想入门深度学习不会搭建环境?手把手教你在Amazon EC2上安装Keras

大数据文摘作品,转载要求见文末
编译 | Molly、寒小阳、Yawei
随着我们使用的神经网络越来越复杂,我们需要更强劲的硬件。我们的个人电脑一般很难胜任这样大的网络,但是你可以相对轻松地在Amazon EC2服务中租到一台强劲的电脑,并按小时支付租金。
我用的是Keras,一个神经网络的开源python库。由于用法十分简单,它很适合入门深度学习。它基于Tensorflow,一个数值计算的开源库,但是也可以使用Theano。租到的机器可以使用Jupyter Notebook通过浏览器来访问。Jupyter Notebook是一个通过交互式代码来共享和编辑文档的web应用。
通过cuDNN,一个深度神经网络GPU加速库,Keras可以在GPU上运行。由于并行运算的设计,这种方式会比一般的CPU要快很多。建议你看几个CNN指标,对比最流行的神经网络在不同的GPU和CPU的运行时间。
我将向你介绍如何一步步在预置好的Amazon Machine Image (AMI)上搭建这样一个深度学习的环境。
1) 创建账户
访问 https://aws.amazon.com/ ,并创建一个AWS账户。
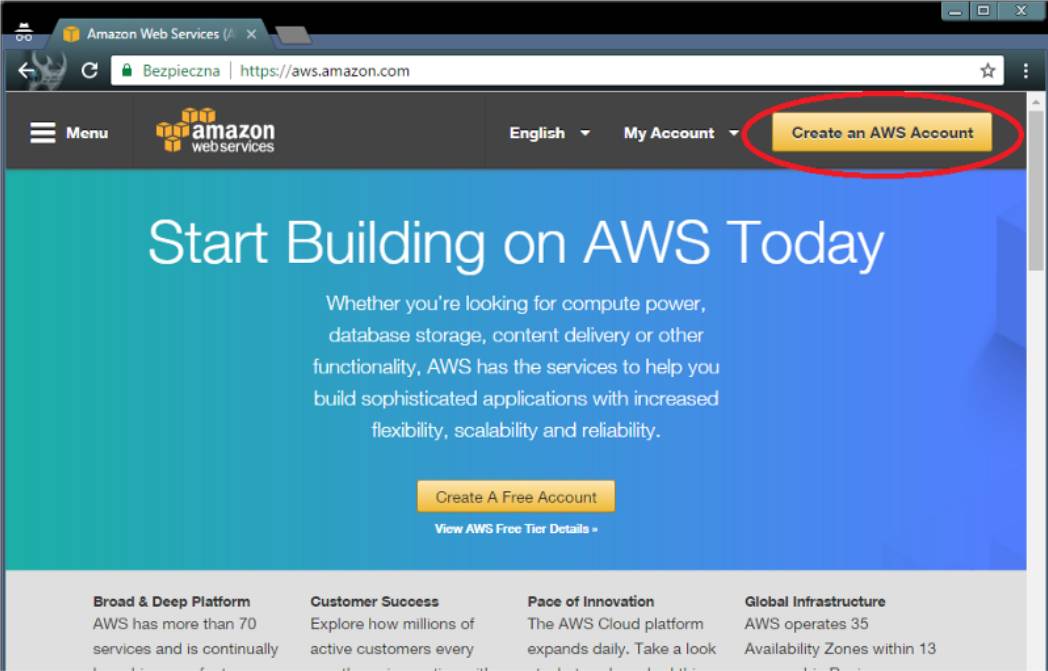
然后登陆控制台。
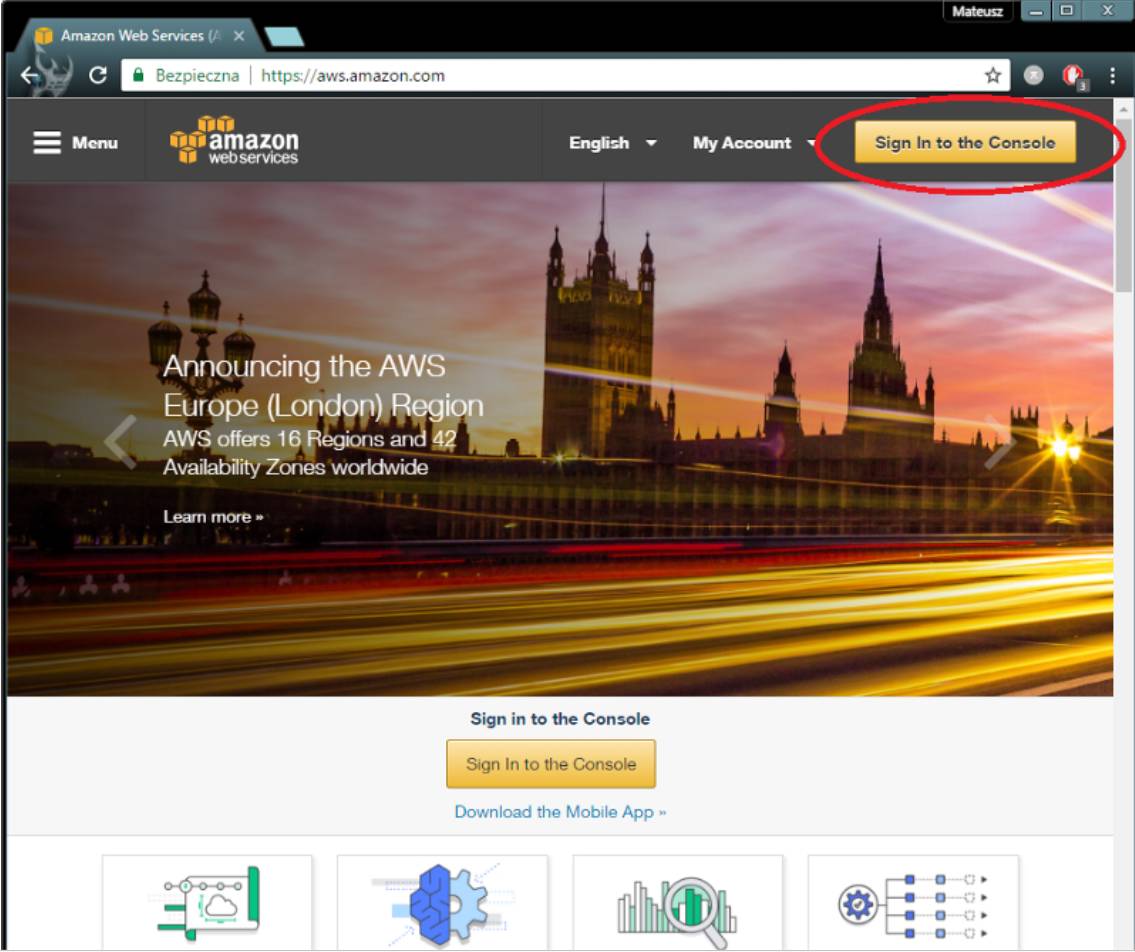
你的控制面板应该看起来像这样。
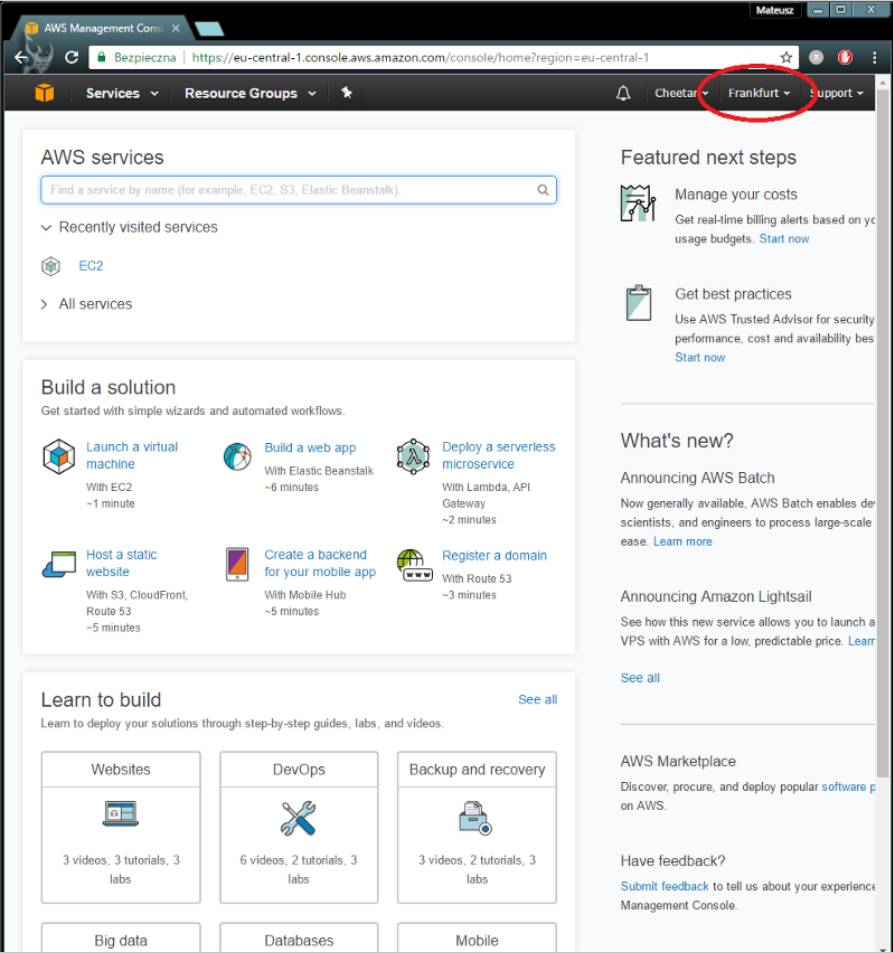
确保你选择的所在地区是法兰克福,N. Virgiania或新加坡,以便之后可以使用一个预置好的Keras AMI。如果你想自己动手设置这样的AMI,你可以按照这个指南。
2) 启动实例
现在让我们跳转到EC2控制页面。
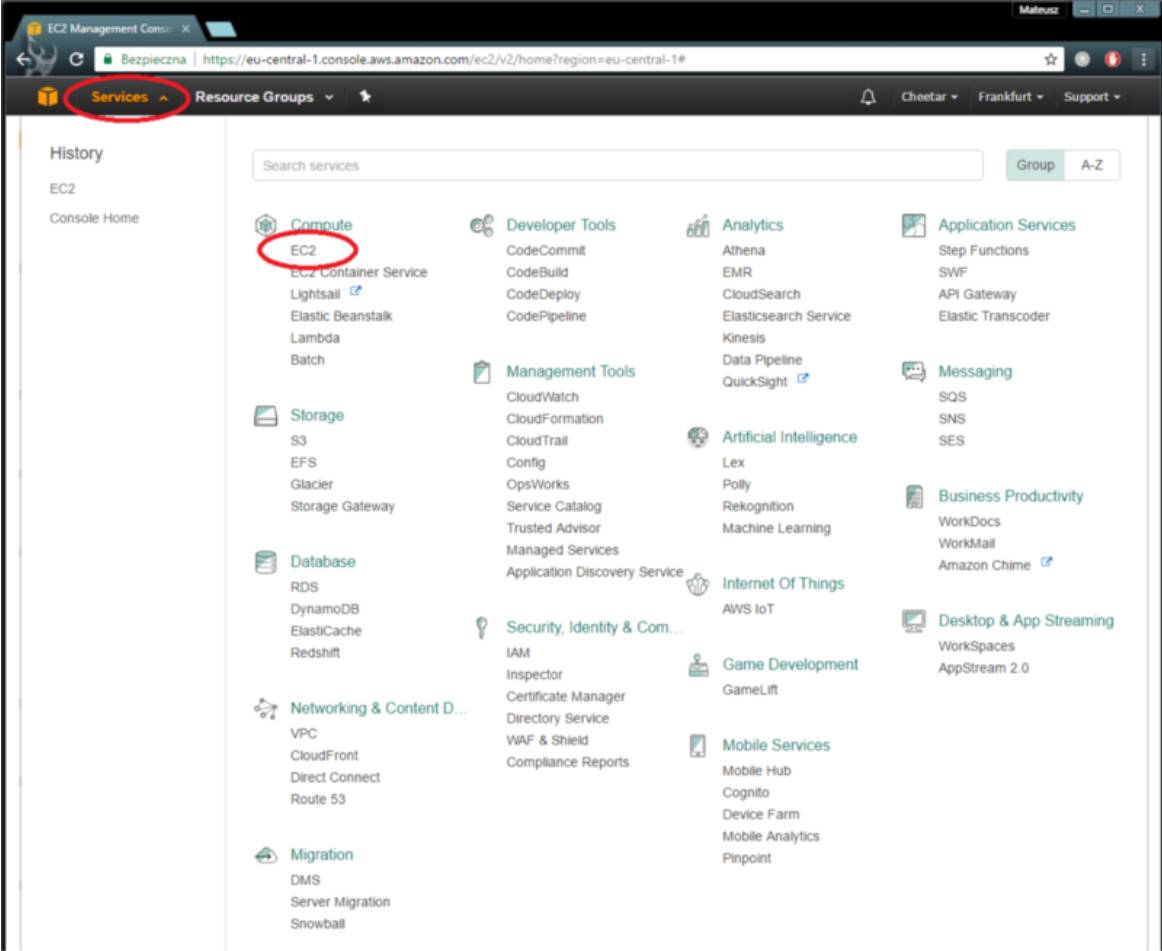
“Amazon Elastic Compute Cloud(Amazon EC2)在Amazon Web Services(AWS)云中提供可扩展的计算功能。 Amazon EC2的使用消除了前期对硬件的投资要求,因此你可以更快地开发和部署应用程序。 你可以使用Amazon EC2启动大量或几个虚拟服务器,配置安全性和网络以及存储管理。 Amazon EC2允许你对硬件升级或降级,来应对需求的变化或流量的峰值,因此不太需要进行流量的预测。”。
所以换句话说,你可以在任何时候租一个服务器来进行计算,也就是机器学习模型训练。 现在让我们启动一个实例吧!
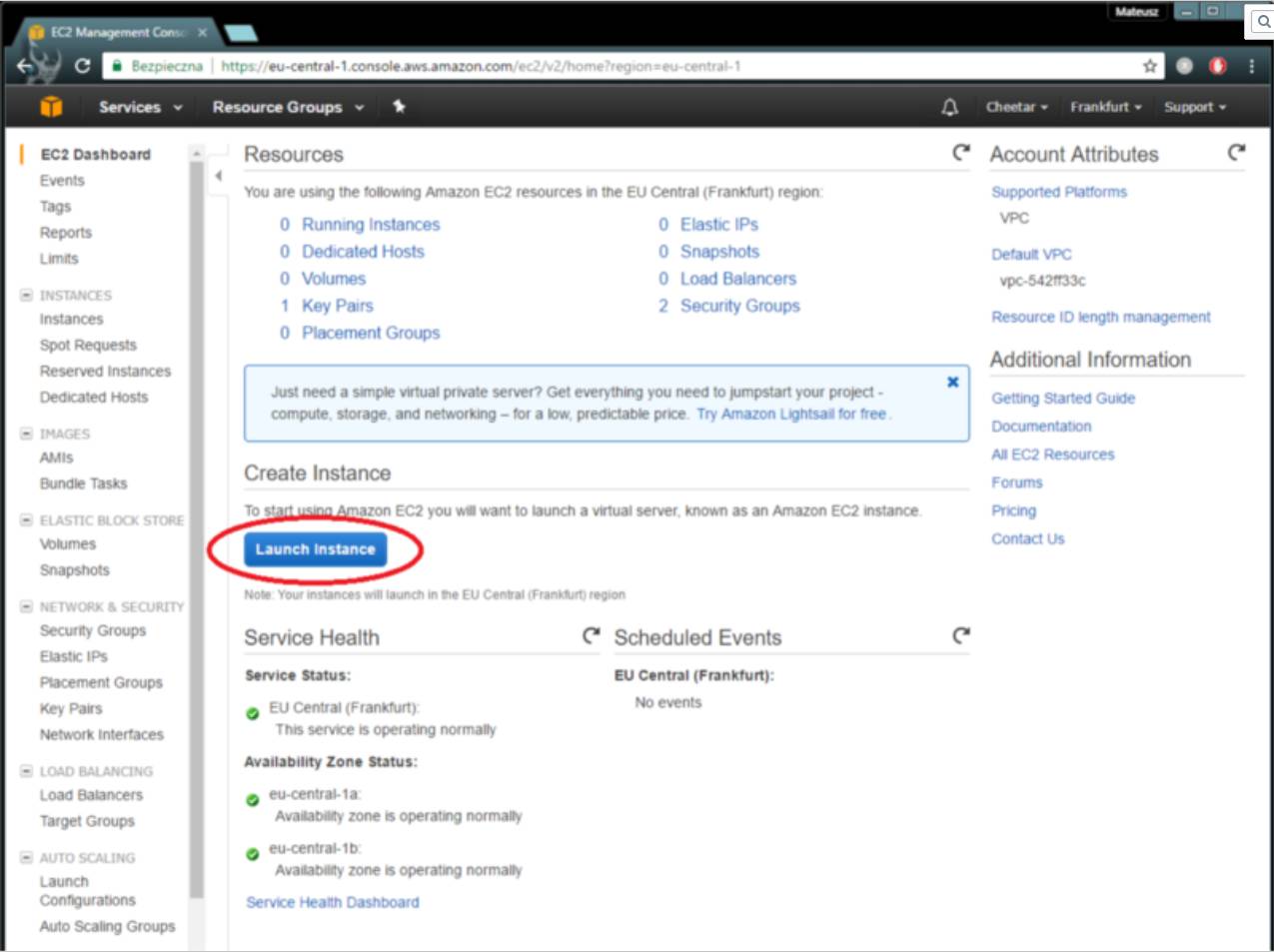
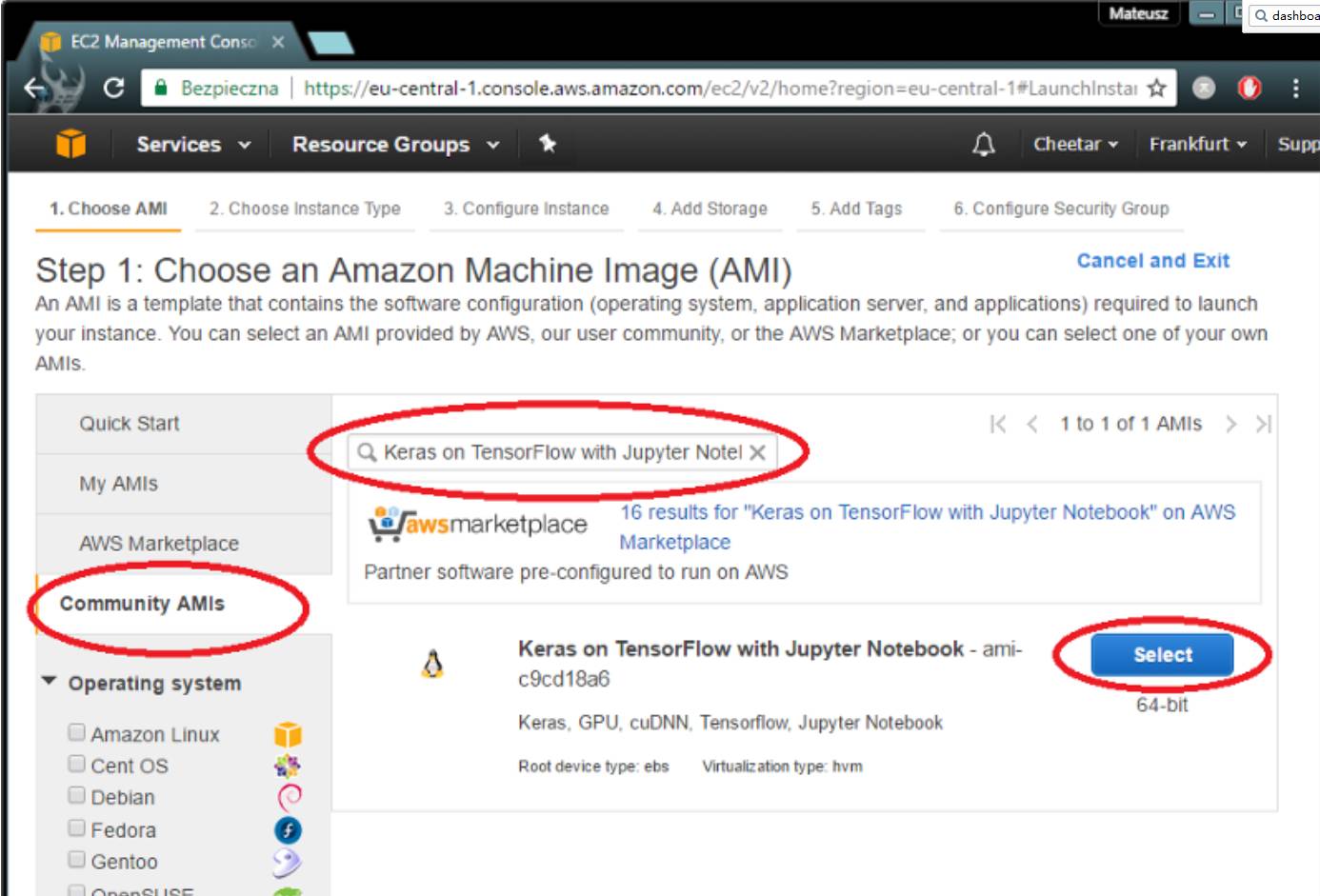
首先,你需要选择一个已经安装了所有必需工具的AMI(基于TensorFlow的Kreas和Jupyter Notebook)。
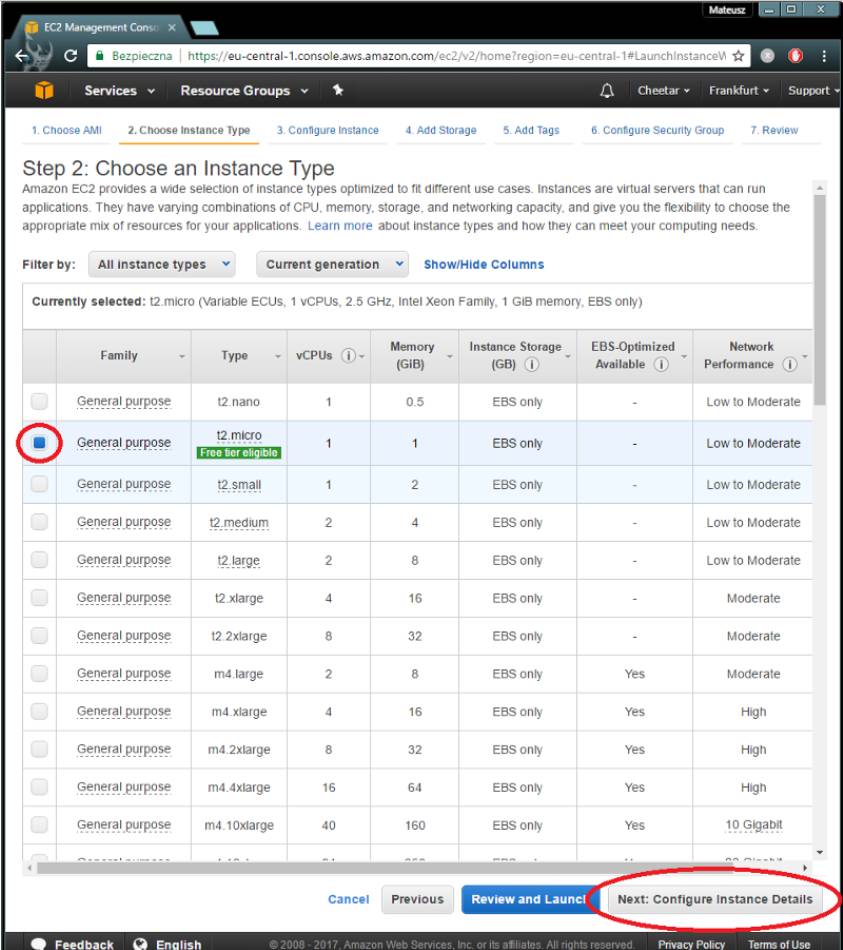
选择实例类型(你租到的计算机的质量)。 当然,你选择的机型越好越贵。 但是你正在创建你的第一个实例,所以你肯定不想选最好的那个。选择t2.micro就够了,它就是一个测试实例。它可以在不掏空你的钱包的情况下,让你体验下环境。 :)
当你比较满意,想要更多的计算能力时,我建议你使用一个g *类型的实例(g代表GPU后端)。比如 g2.2xlarge。 一个默认的GPU实例的定价为每小时0,772美元左右。
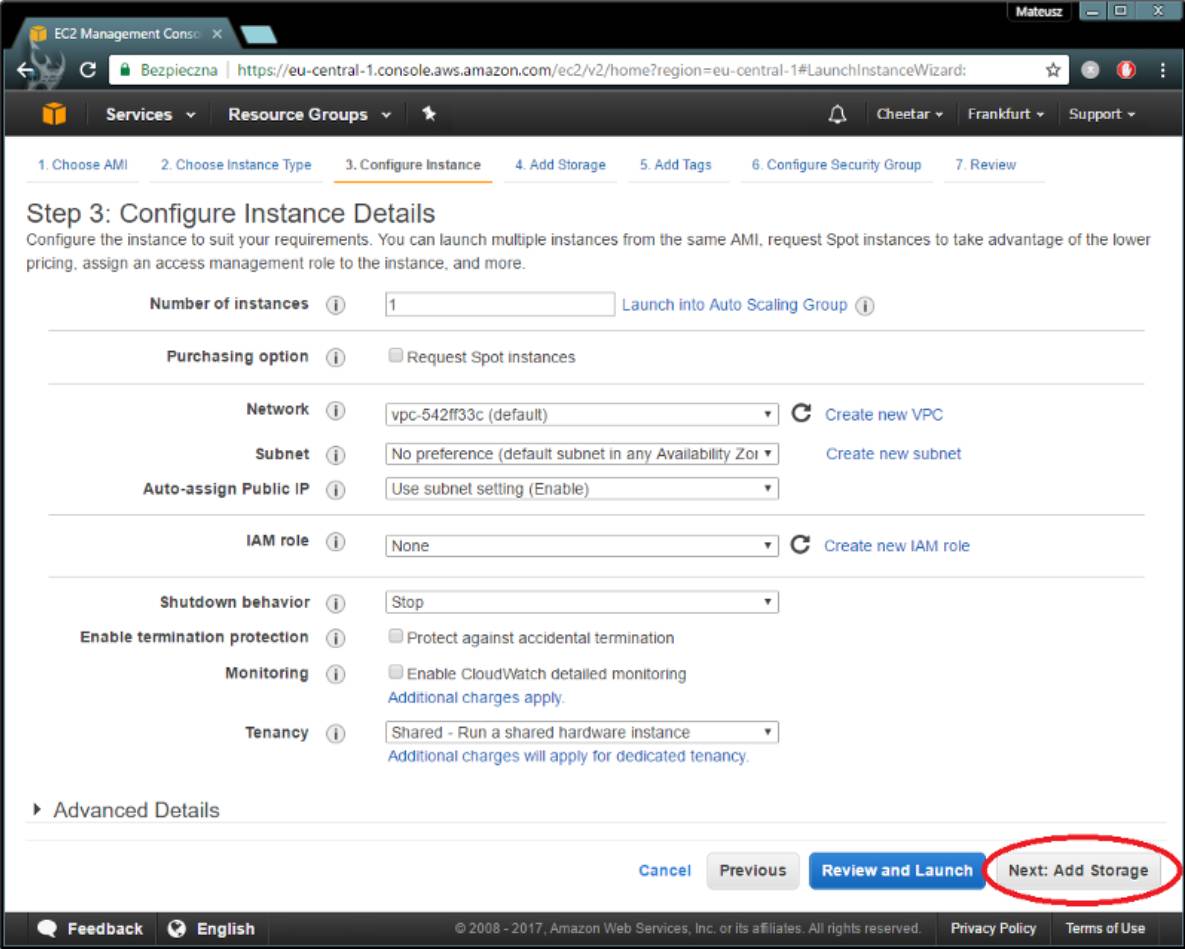
这里没什么意思,跳过。
免费使用的最大容量是30 GB。此外,如果你不希望你的数据在关闭实例后消失,要取消选中“终止时删除”复选框。
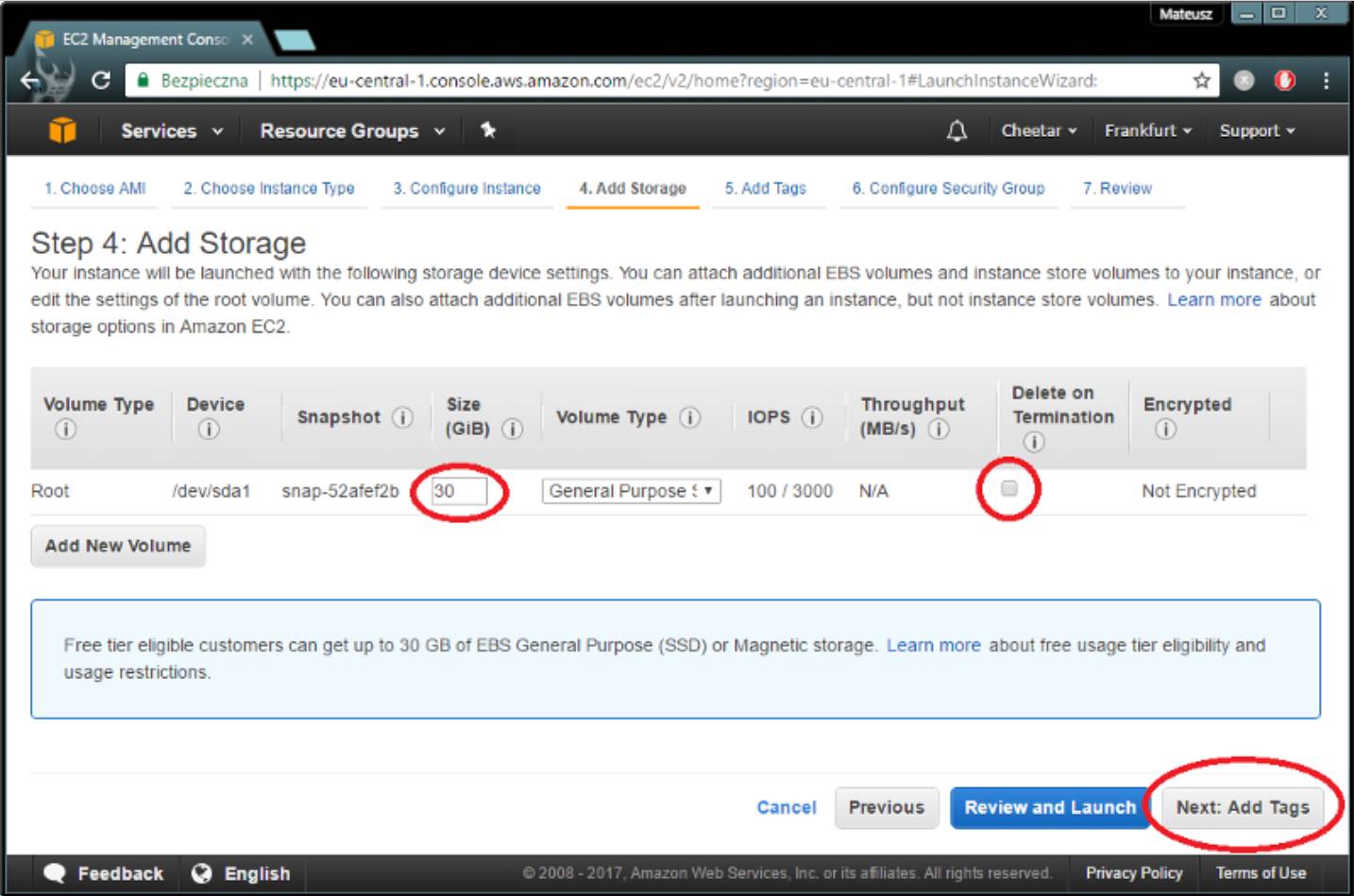
继续。
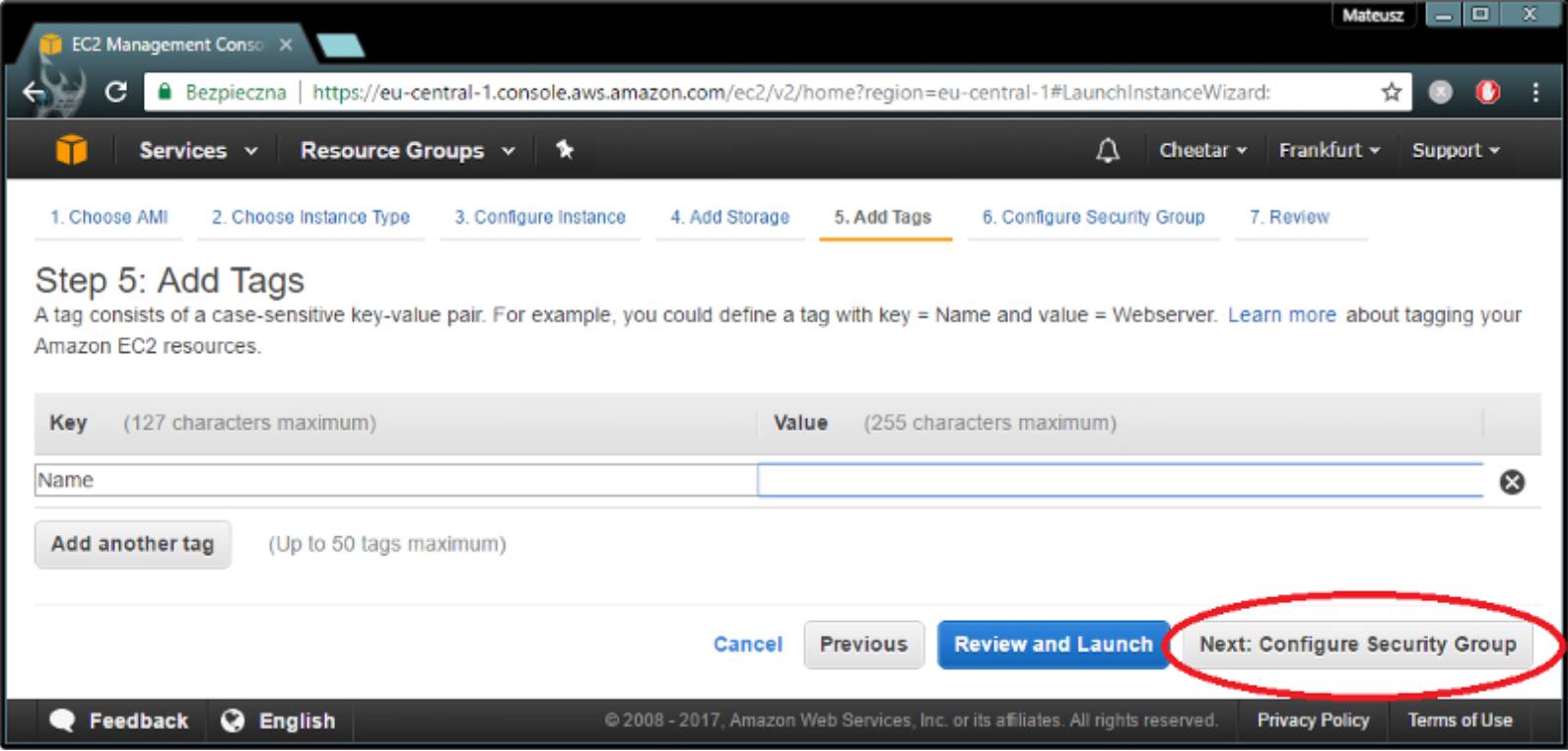
这个步骤很重要,因为你不仅要使用ssh,还要通过浏览器访问你的实例。 在端口8888上添加自定义TCP规则。仅允许从你的IP地址,8888和22(ssh)端口访问它。
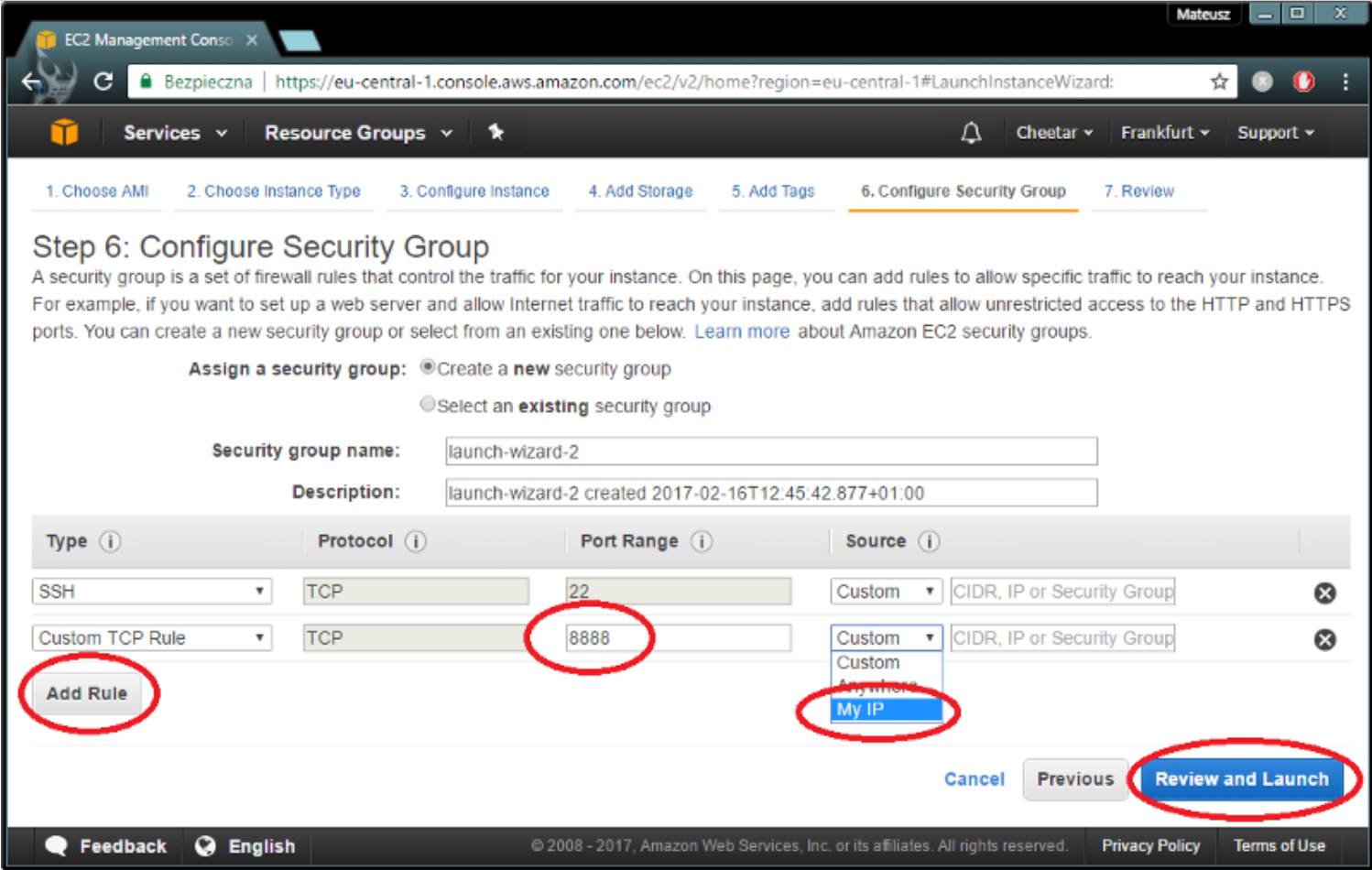
一切准备好了,现在启动实例!
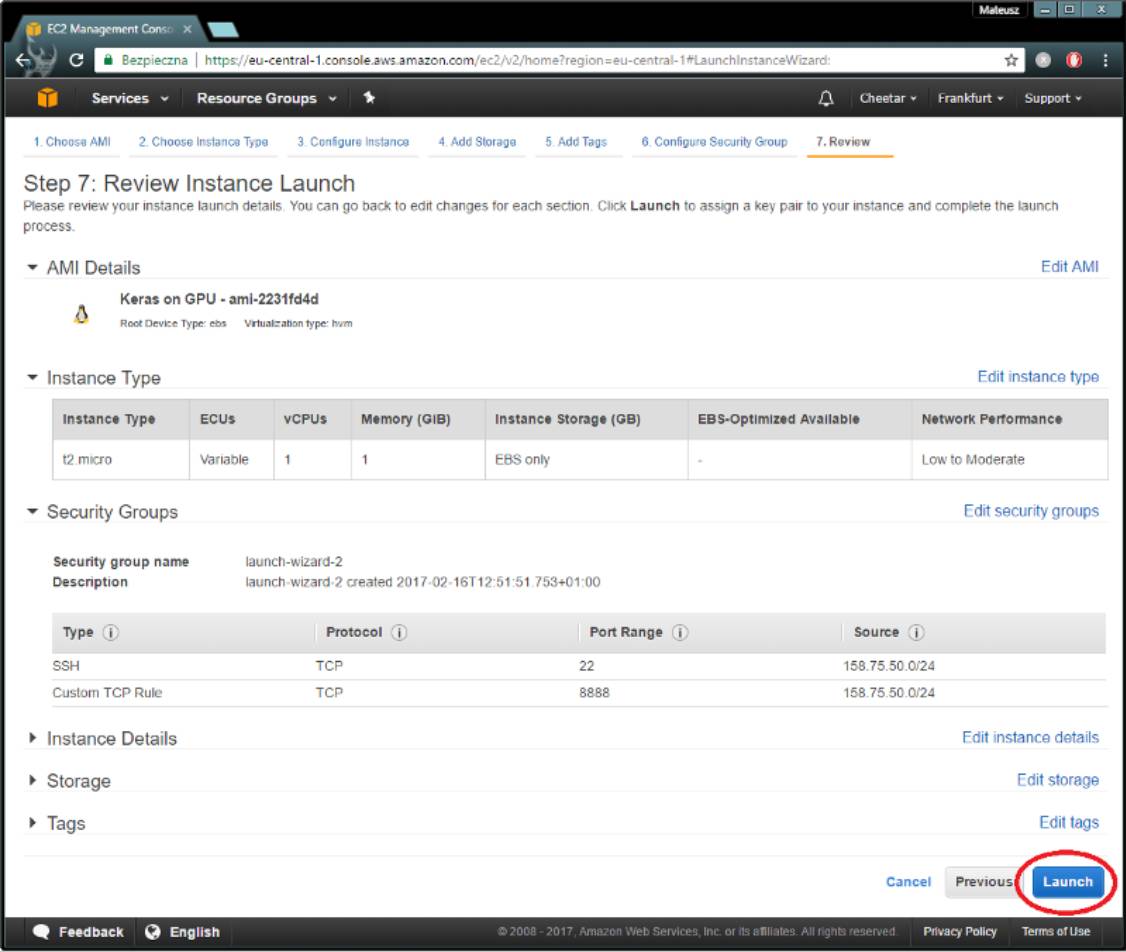
你只需要设置一个新的(或选择一个现有的)密钥对。通过ssh链接到你的机子时,必须要有密钥。
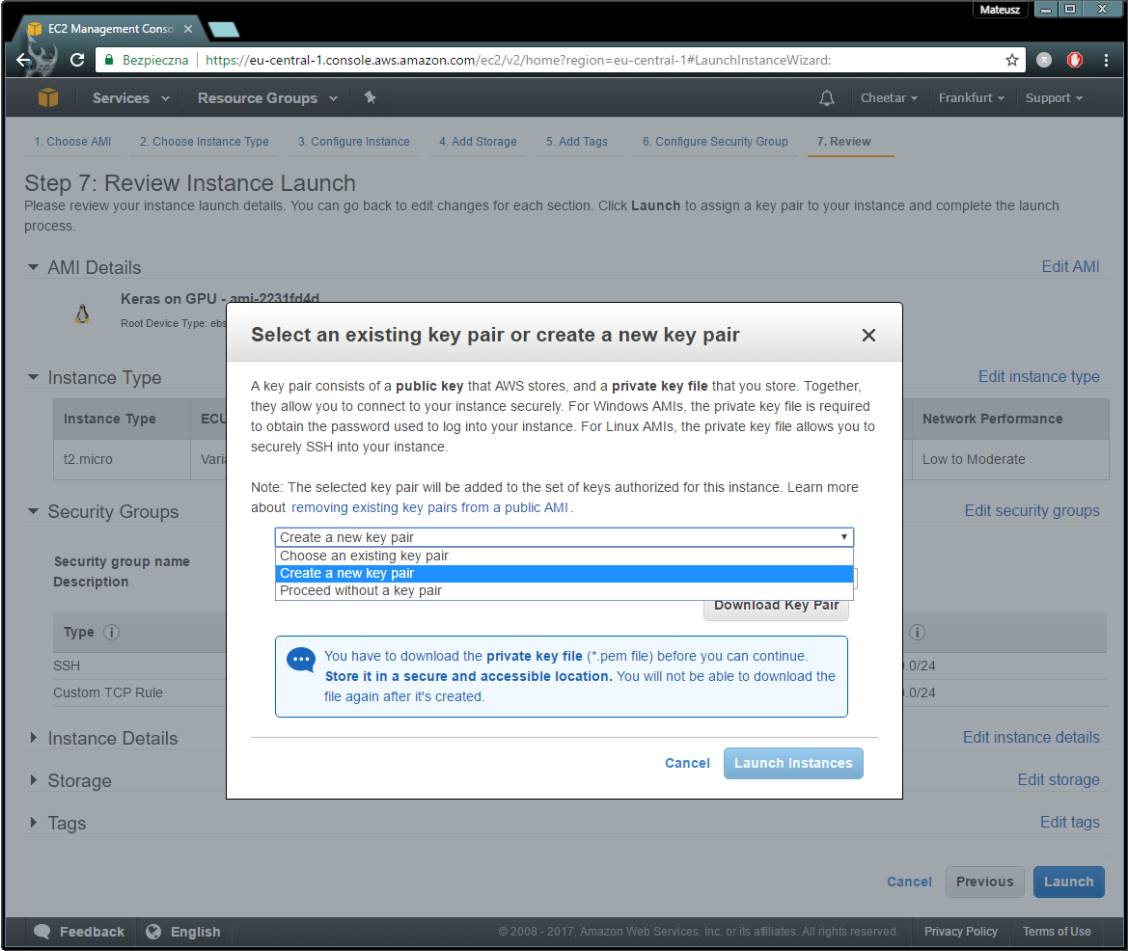
下载生成的密钥,注意保密!这样除你之外没有其他人可以访问这台机器。
现在让我们查看机器的状态。
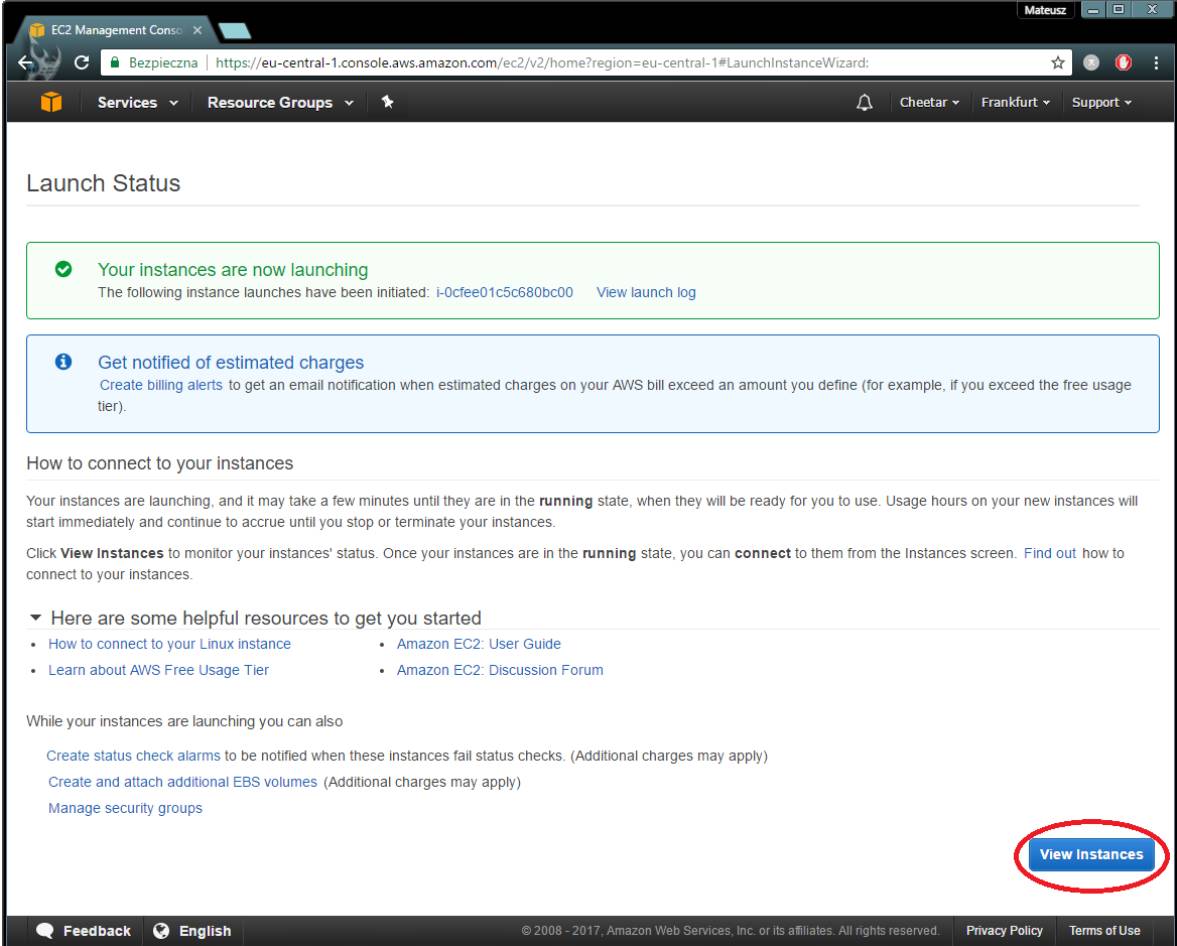
如你所见,实例已启动并正在运行。 棒棒哒! 你刚刚启动了一个AWS实例。
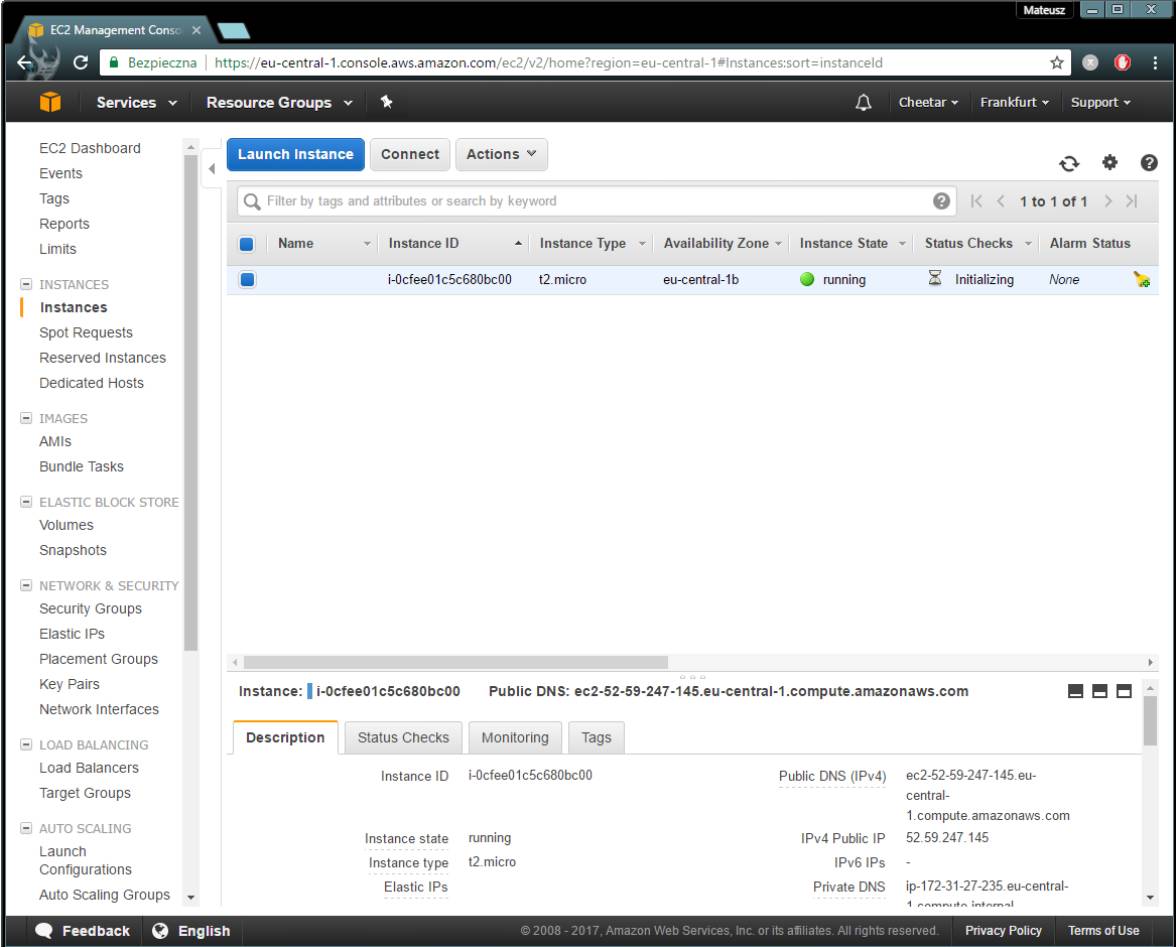
3)设置Jupyter Notebook
现在让我们使用它。 通过ssh连接。
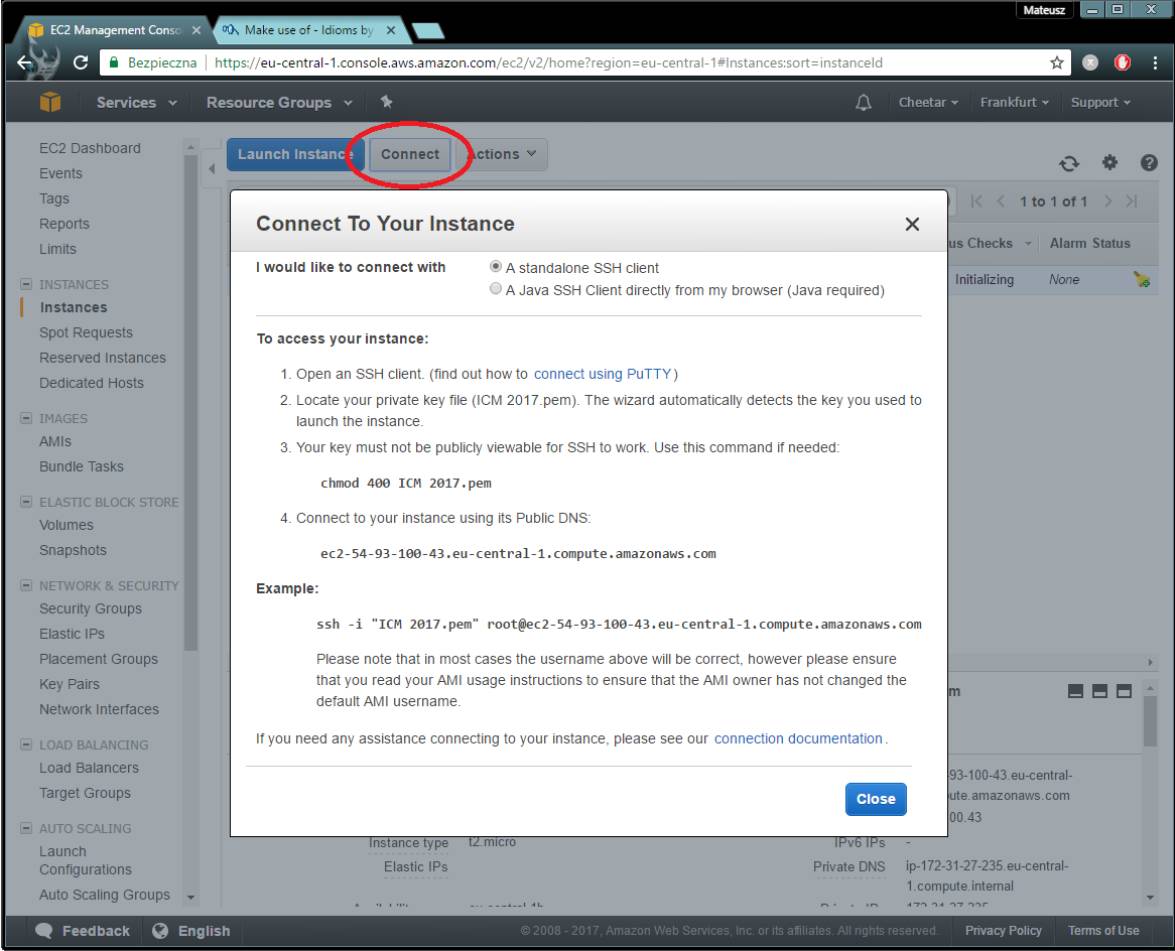
按照说明,更改私钥的权限并将示例键入终端(或使用PuTTY连接)。在-i参数后插入私钥的路径,使用'ubuntu'替换’root’。 所以命令看起来如下(如果你使用Windows,查看如何通过PuTTY连接):
ssh -i ‘path/to/private/key’ ubuntu@public_dns
在终端输入下面命令打开Notebook
sudo jupyter notebook
你可以通过浏览器访问Notebook,方法是键入your_public_dns:8888(8888是Jupyter默认端口)。
4)连接到你的实例
默认密码是“'machinelearningisfun”(我建议你更改密码,在Jupyter Notebook的文档中解释了如何做)。
MNIST数据集是一个著名的手写数字集。 我准备了一个Notebook示例,加载数据集,并拟合一个示例卷积神经网络。 打开mnist.jpynb示例并自行运行其中的cell。
代码来自Keras示例库
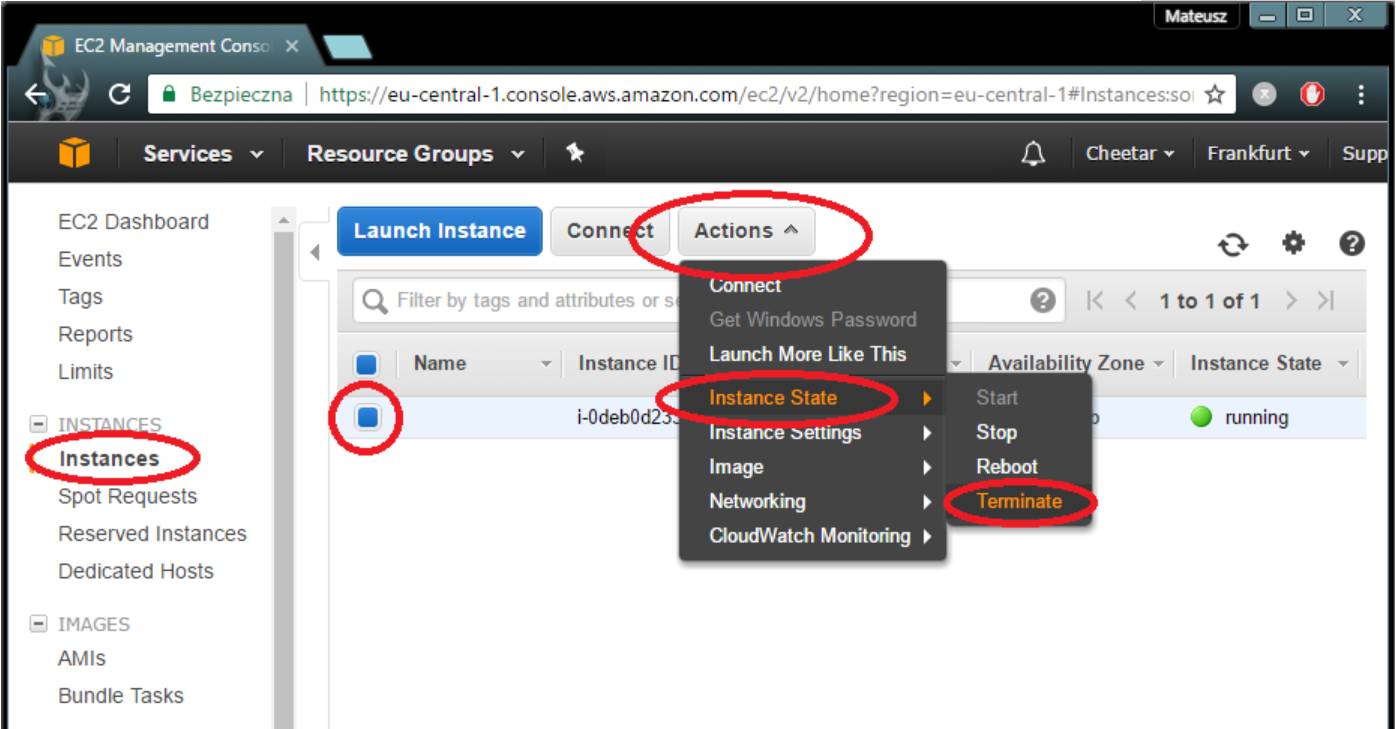
当你用完后,记得终止你的实例!账单是依据实例运行的时间来计算的。例如,如果你忘记关掉你的g2.2xlarge 实例,让它运行了一个月,你将要为此支付$0,772*24*30 = $555,84. :)
那么,接下来呢? 我建议你看看notMNIST数据集,其中包含来自不同字体的字母集。 你也可能对CIFAR-10感兴趣: 一组彩色图像,对应10个类别,比如飞机,船只,鸟类或猫。
如果你是Keras新手,你可能对这个教程感兴趣。 或者,像我做的案例,检测可能触发密集恐惧症的图片(强烈建议不要google相关的照片)。 我在PiotrMigdał主持的波兰儿童基金会的研讨会上学习了卷积神经网络的基础知识(以及如何设置机器)。 其中另一位参与者的源代码,使用VGG16进行特征提取,可在GitHub上获取。
数据、模型、算法、平台、场景
如何有效应用
为变革而来
百度2017ABC SUMMIT
邀请门票限量放送!
详情👇阅读原文


关于转载
如需转载,请在开篇显著位置注明作者和出处(转自:大数据文摘 | bigdatadigest),并在文章结尾放置大数据文摘醒目二维码。无原创标识文章请按照转载要求编辑,可直接转载,转载后请将转载链接发送给我们;有原创标识文章,请发送【文章名称-待授权公众号名称及ID】给我们申请白名单授权。未经许可的转载以及改编者,我们将依法追究其法律责任。联系邮箱:zz@bigdatadigest.cn。
回复“志愿者”加入我们



点击图片阅读
DOTA2获胜的AI比AlphaGo厉害?还是媒体和马斯克在联合炒作?








