前沿 | 看图聊天的骚操作,MIT开发精准到单词的语音-图像配对系统
作者:Rob Matheson 来源:news.mit,机器之心
MIT 计算机科学家开发了一个系统,可以根据有关图像的语音描述学习识别、定位、检索其中的目标。给定一幅图像和一份语音描述,模型就能实时找出图像中与特定词汇描述相符的相关区域,这样配置了该功能的语音助手也能跟你一起分享看照片的心情了。该方法有望应用于无监督双语翻译,相关论文发表在 ECCV2018 上。
与当前语音识别技术不同,该模型不需要人工转录和注释其所训练的例子,而是直接从原图像的录音片段和目标中学习词汇,然后建立它们之间的联系。

图 1:模型的输入:图像和语音波形的配对。
该模型现在只能识别几百个单词和物体类型,但研究人员希望这一「语音-目标」组合识别技术将来能够为人类节省很多时间,同时为语音和图像识别技术打开新的大门。
语音识别系统(如 Siri)需要转录几千个小时的录音。该系统使用这些数据学会匹配语音信号与特定词汇。如果有新词加入词典,这种方法就不好用了,而且系统必须重新训练。
「我们想用一种更自然的方式做语音识别,利用人类便于使用的额外信号和信息,但机器学习算法通常无法利用这些信息。我们训练模型的方法类似于让一个小孩走过一个区域,然后描述他看到了什么,」计算机科学和人工智能实验室(CSAIL)及口语系统小组研究员 David Harwath 表示。Harwath 在一篇 ECCV 大会论文中描述了这一模型。
在该论文中,研究人员展示了他们的模型。他们使用的图像中有一个金发碧眼的小女孩,穿着蓝色连衣裙,背景是一座红顶的白色灯塔。该模型学会了建立图像中的元素与「女孩」、「金发」、「蓝眼睛」、「蓝色裙子」、「白色灯塔」和「红色屋顶」之间的关联。给出一段音频描述,模型会根据描述显示出图像中的每个目标。

图 7:左边显示了两幅图像及其语音信号。每种颜色对应于从完全随机 MISA 网络的两个匹配图中导出的一个连通分量。右边的掩码显示与每个语音片段相对应的片段。掩码下方展示了从 ASR 转录中获得的描述。请注意,这些词从未用于学习,只是用于分析。
学习不同语言之间无需双语注释的翻译是该技术一种有前景的应用。全世界大约有 7000 种口语,其中只有大约 100 种具有充足的语音识别转录数据。如果模型从与图像中的目标对应的语言 A 中学习语音信号,同时从对应于相同目标的语言 B 中学习语音信号,该模型就能假设这两种信号(及对应的词)可以互译。
「这有可能是一种巴别鱼式的机制,」Harwath 说,巴别鱼是《银河系漫游指南》小说中虚构的一种生物耳机,它将不同的语言翻译给佩戴者。该论文的合著者包括 CSAIL 的研究生 Adria Recasens、访问生 Didac Suris、前研究员 Galen Chuang、电气工程和计算机科学教授兼 MIT-IBM 沃森人工智能实验室负责人 Antonio Torralba 及领导 CSAIL 口语系统小组的高级研究科学家 James Glass。
声音-视觉关联
这项研究基于早期由 Harwath、Glass、Torralba 开发的将语音与主题相关的图像关联起来的模型。在早期研究中,他们从众包的 Mechanical Turk 平台的分类数据库提取场景图像。然后他们让人们按照向婴儿叙述的方式用大约 10 秒的时间来描述图像。他们编译了超过 20 万对图像和音频描述,涉及数百个不同的类别,例如海滩、购物广场、城市街道和房间等。

场景识别数据库:http://places.csail.mit.edu/
然后他们设计了一个由两个独立的卷积神经网络构成的模型。一个处理图像,另一个处理声谱(音频信号随时间变化的可视化表示)。模型的最顶层计算两个网络的输出并对语音模式和图像数据进行映射。
例如,研究人员将描述 A 和图像 A(正确配对)馈送给模型。然后他们再馈送一个随机描述 B 和图像 A(错误配对)。在比较了图像 A 的数千个错误配对之后,模型学习到了对应图像 A 的语音信号,并关联描述中的单词信号。如 2016 年的这篇论文所述,模型学习选取对应单词「水」的信号,并检索包含水的图像。「但它并没有提供用特定单词检索特定图像像素块的功能。」Harwath 说。
相关链接:http://news.mit.edu/2016/recorded-speech-images-automated-speech-recognition-1206
制作匹配图
在这篇新论文中,研究人员修改了模型,将特定单词与特定像素块相关联。他们在同一个数据库上训练了该模型,但图像-描述为 40 万对。他们随机拿出了 1000 对用来进行测试。
在训练中,模型同样会得到正确和错误的图像和描述配对。但这一次,图像分析 CNN 将图像分成了由像素块组成的网格。音频分析 CNN 将声谱图分成几段,比如一秒捕捉一两个单词。
对于正确的图像和描述对,模型将网格的第一个单元与第一段音频匹配,然后将同一单元与第二段音频匹配,以此类推,一直贯穿每个网格单元,跨越所有时间段。对于每个单元和音频片段,它提供相似性分数,这取决于信号与目标的匹配程度。
问题是,在训练过程中,模型无法获取语音和图像之间的任何真实对齐信息。Harwath 说,「该论文的最大贡献是,通过简单地教导网络哪些图像和描述属于同一组,哪些对不属于同一组,证明了这些跨模态(视-听)信息可以自动推断对齐。」
研究人员将语音说明的波形与图像像素之间的这种自动学习关联称为「匹配图」。经过成千上万对图像-描述的训练,网络将这些对齐缩小到代表匹配图中特定目标的特定单词。
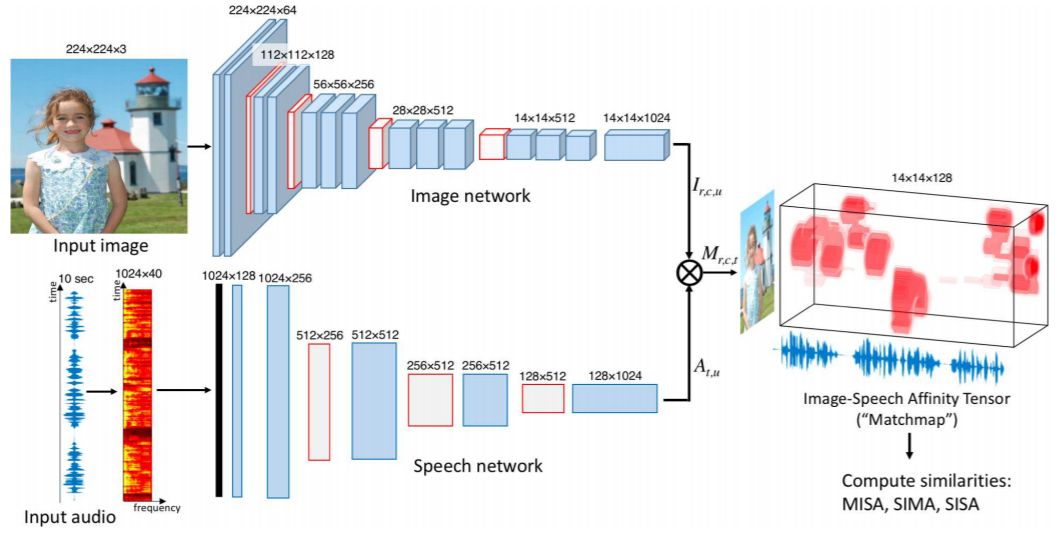
图 3:声音-视觉匹配图模型架构(左),匹配图输出示例(右),显示时空相似性的三维密度。
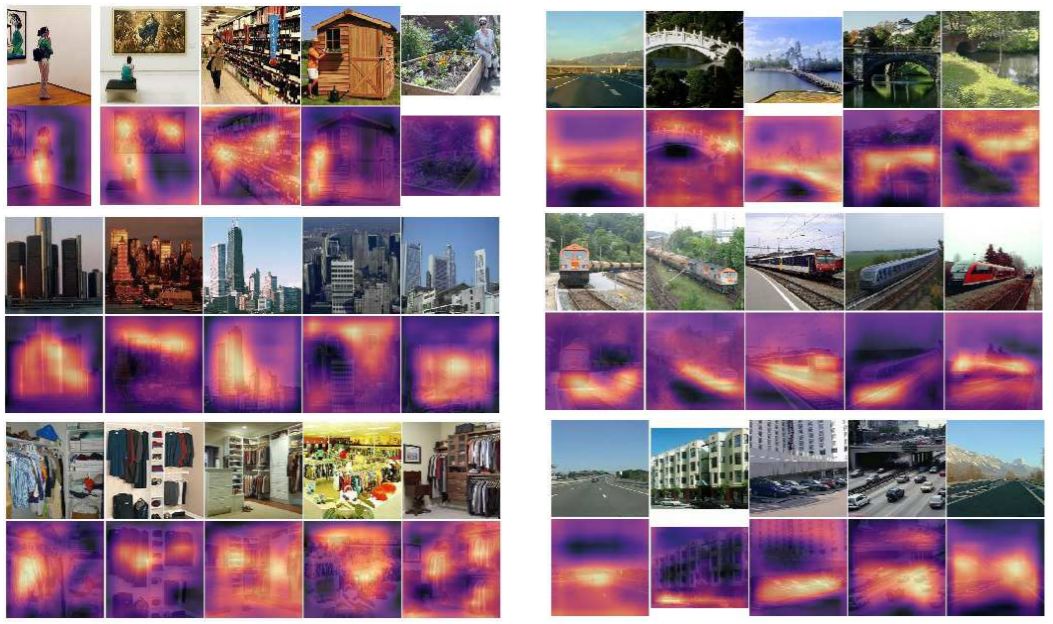
图 4:几个词汇/目标配对的语音提示定位图。
Harwath 还表示,「这有点像大爆炸,物质被分解,然后合并成行星和恒星。预测开始分散开来,但是经过训练后,它们会汇聚成对,代表语音和视觉目标之间有意义的语义基础。」
卡内基梅隆大学语言技术研究所的副教授 Florian Metze 说,「看到神经方法现在也能够将图像元素与音频片段联系起来,而且不需要文本作为中介,真是令人兴奋。与人类的学习不同,这种方法完全基于相关性,没有任何反馈,但它可能帮助我们理解共享表征是如何由听觉和视觉线索形成的。」
论文:Jointly Discovering Visual Objects and Spoken Words from Raw Sensory Input

论文链接:http://openaccess.thecvf.com/content_ECCV_2018/papers/David_Harwath_Jointly_Discovering_Visual_ECCV_2018_paper.pdf
参考链接:http://news.mit.edu/machine-learning-image-object-recognition-0918
点击“ 阅读原文 ”进入AI学院学习




