教程 | 如何判断LSTM模型中的过拟合与欠拟合
选自MachineLearningMastery
作者:Jason Brownlee
机器之心编译
参与:Nurhachu Null、路雪
判断长短期记忆模型在序列预测问题上是否表现良好可能是一件困难的事。也许你会得到一个不错的模型技术得分,但了解模型是较好的拟合,还是欠拟合/过拟合,以及模型在不同的配置条件下能否实现更好的性能是非常重要的。
在本教程中,你将发现如何诊断 LSTM 模型在序列预测问题上的拟合度。完成教程之后,你将了解:
如何收集 LSTM 模型的训练历史并为其画图。
如何判别一个欠拟合、较好拟合和过拟合的模型。
如何通过平均多次模型运行来开发更鲁棒的诊断方法。
让我们开始吧。
教程概览
本教程可分为以下 6 个部分,分别是:
1. Keras 中的训练历史
2. 诊断图
3. 欠拟合实例
4. 良好拟合实例
5. 过拟合实例
6. 多次运行实例
1. Keras 中的训练历史
你可以通过回顾模型的性能随时间的变化来更多地了解模型行为。
LSTM 模型通过调用 fit() 函数进行训练。这个函数会返回一个叫作 history 的变量,该变量包含损失函数的轨迹,以及在模型编译过程中被标记出来的任何一个度量指标。这些得分会在每一个 epoch 的最后被记录下来。
...
history = model.fit(...)
例如,如果你的模型被编译用来优化 log loss(binary_crossentropy),并且要在每一个 epoch 中衡量准确率,那么,log loss 和准确率将会在每一个训练 epoch 的历史记录中被计算出,并记录下来。
每一个得分都可以通过由调用 fit() 得到的历史记录中的一个 key 进行访问。默认情况下,拟合模型时优化过的损失函数为「loss」,准确率为「acc」。
...
model.com pile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X, Y, epochs=100)
print(history.history['loss'])
print(history.history['acc'])
Keras 还允许在拟合模型时指定独立的验证数据集,该数据集也可以使用同样的损失函数和度量指标进行评估。
该功能可以通过在 fit() 中设置 validation_split 参数来启用,以将训练数据分割出一部分作为验证数据集。
...
history = model.fit(X, Y, epochs=100, validation_split=0.33)
该功能也可以通过设置 validation_data 参数,并向其传递 X 和 Y 数据集元组来执行。
...
history = model.fit(X, Y, epochs=100, validation_data=(valX, valY))
在验证数据集上计算得到的度量指标会使用相同的命名,只是会附加一个「val_」前缀。
...
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(X, Y, epochs=100, validation_split=0.33)
print(history.history['loss'])
print(history.history['acc'])
print(history.history['val_loss'])
print(history.history['val_acc'])
2. 诊断图
LSTM 模型的训练历史可用于诊断模型行为。你可以使用 Matplotlib 库来进行性能的可视化,你可以将训练损失和测试损失都画出来以作比较,如下所示:
from matplotlib import pyplot
...
history = model.fit(X, Y, epochs=100, validation_data=(valX, valY))
pyplot.plot(history.history['loss'])
pyplot.plot(history.history['val_loss'])
pyplot.title('model train vs validation loss')
pyplot.ylabel('loss')
pyplot.xlabel('epoch')
pyplot.legend(['train', 'validation'], loc='upper right')
pyplot.show()
创建并检查这些图有助于启发你找到新的有可能优化模型性能的配置。
接下来,我们来看一些例子。我们将从损失最小化的角度考虑在训练集和验证集上的建模技巧。
3. 欠拟合实例
欠拟合模型就是在训练集上表现良好而在测试集上性能较差的模型。
这个可以通过以下情况来诊断:训练的损失曲线低于验证的损失曲线,并且验证集中的损失函数表现出了有可能被优化的趋势。
下面是一个人为设计的小的欠拟合 LSTM 模型。
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from matplotlib import pyplot
from numpy import array
# return training data
def get_train():
seq = [[0.0, 0.1], [0.1, 0.2], [0.2, 0.3], [0.3, 0.4], [0.4, 0.5]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((len(X), 1, 1))
return X, y
# return validation data
def get_val():
seq = [[0.5, 0.6], [0.6, 0.7], [0.7, 0.8], [0.8, 0.9], [0.9, 1.0]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((len(X), 1, 1))
return X, y
# define model
model = Sequential()
model.add(LSTM(10, input_shape=(1,1)))
model.add(Dense(1, activation='linear'))
# compile model
model.compile(loss='mse', optimizer='adam')
# fit model
X,y = get_train()
valX, valY = get_val()
history = model.fit(X, y, epochs=100, validation_data=(valX, valY), shuffle=False)
# plot train and validation loss
pyplot.plot(history.history['loss'])
pyplot.plot(history.history['val_loss'])
pyplot.title('model train vs validation loss')
pyplot.ylabel('loss')
pyplot.xlabel('epoch')
pyplot.legend(['train', 'validation'], loc='upper right')
pyplot.show()
运行这个实例会产生一个训练损失和验证损失图,该图显示欠拟合模型特点。在这个案例中,模型性能可能随着训练 epoch 的增加而有所改善。
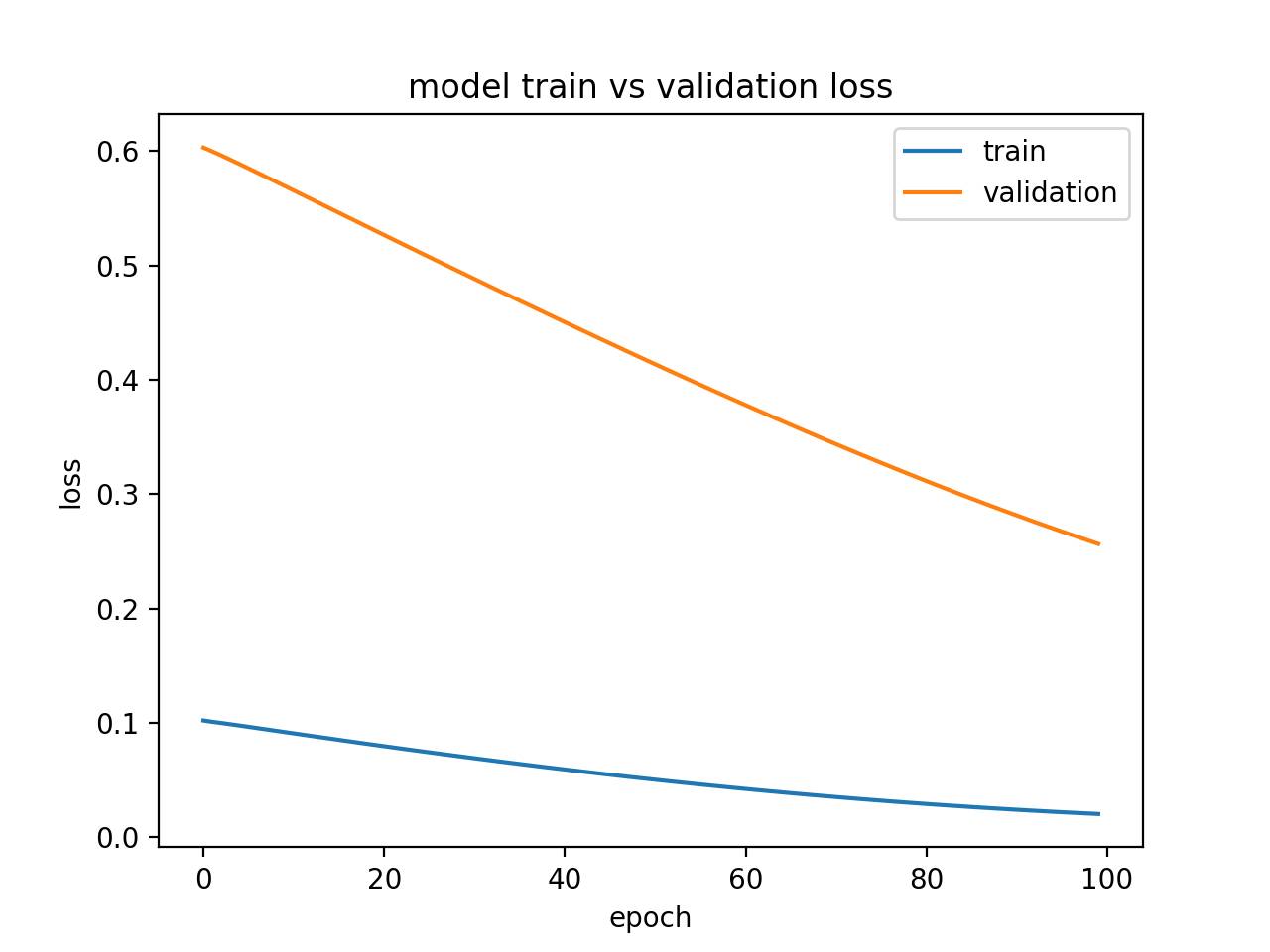
欠拟合模型的诊断图
另外,如果模型在训练集上的性能比验证集上的性能好,并且模型性能曲线已经平稳了,那么这个模型也可能欠拟合。下面就是一个缺乏足够的记忆单元的欠拟合模型的例子。
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from matplotlib import pyplot
from numpy import array
# return training data
def get_train():
seq = [[0.0, 0.1], [0.1, 0.2], [0.2, 0.3], [0.3, 0.4], [0.4, 0.5]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((5, 1, 1))
return X, y
# return validation data
def get_val():
seq = [[0.5, 0.6], [0.6, 0.7], [0.7, 0.8], [0.8, 0.9], [0.9, 1.0]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((len(X), 1, 1))
return X, y
# define model
model = Sequential()
model.add(LSTM(1, input_shape=(1,1)))
model.add(Dense(1, activation='linear'))
# compile model
model.compile(loss='mae', optimizer='sgd')
# fit model
X,y = get_train()
valX, valY = get_val()
history = model.fit(X, y, epochs=300, validation_data=(valX, valY), shuffle=False)
# plot train and validation loss
pyplot.plot(history.history['loss'])
pyplot.plot(history.history['val_loss'])
pyplot.title('model train vs validation loss')
pyplot.ylabel('loss')
pyplot.xlabel('epoch')
pyplot.legend(['train', 'validation'], loc='upper right')
pyplot.show()
运行这个实例会展示出一个存储不足的欠拟合模型的特点。
在这个案例中,模型的性能也许会随着模型的容量增加而得到改善,例如隐藏层中记忆单元的数目或者隐藏层的数目增加。
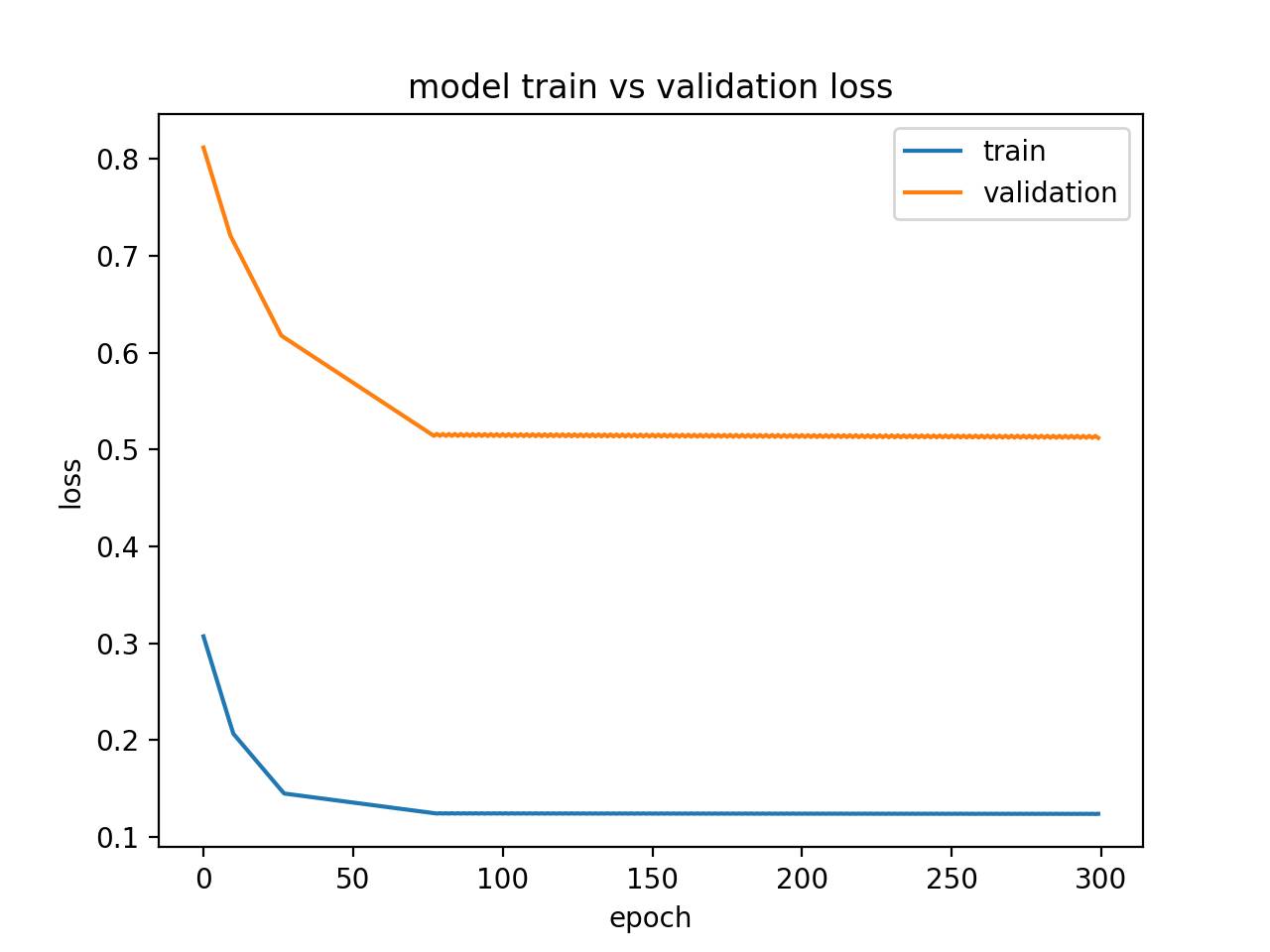
欠拟合模型的状态诊断线图
4. 良好拟合实例
良好拟合的模型就是模型的性能在训练集和验证集上都比较好。
这可以通过训练损失和验证损失都下降并且稳定在同一个点进行诊断。
下面的小例子描述的就是一个良好拟合的 LSTM 模型。
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from matplotlib import pyplot
from numpy import array
# return training data
def get_train():
seq = [[0.0, 0.1], [0.1, 0.2], [0.2, 0.3], [0.3, 0.4], [0.4, 0.5]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((5, 1, 1))
return X, y
# return validation data
def get_val():
seq = [[0.5, 0.6], [0.6, 0.7], [0.7, 0.8], [0.8, 0.9], [0.9, 1.0]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((len(X), 1, 1))
return X, y
# define model
model = Sequential()
model.add(LSTM(10, input_shape=(1,1)))
model.add(Dense(1, activation='linear'))
# compile model
model.compile(loss='mse', optimizer='adam')
# fit model
X,y = get_train()
valX, valY = get_val()
history = model.fit(X, y, epochs=800, validation_data=(valX, valY), shuffle=False)
# plot train and validation loss
pyplot.plot(history.history['loss'])
pyplot.plot(history.history['val_loss'])
pyplot.title('model train vs validation loss')
pyplot.ylabel('loss')
pyplot.xlabel('epoch')
pyplot.legend(['train', 'validation'], loc='upper right')
pyplot.show()
运行这个实例可以创建一个线图,图中训练损失和验证损失出现重合。
理想情况下,我们都希望模型尽可能是这样,尽管面对大量数据的挑战,这似乎不太可能。
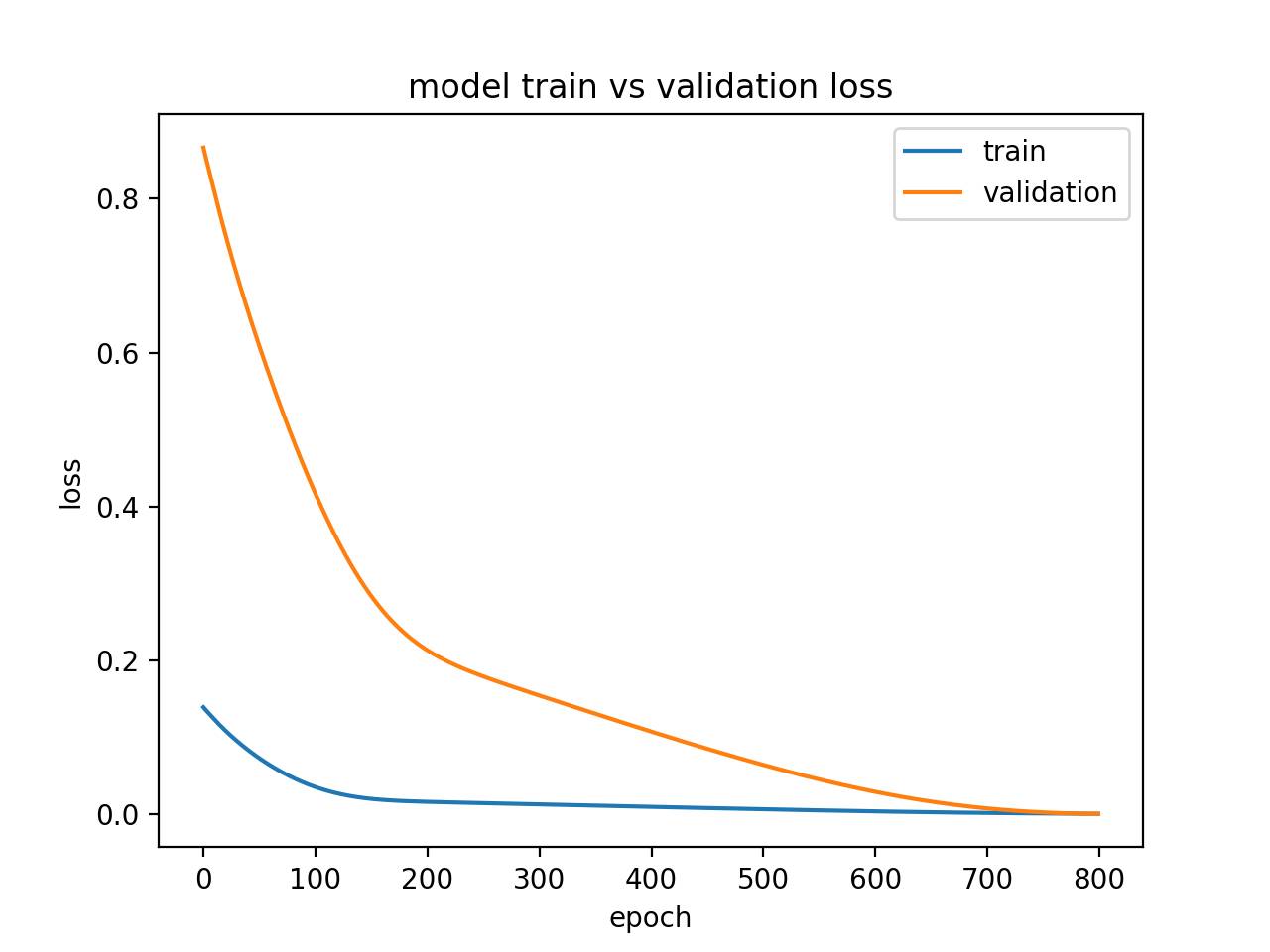
良好拟合模型的诊断线图
5. 过拟合实例
过拟合模型即在训练集上性能良好且在某一点后持续增长,而在验证集上的性能到达某一点然后开始下降的模型。
这可以通过线图来诊断,图中训练损失持续下降,验证损失下降到拐点开始上升。
下面这个实例就是一个过拟合 LSTM 模型。
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from matplotlib import pyplot
from numpy import array
# return training data
def get_train():
seq = [[0.0, 0.1], [0.1, 0.2], [0.2, 0.3], [0.3, 0.4], [0.4, 0.5]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((5, 1, 1))
return X, y
# return validation data
def get_val():
seq = [[0.5, 0.6], [0.6, 0.7], [0.7, 0.8], [0.8, 0.9], [0.9, 1.0]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((len(X), 1, 1))
return X, y
# define model
model = Sequential()
model.add(LSTM(10, input_shape=(1,1)))
model.add(Dense(1, activation='linear'))
# compile model
model.compile(loss='mse', optimizer='adam')
# fit model
X,y = get_train()
valX, valY = get_val()
history = model.fit(X, y, epochs=1200, validation_data=(valX, valY), shuffle=False)
# plot train and validation loss
pyplot.plot(history.history['loss'][500:])
pyplot.plot(history.history['val_loss'][500:])
pyplot.title('model train vs validation loss')
pyplot.ylabel('loss')
pyplot.xlabel('epoch')
pyplot.legend(['train', 'validation'], loc='upper right')
pyplot.show()
运行这个实例会创建一个展示过拟合模型在验证集中出现拐点的曲线图。
这也许是进行太多训练 epoch 的信号。
在这个案例中,模型会在拐点处停止训练。另外,训练样本的数目可能会增加。
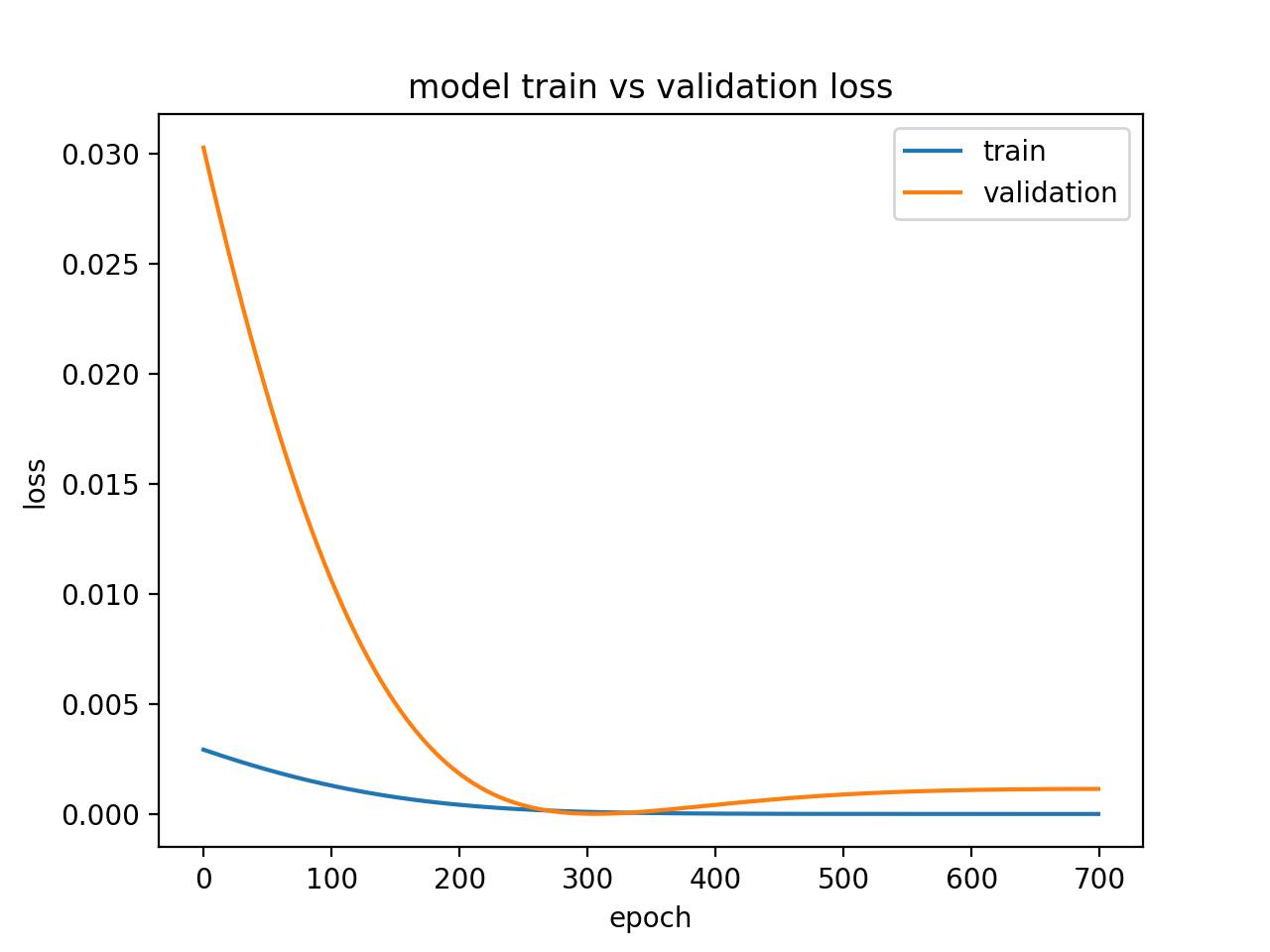
过拟合模型的诊断线图
6. 多次运行实例
LSTM 是随机的,这意味着每次运行时都会得到一个不同的诊断图。
多次重复诊断运行很有用(如 5、10、30)。每次运行的训练轨迹和验证轨迹都可以被绘制出来,以更鲁棒的方式记录模型随着时间的行为轨迹。
以下实例多次运行同样的实验,然后绘制每次运行的训练损失和验证损失轨迹。
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from matplotlib import pyplot
from numpy import array
from pandas import DataFrame
# return training data
def get_train():
seq = [[0.0, 0.1], [0.1, 0.2], [0.2, 0.3], [0.3, 0.4], [0.4, 0.5]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((5, 1, 1))
return X, y
# return validation data
def get_val():
seq = [[0.5, 0.6], [0.6, 0.7], [0.7, 0.8], [0.8, 0.9], [0.9, 1.0]]
seq = array(seq)
X, y = seq[:, 0], seq[:, 1]
X = X.reshape((len(X), 1, 1))
return X, y
# collect data across multiple repeats
train = DataFrame()
val = DataFrame()
for i in range(5):
# define model
model = Sequential()
model.add(LSTM(10, input_shape=(1,1)))
model.add(Dense(1, activation='linear'))
# compile model
model.compile(loss='mse', optimizer='adam')
X,y = get_train()
valX, valY = get_val()
# fit model
history = model.fit(X, y, epochs=300, validation_data=(valX, valY), shuffle=False)
# story history
train[str(i)] = history.history['loss']
val[str(i)] = history.history['val_loss']
# plot train and validation loss across multiple runs
pyplot.plot(train, color='blue', label='train')
pyplot.plot(val, color='orange', label='validation')
pyplot.title('model train vs validation loss')
pyplot.ylabel('loss')
pyplot.xlabel('epoch')
pyplot.show()
从下图中,我们可以在 5 次运行中看到欠拟合模型的通常趋势,该案例强有力地证明增加训练 epoch 次数的有效性。
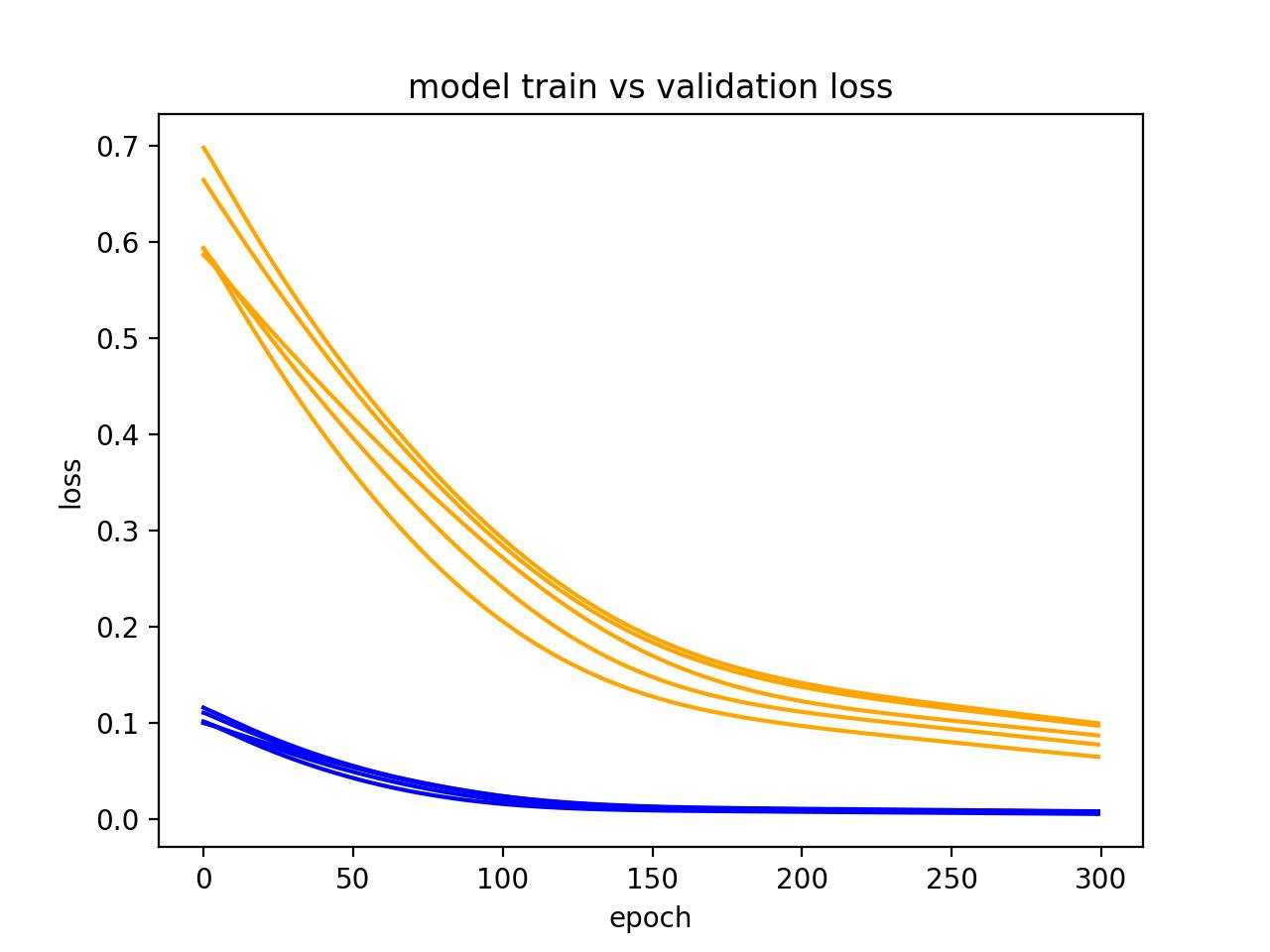
模型多次运行的诊断线图
扩展阅读
如果你想更深入地了解这方面的内容,这一部分提供了更丰富的资源。
Keras 的历史回调 API(History Callback Keras API,https://keras.io/callbacks/#history)
维基百科中关于机器学习的学习曲线(Learning Curve in Machine Learning on Wikipedia,https://en.wikipedia.org/wiki/Learning_curve#In_machine_learning)
维基百科上关于过拟合的描述(Overfitting on Wikipedia,https://en.wikipedia.org/wiki/Overfitting)
总结
在本教程中,你学习到如何在序列预测问题上诊断 LSTM 模型是否拟合。
具体而言,你学到了:
如何收集 LSTM 模型的训练历史并为其画图。
如何判别一个欠拟合、良好拟合和过拟合的模型。
如何通过平均多次模型运行来开发更鲁棒的诊断方法。
原文链接:https://machinelearningmastery.com/diagnose-overfitting-underfitting-lstm-models/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com





