深度学习面试100题(第66-70题)

点击上方蓝字关注

深度学习面试100题(第66-70题)

66
下图是一个利用sigmoid函数作为激活函数的含四个隐藏层的神经网络训练的梯度下降图。这个神经网络遇到了梯度消失的问题。下面哪个叙述是正确的?
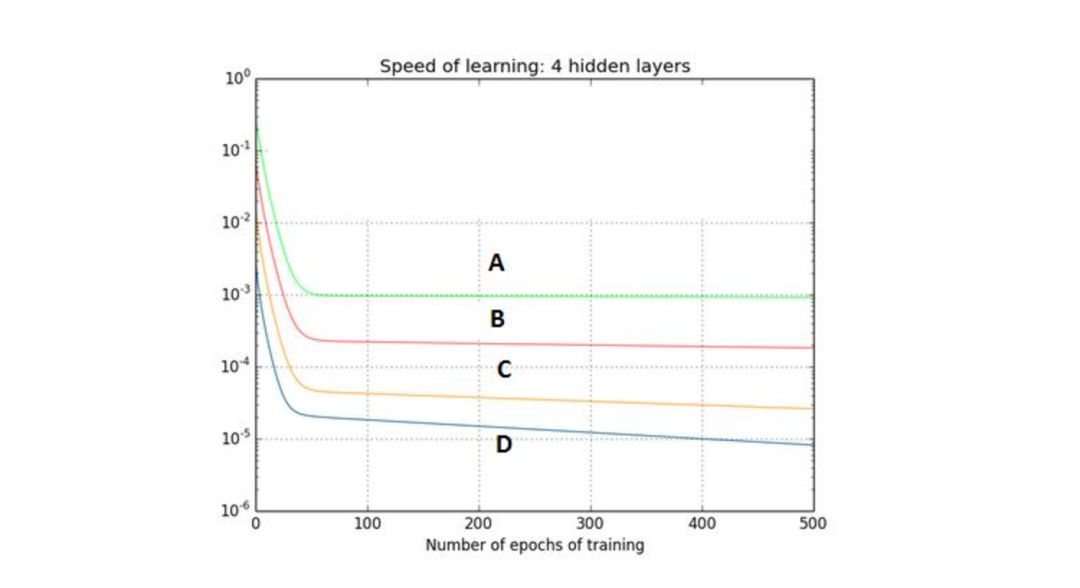
A、第一隐藏层对应D,第二隐藏层对应C,第三隐藏层对应B,第四隐藏层对应A
B、第一隐藏层对应A,第二隐藏层对应C,第三隐藏层对应B,第四隐藏层对应D
C、第一隐藏层对应A,第二隐藏层对应B,第三隐藏层对应C,第四隐藏层对应D
D、第一隐藏层对应B,第二隐藏层对应D,第三隐藏层对应C,第四隐藏层对应A
正确答案是:A
解析:
由于反向传播算法进入起始层,学习能力降低,这就是梯度消失。换言之,梯度消失是梯度在前向传播中逐渐减为0, 按照图标题所说, 四条曲线是4个隐藏层的学习曲线, 那么第一层梯度最高(损失函数曲线下降明显), 最后一层梯度几乎为零(损失函数曲线变成平直线). 所以D是第一层, A是最后一层。

67
考虑某个具体问题时,你可能只有少量数据来解决这个问题。不过幸运的是你有一个类似问题已经预先训练好的神经网络。可以用下面哪种方法来利用这个预先训练好的网络?
A、把除了最后一层外所有的层都冻结,重新训练最后一层
B、对新数据重新训练整个模型
C、只对最后几层进行调参(fine tune)
D、对每一层模型进行评估,选择其中的少数来用
正确答案是:C
解析:
如果有个预先训练好的神经网络, 就相当于网络各参数有个很靠谱的先验代替随机初始化. 若新的少量数据来自于先前训练数据(或者先前训练数据量很好地描述了数据分布, 而新数据采样自完全相同的分布), 则冻结前面所有层而重新训练最后一层即可; 但一般情况下, 新数据分布跟先前训练集分布有所偏差, 所以先验网络不足以完全拟合新数据时, 可以冻结大部分前层网络, 只对最后几层进行训练调参(这也称之为fine tune)。

68
在选择神经网络的深度时,下面哪些参数需要考虑?
1 神经网络的类型(如MLP,CNN)
2 输入数据
3 计算能力(硬件和软件能力决定)
4 学习速率
5 映射的输出函数
A、1,2,4,5
B、2,3,4,5
C、都需要考虑
D、1,3,4,5
正确答案是:C
解析:
所有上述因素对于选择神经网络模型的深度都是重要的。特征抽取所需分层越多, 输入数据维度越高, 映射的输出函数非线性越复杂, 所需深度就越深. 另外为了达到最佳效果, 增加深度所带来的参数量增加, 也需要考虑硬件计算能力和学习速率以设计合理的训练时间。

69
当数据过大以至于无法在RAM中同时处理时,哪种梯度下降方法更加有效?
A、随机梯度下降法(Stochastic Gradient Descent)
B、不知道
C、整批梯度下降法(Full Batch Gradient Descent)
D、都不是
正确答案是:A
解析:
梯度下降法分随机梯度下降(每次用一个样本)、小批量梯度下降法(每次用一小批样本算出总损失, 因而反向传播的梯度折中)、全批量梯度下降法则一次性使用全部样本。这三个方法, 对于全体样本的损失函数曲面来说, 梯度指向一个比一个准确. 但是在工程应用中,受到内存/磁盘IO的吞吐性能制约, 若要最小化梯度下降的实际运算时间, 需要在梯度方向准确性和数据传输性能之间取得最好的平衡. 所以, 对于数据过大以至于无法在RAM中同时处理时, RAM每次只能装一个样本, 那么只能选随机梯度下降法。

70
当在卷积神经网络中加入池化层(pooling layer)时,变换的不变性会被保留,是吗?
A、不知道
B、看情况
C、是
D、否
正确答案是:C
解析:
池化算法比如取最大值/取平均值等, 都是输入数据旋转后结果不变, 所以多层叠加后也有这种不变性。

题目来源:七月在线官网(https://www.julyedu.com/)——面试题库——笔试练习——深度学习
福利时刻:为了帮助大家更多的学习深度学习课程的相关知识,我们特意推出了深度学习系列课程。

更多资讯
请戳一戳


往期精选
人工智能 | AI人才薪酬是什么水平?看完惊呆了!
面试大题 | 教你如何迅速秒杀掉:99%的海量数据处理面试题
干货合集 | 推荐系统算法合集,满满都是干货(建议收藏)
分享一哈 | 机器学习13种算法的优缺点,你都知道哪些?

点击“阅读原文”,可在线报名




