几条腿都能走!迪士尼另辟蹊径,将深度学习直接用于实体机器人

前言
通常我们所见的深度学习都是在模拟环境中实现的,而迪士尼研究院的科学家们最近将深度学习应用到了实体机器人上,并创建了一个自动学习环境,可以直接将控制策略应用到实体机器人上。

说的就是上面这个机器人,是一个模块化有腿的机器人,是不是有点像蜘蛛~
有一种生物叫长脚蜘蛛,当它们遇到敌人时,会自动伸出脚,过一段时间后又会恢复行走速度和转向控制。其实在自然界中,很多生物都能根据环境做出适应性动作,即使不会自动变化,很多生物也会在改变身体结构之后调整动作姿态,这都是长期学习适应的结果。
而今天这个实验就是研究人员将生物的这种学习运动的技巧应用到了这个机器人身上~
1
实验概述
迪士尼研究院的研究者们提出了一种自动学习环境,直接在模块化有腿机器人上建立控制策略。这一环境通过计算奖励促进了强化学习过程,计算过程是利用基于视觉的追踪系统和将机器人重新放回原位的重置系统进行的。
实验人员应用了两种先进的深度学习算法——Trust Region Policy Optimization(TRPO)和Deep Deterministic Policy Gradient(DDPG),这两种算法可以训练神经网络做简单的前进和爬行动作。利用搭建好的环境,上述两种算法都能在高度随机的硬件和环境条件下有效学习简单的运动策略。实验人员将这种学习迁移到了模块化有腿机器人上。
2
实验装置
实验所用机器人:

这个机器人是可以灵活拆卸的,中间的本体呈六边形,每一面都可以利用磁铁吸附上一条“机械腿”,不过在本实验中最多用到了三条腿。这三条腿分别可以实现不同的前进方向。

A腿运动方向:横轴+纵轴。
☟

B腿运动方向:竖轴+纵轴。
☟

C腿运动方向:横轴+竖轴+纵轴。
☟

那么问题来了,如果按最多能装六条腿来算,一共可以拼出多少种不同的机器人呢?
A、B、C三种腿型的结果如图:
☟
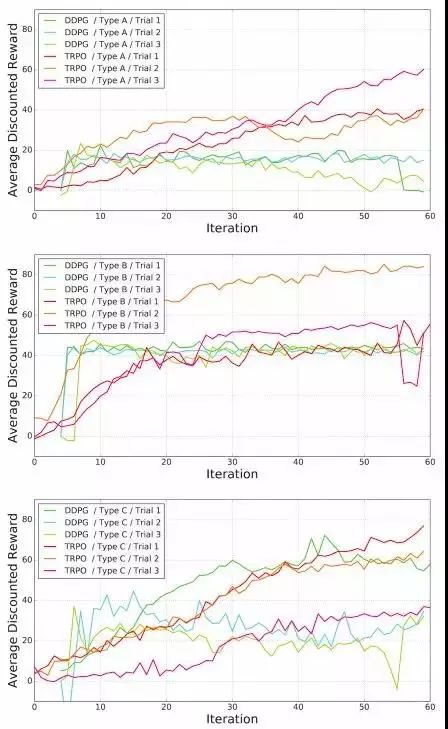
可以看出,TRPO和DDPG两种算法都能成功地在硬件上进行训练,同时表现得要比其他手动设计的步态好。
实验环境布局:
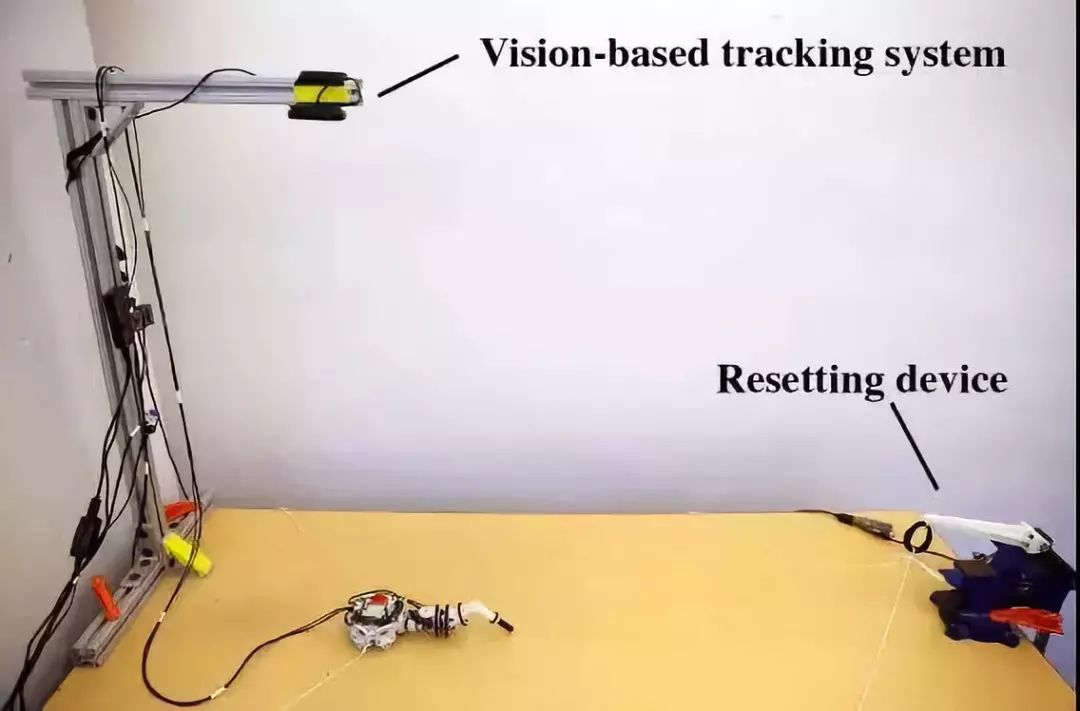
环境主要由两部分组成:视觉追踪系统和重置装置。视觉系统用到了摄像头,它追踪的是机器人身上的绿色和红色两个点,从而重现全局的位置并为机器人导航。
重置装置是用来让机器人复位的。实验人员用只有一个自由度的杠杆结构就可以将机器人拉回到初始位置。两个1.5m长的线分别连接机器人本体上的两点。
环境布局好后,研究人员将控制问题用部分可观察马尔科夫决策过程(POMDP)表示,它可以用无法观察到的状态变量来解释决策问题。具体的数学公式大家可以参考原论文。
3
算法的学习
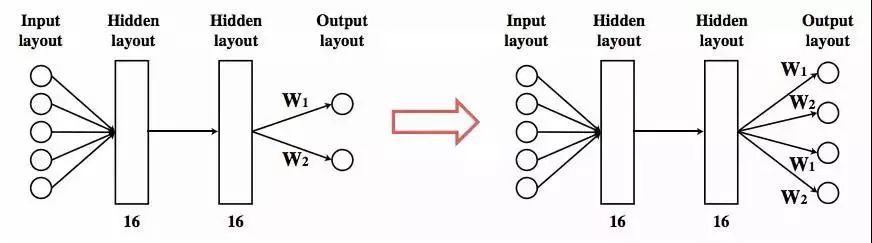
模型的策略用一个神经网络表示,该网络由两个完全连接的隐藏层组成,每层有16个活动神经元。研究人员设想当在单腿机器人上训练好策略,他们也许就能将所学到的知识转移到多腿机器人上。假设所有的腿都有同样的接头形状,那么就可以通过复制输出神经元和对应的链接进行多腿运动。
实验结果:
不看视频或想看详细解析的朋友请看下边内容~
在本实验中,研究人员主要研究了两个问题:
目前最先进的深度强化学习算法能否直接在硬件上训练策略?
我们能否通过迁移策略将学习转化到复杂场景中?
首先是一条腿训练
图中下面那条腿是用TRPO学习完毕的A腿,与上面的A腿相比,前进姿势有所不同,速度也快了一点点。

两条腿训练
下图是两条在Trust Region Policy Optimization(TRPO)深度学习算法下的B腿,爬着前进。

下图是两条在Deep Deterministic Policy Gradient(DDPG)深度学习算法下的B腿,好像是要向前翻还没翻过去。

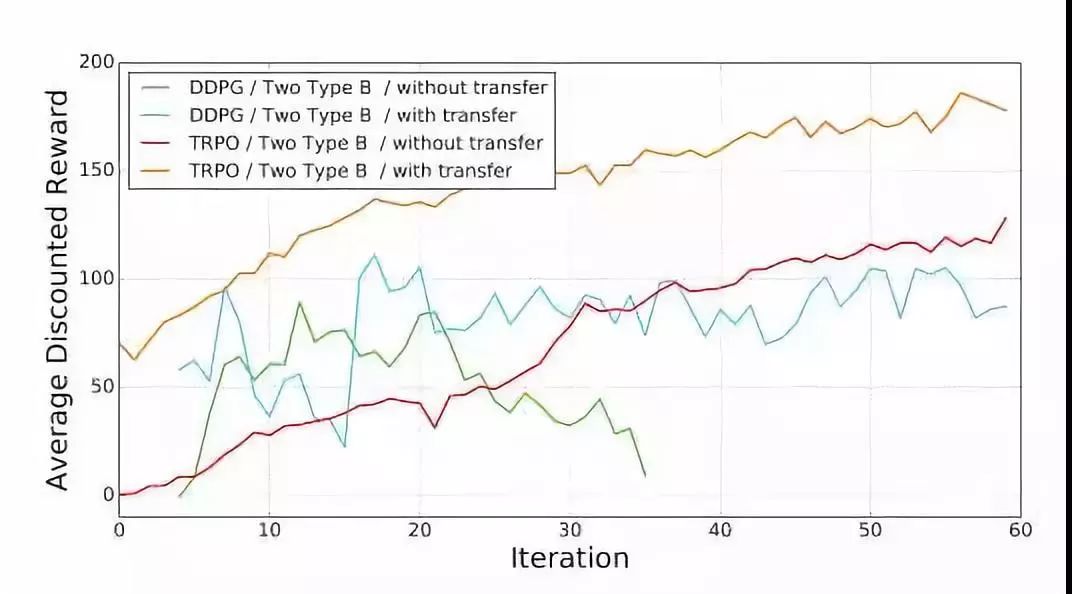
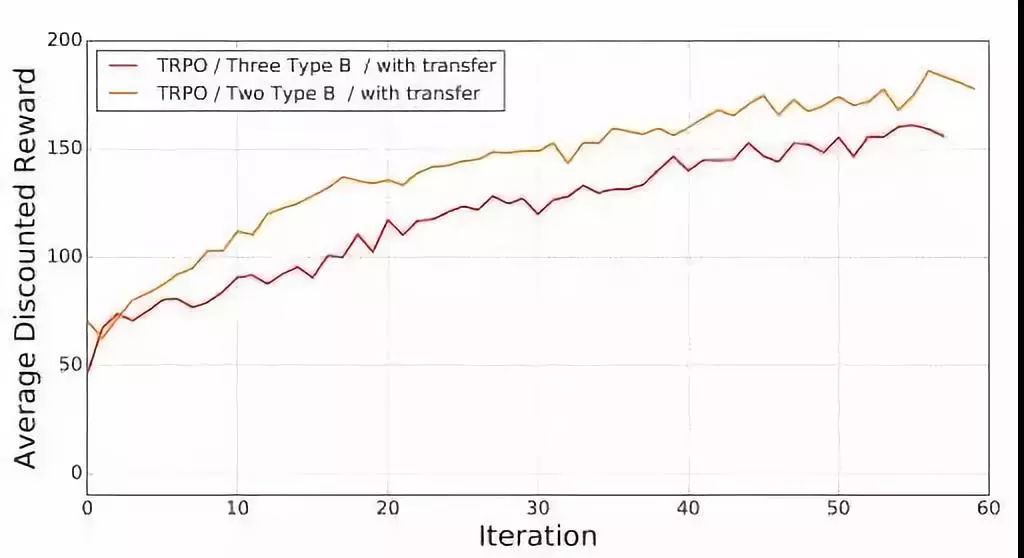
下图为B腿关于两种算法在迁移学习和无迁移下的表现,结果符合预期,迁移学习能作为一个很好地初始解决方案。
三条腿训练
看起来有蜘蛛的雏形了,扑腾着向前爬,有了TRPO和DDPG两种算法的加持,好像要挣脱束缚,欢快前行了~

结果显示中间的那条腿作用并不大。
4
结语
由于传感器能力有限,实验人员在仅对简单的开环爬行运动进行了测试。如果有更复杂的控制器和奖励,预计会得到更为复杂的行为。例如,可以用基于IMU的反馈控制器训练机器人走路或跑步;可以用深度相机收集机器人的高度,当它们从爬行转变成走路时给予奖励。
另外,虽然研究者展示了迁移学习在初始策略上的重要作用,但都是应用在相同种类的腿上,动作也都类似。未来,他们计划将动作分解成不同难度水平,应用于不同任务上。
追踪系统也会出现bug,当机器人挡住标记时会对其位置进行误判。虽然这不会对本实验的机器人造成损坏,但是对于体型庞大的机器人却很危险。所以,想在硬件系统上进行直接学习或许也需要传统算法的帮助,保证机器人的安全。
论文地址:
https://s3-us-west-1.amazonaws.com/disneyresearch/wp-content/uploads/20180625141830/Automated-Deep-Reinforcement-Learning-Environment-for-Hardware-of-a-Modular-Legged-Robot-Paper.pdf

工程院院士 蔡鹤皋丨北航教授 文力丨深醒科技 袁培江丨深之篮 魏建仓
一飞智控丨深醒科技丨发那科丨柔宇科技丨优傲机器人丨宇树科技丨臻迪科技丨iRobot
①工业 缝纫机器人丨无人智能采矿机器人丨中国饺子生产线自动化车间丨MIT 建筑机器人
②服务 索尼机器狗 Aibos丨叠衣机器人 FoldiMate丨日本 骑自行车机器人丨有触觉机械手 LUKE丨达芬奇机器人丨机器人乐队丨空中飞车丨日本护理机器人合集
③特种 丰田人形机器人丨水下机器人 探索号丨俄罗斯人形机器人 FEDOR丨美国重型机械 Guardian GT丨波士顿动Atlas 360度后空翻丨中国四足机器人 Laikago丨北理工 四轮足机器人丨佛罗里达研究院 “机械鸵鸟
④仿生 3D打印 仿生机器人 丨东京大学 流汗人形机器人丨柔性电池丨哈佛 柔软肌肉丨哈佛丨哈佛 RoboBee
英特尔 宋继强博士 | 中民国际 刘国清丨陈小平教授 |驭势科技 姜岩丨浙大 熊蓉教授|长江学者 孙立宁丨上海大学 无人艇专家团|新松总裁 曲道奎丨北航 王田苗教授|863专家 李铁军教授丨北邮 刘伟教授|清华 邓志东教授丨清华 孙富春教授|天津大学博导 齐俊桐丨哈工大 杜志江教授|长江学者 王树新丨甘中学教授 | 硅谷创客 赵胜
意向合作,文章转载, 均可联系堂博士
商务合作:13810423387(同微信)
内容合作:15611695072(同微信)





