用Keras中的权值约束缓解过拟合
选自Machine Learning Mastery
作者:Jason Brownlee
机器之心编译
参与:Geek AI、张倩
权值约束为缓解深度学习神经网络模型对训练数据的过拟合、提高模型在新数据上的性能提供了一种方法。目前有多种类型的权值约束方式,比如最大向量范数和单位向量范数,其中有些方法要求用户必须配置超参数。在本教程中,作者介绍了向深度学习神经网络模型加入权值约束以缓解过拟合的 Keras API。
本教程将帮你掌握:
如何使用 Keras API 创建向量范数约束。
如何通过向一个现有的模型添加权值约束来缓解过拟合。

如何使用 Keras 中的权值约束缓解深度神经网络中的过拟合现象(图源:https://www.flickr.com/photos/31246066@N04/5907974408/)
教程大纲
本教程分为三个部分:
1. Keras 中的权值约束
2. 神经网络层上的权值约束
3. 权值约束的案例分析
Keras 中的权值约束
Keras API 支持权值约束技术。这样的权值约束是逐层指定的,但是需要在层中的每一个节点应用并执行。使用权值约束的方法通常包括在层上为输入权值设置「kernel_constraint」参数,以及为偏置的权值设置「bias_constraint」。一般来说,权值约束不会用于偏置的权重。我们可以使用一组不同的向量范数作为权值约束,Keras 在「keras.constraints module」中给出了这些方法:
最大范数(max_norm),限制权值的大小不超过某个给定的极限。
非负范数(non_neg),限制权值为正。
单位范数(unit_form),限制权值大小为 1.0。
最小最大范数(min_max_norm),限制权值大小在某个范围内。
例如,一个权值约束可以通过下面的方式被引入并实例化
# import norm
from keras.constraints import max_norm
# instantiate norm
norm = max_norm(3.0)
Weight Constraints on Layers神经网络层上的权值约束
在 Keras 中,多数层都可以使用权值范数。本章将介绍一些常见的示例。
多层感知机的权值约束
下面的例子在一个稠密全连接层中设置了一个最大范数权值约束。
# example of max norm on a dense layer
from keras.layers import Dense
from keras.constraints import max_norm
...
model.add(Dense(32, kernel_constraint=max_norm(3), bias_constraint==max_norm(3)))
...
卷积神经网络的权值约束
下面的例子在一个卷积层中设置了一个最大范数权值约束。
# example of max norm on a cnn layer
from keras.layers import Conv2D
from keras.constraints import max_norm
...
model.add(Conv2D(32, (3,3), kernel_constraint=max_norm(3), bias_constraint==max_norm(3)))
...
循环神经网络的权值约束
与其他的层类型不同,循环神经网络允许你同时针对输入权值、偏置权值以及循环输入权值设置一个权值约束。对循环权值执行的约束是通过设置这一层的「recurrent_constraint」参数实现的。
下面的示例在一个 LSTM 层上设置了一个最大范数权值约束。
# example of max norm on an lstm layer
from keras.layers import LSTM
from keras.constraints import max_norm
...
model.add(LSTM(32, kernel_constraint=max_norm(3), recurrent_constraint=max_norm(3), bias_constraint==max_norm(3)))
...相信读到这里,读者已经知道如何使用权值约束 API 了。下面将为读者展示一个有效的案例。
权值约束案例分析
在本章中,我们将展示如何在一个简单的二分类问题上使用权值约束缓解一个多层感知机的过拟合现象。
下面的例子给出了一个将权值约束应用到用于分类和回归问题的神经网络的模板。
二分类问题
本文使用了一个标准的二分类问题,它定义了两个半圆的观测数据,每一个半圆对应一个类。每个观测数据都有两个相同规模的输入变量和一个 0 或 1 的类输出值。该数据集被称为「月牙形」数据集,因为在绘制图形时,每个类别的观测数据所形成的形状都是如此。我们可以使用「make_moons()」函数为该问题生成观测数据。我们将向数据增加一些噪声,并且为随机数生成器设置了种子,从而使每次代码运行时生成的示例相同。
# generate 2d classification dataset
X, y = make_moons(n_samples=100, noise=0.2, random_state=1)
我们可以在一幅图中将数据集中的两个变量作为 x 和 y 坐标绘制出来,并用观测的颜色表示分类值的大小。
生成数据集及绘图的完整示例如下:
# generate two moons dataset
from sklearn.datasets import make_moons
from matplotlib import pyplot
from pandas import DataFrame
# generate 2d classification dataset
X, y = make_moons(n_samples=100, noise=0.2, random_state=1)
# scatter plot, dots colored by class value
df = DataFrame(dict(x=X[:,0], y=X[:,1], label=y))
colors = {0:'red', 1:'blue'}
fig, ax = pyplot.subplots()
grouped = df.groupby('label')
for key, group in grouped:
group.plot(ax=ax, kind='scatter', x='x', y='y', label=key, color=colors[key])
pyplot.show()运行该示例代码将创建一个散点图,该图会显示出每个类的半圆或月牙形的观测数据。我们可以看到这些散开的噪声使得月牙形显得没有那么明显了。
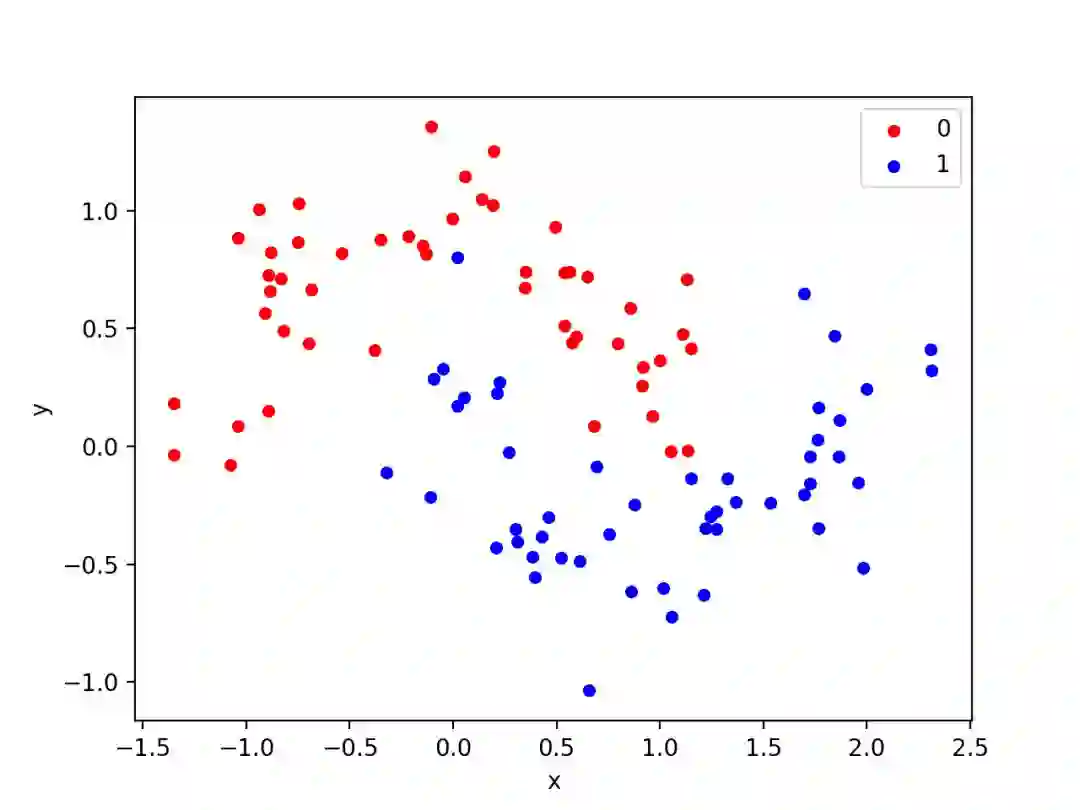
月牙形数据集的散点图,图中不同的颜色表示每个样本的类值
这是一个很好的测试问题,因为这样的类不能通过一条直线来分割,即线性不可分的情况,我们需要通过诸如神经网络这样的非线性方法来解决这个问题。
我们仅仅生成了 100 个样本,这样的样本量对于一个神经网络来说是很小的,但这恰好为在训练数据集上发生过拟合提供了机会,会在测试数据集上出现更高的误差:
这是一个使用正则化技术的绝佳场合。此外,样本中带有噪声,这让该模型有机会学习到它不能够泛化到的样本的一些特征。
过拟合的多层感知机
我们可以开发一个多层感知机模型来解决这个二分类问题。该模型将含有一个隐藏层,其中包含的节点比解决这个问题本身所需的节点要多一些,从而为过拟合提供了机会。我们还将对模型进行较长时间的训练,以确保模型过拟合。在定义模型之前,我们将把数据集分为训练集和测试集,使用 30 个示例训练模型,70 个示例评估拟合模型的性能。
# generate 2d classification dataset
X, y = make_moons(n_samples=100, noise=0.2, random_state=1)
# split into train and test
n_train = 30
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]接下来,我们可以开始定义模型了。隐藏层使用了 500 个节点,并且使用了线性整流(ReLU)函数。在输出层中使用 sigmoid 激活函数来预测类的值为 0 还是 1。该模型采用二值交叉熵损失函数进行优化,适用于二分类问题和高效的 Adam 版本的梯度下降。
# define model
model = Sequential()
model.add(Dense(500, input_dim=2, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])接着,上面定义的模型将在训练数据上进行 4000 个 epoch 的拟合,默认批大小为 32。我们还将使用测试数据集作为验证数据集进行实验。
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0)我们可以评价该模型在测试数据集上的性能,并展示实验结果。
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))最后,我们将绘制模型在每个 epoch 中在训练集和测试集上的性能曲线。如果模型确实过拟合了训练数据集,随着模型在训练数据集中学习到统计噪声,我们希望训练集的准确率直线图会持续递增,而测试集的准确率曲线则会先上升,然后再次下降。
# plot history
pyplot.plot(history.history['acc'], label='train')
pyplot.plot(history.history['val_acc'], label='test')
pyplot.legend()
pyplot.show()将以上所有部分合并在一起后,我们得到了如下所示的完整示例。
# mlp overfit on the moons dataset
from sklearn.datasets import make_moons
from keras.layers import Dense
from keras.models import Sequential
from matplotlib import pyplot
# generate 2d classification dataset
X, y = make_moons(n_samples=100, noise=0.2, random_state=1)
# split into train and test
n_train = 30
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
# define model
model = Sequential()
model.add(Dense(500, input_dim=2, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0)
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
# plot history
pyplot.plot(history.history['acc'], label='train')
pyplot.plot(history.history['val_acc'], label='test')
pyplot.legend()
pyplot.show()通过运行上面的示例,你将得到模型在训练数据集和测试数据集上的性能。
我们可以看到,该模型在训练数据集上的性能优于在测试数据集上的性能,这可能是发生过拟合的一个迹象。
由于神经网络和训练算法的随机特性,你得到的具体训练结果可能有所不同。由于模型是过拟合的,所以我们通常不会期望模型在相同数据集上重复运行得到的准确率之间有很大差异。
Train: 1.000, Test: 0.914
在训练和测试集上创建的显示模型准确率的折线图。
我们可以看到预期的过拟合模型的形状,它的准确率会增加到一个点,然后又开始下降。
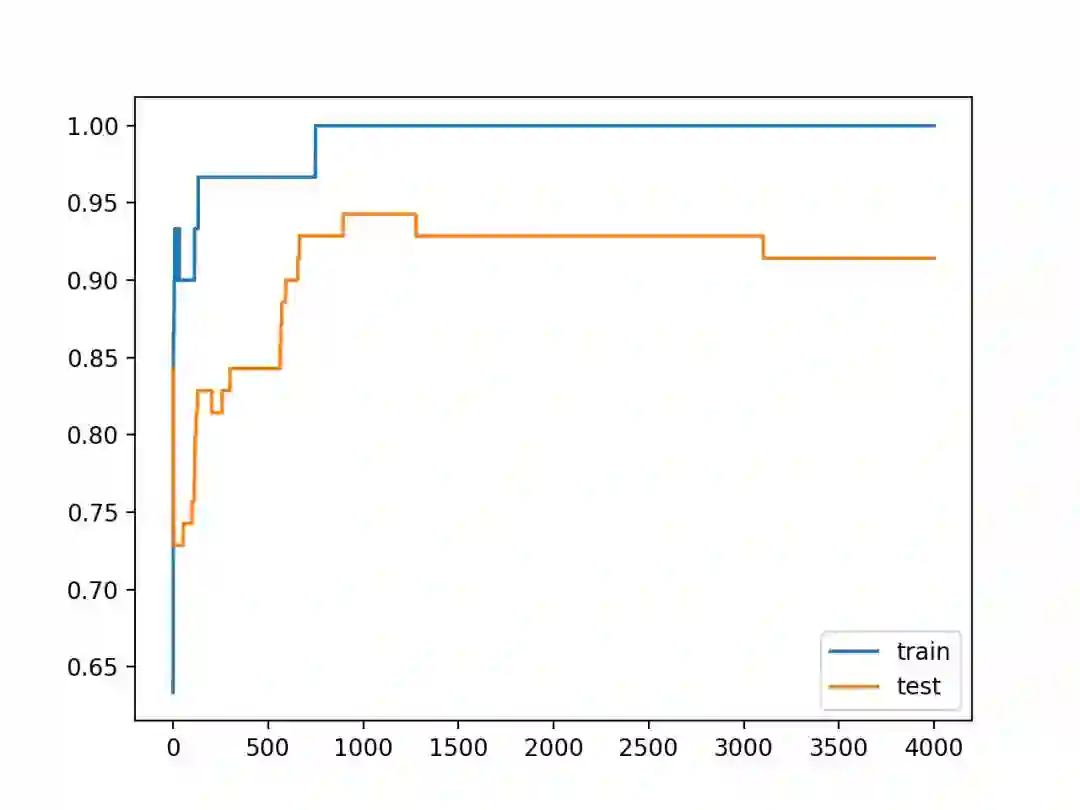
带权值约束的过拟合多层感知机
我们可以进一步更新使用权值约束的示例。有几种不同的权值约束方式可供选择。对于该模型来说,一个很好的简单约束方式就是直接归一化权值,使范数等于 1.0。这个约束的作用是迫使所有传入的权值都很小。我们可以通过使用 Keras 中的「unit_norm」来实现这一点。该约束可以通过下面的方式添加到第一个隐藏层中:
model.add(Dense(500, input_dim=2, activation='relu', kernel_constraint=unit_norm()))
我们还可以通过使用「min_max_norm」并将最小值和最大值都设为 1.0 来得到相同的结果,例如:
model.add(Dense(500, input_dim=2, activation='relu', kernel_constraint=min_max_norm(min_value=1.0, max_value=1.0)))
我们不能使用最大范数约束得到相同的结果,这是因为它允许范数取不大于某个极限的值,例如:
model.add(Dense(500, input_dim=2, activation='relu', kernel_constraint=max_norm(1.0)))
完整的带单位范数约束的新的示例如下:
# mlp overfit on the moons dataset with a unit norm constraint
from sklearn.datasets import make_moons
from keras.layers import Dense
from keras.models import Sequential
from keras.constraints import unit_norm
from matplotlib import pyplot
# generate 2d classification dataset
X, y = make_moons(n_samples=100, noise=0.2, random_state=1)
# split into train and test
n_train = 30
trainX, testX = X[:n_train, :], X[n_train:, :]
trainy, testy = y[:n_train], y[n_train:]
# define model
model = Sequential()
model.add(Dense(500, input_dim=2, activation='relu', kernel_constraint=unit_norm()))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# fit model
history = model.fit(trainX, trainy, validation_data=(testX, testy), epochs=4000, verbose=0)
# evaluate the model
_, train_acc = model.evaluate(trainX, trainy, verbose=0)
_, test_acc = model.evaluate(testX, testy, verbose=0)
print('Train: %.3f, Test: %.3f' % (train_acc, test_acc))
# plot history
pyplot.plot(history.history['acc'], label='train')
pyplot.plot(history.history['val_acc'], label='test')
pyplot.legend()
pyplot.show()
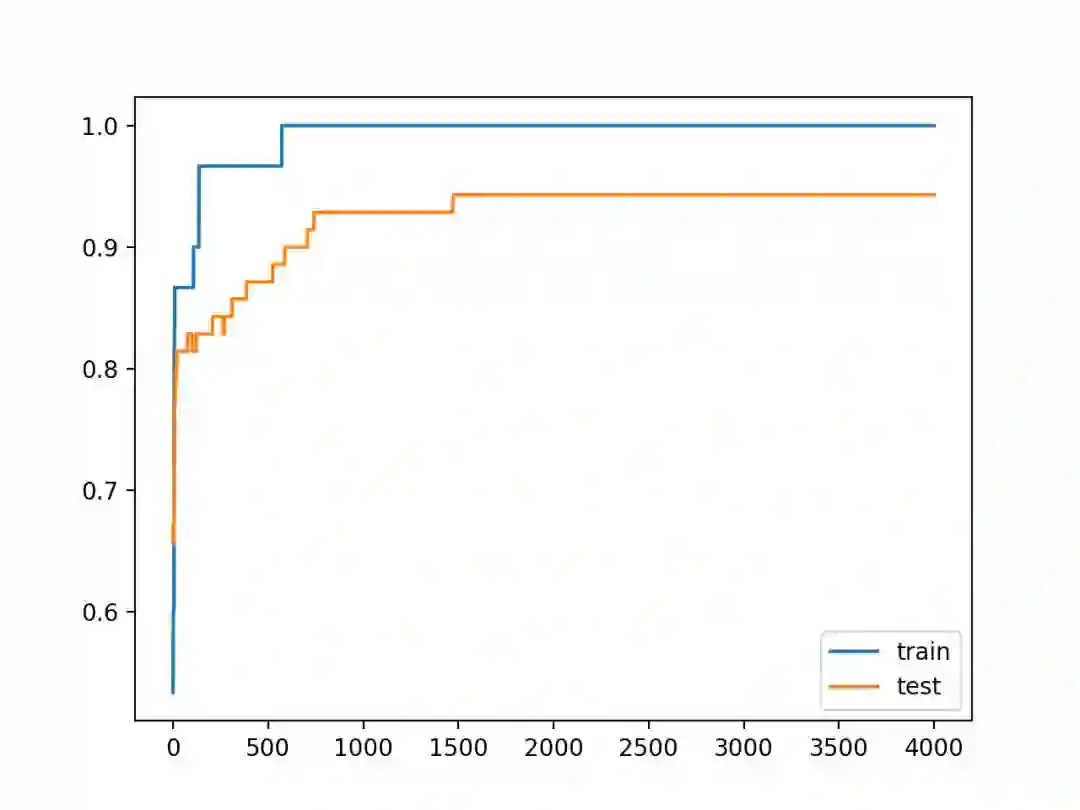
通过运行上面的示例,你将得到模型在训练数据集和测试数据集上的性能。
我们可以看到,对权值大小的严格约束确实在不影响模型在训练集上的性能的情况下提高了模型在保留(验证)集上的性能。
Train: 1.000, Test: 0.943
仔细观察训练和测试的准确率的折线图,我们可以看到,模型不再出现过拟合训练数据集的情况。
在训练集和测试集上的模型的准确率继续上升到一个稳定的水平。
扩展
本章列举出了一些扩展内容:
显示出权值范数。更新示例以计算所处网络权值的大小,并说明权值约束确实能让权值更小。
约束输出层。更新示例,向模型的输出层添加约束并比较结果。
约束偏置。更新示例,从而向偏差权值添加约束并比较结果。
多次评价。更新示例,从而对模型进行多次拟合和评价,并显示出模型性能的均值和标准差。

API
Keras Constraints API:https://keras.io/constraints/
Keras constraints.py:https://github.com/keras-team/keras/blob/master/keras/constraints.py
Keras Core Layers API:https://keras.io/layers/core/
Keras Convolutional Layers API:https://keras.io/layers/convolutional/
Keras Recurrent Layers API:https://keras.io/layers/recurrent/
sklearn.datasets.make_moons API:http://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_moons.html
原文链接:https://machinelearningmastery.com/how-to-reduce-overfitting-in-deep-neural-networks-with-weight-constraints-in-keras/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



