如何将知识图谱特征学习应用到推荐系统?

来源 | 微软研究院AI头条
编者按:在上周发表的“推荐算法不够精准?让知识图谱来解决”一文中,我们为大家介绍了日常生活中几乎每天都会用到的推荐系统,以及用来提高推荐系统精准性、多样性和可解释性的推荐算法辅助信息——知识图谱。今天,我们将进一步为大家讲解将知识图谱特征学习引入到推荐系统的各种思路与实现方法。
将知识图谱作为辅助信息引入到推荐系统中可以有效地解决传统推荐系统存在的稀疏性和冷启动问题,近几年有很多研究人员在做相关的工作。目前,将知识图谱特征学习应用到推荐系统中主要通过三种方式——依次学习、联合学习、以及交替学习。
依次学习(one-by-one learning)。首先使用知识图谱特征学习得到实体向量和关系向量,然后将这些低维向量引入推荐系统,学习得到用户向量和物品向量;

联合学习(joint learning)。将知识图谱特征学习和推荐算法的目标函数结合,使用端到端(end-to-end)的方法进行联合学习;

交替学习(alternate learning)。将知识图谱特征学习和推荐算法视为两个分离但又相关的任务,使用多任务学习(multi-task learning)的框架进行交替学习。

Deep Knowledge-Aware Network (DKN)
我们以新闻推荐[1]为例来介绍依次学习。如下图所示,新闻标题和正文中通常存在大量的实体,实体间的语义关系可以有效地扩展用户兴趣。然而这种语义关系难以被传统方法(话题模型、词向量)发掘。
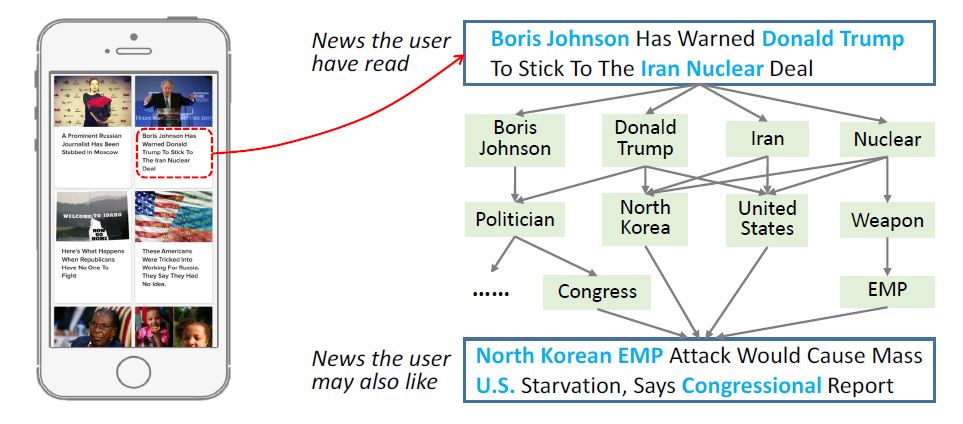
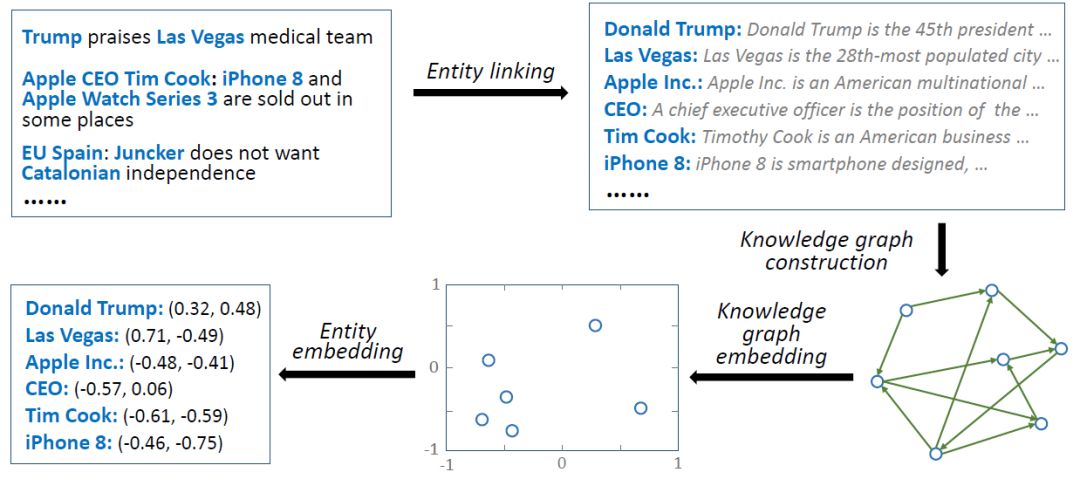
为了将知识图谱引入特征学习,遵循依次学习的框架,我们首先需要提取知识图谱特征。该步骤的方法如下:
实体连接(entity linking)。即从文本中发现相关词汇,并与知识图谱中的实体进行匹配;
知识图谱构建。根据所有匹配到的实体,在原始的知识图谱中抽取子图。子图的大小会影响后续算法的运行时间和效果:越大的子图通常会学习到更好的特征,但是所需的运行时间越长;
知识图谱特征学习。使用知识图谱特征学习算法(如TransE等)进行学习得到实体和关系向量。
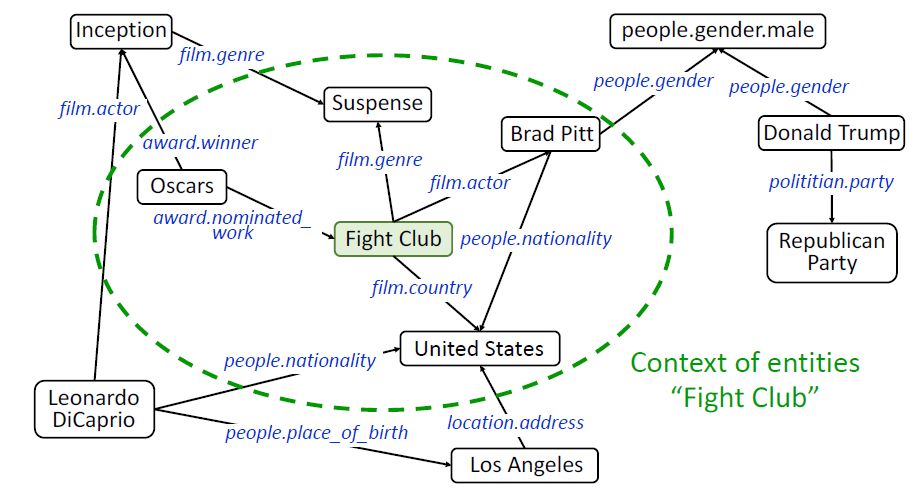
需要注意的是,为了更准确地刻画实体,我们额外地使用一个实体的上下文实体特征(contextual entity embeddings)。一个实体e的上下文实体是e的所有一跳邻居节点,e的上下文实体特征为e的所有上下文实体特征的平均值:
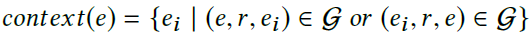
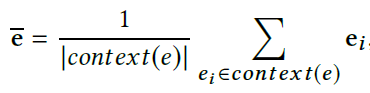
下图的绿色椭圆框内即为“Fight Club”的上下文实体。
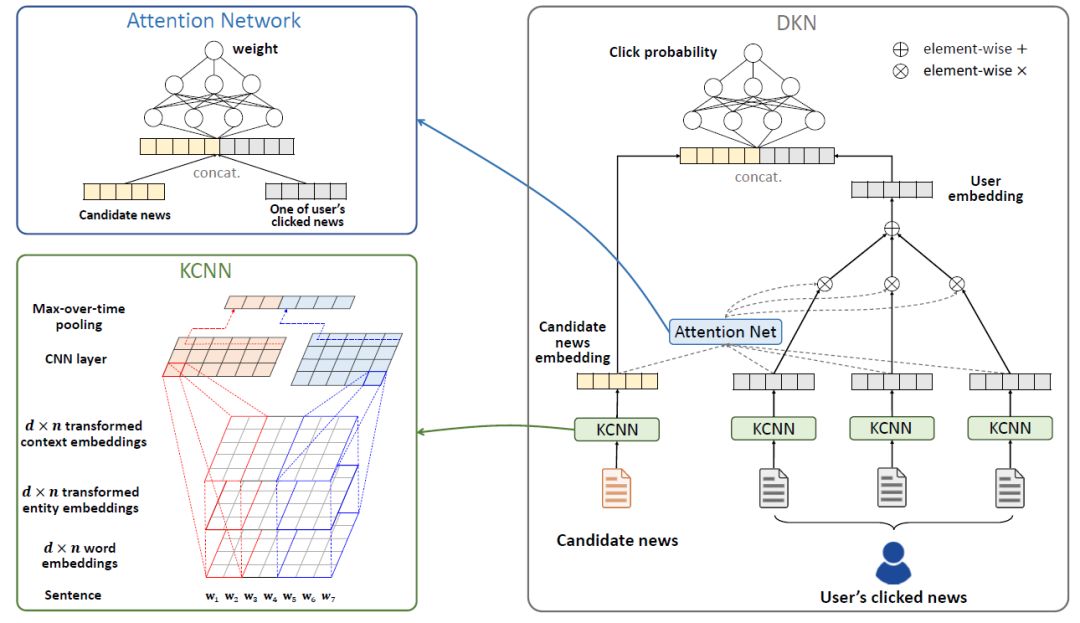
得到实体特征后,我们的第二步是构建推荐模型,该模型是一个基于CNN和注意力机制的新闻推荐算法:
基于卷积神经网络的文本特征提取:将新闻标题的词向量(word embedding)、实体向量(entity embedding)和实体上下文向量(context embedding)作为多个通道(类似于图像中的红绿蓝三通道),在CNN的框架下进行融合;
基于注意力机制的用户历史兴趣融合:在判断用户对当前新闻的兴趣时,使用注意力网络(attention network)给用户历史记录分配不同的权重。
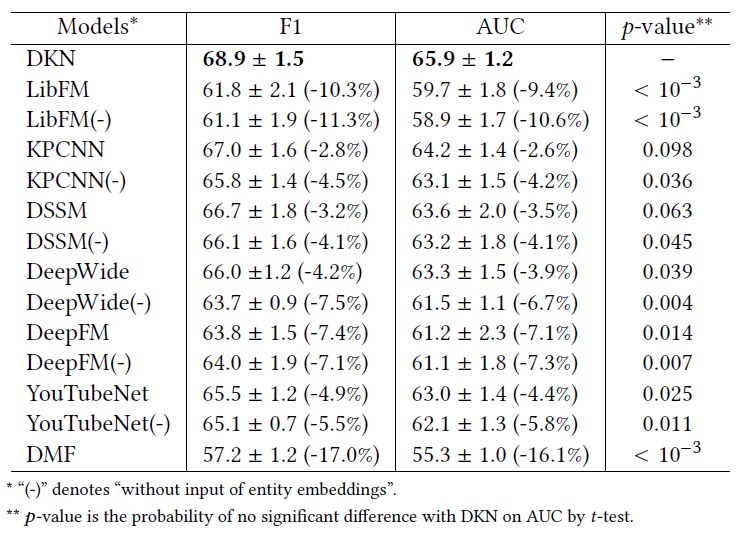
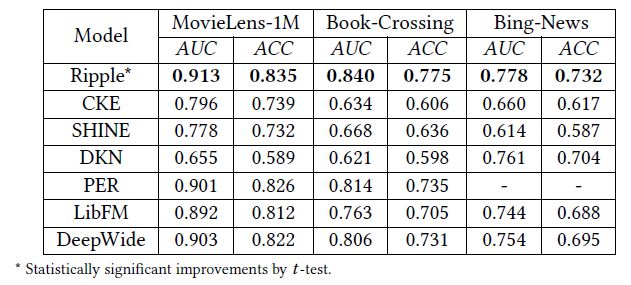
该模型在新闻推荐上取得了很好的效果:DKN取得了0.689的F1值和0.659的AUC值,并在p=0.1水平上比其它方法取得了显著的提升。
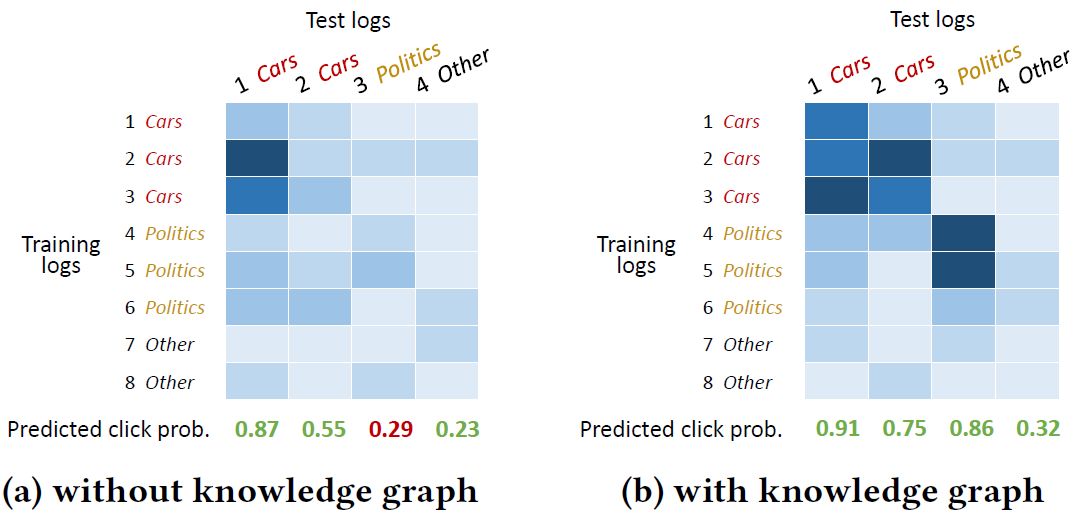
我们也可以通过注意力权重的可视化结果看出,注意力机制的引入对模型的最后输出产生了积极的影响。由于注意力机制的引入,DKN可以更好地将同类别的新闻联系起来,从而提高了最终的正确预测的数量:
依次学习的优势在于知识图谱特征学习模块和推荐系统模块相互独立。在真实场景中,特别是知识图谱很大的情况下,进行一次知识图谱特征学习的时间开销会很大,而一般而言,知识图谱远没有推荐模块更新地快。因此我们可以先通过一次训练得到实体和关系向量,以后每次推荐系统模块需要更新时都可以直接使用这些向量作为输入,而无需重新训练。
依次学习的缺点也正在于此:因为两个模块相互独立,所以无法做到端到端的训练。通常来说,知识图谱特征学习得到的向量会更适合于知识图谱内的任务,比如连接预测、实体分类等,并非完全适合特定的推荐任务。在缺乏推荐模块的监督信号的情况下,学习得到的实体向量是否真的对推荐任务有帮助,还需要通过进一步的实验来推断。
联合学习的核心是将推荐算法和知识图谱特征学习的目标融合,并在一个端到端的优化目标中进行训练。我们以CKE[2]和Ripple Network[3]为例介绍联合学习。
Collaborative Knowledge base Embedding (CKE)
在推荐系统中存在着很多与知识图谱相关的信息,以电影推荐为例:
结构化知识(structural knowledge),例如导演、类别等;
图像知识(visual knowledge),例如海报、剧照等;
文本知识(textual knowledge),例如电影描述、影评等。
CKE是一个基于协同过滤和知识图谱特征学习的推荐系统:
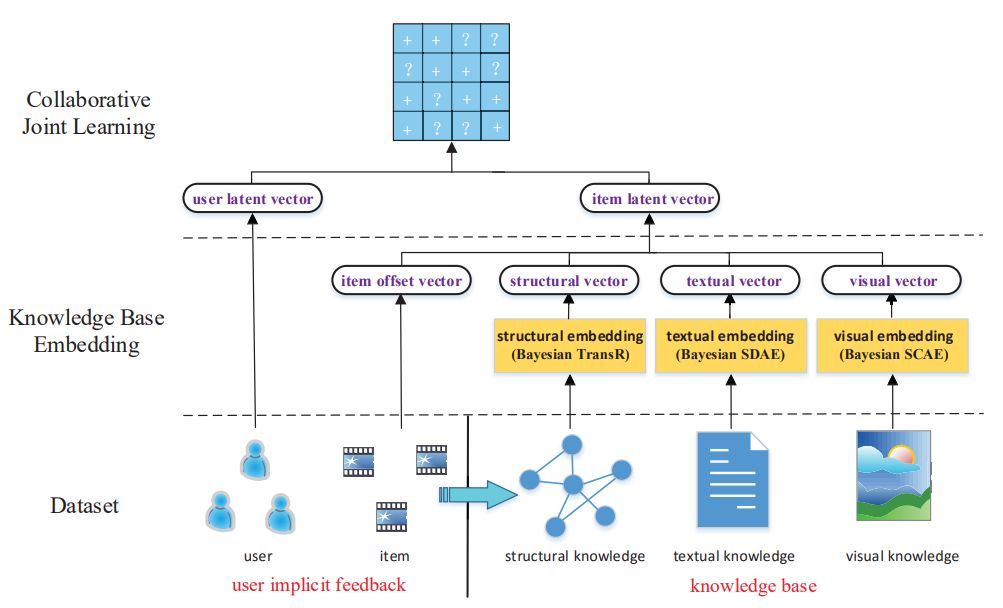
CKE使用如下方式进行三种知识的学习:
结构化知识学习:TransR。TransR是一种基于距离的翻译模型,可以学习得到知识实体的向量表示;
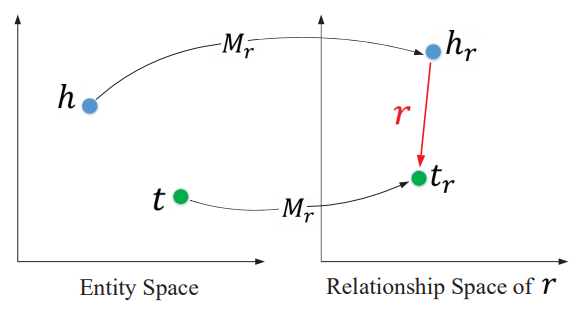
文本知识学习:去噪自编码器。去噪自编码器可以学习得到文本的一种泛化能力较强的向量表示;
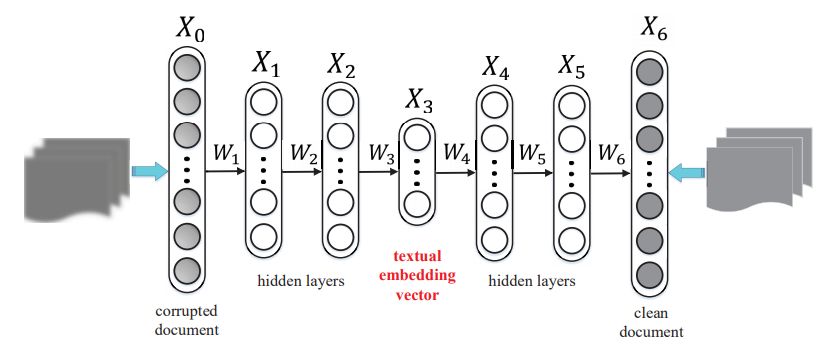
图像知识学习:卷积-反卷积自编码器。卷积-反卷积自编码器可以得到图像的一种泛化能力较强的向量表示。
我们将三种知识学习的目标函数与推荐系统中的协同过滤结合,得到如下的联合损失函数:
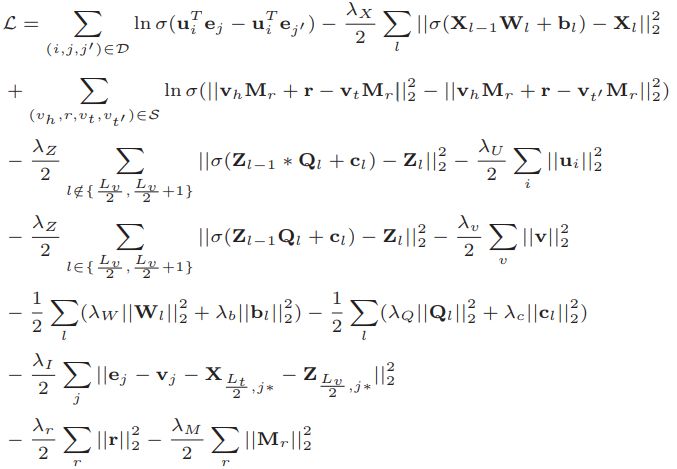
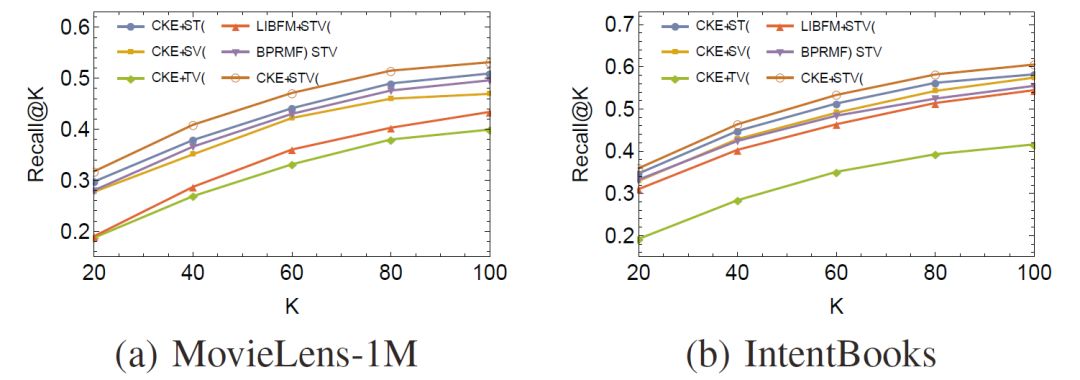
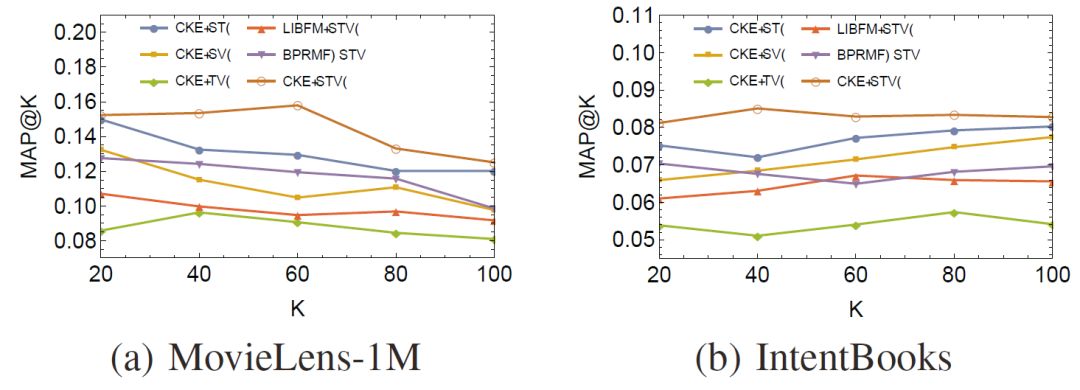
使用诸如随机梯度下降(SGD)的方法对上述损失函数进行训练,我们最终可以得到用户/物品向量,以及实体/关系向量。CKE在电影推荐和图书推荐上取得了很高的Recall值和MAP值:
Ripple Network
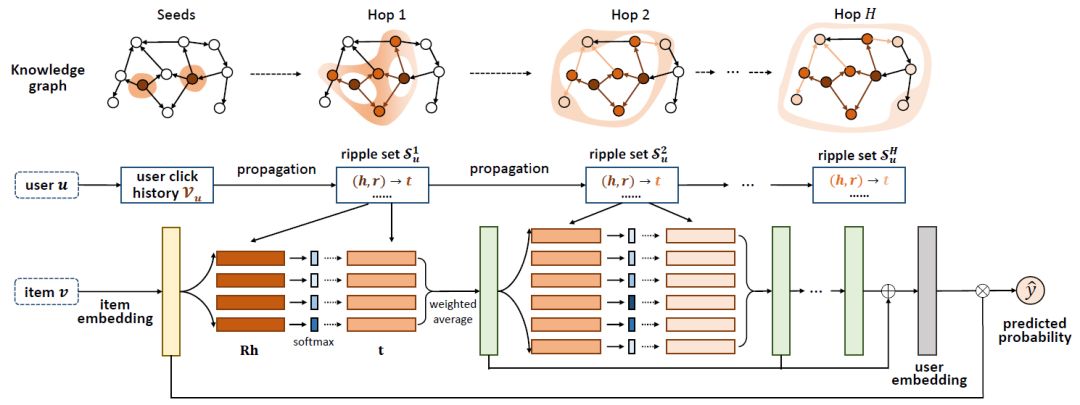
Ripple的中文翻译为“水波”,顾名思义,Ripple Network模拟了用户兴趣在知识图谱上的传播过程,整个过程类似于水波的传播:
一个用户的兴趣以其历史记录中的实体为中心,在知识图谱上向外逐层扩散;
一个用户的兴趣在知识图谱上的扩散过程中逐渐衰减。
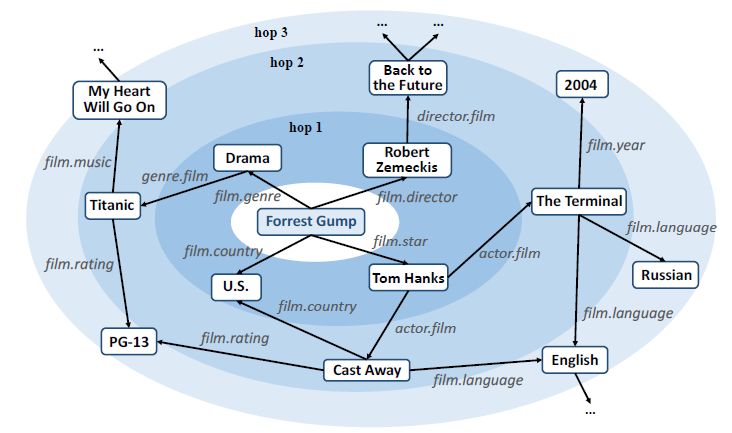
下图展示了用户兴趣在知识图谱上扩散的过程。以一个用户看过的“Forrest Gump”为中心,用户的兴趣沿着关系边可以逐跳向外扩展,并在扩展过程中兴趣强度逐渐衰减。
下图展示了Ripple Network的模型。对于给定的用户u和物品v,我们将历史相关实体集合V中的所有实体进行相似度计算,并利用计算得到的权重值对V中实体在知识图谱中对应的尾节点进行加权求和。求和得到的结果可以视为v在u的一跳相关实体中的一个响应。该过程可以重复在u的二跳、三跳相关实体中进行,如此,v在知识图谱上便以V为中心逐层向外扩散。
最终得到的推荐算法和知识图谱特征学习的联合损失函数如下:
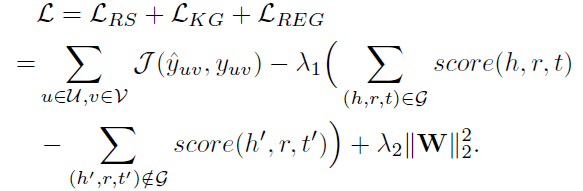
类似于CKE,我们在该损失函数上训练即可得到物品向量和实体向量。需要注意的是,Ripple Network中没有对用户直接使用向量进行刻画,而是用用户点击过的物品的向量集合作为其特征。Ripple Network在电影、图书和新闻的点击率预测上取得了非常好的效果:
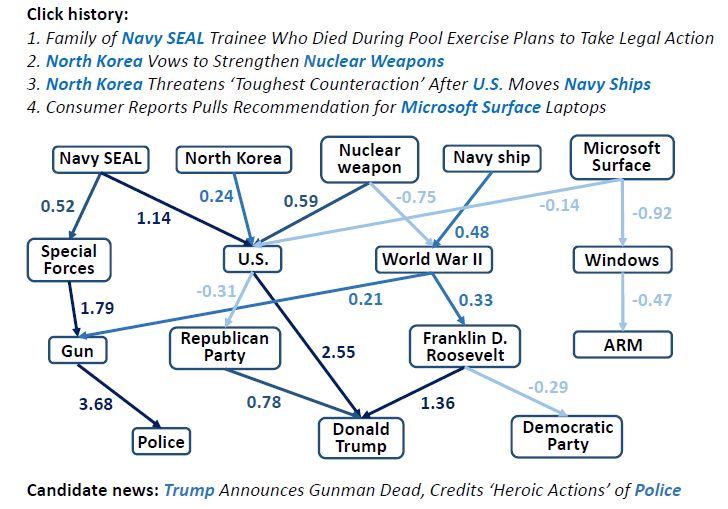
我们将Ripple Network的计算结果可视化如下。可以看出,知识图谱连接了用户的历史兴趣和推荐结果,其中的若干条高分值的路径可以视为对推荐结果的解释:
联合学习的优劣势正好与依次学习相反。联合学习是一种端到端的训练方式,推荐系统模块的监督信号可以反馈到知识图谱特征学习中,这对于提高最终的性能是有利的。但是需要注意的是,两个模块在最终的目标函数中结合方式以及权重的分配都需要精细的实验才能确定。联合学习潜在的问题是训练开销较大,特别是一些使用到图算法的模型。
Multi-task Learning for KG enhanced Recommendation (MKR)
推荐系统和知识图谱特征学习的交替学习类似于多任务学习的框架。该方法的出发点是推荐系统中的物品和知识图谱中的实体存在重合,因此两个任务之间存在相关性。将推荐系统和知识图谱特征学习视为两个分离但是相关的任务,采用多任务学习的框架,可以有如下优势:
两者的可用信息可以互补;
知识图谱特征学习任务可以帮助推荐系统摆脱局部极小值;
知识图谱特征学习任务可以防止推荐系统过拟合;
知识图谱特征学习任务可以提高推荐系统的泛化能力。
MKR[4]的模型框架如下,其中左侧是推荐任务,右侧是知识图谱特征学习任务。推荐部分使用用户和物品的特征表示作为输入,预测的点击概率作为输出。知识图谱特征学习部分使用一个三元组的头结点和关系表示作为输入,预测的尾节点表示作为输出。
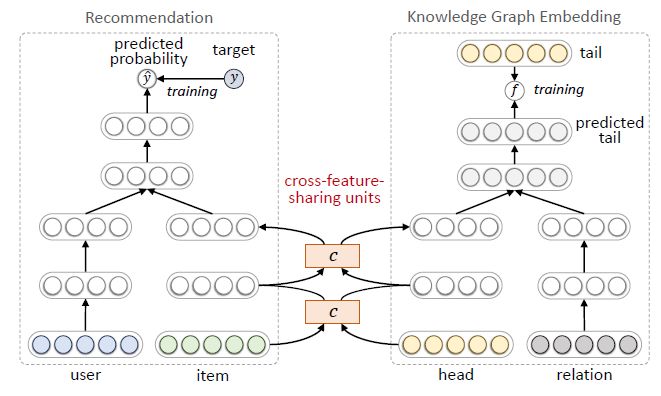
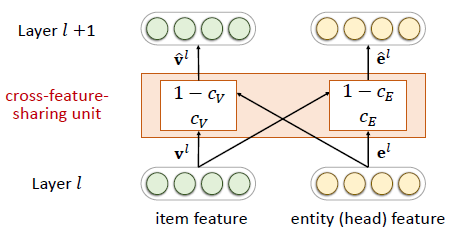
由于推荐系统中的物品和知识图谱中的实体存在重合,所以两个任务并非相互独立。我们在两个任务中设计了交叉特征共享单元(cross-feature-sharing units)作为两者的连接纽带。
交叉特征共享单元是一个可以让两个任务交换信息的模块。由于物品向量和实体向量实际上是对同一个对象的两种描述,他们之间的信息交叉共享可以让两者都获得来自对方的额外信息,从而弥补了自身的信息稀疏性的不足。
MKR的整体损失函数如下:
在实际操作中,我们采用交替训练的方式:固定推荐系统模块的参数,训练知识图谱特征学习模块的参数;然后固定知识图谱特征学习模块的参数,训练推荐系统模块的参数:

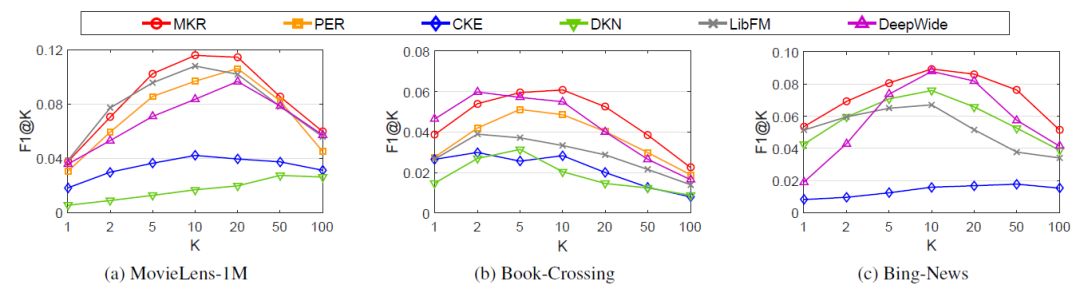
MKR在电影、图书和新闻推荐上也取得了不错的效果,其F1@K指标在绝大多数情况下都超过了baseline方法:
交替学习是一种较为创新和前沿的思路,其中如何设计两个相关的任务以及两个任务如何关联起来都是值得研究的方向。从实际运用和时间开销上来说,交替学习是介于依次学习和联合学习中间的:训练好的知识图谱特征学习模块可以在下一次训练的时候继续使用(不像联合学习需要从零开始),但是依然要参与到训练过程中来(不像依次学习中可以直接使用实体向量)。
知识图谱作为推荐系统的一种新兴的辅助信息,近年来得到了研究人员的广泛关注。未来,知识图谱和时序模型的结合、知识图谱和基于强化学习的推荐系统的结合、以及知识图谱和其它辅助信息在推荐系统中的结合等相关问题仍然值得更多的研究。欢迎感兴趣的同学通过留言与我们互动沟通。
参考文献
[1] DKN: Deep Knowledge-Aware Network for News Recommendation.
[2] Collaborative knowledge base embedding for recommender systems.
[3] Ripple Network: Propagating User Preferences on the Knowledge Graph for Recommender Systems.
[4] MKR: A Multi-Task Learning Approach for Knowledge Graph Enhanced Recommendation.
作者简介

王鸿伟,本科毕业于上海交通大学计算机科学与技术专业ACM试点班,目前为上海交通大学在读四年级博士,在微软亚洲研究院社会计算组实习。研究兴趣为网络特征学习、推荐系统、文本和社交数据挖掘,并在WWW、AAAI、WSDM、CIKM、TPDS上发表了十余篇论文。

张富峥,微软亚洲研究院研究员,从事人工智能和数据挖掘方面的研究。研究兴趣包括推荐系统、用户画像、自然语言处理等领域,在这些领域的顶级会议和期刊上发表了近30余篇论文,如KDD、WWW、Ubicomp、TIST等,曾获ICDM 2013最佳论文大奖。

谢幸,微软亚洲研究院资深研究员,中国科技大学兼职博士生导师。他的团队在数据挖掘、社会计算和普适计算等领域展开创新性的研究。他在国际会议和学术期刊上发表了200余篇学术论文,共被引用18000余次,多次在KDD、ICDM等顶级会议上获最佳论文奖。他是ACM、IEEE高级会员和计算机学会杰出会员,曾担任ACM UbiComp 2011、PCC 2012、IEEE UIC 2015、以及SMP 2017等大会程序委员会共同主席。
精彩推荐
◆
AI公开课
◆
时间:6月14日 20:00-21:00
扫描海报二维码,查看课程信息,免费报名
添加小助手微信csdnai,加入公开课交流群




