
原文来源:Deloitte
编辑整理:专知
AI模型偏差对信任的损害可能比你想象的要大,但有方法可以克服!
人工智能影响整个企业的决策,但偏差会对信任和利益相关者关系造成深远的损害。然而有一些方法可以改善此局面。
一家大型区域性银行使用新开发的欺诈检测人工智能 (AI) 算法来识别潜在的银行欺诈案例,包括金融交易、贷款申请和新账户申请的异常模式。该算法在一组初始数据上进行训练,以了解正常交易与欺诈交易的外观。但是,由于对 45 岁以上的申请人进行了过度抽样以获取欺诈行为的示例,因此训练数据会出现偏差。这种过采样会持续数月,随着偏差的增加并且未被检测到。与现实所暗示的相比,该模型更有可能认为老年人正在实施欺诈。越来越多的客户被拒绝贷款。当监管机构开始提问时,一些人开始感到疏离,失去信任。 我们知道模型偏差可能是一个问题,但我们真的知道它有多普遍吗?当然,媒体机构撰写的故事能够激发公众的想象力,例如不公平地偏向女性的 AI 招聘模型或基于种族身份不公平地分配更高风险分数的 AI 健康保险风险算法。但尽管这些例子可能很糟糕,但 AI 模型偏差的故事几乎不会以我们在大众媒体上看到的内容而结束。
我们的研究表明,模型偏差可能比许多组织意识到的更为普遍,它所造成的损害可能比我们想象的要大得多,从而削弱了员工、客户和公众的信任。成本可能很高:昂贵的技术修复、较低的收入和生产力、声誉损失和员工短缺,更不用说投资损失了。事实上,在德勤最近发布的第四版企业人工智能状况报告中,68% 的受访高管表示,仅在过去一个财政年度,他们的职能部门就在人工智能项目上投资了 1000 万美元或更多。3即使是面向内部的模型也可能造成重大损害,并可能使数百万美元的投资面临风险。
要解决这个问题,我们需要超越同理心和善意。了解、预测并尽可能避免模型偏差的发生对于以保持利益相关者信任的方式在整个组织内推进 AI 模型的使用至关重要。好消息是,组织可以采用一些可以提供帮助的方法(包括基于技术的解决方案)。
1 组织内的模型偏差可能比您知道的更普遍
“偏差”一词有很多含义。出于本研究的目的,我们可以将 Merriam-Webster 对偏差的定义视为“通过选择或鼓励一种结果或答案而不是其他结果或答案而引入抽样或测试的系统性错误”。一般而言,当 AI 算法或模型所依赖的训练数据不能反映 AI 预期运行的现实时,就会发生 AI 模型偏差。换句话说,尽管使用了“模型偏差”一词,但模型本身并没有偏差。而是训练数据这使得模型有偏差。人工智能企业软件公司 Chatterbox Labs 的首席技术官 Stuart Battersby 对此表示赞同。Battersby 表示,“无论背景如何,[模型偏差风险] 通常都归结为训练数据,”用于通知模型,任何训练数据都容易受到偏差的影响。 模型偏差尤其令人不安,部分原因是组织或使用相关 AI 模型的人并不总是预料到它。正如 Cathy O'Neil 在她的书中所暗示的,这些“数学破坏武器”是秘密且可扩展的,这会放大它们对组织及其利益相关者的危险。
模型偏差尤其令人不安,部分原因是组织或使用相关 AI 模型的人并不总是预料到它 有证据表明,人工智能模型的一些用户可能没有注意到这种危险。考虑德勤的人工智能状态报告,其中约四分之三的总体受访者表示他们“有信心”或“非常有信心”他们部署的模型将表现出公平和公正的品质。类似的份额表示,他们“有信心”或“非常有信心”他们部署的模型将表现出稳健性和可靠性的品质。7这些数据点很重要,因为公平性和稳健性等特征是模型按其应有的方式运行且没有偏差的标志。
在涉及社会歧视和偏差的 AI 模型中发现的偏差故事存在于多种背景中,包括大学录取决定、刑事判决和假释决定、和雇用决定、在许多其他人中。公开提到的许多模型偏差示例都与服务于面向客户功能的模型中的偏差有关。然而,我们的研究表明,无论我们指的是影响客户的模型还是组织的运营或内部部分,偏差风险都很普遍。组织“后台”中的一些模型风险通常要等到部署很久之后才会被发现,并产生相应的影响。事实上,在网络安全或合规性等内部运营领域中,模型偏差的风险可能尤其隐蔽,因为内部模型可能无法像更面向外部的部署那样受到公众审查,从而延迟了对它们的检测。世界经济论坛人工智能和机器学习技术政策负责人 Jayant Narayan 说:“大多数 AI 模型偏差讨论仍然是关于面向外部的功能和更面向客户的行业的用例。公司应该重新评估其内部功能和用例的偏差和风险分类。”
换句话说,AI 模型偏差与领域无关。在所有形式中,它都可以发生在部署 AI 模型的任何地方,无论上下文如何。正如我们将讨论的那样,上下文确实很重要,在于模型偏差对信任的影响。 组织模型偏差的“狂野西部 在我们的研究过程中,出现了几种类型或原型的模型偏差。我们根据影响模型的行为类型确定了两组主要的偏差:“被动”偏差——偏差不是计划行为的结果——和“主动”偏差——偏差是由于人为行为而发生的,要么有或没有意图,即使是有意的,通常也没有负面意图。两种类型的偏差都可以以不同的方式表现出来,在制定减轻模型偏差风险的策略时,都应该考虑这两种偏差。在随后的分类中描述偏差时,我们使用我们自己的术语以及社会科学和技术文献中常见的术语。
01 被动偏差
被动偏差的例子可能包括:
选择偏差:一个群体的过度包容或包容不足;数据不足;标签不良。选择偏差的一个例子可以在基于数据训练的 AI 模型中找到,在该模型中,特定群体被识别为具有特定特征的比率高于客观现实的合理性。
环境偏差:训练数据过时;变化的情况。环境偏差的一个例子可能包括一个预测性 AI 模型,该模型使用最初准确但由于不断变化的现实或“实地事实”而不再准确的数据进行训练。
遗留或关联偏差:AI 模型根据与基于种族、性别和其他原因的偏差遗留相关的术语或因素进行训练,即使是无意的。一个例子是在一种基于数据训练的招聘算法中发现的,这些数据虽然没有明显的性别偏差,但指的是带有男性关联遗产的术语。
02 主动偏差
主动偏差的示例可能包括:
对抗性偏差:数据中毒;部署后的对抗性偏差。例如,敌对行为者可以访问模型的训练数据并引入对邪恶目标的偏差。
判断偏差:模型经过适当训练,但模型用户在实施过程中通过误用 AI 决策输出的方式引入偏差。例如,一个模型可能会产生客观正确的结果,但最终用户会以系统的方式误用这些结果。从这个意义上说,判断偏差不同于其他模型偏差,因为它不是训练数据有缺陷的直接结果。
上述分组远非详尽或明确;存在其他偏差特征。这说明了对模型偏差是什么以及它是如何发生的不断发展且仍处于萌芽状态的理解。
换句话说,AI 模型偏差与领域无关。在所有形式中,它都可以发生在部署 AI 模型的任何地方,无论上下文如何。
2 信任联系:模型偏差的破坏性可能比你知道的要大的多
AI 模型偏差的影响可以通过影响其决策制定和与利益相关者的信任来影响整个组织。决策和信任是两个独立但相互关联的概念。信任是组织与其利益相关者在个人和组织层面建立有意义关系的基础。信任是通过表现出高度能力和意图的行动来建立的,从而表现出能力、可靠性、透明度和人性。能力是信任的基础,是指执行能力,兑现您的品牌承诺。意图是指您的行为背后的原因,包括公平性、透明度和影响力。一个没有另一个不会建立或重建信任。两者都是需要的。
当基于有偏差的数据的错误分析做出错误的决定时,组织可能会失去对可能依赖模型建议的利益相关者的信任。例如,这可能表现在董事会成员对推荐无利可图项目的执行团队失去信任,或者员工质疑聘用不合格候选人的情况。
一旦发生决策错误并且与给定利益相关者的信任破裂,该利益相关者的行为就会改变。对于员工而言,这可能意味着工作参与度降低、客户参与度降低、品牌忠诚度降低,或者对于供应链合作伙伴而言,将业务推荐给他人的意愿降低。这些行为变化会对组织绩效产生有意义的影响,可能会限制销售、生产力和盈利能力。最终,缺乏信任会阻止公司与利益相关者一起实现其目标和宗旨。
考虑一下我们在本文开头提到的银行。在该示例中,人工智能模型偏差会影响决策,导致银行对年长的信贷申请人做出不公平的假设,从而避免向服务不足的年长市场销售产品。反之亦然,因为偏差导致银行向实际参与欺诈的年轻申请人发放贷款申请。一旦知道了这种偏差——即使银行努力纠正它——银行专业人员也可能对算法的输出失去信心。事实上,他们可能会更普遍地对人工智能模型失去信心。因此,他们可能会避免重要的业务决策,例如追查实际的欺诈案件。
此示例中的模型偏差影响了多个利益相关者。如果这种偏差导致银行对老客户的服务不足,可能会疏远选民。这将使他们的信任和赞助受到威胁。即使没有受到直接影响,它也可能会危及其他客户的信任和业务,这些客户意识到并受到这种偏差的冒犯。由于这种偏差可能会违反《平等信用机会法》中的各种监管和法定要求,因此可能会损害监管机构的信任,从而可能导致影响利润的民事处罚。最终,这种模型偏差的后果可能会损害银行的声誉和底线业绩。
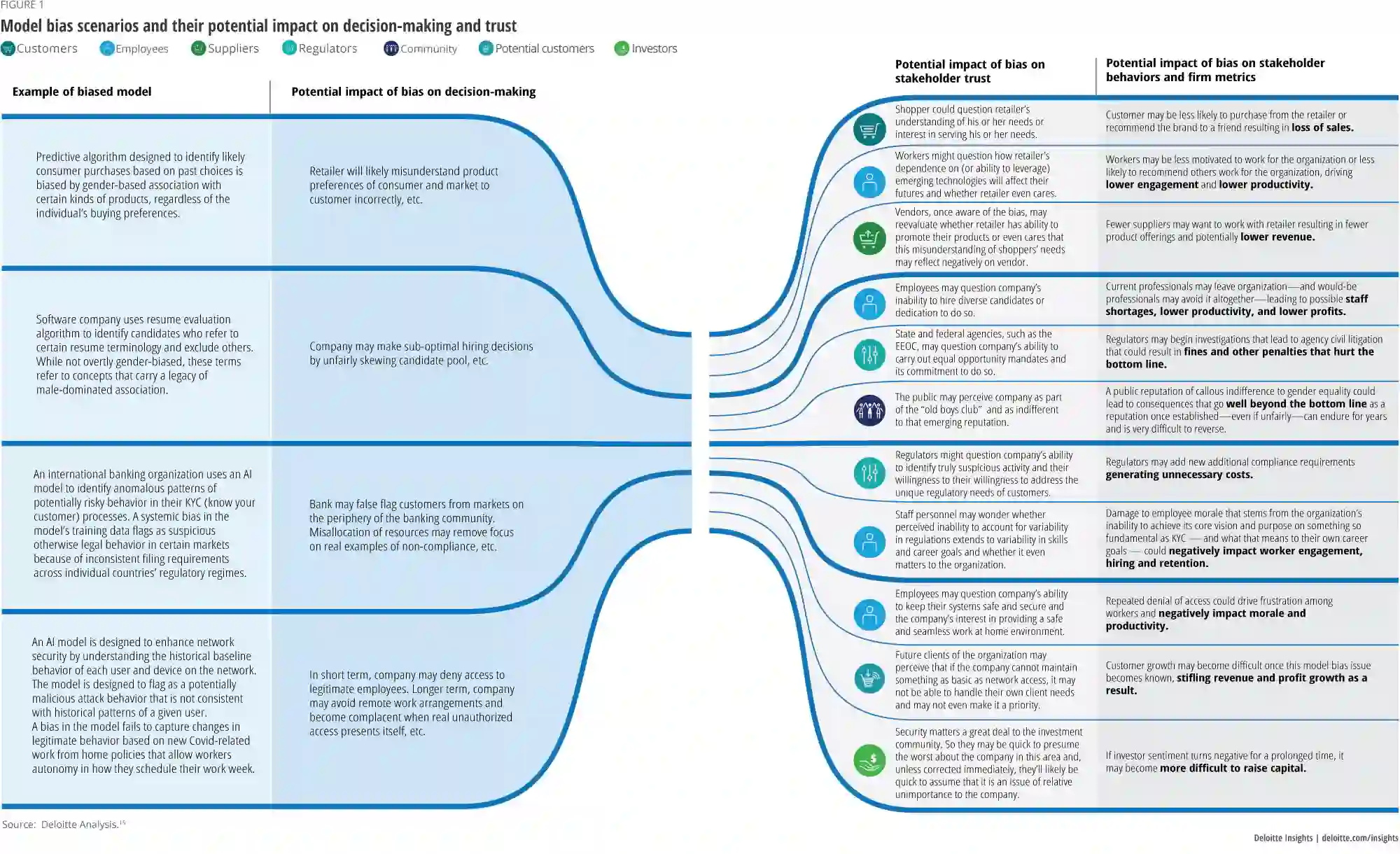
这只是 AI 模型存在不公平偏差时对决策和信任造成后果的众多示例之一(下图)。AI 模型偏差的影响通常不限于一个利益相关者群体。相反,最常导致的错误决策通常会影响多个利益相关者群体,并可能对其信任组织的意愿产生负面影响。这种偏差发生的背景——一系列决策、利益相关者和由此产生的行为变化——可以定义组织的风险和成本。
模型偏差的影响通常不限于一个利益相关者群体。相反,最常导致的错误决策通常会影响多个利益相关者群体,并可能对其信任组织的意愿产生负面影响。 为了说明模型偏差的个体特征,我们描述了一些不同的案例场景,其中模型偏差的性质可能会表现出来,以及决策和信任如何因此受到影响(下图)。
3 应以主动和整体的方式解决模型偏差
一旦发现模型偏差事件,组织应该“深入了解”以评估偏差的性质(包括其原因),它已经影响决策制定的方式,最终影响利益相关者的信任,以及如何预防它的再次发生。正如 Chatterbox Lab 的 Battersby 所说,“你想真正找到根本原因,了解为什么你有这种偏差以及这在你的组织中意味着什么,以防止它再次发生。” 话虽如此,对已经存在的偏差做出反应远不如预测和阻止偏差的起源——或至少在部署之前。DataRobot 可信 AI 副总裁 Ted Kwartler 是这样说的:“在模型中发现偏差是可以的,只要它在生产之前。当你投入生产时,你就有麻烦了。”
以下指南可帮助组织预测不同环境下的 AI 模型偏差。这样的指南可以帮助组织以公平和透明的方式部署人工智能模型。
对组织内的所有人进行有关 AI 模型偏差风险的潜在教育。即使在那些最直接参与人工智能模型开发和部署的人中,偏差也并不总是放在首位。对于整个组织的其他人来说,模型偏差通常是一种抽象,只有在偏差及其伴随的影响变得明显之后才会成为问题。组织内的领导者和员工——包括最高管理层及其他——应该理解模型偏差所代表的战略必要性,因为整个组织的每个人都可能受到它的影响。此类教育应针对营销和人力资源等部门的模型最终用户,因此他们可以警惕存在偏差的可能性,并注意不要通过错误的实施无意中引入偏差。
建立一种共同语言来讨论模型风险和减轻风险的方法。值得信赖的人工智能,也称为道德或负责任的人工智能,在人工智能应用程序的开发和使用中具有共同的主题。这些主题包括公平、透明、可靠性、问责制、安全和保障以及隐私。这些主题为评估和减轻人工智能风险(包括模型偏差)提供了共同语言和视角。组织在设计、开发、部署和操作 AI 系统时可以考虑这些主题。这些主题中的每一个都阐明了共同构成值得信赖的人工智能的一个方面。每个都支持组织以正确的意图胜任部署人工智能模型的能力。
确保受模型影响最大的人在开发模型时处于“循环中”。我们的研究表明,人类倾向于相信 AI 模型决策的准确性,而没有真正了解模型的工作原理或开发方式。当模型偏差出现时,这是一种特别不稳定的做法。AI 模型生命周期的每个部分都应经常反映技术与所有利益相关者之间的伙伴关系。“如果有人参与,偏差是可以控制的,”Chatterbox Labs 首席执行官 Danny Coleman 说。但循环中的人不仅仅是开发和部署模型的人。这也与模型决策输出的最终消费者有关。它们应该与任何人一样成为模型开发方式的一部分(了解它可以做什么和不能做什么),以减轻问题可能带来的对信任的潜在损害。科尔曼称之为“管理利益相关者的期望”。利益相关者的参与应该从模型构思阶段开始。德勤加拿大值得信赖的人工智能领导者 Preeti Shivpuri 表示:“与不同的利益相关者进行磋商并收集不同的观点以挑战现状对于解决数据中的固有偏差和从一开始就使人工智能系统具有包容性至关重要。”
包括工艺和技术。“偏差是一个挑战。它总是会在那里。但我认为解决这个问题的最佳方法是采用人员、流程和技术方法。” Chatterbox Lab 的 Coleman 是这么说的。人类在人工智能开发生命周期和偏差缓解中发挥着不可或缺的作用。但人类只是使值得信赖的人工智能成为可能的更大、集成示意图的一部分。
DataRobot 可信 AI 副总裁 Ted Kwartler 是这样说的:“在模型中发现偏差是可以的,只要它在生产之前。当你投入生产时,你就有麻烦了。”
换句话说,任何应对 AI 模型偏差挑战的解决方案都应该基于人、流程和技术的整体整合。这个三足凳的任何一个方面都不一定比另一个方面更重要。正如我们所提到的,人的判断很重要。流程为 AI 模型治理提供了秩序感和纪律感。它包括监控和纠正模型偏差,这些偏差共同帮助形成操作机器学习模型的连续步骤,有时称为“MLOps”。就技术而言,它是三足凳的第三条腿。没有它,模型(以及任何模型偏差)就不会存在。但技术也是解决方案的一部分。现在正在开发的软件平台可以帮助组织发现偏差和其他漏洞,并帮助确保模型公平运行。
4 用心前行
与利益相关者建立信任是一个多方面的复杂挑战。我们都是相连的。当与一个利益相关者的信任破裂时,其他利益相关者就会意识到并可能改变他们的行为。
人工智能和信任有着密不可分的关系。在依赖有缺陷的 AI 的环境中,信任无法蓬勃发展,即使是最公正的 AI 模型,如果它们服务于不信任的环境,也可以提供无关紧要的决策结果。组织应该考虑 AI 模型偏差的主要原因是——除了许多问题之外——偏差有可能破坏这种关系。
组织应该以这种重要问题应得的紧迫感来应对人工智能模型偏差的挑战。对某些人来说,模型偏差似乎是一种新兴的、遥远的抽象。但它是真实的。而且它可能对利益相关者的信任造成的损害是真实的,无论组织是否关注它。
但有一条前进的道路。组织拥有可用的工具和资源,可通过包括教育、通用语言和不懈意识在内的整体方法来帮助解决 AI 模型偏差的挑战。现在选择主动方法的组织可能会在以后需要采取被动方法的组织中占得先机。


