

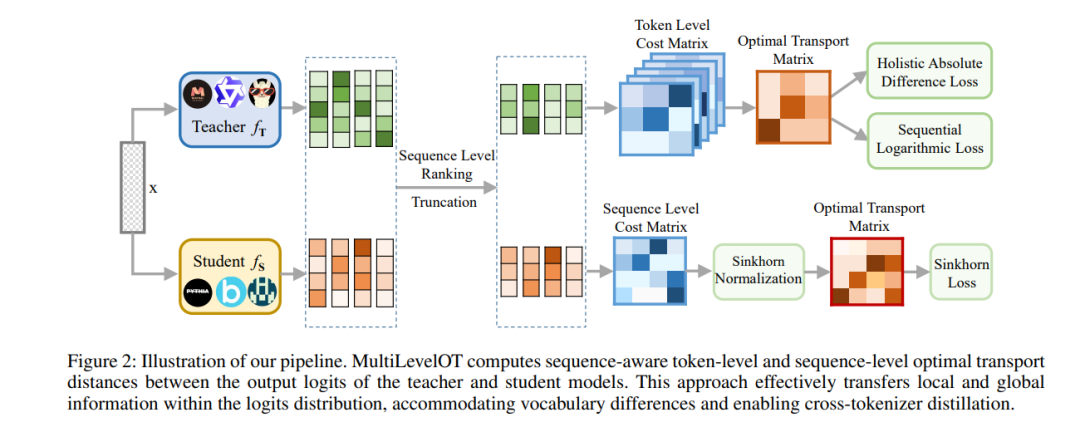
知识蒸馏(KD)已成为压缩大规模语言模型(LLM)的一种流行技术。现有的KD方法受限于教师模型和学生模型之间必须使用相同的标记器(即词汇表),这限制了其在处理不同架构家族的LLM时的通用性。本文提出了多层次最优传输(MultiLevelOT),这是一种新的方法,推进了通用跨标记器知识蒸馏的最优传输技术。我们的方法通过使用多种成本矩阵,在标记级和序列级对教师和学生的logit分布进行对齐,从而消除了维度或逐标记符对应的需求。
在标记级,MultiLevelOT通过联合优化序列中的所有标记,整合了全局和局部信息,从而增强了鲁棒性。在序列级,我们通过Sinkhorn距离高效捕捉logits的复杂分布结构,该距离近似于Wasserstein距离,用于度量分布的散度。通过在抽取式问答、生成式问答和摘要等任务上的大量实验证明,MultiLevelOT在各种设置下优于现有的跨标记器KD方法。我们的 approach 对不同的学生和教师模型在不同的模型家族、架构和参数规模下表现出较强的鲁棒性。
成为VIP会员查看完整内容
相关内容
Arxiv
224+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日