 技术内参”将为你系统剖析人工智能核心技术,精讲人工智能国际顶级学术会议核心论文,解读技术发展前沿与最新研究成果,分享数据科学家以及数据科学团队的养成秘笈。

点「阅读原文」,免费试读精品文章。