【知识图谱】林钦佑:人工智能的下一个风口——知识计算

林钦佑 微软亚洲研究院首席研究员
就在上周,微软AI讲堂来到了哈尔滨工业大学。微软亚洲研究院首席研究员林钦佑博士在此次分享中深入浅出地带来知识计算方向的满满干货。今天就让我们回顾一下林钦佑博士的演讲——人工智能的下一个风口:知识计算,来了解什么是知识计算,以及知识计算将如何帮助实现智能未来。
演讲全文如下(文字内容略有精简)
很高兴回到哈工大,今天跟各位分享一下微软研究院在人工智能所做的方向,以及未来大家可以准备朝哪个方向发展。
人工智能不是过去两三年才发生的事情,事实上,在1960年就有很多人工智能的发展。首先我想用很短的一个时间轴跟大家一起来看看最近这几年的发展。
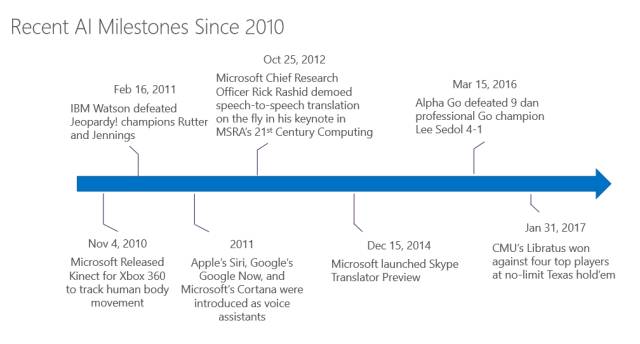
2010年,微软XBox推出了Kinect,那个时候大家觉得计算机真的很了不起,能看到人的动作,并把动作融入到游戏里面。这是第一次工业界的产品能够实时追踪每个人的关节、动作,是一个很大的突破,就好像机器有眼睛,可以看到人是怎么做动作的一样。
2011年,IBM Watson在美国的Jeoparody!秀里做猜谜游戏时击败了Ken Jennings和Brad Rutter。2012年,微软研究院的创始人Rick Rashid在天津举办的“二十一世纪的计算”学术大会上展示了实时语音翻译技术,造成了很大的震撼。
到了2014年,微软把这个实时语音翻译技术运用到了Skype Translator里。不管是iOS系统、安卓系统还是Window系统,你都可以下载安装Skype,并使用Skype Translator实时语音翻译技术。
接下来2016年不用多讲了,AlphaGo在围棋比赛中战胜了李世石。今年5月AlphaGo还会再战一场。而在2017年1月,CMU的一个团队写了一个AI程序,赢了德州扑克。所以可以想象接下来几年,我们可能要经常遭受类似的打击——机器赢过人的某项技能。因此,我想利用这个机会跟各位解释一下,今天AI到底做到了什么程度,还有哪些方面可以做研究的。

人工智能在1960年左右就已经开始了,那为什么在过去这几年人工智能这个洪流又开始爆发了呢?主要有几项:
第一,有很大的数据。大家现在用手机传短信、在微信上和朋友聊天、搜索内容等等,这里面所有的数据都会被记录下来,从而使得我们有很大的数据。当有了很多你跟同学、朋友交互的过程,或者即使不看你和朋友间的聊天记录,也可以在网上、微博上看到你发表的内容。而这些数据就可以让机器看到人在对话的时候,可以讲什么,会讲什么。
所以,因为有大数据的关系,现在的机器可以把有些很难的事情变得简单。因为机器知道你以前在什么场合下讲过什么话。
第二,云计算。现在大家都希望手机有超大的内存,比如64G、128G的。以前我在学校刚刚念书的时候,一个机器只要有2MB,我就已经很高兴了,但是现在手机和它的计算能力实际上比20年前电脑的计算能力还要强。所以,有了大数据之后,又有了很多的计算能力,很大的储存能力。
二三十年前,架一个网站,我们还需要去想要买什么样的PC机,要装什么操作系统,可能还要租一条线,再设计个网页,然后上线。而现在不用了,你可以用微软的Azure云或者用亚马逊的云系统,只要一上线你就可以有自己的网站。因为是云计算,所以每个人都可以通过各种不同的终端设备看到自己的数据。
第三,算法。有了这些数据和存储能力的时候,我们就要有一些算法。过去几年,在计算机领域,大家会经常听到深度学习。深度学习的前身其实在1960年就已经有了,但是当时它叫做神经网络。现在因为神经网络做深了,计算能力提高了,数据增多了,才让深度学习有了它可以发展、发挥、发力的机会。
所以,这几个关键技术结合在一起,促使了现在AI的爆发。

在微软,我们的AI技术有四个方向,我们看看,微软在这四方面都做了哪些事情。
第一,让机器能看得到。视觉方面,我们在2015年做了一个152层的深层神经网络,它能够在像素级别上知道一张图上有一只蜘蛛。甚至在有些医学上的应用,比如判断切片影像中是否有癌细胞,最新的消息是机器判断的正确率已经比医生更高了。
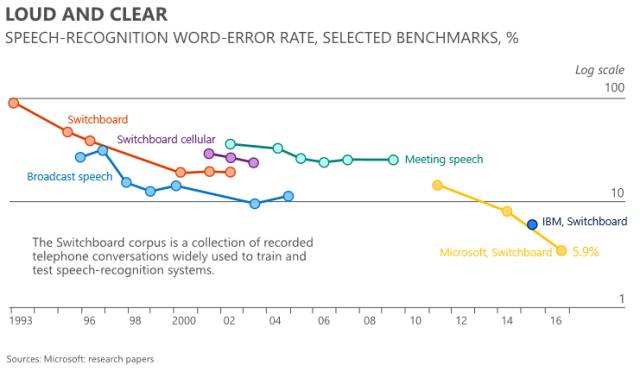
第二,让机器能够听。学术界在评价技术的进步与否时都有一个标准的测试集。看看下图的这些线,每个点都是一个语音识别测试数据的结果,线越往下就表示做得越好,错误率低。可以看到最右边的这条线,微软去年做的错误率在5.9%左右,5.9%已经达到了人类水平。
第三个是语言,机器还要能读。在语言方面微软亚洲研究院也一直都有深入的研究,让机器可以更好的阅读、理解文字内容,并且我们在这方面也取得了十分优异的成绩。未来会与大家有更多的分享。
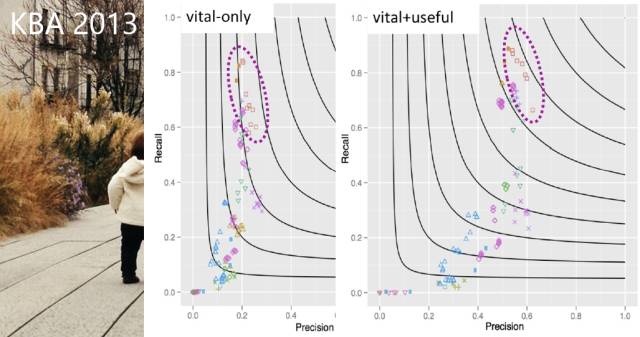
最后,机器要能够对答如流,要有知识。知识方面有一个测试叫做Knowledge Base Acceleration(KBA)。为什么我们说做一个像人一样的人工智能比较难?先举个例子,今天我讲了一些有关AI的内容,有些东西你可能知道,有些东西你可能不知道,但是你今天听到的一些之前不知道的事情,明天你就应该知道了。也就是说,人是有学习能力的。
机器有没有学习能力呢?机器可以识别人脸,但是人要先告诉机器说这是我,学习了之后它才能找到图片里哪个是我。现在还没有一种人脸识别的算法可以识别它没看过的人。所以在做KBA的时候就是假如给出一个百科,让机器每天读新闻,当它知道这个新闻是有关哈工大的之后,就把报道哈工大的这个新的新闻中的新知识抽取出来放在哈工大的网页上,这个测试就是类似这样的一个实验。
我们在2013年的时候就做到了最好的效果。我们的系统可以找到vital(最重要而且相关)的信息,就是说机器找到的新闻确实是非常相关的而且有必要记录的。比如,微软买了某个公司,这个跟微软是非常相关,但是,某个人买了微软的某个产品,也是跟微软相关的,但是普通人买其实没那么重要,但如果是哈工大买微软的某个产品那就很重要了,这也是vital和useful的差别。
所以,大家可以看到微软在刚才讲的,会看、会听、会读、有知识这四个前沿领域都做了很多的研究、开发。
接下来跟大家做一个数学题——“There are 20 horses and chickens at Old Macdonald's farm. Together there are 58 legs. How many horses and how many chickens?”。这个问题很简单,大家小学的时候就会做了。但要让机器来解这个问题就没有那么简单了。为什么呢?
因为计算机不知道马有几只脚,鸡有几只脚。即使知道,它还要知道Macdonald's farm和解决问题一点关系都没有。另外,解决这个问题还要有数学知识,考的就是加减乘除。
我们可以看出,计算机要有语言理解能力才可能和人沟通。计算机要怎么解题呢?首先必须要了解语言,不管是英文还是中文。再就是要有知识,即使能理解所有的东西,它还要知道脚和鸡的关系,鸡和马的关系,以及农场这个信息跟解题一点关系都没有等等。第三,是知道这些东西之后,还要能计算。如果所有内容都知道了,但是不知道怎么算,那也不行。对于一个物理题,要有物理的计算能力,对于统计题,要有统计的计算能力。
所以,我们现在还是有很多问题没有解决的。比如,机器怎么能够知道所有的知识呢?今天要解这个题,我们把鸡和马几只脚的知识放进去。明天改成蛇,就要把蛇没有脚加进去。如果再改成螃蟹,就要把螃蟹有八只脚加进去等等。这样的工作量就会十分巨大,每讲一个东西都要加进去新的信息,这是不可能的。所以这时候就有一个问题了,如何很快速地累积知识?
总结一下我们刚刚讲的这个问题。
首先,要有自然语言的能力,要有知识,机器要学习。要考虑如何让机器可以很快地有一个学习的算法来了解语言中的信息。
其次,人和机器要结合在一起。微软在讲到AI时都会强调一个概念——Artificial Intelligence(人工智能)+ Human Intelligence(人类智能)= Super Intelligence(超级智能)。在此我要强调的一点就是,人在这样一个成功的环路里是不可或缺的。
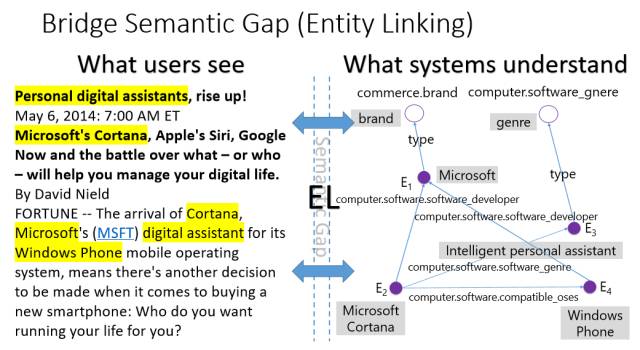
第三,机器要有知识。机器解这个数学题的时候需要哪些能力呢?上图的左边是一篇文章,它讲到了个人助理。机器要了解这件事,首先要知道什么是个人助理。然后,机器需要有一个表达的方法,这就是知识了。在知识方面,比如文章里讲到微软,那么机器要知道微软是什么,微软跟它的产品的关系是什么。
所以,机器跟人之间的沟通或者是机器要去了解这个世界的时候,它有一个语义的鸿沟。我们还有个技术叫实体链接,比如文章里有“微软的Cortana”,这个短语里包括了两个实体,一个是微软,一个是Cortana。以前在做自然语言处理的时候,我们说这是一个名词词组,不需要了解里面讲的是微软还是什么,它就是个专有名词,Cortana也是一个专有名词。但人理解的时候,我们不是只知道它是什么词性的,我们知道微软是代表一个公司,Cortana是微软公司的一个产品。
所以说真正要进入到AI时代,机器必须要有语义的理解,而且要知道为什么用这个东西来代表某个事情。我们微软知识计算组的任务就是,我们怎么能够为这个世界服务,通过什么手段让机器可以自动理解知识,通过对数据的挖掘来增进我们的知识。我们希望机器以后能帮人们干更多的活。
自然语言中有一些问题对计算机来说很麻烦,比如,当我通过语音让智能手机给潘副院长打电话,但通讯录里只写了潘天佑博士,那么机器就无法执行这个操作。再比如重名问题,再比如当说到我来自中国的时候,机器要知道这个中国指的就是中华人民共和国等等类似的问题。事实上机器要理解语言,要有知识,这个方面还是非常宽阔的。
第一,理解知识。我们必须要知道怎么建这个包含巨大知识的数据库,机器怎么才能知道这么多不同的东西。今天有iPhone 8,明天就有iPhone 9了,机器的知识要一直不断增加,这对人类来说没有问题。当别人说iPhone 8要出来了,你就会想什么时候出更新一代的iPhone,你会自己推理。
第二,机器必须要有一定的推理能力。这个推理的能力也包括一部分知识,不是只知道事实。比如,地上有水,那就一定下过雨吗?不一定。但是,天下雨地上一定有水。所以要考虑怎么把这类知识放到机器里面去理解这个内容。
我们从哪些地方取得这些知识呢?就是从非结构性的数据中,比如新闻、文件,还有从结构性的数据中,如个人数据库、公司、学校里的一些内容,像每天选课的课表都是结构化的数据,这些都可以综合起来使用。除此之外当然还可以让人直接给机器添加知识。
第三,算法。有了知识和理解能力后,我们要做一些算法,把这些数据结合、清理、连接起来,提供服务给上层的应用。
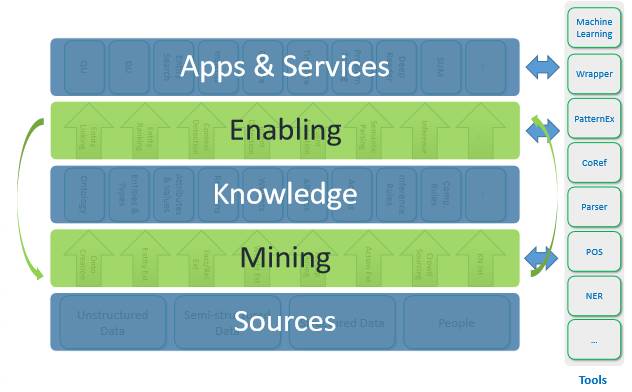
经过来源之后,我们会做挖掘的工作,做处理。然后把获得的内容存在知识库里,然后知识库就能应用到不同的场景中了。
我们还有什么挑战呢?
第一个,机器什么时候可以真正的理解?所谓的理解不是说只把它变成一个语法树,而是真正能够知道我们讲的是什么东西。
第二个,如何解决问题?理解语言没问题,但你要怎么解决问题呢,解决问题的知识去哪里获得?我们不能靠百科网页,因为这些百科网页不能解决所有的事情。所以,我们要怎么获取这样的知识?
第三个,怎么让机器有永久学习的能力?人每天看一些书本,听一些演讲,看一些视频,可以自己教育自己,机器可不可以做到这些?
最后总结一下,我们要机器能看、能听、能说、能写、能学习、有知识,就需要自然语言的处理能力。并且,我们不只是可以做中文、英文,我们要做各种不同的语言。在这个领域,未来的工作机会有太多太多。希望大家在生活和学习中多思考,用自己的创新想法解决人工智能的核心问题。
谢谢!

不懂知识图谱的你,正在失去转行做AI产品经理的机会
人人都是产品经理
伴随着AI这块新的投资风口,新兴企业对AI人才的需求也是激增。所以,你准备好了么?

一、AI来了,你被OUT了,有人却已在快车道上了
给你讲个恐怖的故事:我今年,32岁了!三十岁左右是一生中最焦虑的年纪。在大城市打拼的我们,每天在瞬息万变的互联网行业里累成翔;为了保住饭碗付每月的房贷或者房租,回家还要拼命学习成长,想怎么和有想法且已经创业几次的95后比更有市场竞争力;活在青春尾巴的我们,看着自己开始发福的身体不断问自己:会像李世石那样被阿尔法狗打败那样,被超人类的AI取代吗?
看另一批已借助AI先行出发、领跑时代的30岁产品经理们。85后的黄钊,既是较早的一批互联网产品经理(08年开始),又是最早的AI 产品经理(12年开始); 既受到过最正规的互联网PM培训熏陶(腾讯),又在AI PM的行业探索前行(图灵机器人 );现在已经华丽转身为AI第一梯队、未来独角兽——图灵机器人的VP了。逆袭之路正在逐渐收窄,弯道超车的赛道开始闭合,只剩眼前这条路。那作为传统信息流产品经理的你,又能从哪个切入点找到转行AI产品经理的机会呢?
二、这个时代的焦虑,终需要用这个时代的技术解决
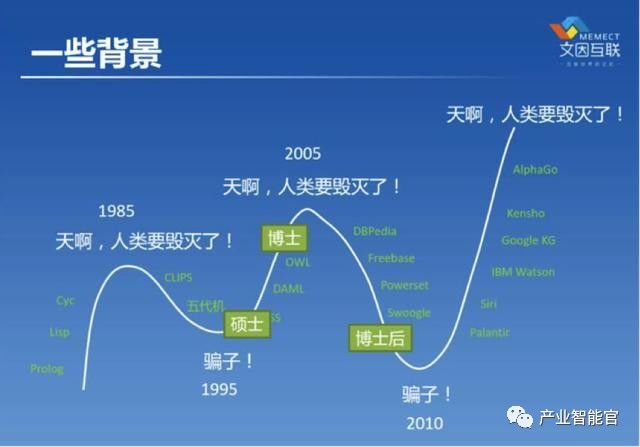
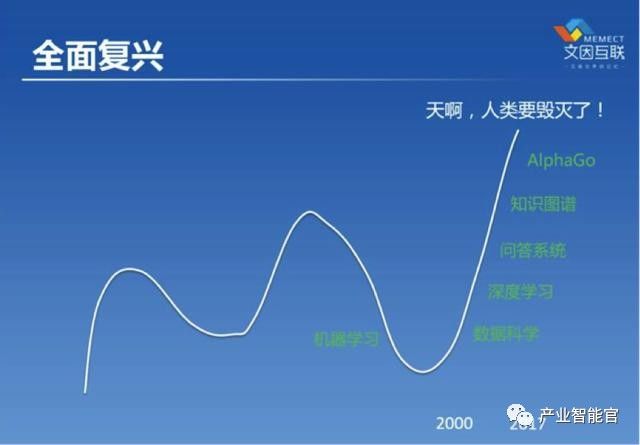
鲍捷老师的《人工智能的钟摆》中介绍到AI过去30年的八卦史,每一次轮回就像一次次的雪崩,起点是坚实的技术发展基础,暗流涌动的媒体煽动又一次次将其 推向深渊。用王菲的歌来描述就是:一个一个概念都不过如此,沉迷过的概念一个个消失。但是,最近一次AI又借助AplhaGo 而名声大噪。 人工智能的底层是海量大数据碎片化散落在世界角落,通过借助于云计算极低的计算成本和极强的计算能力,进而输出人工智能所需的各种结构化数据。在这之上是AI人工智能领域的范畴,包括:机器学习、深度学习、自然语言处理和知识图谱。
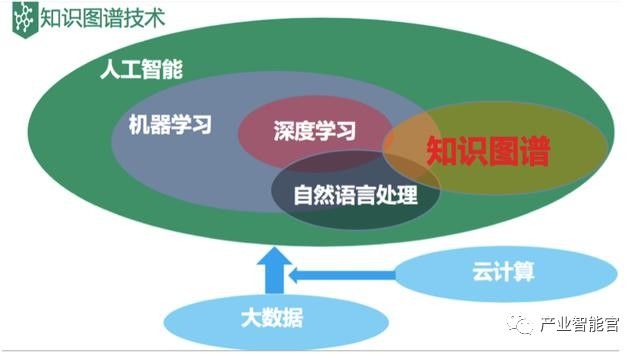
看到上面的图是不是感觉:知识图谱不就是人工智能的一个不起眼的小弟,同时还被机器学习、深度学习和自然语言处理各位更有名气大哥的挤到角落里的受气包吗?其实知识图谱是人工智能运筹帷幄之中的幕后英雄。
三、知识图谱又是什么鬼?
在一个快速迭代的行业里面,如果你看的只有大家都在热议的东西是做不了大事的。知识图谱最能体现人工智能的特色——像人类大脑一样思考!人类最擅长的思考方式就是将点和线关联起来并由点及面,然后抽丝剥茧,慢慢理清其中的逻辑推理关系。
福尔摩斯作者有一句名言:
“一个逻辑学家,不需要亲眼见过,或听过大西洋和尼亚加拉大瀑布,他从一滴水中就能推测出它们。”
知识图谱就像福尔摩斯破案一样,首先需要采集散布在各个角落的碎片化信息和数据,然后把它按标准化思考方式整理,再将各个看似不相关但背后有着共同联系的 信息关联起来,并挖掘背后的规律,据此做深入的推理,最后激昂的背景音乐就此响起,智慧的福尔摩斯搬出最致命的证据,凶手的脸一阵抽搐……
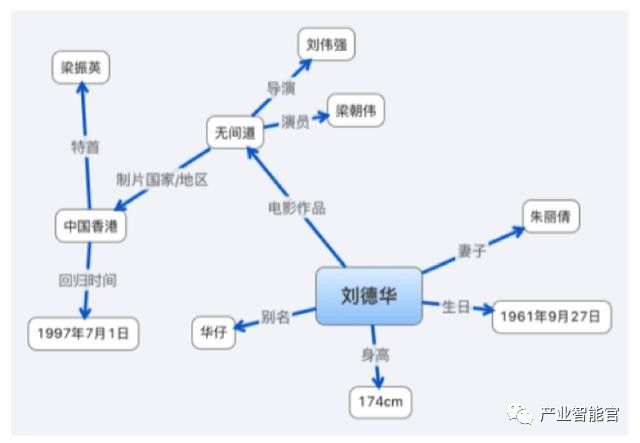
知识图谱又可以从数据角度和技术角度来看。以数据方面为例,它就是一个语义的知识库,里面的组成单位是“实体—属性—关系”这样的三元组,各个组聚合在一起 就构成了复杂的网状知识结构。比如“刘德华”周围有很多关系:他的别名、身高、生日、妻子以及电影作品,他演的《无间道》又包含了相关的导演、演员以及制 片地区香港等。所以知识图谱能非常直观的表达对象与对象之间的关系。世间万物是一个错综复杂的关系网,但是无论形式上多么复杂,其实本质上都是简单的三元 组。
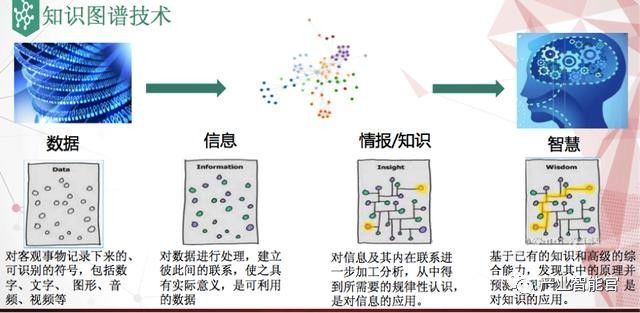
以技术方面为例,知识图谱是从数据、情报到知识,最后再到智慧的过程。
首先是分布式数据采集,这里面既会涉及到外部海量在线数据(像新闻,公司披露等信 息),也会有内部业务数据。并且需要把采集来的数据像刚从果园采回的鲜果一样做彻底的清洗,然后输出干净的基础数据。
下一步需要对其做语义处理,因为新闻 本身可能也含有广告,所以需要通过自然语言处理识别新闻中到底谈到哪个公司,或者哪位高管,又或者提到公司的什么大事,比如中了什么标,可能会对业绩有较 大的影响。
做完语义处理之后,输出结构化标准数据,然后将行业专家的知识融合进来去建模,从而构建出各个行业的知识库。
在这个基础上,就可以做上层决策支持系统,通过更加简易的人机交互来访问这些底层的知识图谱。
比如你向同花顺i问财 提问“同花顺可以买吗?”,它首先需要理解你要问的是什么:意图是同花顺这个公司,实体是怎么样,要不要买;然后把它转化到庞大的底层知识图谱中去做搜 索,最后返回给你想要的结果,比如同类型的事件当时同花顺股票涨跌的概率等。
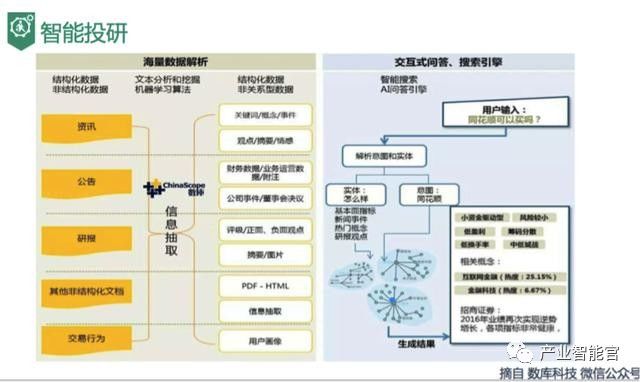
四、人工智能的“神奇魔杖”
你现在对知识图谱有了大致了解,那我们再以通联数据萝卜投研揭秘猪肉价格上涨背后的产业链投资机会,来看看这个类似哈利波特手中的“神奇魔杖”到底已经如何 运用到金融科技的前沿领域中了。 在2015年7月,萝卜投研的数据监控系统对猪肉价格发出异动提醒,这时我们注意到猪肉价格自4月以来,已连续上涨超过 20% 。
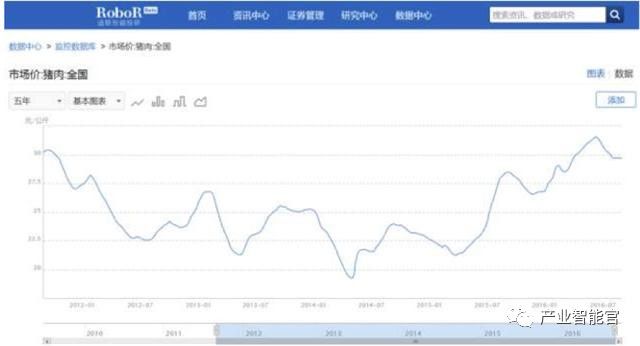
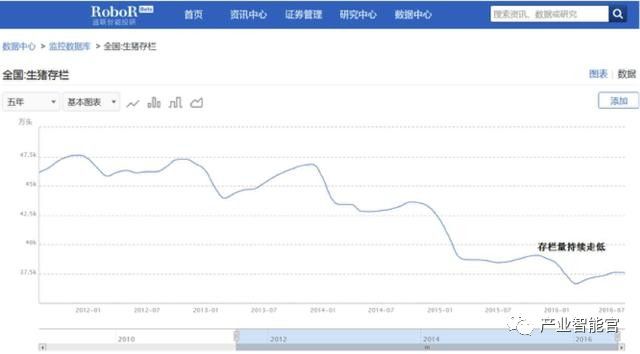
进一步结合供需关系来分析猪肉价格上涨的原因,可以发现相比猪肉价格不断上涨的同时,而生猪存栏量却在持续走低,养殖行业并未进行补栏。
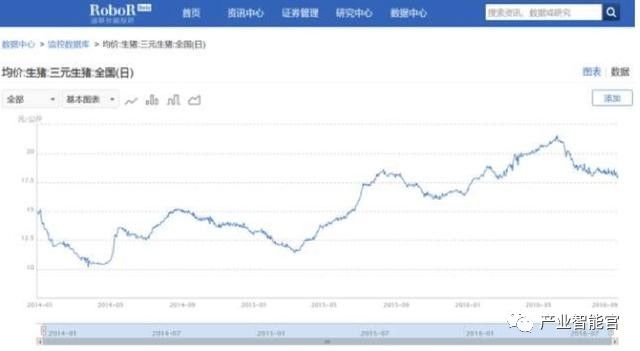
在系统推荐的关联数据中, 仔猪价格仍旧表现平稳,因此可以预测,如果猪肉价格继续上涨,养殖者一定会跟风养猪,仔猪需求量就会上升,随之而来的就是仔猪价格的上涨。
如预测的那样,随后仔猪价格大幅飙升。
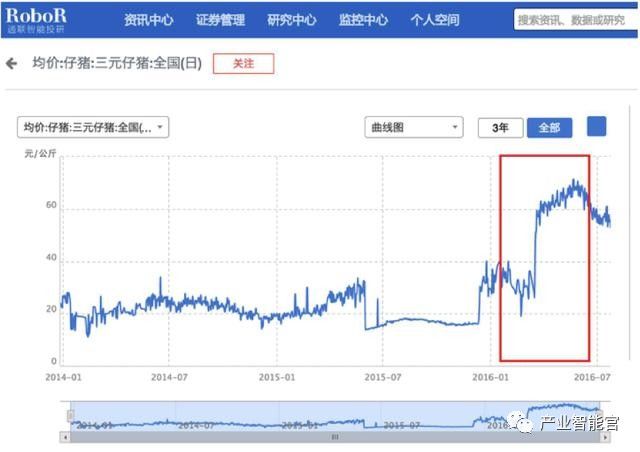
此时是投资生猪繁育行业的大好机会,那么仔猪价格的上涨是否也影响到了其上下游产业?更多潜在的投资机会也许就埋在这些关系链中。
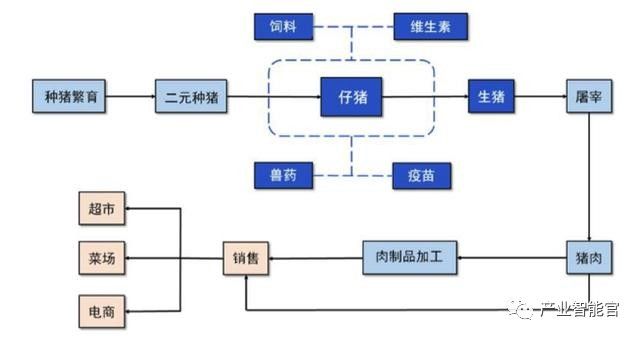
于是利用萝卜投研的知识图谱,首先挖掘出了仔猪的上游产业——从饲料、疫苗再到维生素,这些都存在着不错的投资价值。
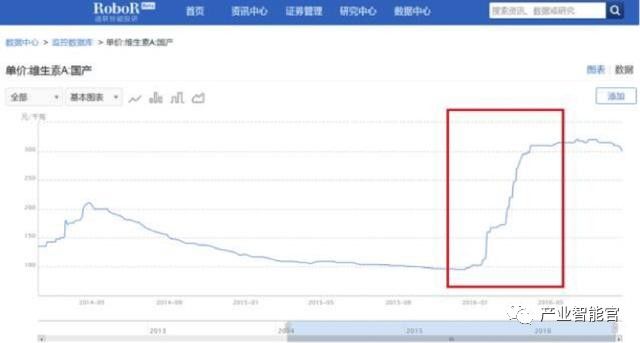
以维生素为例,在包括仔猪养殖量上涨等多种因素的叠加下,各类维生素价格出现了大幅度的飙升;这为主营维生素的企业提供了有力的业绩支撑。
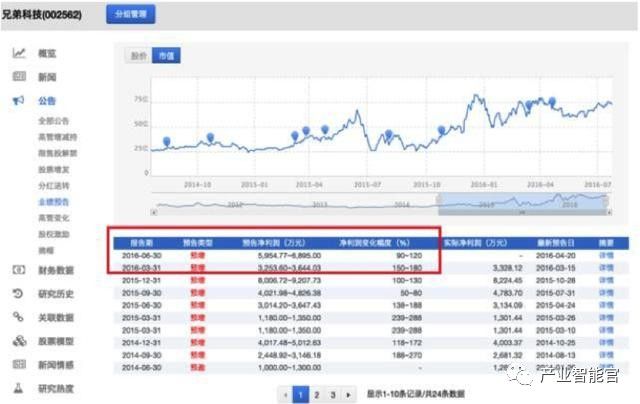
回到知识图谱对产业下游进行观察,可以预估,到了2016年底,当这批生猪出栏之后,猪肉的屠宰业将引来业绩大爆发,这又利好相关上市公司。
可见,如果能拥借助知识图谱这个“神奇魔杖”,即使不是专业的农业分析师,也能试着从猪肉价格变化挖掘出整个生猪产业链里的投资机会。
不 过,就算让华尔街人人自危的智能投研Kensho也达不到其宣称的那样:你问的问题它都懂。但是,这也正是AI产品经理与信息类产品经理思路不同之处:比 如智能问答,没有太多UI界面设计,而是需要知道底层技术边界是什么,现在能做什么,以后能做什么,理解这套逻辑之后设计出来的产品才能不断去自我演化。 像kensho不能回答的问题,就会搜集起来,自己去演化,通过和人的交互逐步把人想了解的知识、问的问题,集成到系统里面,让底层的知识图谱逐渐去匹配 完善。这也就是为什么AI系统与传统信息系统不一样,它可能更多是搜集人机交互、外部信息,形成闭环,从而使自己像奋进不停的学习者一样不断成长演化。
五、机会之门正为你打开
伴随着AI这块新的投资风口,新兴企业对AI人才的需求也是激增。据LinkedIn的报告显示:过去三年间,通过领英平台发布的AI职位数量从2014年 的5万飙升至2016年的44万,增长近8倍。截至2017年一季度,基于领英平台的全球AI领域技术人才数量超过190万,其中美国相关人才总数超过 85万,高居榜首,而中国的相关人总数也才5万人,缺口极大。
很多人讲没机会进入AI领域,其实你有没有想过,我们每一天都是做选择。比如,你开一个会,你在会上表现的沉默还是表现积极,方案给的是偏保守还是很激进,工作里的每一步,都是选择。选择会累积变成机会,机会最终会引发质变。机会来自量的积累,机会不是说来就来的。新岗位永远有缺口,这就需要你争分夺秒地去适应,去学习,去抢工作。 AI已来,未来不远!
特别感谢北京知识图谱科技有限公司吴刚老师的无条件支持才能完成此篇文章!
知识图谱数据管理浅讲
来源:邹磊 数据简化DataSimp
作者:邹磊,北京大学副教授、国家优青基金获得者。2003年和2009年毕业于华中科技大学计算机科学与技术学院,获工学学士和博士学位。2009年7月入职北京大学计算机科学技术研究所,任讲师;并于2012年8月晋升为副教授。目前研究方向“海量图数据的管理”和“基于图的RDF知识库数据管理”等,代表性论文网址http://www.icst.pku.edu.cn/intro/leizou/cn/index.html。北京大学“北京大数据研究院BIBDR”邹磊原创首发《浅谈知识图谱数据管理》授权转载。

近年随着“人工智能”概念的再度活跃,除了“深度学习”这个炙手可热的名词以外,“知识图谱”无疑也是研究者、工业界和投资人心目中的又一颗“银弹”。简单地说,“知识图谱”就是以图形(Graph)的方式来展现“实体”、实体“属性”,以及实体之间的“关系”。下图是截取Google知识图谱介绍网页中的一个例子。例子中有4个实体,分别是“达芬奇”,“意大利”,“蒙拉丽莎”和“米可朗基罗”。这个图明确地展示了“达芬奇”的逐个属性和属性值(例如名字、生日和逝世时间等),以及之间的关系(例如蒙拉丽莎是达芬奇的画作,达芬奇出生在意大利等)。当我谈论到这时,我相信有很多读者会不经意地联系到数据库课程中的“ER Diagram”(实体-联系图)的概念。从某种角度的来说,两者确实是有异曲同工之处。根据传统数据库理论,当我们将现实世界的事物映射到信息世界时,最需要关注的是两个方面的信息:实体(包括实体属性)和实体关系;而ER图是反映实体和实体关系的最为经典的概念模型。我们之所以称ER图是概念模型,因为它的设计是为人去理解客观世界的事物的,不是计算机实现的模型。在数据库管理系统历史上,出现过层次模型、网状模型和关系模型;这些是数据库管理系统(DBMS)所实现的计算机模型。因此实际的数据库应用项目中就存在了一个从概念模型到实现模型的转换问题,例如如何根据ER图来构建关系表。如果从这个角度上来看,知识图谱又不同于ER图,因为知识图谱不仅显示地刻画了实体和实体关系,而且其本身也定义了一种计算机所实现的数据模型(即W3C所提出的RDF三元组数据模型),这就是本文第一章介绍的内容。由于本文作者的研究背景是数据库,因此本文试图从数据管理的角度去介绍知识图谱的相关概论以及研究和应用中的问题。同时因为知识图谱本身是一个交叉性研究课题,本文也将介绍不同学科(包括自然语言处理、知识工程和机器学习等领域)在知识图谱研究中的侧重。
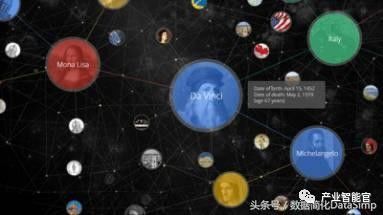
图0 Google的知识图谱示例
本文首先在第一章介绍知识图谱的数据模型;第二章重点介绍知识图谱在工业界的几个成果案例;第三章重点讨论面向海量知识图谱的数据管理问题,第四章是总览不同学科在知识图谱研究中的侧重,第五章总结全文。
1、知识图谱的数据模型
“知识图谱”这个名词活跃是由于2012年5月16日Google启动的“Knowledge Graph”(知识图谱)项目。目前知识图谱普遍采用了语义网框架中RDF(Resource Description Framework,资源模式框架)模型来表示数据。语义网是万维网之父蒂姆·伯纳斯-李(Tim Berners-Lee)在1998年提出的概念,其核心是构建以数据为中心的网络,即Web of Data;这是相对于我们目前的万维网是Web of Pages而提出的。众所周知,万维网是利用超链接技术将不同的文档链接起来,从而方便用户的浏览和文档的共享。HTML文档的语法在于告诉浏览器按照何种格式来显示该文档,而并不是告诉计算机文档中的数据分别表示什么语义信息。语义网的核心是让计算机能够理解文档中的数据,以及数据和数据之间的语义关联关系,从而使得机器可以更加智能化地处理这些信息。因此我们可以把语义网想象成是一个全球性的数据库系统,也就是我们通常所提到的Web of Data。由于语义网技术涉及面较广,本文仅涉及知识图谱所采用的语义网框架中的一项核心概念RDF(Resource Description Framework,资源描述框架)。RDF的基本数据模型包括了三个对象类型,资源(Resource)、谓词(Predicate)及陈述(Statements)。
资源:所有能够使用RDF表示的对象都称之为资源,包括所有网络上的信息、虚拟概念、现实事物等等。资源以唯一的URI(统一资源标识——Uniform Resource Identifiers,通常使用的URL是它的一个子集)来表示,不同的资源拥有不同的URI。
谓词:谓词描述资源的特征或资源间的关系。每一个谓词都有其意义,用于定义资源在谓词上的属性值(Property Value)或者其他资源的关系。
陈述:一条陈述包含三个部分,通常称之为RDF三元组<主体 (subject),谓词 (predicate),宾语(object)>。其中主体一定是一个被描述的资源,由URI来表示。谓词可以表示主体的属性,或者表示主体和宾语之间某种关系;当表示属性时,宾语就是属性值,通常是一个字面值(literal);否则宾语是另外一个由URI表示的资源。
下图1展示了一个人物类百科的RDF三元组的知识图谱数据集。例如y:Abraham_Lincoln表示一个实体URI(其中y表示前缀http://en.wikipedia.org/wiki/),其有3三个属性(hasName,BornOndate,DiedOnDate)和一个关系(DiedIn)。
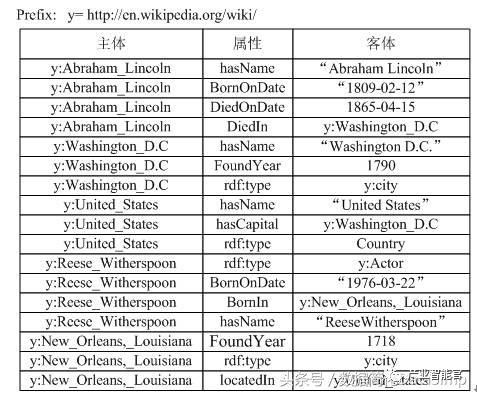
图1.RDF数据的例子
面向RDF数据集,W3C提出了一种结构化查询语言SPARQL;它类似于面向关系数据库的查询语言SQL。和SQL一样,SPARQL也是一种描述性的结构化查询语言,即用户只需要按照SPARQL定义的语法规则去描述其想查询的信息即可,不需要明确指定如何进行查询的计算机的实现步骤。2008年1月,SPARQL成为W3C的正式标准。SPARQL中的WHERE子句定义了查询条件,其也是由三元组来表示。我们不过多的介绍语法细节,有兴趣的读者可以参考[1]。下面的例子解释了SPARQL语言。假设我们需要在上面的RDF数据中查询“在1809年2月12日出生,并且在1865年4月15日逝世的人的姓名?” 这个查询可以表示成如图2的SPARQL语句。

图2.SPARQL查询的例子
我们也可以将RDF和SPARQL分别表示成图的形式。例如在RDF中,主体和客体可以分别表示成RDF图中的节点,一条称述(即RDF三元组)可以表示成一条边,其中谓词是边的标签。SPARQL语句同样可以表示成一个查询图。图3显示了上例所对应的RDF图和SPARQL查询图结构。回答SPARQL查询本质上就是在RDF图中找到SPARQL查询图的子图匹配的位置,这就是基于图数据库的回答SPARQL查询的理论基础。在图3例子中,由节点005,009,010和011所推导的子图就是查询图的一个匹配,根据此匹配很容易知道SPARQL的查询结果是“Abraham Lincoln”。
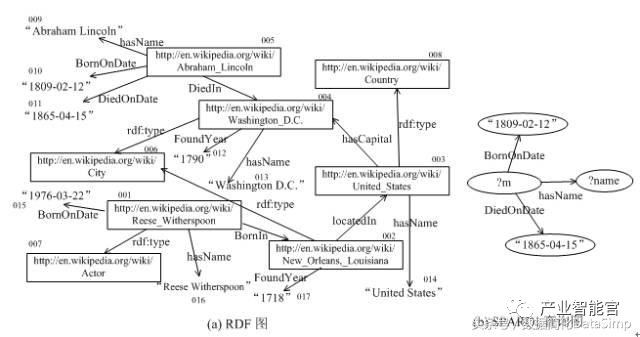
图3.RDF图和SPARQL查询图
2、知识图谱目前的应用
本章简单介绍一下知识图谱在工业界,尤其是在互联网领域中的相关应用。其实知识图谱技术在其他领域,包括工业设计和产品管理、知识出版、健康医疗和情报分析等领域,目前都出现了不少的应用,由于篇幅有限,这里主要介绍互联网领域的相关公司的产品。
如前所述,知识图谱的活跃得益于Google的Knowledge Graph项目。Google通过构建知识图谱,将内部信息资源都唯一的关联起来。例如“姚明”是知识图谱中的一个实体,包含相关的一些属性例如出生时间、地点、身高。同时,可以将搜索引擎中所爬取的和“姚明”相关的文档和图片都与这个实体关联起来。Google的知识图谱项目中最早的应用方式就是在搜索引擎返回结果里面提供“知识卡片”。传统的搜索引擎返回界面中,通常是查询词所匹配的文档列表,如图4左面所示。然而在2012年5月16日以后的Google的搜索引擎返回结果中,如果查询词匹配了Google的知识图谱中的某个实体,Google还会以知识卡片的形式返回这个实体的一些属性和其他实体的关系。例如当我们搜索“姚明”时,Google会返回如图4右边所示的知识卡片,包括姚明的出生时间、地点、身高,以及他的妻子叶丽;甚至包括相关联的姚明的图片。
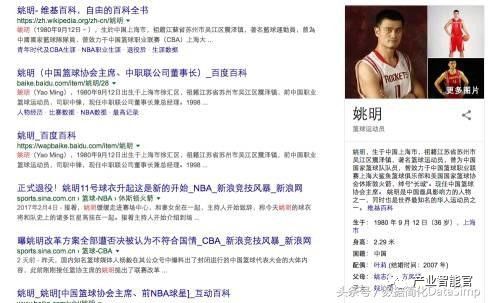
图4.Google搜索结果中的知识卡片
下面介绍Google另外一个利用知识图谱的项目叫“Google Rich Snippets”(Google富摘要)。搜索引擎在搜索结果的页面中会为每一篇搜索结果提供一个目标网页的摘要,以便用户判断是否是自己想搜索的页面。通常网页的摘要是采用“抽取式”方式生成的,即从网页的页面文本中找到和搜索关键词相关的并且比较重要的句子来构成页面的摘要返回给用户。但是Google的富摘要产品中,会抽取在用户HTML页面中以结构化形式存在的知识图谱数据,例如描述实体的属性的数据。目前这方面的标准有包括RDFa, Microdata和Schema.org等结构化数据标签。假设用户想在搜索“Thinkpad T450”产品,在Google返回的Walmart(沃尔玛)线上商店的页面摘要(如图7所示)中,摘要中包含了这个产品的打分(Rating 3星),评论数目(Vote 1份评论)和商品的价格(616.67 美金)。实际上这些重要的数据,用户已经通过Schema.org等结构化的语义标签在HTML中标示出来了,搜索引擎可以通过解析器(Parser)解析出这些结构化数据,利用这些结构化知识图谱数据来产生摘要。我们在图6中展示了利用Google的结构化测试工具,可以从上述沃尔玛产品页面的HTML中抽取上面提到的商品的价格和商标等属性信息。
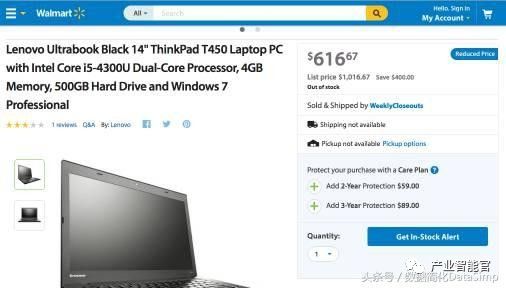
图5.Walmart(沃尔玛)线上商店的一个产品页面
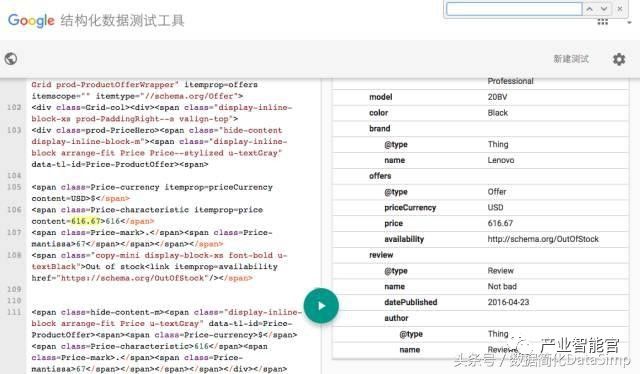
图6.Google结构化抽取工具所抽取出来的“Walmart产品页面”上的结构化数据
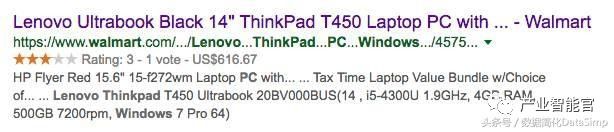
图7.根据抽取的结构化数据产生的“Walmart产品页面”搜索结果摘要
Facebook也定义了一种类似的标签语言,名叫Open Graph Protocol(OGP)。Facebook利用OGP协议定义了社交网络中上的知识图谱,即Facebook Social Graph,用于连接社交网络的用户,用户分享的照片,电影,评论,甚至包括通过Facebook定义的Graph API所链接的第三方的关于社交用户知识图谱数据。在所构建的Social Graph基础上,Facebook推出了Graph Search(图搜索)功能。将用户的自然语言问题,转化为面向Social Graph上的图搜索问题,从而回答用户的问题。假设以我的Facebook账号登录,输入自然语言“My friends who live in Canada”,将显示了我在加拿大的朋友的账号;同样地,再输入“Photos of my friends who live in Canada”,显示这些朋友的在Facebook上分享的照片。从这个例子上可以很明确的看出,Facebook所构建的Social Graph将用户、地点以及照片都关联起来,否则无法回答上述两个自然语言问题。Facebook将用户的输入的自然语言转化为面向Social Graph的结构化查询操作。从图8中可以看出,原始查询语句在经过自然语言接口模块处理后,对应的规范化自然语言查询语句和结构化查询语句分别为:“my friends who live in [id:12345]”和“intersect(friends(me), residents(12345))”[31]。其中,“12345”代表“Canada”在社交图谱上对应的Facebook ID。对应的结构化查询语句会交给Facebook内部设计的面向社交图谱的索引和搜索系统Unicorn[2],最后查询得到答案。
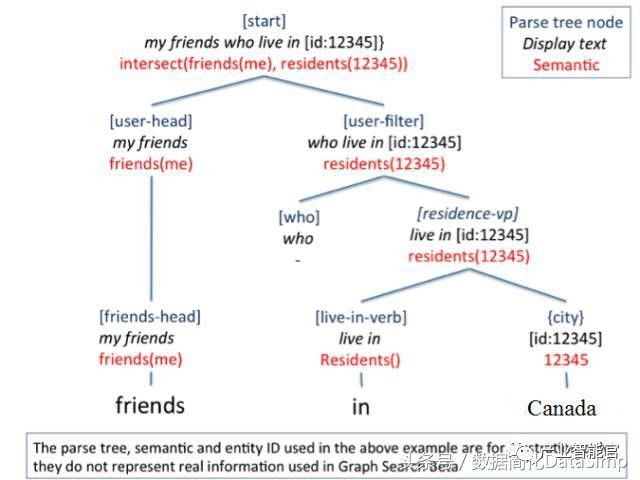
图8.Facebook中将自然语言转换为结构化查询的一个示例
面向知识图谱的问答系统还包括Amazon收购的EVI产品。EVI的原名叫True Knowledge[29],是一家创业公司的产品。本质上就是用三元组的形式来组织数据,根据模板技术将用户的自然语言问题转化为结构化的查询语句找到结果返回给用户[29]。IBM的Watson系统中也同样采用DBpedia和Yago知识图谱数据来回答某些自然语言问题[3];相比于传统基于文档的问答方法,基于知识图谱的问答其准确度更高,但是这样方法所能回答的问题相对较少。例如图9给出了IBM的Watson系统中利用知识图谱检索可以回答的问题的覆盖面小于传统利用文本搜索的覆盖率,但是利用知识图谱进行问答其精确度要高得多。
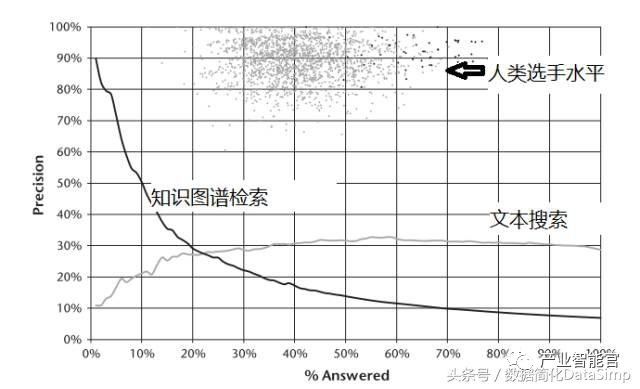
图9.IBM的Watson系统参加Jeopardy挑战的实验数据(摘自[3])
3、知识图谱数据管理方法
知识图谱数据管理的一个核心问题是如何有效地存储和查询RDF数据集。总的来说,有两套完全不同的思路。其一是我们可以利用已有的成熟的数据库管理系统(例如关系数据库系统)来存储知识图谱数据,将面向RDF知识图谱的SPARQL查询转换为面向此类成熟数据库管理系统的查询,例如面向关系数据库的SQL查询,利用已有的关系数据库产品或者相关技术来回答查询。这里面最核心的研究问题是如何构建关系表来存储RDF知识图谱数据,并且使得转换的SQL查询语句查询性能更高;其二是直接开发面向RDF知识图谱数据的Native的知识图谱数据存储和查询系统(Native RDF图数据库系统),考虑到RDF知识图谱管理的特性,从数据库系统的底层进行优化。针对以上两个方面的思路,我们分别加以介绍。
3.1 基于关系数据模型的方法
由于RDBMS(关系数据库管理系统)在数据管理方面的巨大成功以及成熟的商业软件产品,同时RDF数据的三元组模型可以很容易映射成关系模型,因此大量研究者尝试了使用关系数据模型来设计RDF存储和检索的方案 [4,5,6]。根据所设计的表结构的不同,相应的存储和查询方法也各异,下面介绍几种经典的方法。
简单三列表
一种最为简单的将RDF数据映射到关系数据库表的方法是构建一张只有三列表(Subject,Property,Object),将所有的RDF三元组都放在这个表中。给定一个SPARQL查询,我们设计查询重写机制将SPARQL转化为对应的SQL语句,由关系数据库来回答此SQL语句。例如我们可以将图2中的SPARQL查询转换为图10中的SQL语句。

图10.转换以后的SQL查询
虽然这种方法具有很好的通用性,但最大的问题是查询性能差。首先这张三列表的规模可能非常庞大,例如目前的DBpeida知识库超过了5亿条三元组。如图12所示的SQL语句中有多个表的自连接操作,这将严重地影响其查询性能。
水平存储
文献[7]中提到的水平方法(Horizontal Schema)是将知识图谱中的每一个RDF主体(subject)表示为数据库表中的一行。表中的列包括该RDF数据集合中所有的属性。这种的策略的好处在于设计简单,同时很容易回答面向某单个主体的属性值的查询,即星状查询,如图11所示。
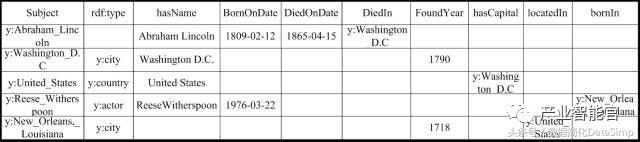
图11.水平存储
根据图13表的结构,为了回答图2中的SPARQL查询,可以转换为下面的SQL语句。与图12比较,下面的SQL语句没有耗时的连接操作,因此其查询效率要远高于图12中的SQL语句。

图12.水平存储上的SQL查询
然而这种水平存储方法的缺点也是很明显的[7,8]:其一,表中存在大量的列。一般来讲属性数目会比主体和属性值的个数少很多,但是还是有可能超过当前数据库能够承受的数量。其二,表的稀疏性问题。通常一个主体并不在所有的属性上有值。相反,主体仅仅在极少量的属性上有值。然而由于一个主体存成一行,那么表中将存在大量空值。空值不仅增加了存储负载,而且带来了其他的问题,比如增大了索引大小,影响查询效率,文献[7,8,9]详述了空值带来的问题。其三,水平存储存在多值性问题。一个表中列的数量是固定的,这就使得主体在一个属性上只能有一个值。而真实数据往往并不符合这个限制条件。其四,数据的变化可能带来很大的更新成本。在实际应用中,数据的更新可能导致增加属性或删除属性等改变,但是这就涉及到整个表结构的变化,水平结构很难处理类似的问题。
属性表
属性表是水平存储的优化。根据每个实体所关联的属性集合,将不同的实体进行分类。每一类采用水平存储策略的数据库表。属性表在继承了水平存储策略优势的基础上,又通过对相关属性的分类避免了表中列数过多等问题。Jena2[10,11]中使用属性表以提高对RDF三元组的查询效率。研究者提出了两种不同的属性表,其一称为聚类属性表(clustered property table),另一类称为属性类别表(property-class table)。
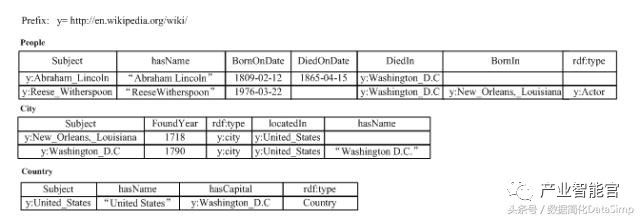
图13. 聚类属性表
聚类属性表将概念上相关的属性聚成一类,每一类定义一个单独的数据库表,使用水平方式存储这些三元组。如果有一些三元组不属于任何一个类别,它们被放在一张剩余表(left-over table)中。在图13中,根据属性的相关性,将所有的属性聚类成三个类,每个类用一张水平表来存储。同样的,根据图7给出的属性表结构,我们也可以将图3中的SPARQL查询转换成类似于图12的SQL语句。属性类别表将所有的实体按照rdf:type来分类,每一类用一个张水平表来表示。这种组织方式要求每个实体都必须有一个rdf:type属性(标识实体分类的标签)。
属性表最主要的优点在于可以减少查询时主体-主体间的自连接代价,这样可以极大地提高查询效率。属性表的另外一个优点在于由于与一个属性相关的属性值存储在一列中,就可以针对该列的数据类型设计一些存储策略来减少存储空间。这样就避免了三元组存储策略中由于数据类型不同的属性值存储在一列中造成存储上的不便。Jena2等的研究工作以及其他的一些研究工作证明了属性表的有效性,但属性表也有着先天性的缺陷。其一,文献[12]指出,虽然属性表对于某些查询能够提高查询性能,但是大部分的查询都会涉及多个表的连接或合并操作。对聚类属性表而言,如果查询中属性作为变量出现,则会涉及多个属性表;对属性分类表而言,如果查询并未确定属性类别,则查询会涉及多个属性表。在这种情况下,属性表的优点就较不明显了。其二,RDF数据由于来源庞杂,其结构性可能较差,从而属性和主体间的关联性可能并不强,类似的主体可能并不包含相同的属性。这时,空值的问题就出现了。数据的结构性越差,空值的问题就越发明显。其三,在现实中,一个主体在一个属性上可能存在多值。这时,用RDBMS管理这些数据时就带来麻烦。其中,前两个问题是相互影响的。当一个表的列数目减小时,对结构性要求较低,空值问题得到缓解,但查询会涉及更多的表;而当表的列数加大时,如果数据结构性不强,就会出现更多空值的问题[29]。
垂直划分策略
Abadi等人[12]以一种完全的分解存储模型(DSM[13],Decomposed Storage Model)为基础,将DSM引入了语义网数据的存储,提出了垂直分割技术。在垂直分割的结构下,三元组表被重写为N张包含两列的表,N等于RDF数据中属性的个数。每一张表都以相对应的属性为表名,其第一列是所有在这个属性上有属性值的主体,第二列是该主体在这个属性上的值。每一张表中的数据按照主体进行排序,从而能够迅速定位特定主体,而且将所有涉及主体-主体的表连接转换为可以迅速完成的排序合并连接 (Merge Join)。在对存储空间限制较少时,也可以对属性值这一列建立索引或对每个表建立一个按照属性值排序的副本,以提高涉及对特定属性值的访问和属性值-主体、属性值-属性值连接的性能。如图14中显示了将图1中的RDF数据集分解成8个二元表,并且每个二元表按照主体进行排序。
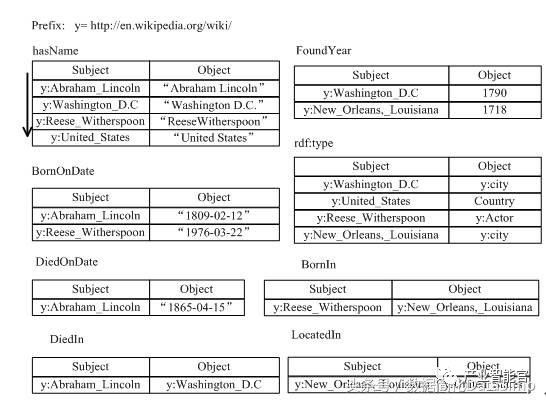
图14.二元垂直分割表
相比较于三元组存储,这种二元存储方式有如下的优点:由于属性名不再重复出现,因此有效地减少了存储空间。在查询时,只需要处理涉及查询条件的表,从而有效地减少了I/O代价。相比于属性表方式,垂直分割的优点在于以下几条。垂直分割适应于多值数据。如同三元组存储方式一样,当一个主体在一个属性上有多个属性值时,只需要将其存储为多行即可。垂直存储也很适用于结构化较差的数据,如果一个主体未定义某个属性,那么这个记录就不会在这种存储方式中出现,避免了空值的产生。二元存储技术不需要对属性进行聚类,就不需要寻找好的聚类算法。在查询时,如果属性名被限定,那么查询的内容就不会出现在多个表中,减少了合并操作。SW-Store[12]利用了垂直分割技术,更进一步的还减少了主体存储的冗余。但垂直分割技术同样存在着缺点。首先,这种存储方式增加了表连接的运算数。即使这些连接都是时间代价较低的合并连接,总的运算代价也是不可忽略的。其次,表的增多增加了数据更新的难度,尤其是SW-Store采用列存储策略进行空间优化以后系统的更新性能就碰到更大的挑战。对一个主体的更新需要涉及多个表,就可能因为外存存储方式的影响增加I/O代价。当表上存在索引时,更新代价更是相当昂贵。另外,文献[14,15]认为在多个表中存储结构化不强的数据(如某些RDF数据集)会存在一些问题,将多个表返回的结果重构成一张视图所进行的运算可能代价较高。他们建议将较稀疏、结构化较差的数据存储于一张表中,并对存储结构加以描述。
全索引策略
如前所述,简单的三列表存储的缺点在于自连接次数较多。为了提高简单三列表存储的查询效率,目前一种普遍被认可的方法是“全索引(exhaustive indexing)”策略,例如RDF-3X[16]和Hexastore[17]。列举三列表的所有排列组合的可能性(6种),并且按照每一种排列组合建立聚集B+-树。建立这样全索引的好处有两点:其一,对于SPARQL查询中的每个查询三元组模式,都可以转换成对于某个排列组合上的范围查询。例如 ?m <BornOnDate> “1809-02-12”这个查询三元组模式,可以转换为对于(P,O,S)排列上的范围查询。因为在(P,O,S)排列中,所有P, O为<BornOnDate>和“1809-02-12”的三元组都连在一起。其二,全索引的好处在于可以利用归并连接(Merge Join)降低连接的复杂度。我们知道嵌套循环(Nested Loop Join)连接的复杂度是O(|L1|*|L2|),这里|L1|和|L2|分别表示两个待连接列表的长度。然而归并连接的复杂度是O(MAX(|L1|, |L2|) )。例如从(P,O,S)排列中可以得到满足?m <BornOnDate> “1809-02-12”查询条件的?m的取值,并且这些取值按照顺序进行排列。同样的,从(P,O,S)排列中也可以得到满足?m <DiedOnDate> “1865-04-15”查询条件的?m的取值,并且这些取值也按照顺序进行排列。通过归并排序,我们可以很容易找到同时满足这两个查询条件的?m的取值。
虽然用全索引策略可以弥补一些简单垂直存储的缺点,但三元存储方式难以解决的问题还有很多。其一,不同的三元组其主体/属性/属性值可能重复,这样的重复出现会浪费存储空间。其二,复杂的查询需要进行大量表连接操作,即使精心设计的索引可以将连接操作都转化为合并连接,当SPARQL查询复杂时,其连接操作的查询代价依然不可忽略。其三,随着数据量增长,表的规模会不断膨胀,系统的性能下降严重;而且目前此类系统都无法支持分布式的存储和查询,这限制了其系统的可扩展性。其四,由于数据类型多样,无法根据特定数据类型进行存储的优化,可能会造成存储空间的浪费(例如,客体的值可能多种多样,如URI、一般字符串或数值。客体一栏的存储空间必须满足所有的取值,而无法进行存储优化)。为了解决这个问题,目前的全索引方法都是利用字典方式将所有的字符串和数值映射成一个独立的整数ID。但是这种字典映射的方法很难支持带有数值范围约束和字符串中的子串约束的SPARQL查询。
3.2 基于图数据模型的方法
通过将RDF三元组看作带标签的边,RDF知识图谱数据很自然地符合图模型结构。因此,有的研究者从RDF图模型结构的角度来看待RDF数据,他们将RDF数据视为一张图,并通过对RDF图结构的存储来解决RDF数据存储问题。图模型符合RDF模型的语义层次,可以最大限度的保持RDF数据的语义信息,也有利于对语义信息的查询。此外,以图的方式来存储RDF数据,可以借鉴成熟的图算法、图数据库来设计RDF数据的存储方案与查询算法。然而,利用图模型来设计RDF存储与查询也存在着难以解决的问题。第一,相对于普通的图模型,RDF图上的边具有标签,并可能成为查询目标;第二,典型的图算法往往时间复杂度较高,需要精心的设计以降低实时查询的时间复杂度。
我们在文献[18]中提出一种利用子图匹配方法来回答SPARQL的方法,并构建了相关开源系统gStore。图15给出了系统架构图。在导入RDF知识图谱数据和构建索引阶段,首先将用户输入RDF的三元组文件表示成一张图G,通过链接列表的方式直接存储图G本身。为了加快子图匹配查询的速度,通过编码的方法,将RDF图G中的每个实体节点和它的邻居属性和属性值编码成一个带有Bitstring的节点,从而得到一张标签图G*。我们提出了一种面向G*图的VS-tree的索引结构,可以有效地支持在线查询的阶段的搜索空间过滤。在查询阶段,将用户的SPARQL查询转换为子图匹配查询,利用子图匹配查询的结果来回答用户的问题。图16展示了在3-5亿规模的三元组的国际标准测试集(LUBM和WatDiv)上,gStore系统和目前使用最为广泛的RDF知识图谱存储查询系统Virtuoso和Apache Jena之间的查询性能对比情况。由于基于图结构方法的索引可以考虑到查询图整体信息,因此总的来说查询图越复杂(例如查询图的边越多),gStore相对于对比系统的性能会更好,有的可以达到一个数量级以上的性能优势。gStore的分布式版本的在10台机器组成的Cluster上可以进行50-100亿规模的RDF知识图谱管理的任务。
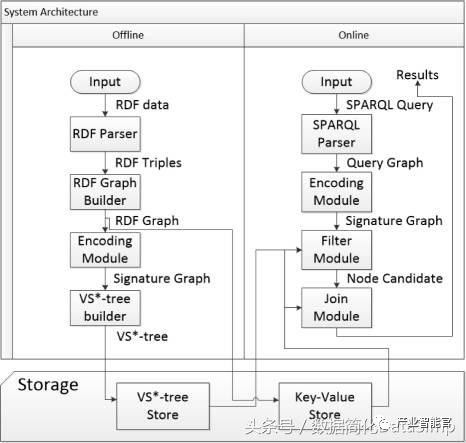
图15.gStore系统架构
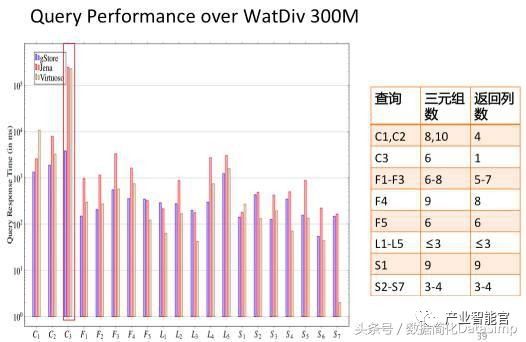
a.在WatDiv 3亿三元组规模数据上的评测结果
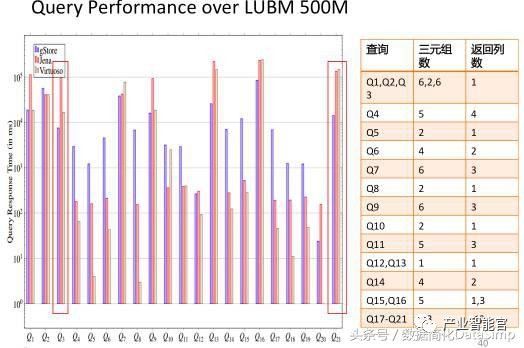
b.在LUBM 5亿三元组规模数据上的评测结果
图16.在国际通用RDF测评数据集上的比较结果
另外,Udrea等人提出GRIN算法[39]来回答SPARQL查询,其基本思想是构建一个类似M-tree结构[21]的GRIN 索引,利用图上的距离约束来介绍搜索空间。所有的RDF图上的节点表示成GRIN索引上的叶子节点。GRIN索引上的非叶子节点包括两个元素(center,radius),其中center是一个中心点,radius是半径长度。在RDF图上离center最短路径距离小于等于radius的节点在GRIN上是该非叶子节点的子孙节点。利用距离约束,GRIN可以迅速判断RDF图哪些部分不能满足查询条件,从而提高查询性能。
另外一个我们需要提到基于图的系统是Trinity.RDF[20],是由微软亚洲研究院开发的一种分布式基于内存的图数据引擎。由于图操作的“局部性”差的特点,该系统通过采用内存云的形式来管理RDF图数据。另外为了回答子图匹配查询,Trinity.RDF提出通过图上的扩展(Exploration)策略而非通常的Join(链接查询)的策略来找到子图匹配的位置。
4、不同领域对知识图谱研究的侧重
总的来说,知识图谱是一项交叉研究领域;计算机的不同学科都从不同的角度对知识图谱这个领域进行了研究工作。图16展示这样的一种多学科交叉研究的状况。前三章主要是从数据库和数据管理的角度对知识图谱的研究内容进行了介绍,下面分别从自然语言处理,知识工程和机器学习领域分别简单介绍这几个领域对知识图谱研究的目前的热点。

图16.不同领域对“知识图谱”研究的侧重
自然语言处理领域,针对知识图谱的研究主要在两个方面。其一是“信息抽取”。目前互联网上大部分数据仍然是“非结构化”的文本数据,如何从非结构的文本数据中抽取出知识图谱所需要的三元组数据是一项带有挑战性的工作[22]。另外一项目前非常活跃的研究课题是“语义解析(Semantic Parser)”,即将用户输入的自然语言问题转化面向知识图谱的结构化查询[23]。
在知识工程领域主要也有两个方面的热点研究问题。其一是大规模本体和知识库的构建。例如DBpeida[24]和Yago[25]都是通过从维基百科上获取知识从而构建大规模的知识图谱数据集;另外面向特定封闭领域(closed domain)的知识图谱构建在工业界应用比较广泛。另外一项研究课题是知识图谱上的推理问题研究。注意到,知识图谱不同于传统数据库的闭世界假设(Closed-world assumption),知识图谱采用的是开放世界假设(Open-world assumption)。在开放世界假设情况下,系统并不假设所存储的数据是完备的;系统中没有被显示存储但是可以通过推理得到的“陈述(Statement)”,仍然被认为是正确的数据。
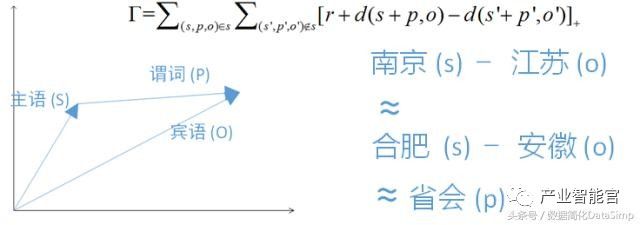
图 17. TransE模型示例
近几年来,机器学习领域也掀起了对知识图谱的研究,热门的课题包括面向知识图谱的“表示学习”,其中最为代表性的研究工作是TransE模型[26]。给定一个知识图谱,我们将知识图谱三元组中的每个主语、宾语和谓词都映射成一个高维向量,其优化目标可以表示为最小化图17中的公式。这个公式的基本含义是,对于存在于知识图谱G里面的任何一条三元组,其中主语,谓词和宾语的向量表示结果为s, p 和o, 我们要求主语(s)和谓词(p)的向量和(SUM)离宾语(o)的向量表示尽量的近;对于不存在知识图谱G中的三元组,则相互距离尽量的远。图17可视化了TransE模型的含义,基本含义是谓词相同的两个三元组,它们分别的主语与宾语的向量差是近似的。在TransE模型的基础上,学术界提出了很多改进的知识图谱Embedding的方案。这些模型在很多任务,例如知识图谱的谓词预测,知识补全等方面比以前的方法在准确度都有不小的提升。
5、总结
知识图谱(Knowledge Graph)从某种角度来说,是一个商业包装的词汇;但是其本身来源于诸如语义网、图数据库等相关的学术研究领域。本文试图从知识数据管理的角度来介绍知识图谱领域的研究的热点,以及不同学科对于知识图谱不同研究侧重。由于篇幅有限和本人的学术研究水平的局限,对于更大范围的知识图谱研究和应用的介绍难免挂一漏万,敬请读者批评指正。本人和所领导的北京大学计算机所数据管理研究室(1)以及我们的合作者,长期从事RDF知识图谱数据管理的方面的工作,开发了一套面向海量RDF知识图谱数据的图数据库系统gStore[18](2)和自然语言问答系统gAnswer[27](3).读者如果对这两个系统的工作感兴趣,请参考系统发表原始论文VLDB 11[30]和SIGMOD 14 [27], 以及我们近期所总结这两个知识图谱项目研究思路的文章[28](4)。
(1)http://www.icst.pku.edu.cn/db/en/index.php/Main_Page
(2)http://www.icst.pku.edu.cn/intro/leizou/projects/gStore.htm
(3) http://www.icst.pku.edu.cn/intro/leizou/projects/gAnswer.htm
(4)http://rdcu.be/o1nT

人工智能赛博物理操作系统
AI-CPS OS
“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能)分支用来的今天,企业领导者必须了解如何将“技术”全面渗入整个公司、产品等“商业”场景中,利用AI-CPS OS形成数字化+智能化力量,实现行业的重新布局、企业的重新构建和自我的焕然新生。
AI-CPS OS的真正价值并不来自构成技术或功能,而是要以一种传递独特竞争优势的方式将自动化+信息化、智造+产品+服务和数据+分析一体化,这种整合方式能够释放新的业务和运营模式。如果不能实现跨功能的更大规模融合,没有颠覆现状的意愿,这些将不可能实现。
领导者无法依靠某种单一战略方法来应对多维度的数字化变革。面对新一代技术+商业操作系统AI-CPS OS颠覆性的数字化+智能化力量,领导者必须在行业、企业与个人这三个层面都保持领先地位:
重新行业布局:你的世界观要怎样改变才算足够?你必须对行业典范进行怎样的反思?
重新构建企业:你的企业需要做出什么样的变化?你准备如何重新定义你的公司?
重新打造自己:你需要成为怎样的人?要重塑自己并在数字化+智能化时代保有领先地位,你必须如何去做?
AI-CPS OS是数字化智能化创新平台,设计思路是将大数据、物联网、区块链和人工智能等无缝整合在云端,可以帮助企业将创新成果融入自身业务体系,实现各个前沿技术在云端的优势协同。AI-CPS OS形成的数字化+智能化力量与行业、企业及个人三个层面的交叉,形成了领导力模式,使数字化融入到领导者所在企业与领导方式的核心位置:
精细:这种力量能够使人在更加真实、细致的层面观察与感知现实世界和数字化世界正在发生的一切,进而理解和更加精细地进行产品个性化控制、微观业务场景事件和结果控制。
智能:模型随着时间(数据)的变化而变化,整个系统就具备了智能(自学习)的能力。
高效:企业需要建立实时或者准实时的数据采集传输、模型预测和响应决策能力,这样智能就从批量性、阶段性的行为变成一个可以实时触达的行为。
不确定性:数字化变更颠覆和改变了领导者曾经仰仗的思维方式、结构和实践经验,其结果就是形成了复合不确定性这种颠覆性力量。主要的不确定性蕴含于三个领域:技术、文化、制度。
边界模糊:数字世界与现实世界的不断融合成CPS不仅让人们所知行业的核心产品、经济学定理和可能性都产生了变化,还模糊了不同行业间的界限。这种效应正在向生态系统、企业、客户、产品快速蔓延。
AI-CPS OS形成的数字化+智能化力量通过三个方式激发经济增长:
创造虚拟劳动力,承担需要适应性和敏捷性的复杂任务,即“智能自动化”,以区别于传统的自动化解决方案;
对现有劳动力和实物资产进行有利的补充和提升,提高资本效率;
人工智能的普及,将推动多行业的相关创新,开辟崭新的经济增长空间。
给决策制定者和商业领袖的建议:
超越自动化,开启新创新模式:利用具有自主学习和自我控制能力的动态机器智能,为企业创造新商机;
迎接新一代信息技术,迎接人工智能:无缝整合人类智慧与机器智能,重新
评估未来的知识和技能类型;
制定道德规范:切实为人工智能生态系统制定道德准则,并在智能机器的开
发过程中确定更加明晰的标准和最佳实践;
重视再分配效应:对人工智能可能带来的冲击做好准备,制定战略帮助面临
较高失业风险的人群;
开发数字化+智能化企业所需新能力:员工团队需要积极掌握判断、沟通及想象力和创造力等人类所特有的重要能力。对于中国企业来说,创造兼具包容性和多样性的文化也非常重要。
子曰:“君子和而不同,小人同而不和。” 《论语·子路》云计算、大数据、物联网、区块链和 人工智能,像君子一般融合,一起体现科技就是生产力。
如果说上一次哥伦布地理大发现,拓展的是人类的物理空间。那么这一次地理大发现,拓展的就是人们的数字空间。在数学空间,建立新的商业文明,从而发现新的创富模式,为人类社会带来新的财富空间。云计算,大数据、物联网和区块链,是进入这个数字空间的船,而人工智能就是那船上的帆,哥伦布之帆!
新一代技术+商业的人工智能赛博物理操作系统AI-CPS OS作为新一轮产业变革的核心驱动力,将进一步释放历次科技革命和产业变革积蓄的巨大能量,并创造新的强大引擎。重构生产、分配、交换、消费等经济活动各环节,形成从宏观到微观各领域的智能化新需求,催生新技术、新产品、新产业、新业态、新模式。引发经济结构重大变革,深刻改变人类生产生活方式和思维模式,实现社会生产力的整体跃升。
产业智能官 AI-CPS
用“人工智能赛博物理操作系统”(新一代技术+商业操作系统“AI-CPS OS”:云计算+大数据+物联网+区块链+人工智能),在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的认知计算和机器智能;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。


长按上方二维码关注微信公众号: AI-CPS,更多信息回复:
新技术:“云计算”、“大数据”、“物联网”、“区块链”、“人工智能”;新产业:“智能制造”、“智能农业”、“智能金融”、“智能零售”、“智能城市”、“智能驾驶”;新模式:“财富空间”、“特色小镇”、“赛博物理”、“供应链金融”。
点击“阅读原文”,访问AI-CPS OS官网
本文系“产业智能官”(公众号ID:AI-CPS)收集整理,转载请注明出处!
版权声明:由产业智能官(公众号ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源。部分文章推送时未能与原作者取得联系。若涉及版权问题,烦请原作者联系我们,与您共同协商解决。联系、投稿邮箱:erp_vip@hotmail.com




