xgboost特征选择

大数据挖掘DT数据分析 公众号: datadw
Xgboost在各大数据挖掘比赛中是一个大杀器,往往可以取得比其他各种机器学习算法更好的效果。数据预处理,特征工程,调参对Xgboost的效果有着非常重要的影响。这里介绍一下运用xgboost的特征选择,运用xgboost的特征选择可以筛选出更加有效的特征代入Xgboost模型。
这里采用的数据集来自于Kaggle | Allstate Claims Severity比赛,
https://www.kaggle.com/c/allstate-claims-severity/data
这里的训练集如下所示,有116个离散特征(cat1-cat116),14个连续特征(cont1 -cont14),离散特征用字符串表示,先要对其进行数值化:
id cat1 cat2 cat3 cat4 cat5 cat6 cat7 cat8 cat9 ... cont6 \
0 1 A B A B A A A A B ... 0.718367
1 2 A B A A A A A A B ... 0.438917
2 5 A B A A B A A A B ... 0.289648
3 10 B B A B A A A A B ... 0.440945
4 11 A B A B A A A A B ... 0.178193
cont7 cont8 cont9 cont10 cont11 cont12 cont13 \
0 0.335060 0.30260 0.67135 0.83510 0.569745 0.594646 0.822493
1 0.436585 0.60087 0.35127 0.43919 0.338312 0.366307 0.611431
2 0.315545 0.27320 0.26076 0.32446 0.381398 0.373424 0.195709
3 0.391128 0.31796 0.32128 0.44467 0.327915 0.321570 0.605077
4 0.247408 0.24564 0.22089 0.21230 0.204687 0.202213 0.246011
xgboost的特征选择的代码如下:
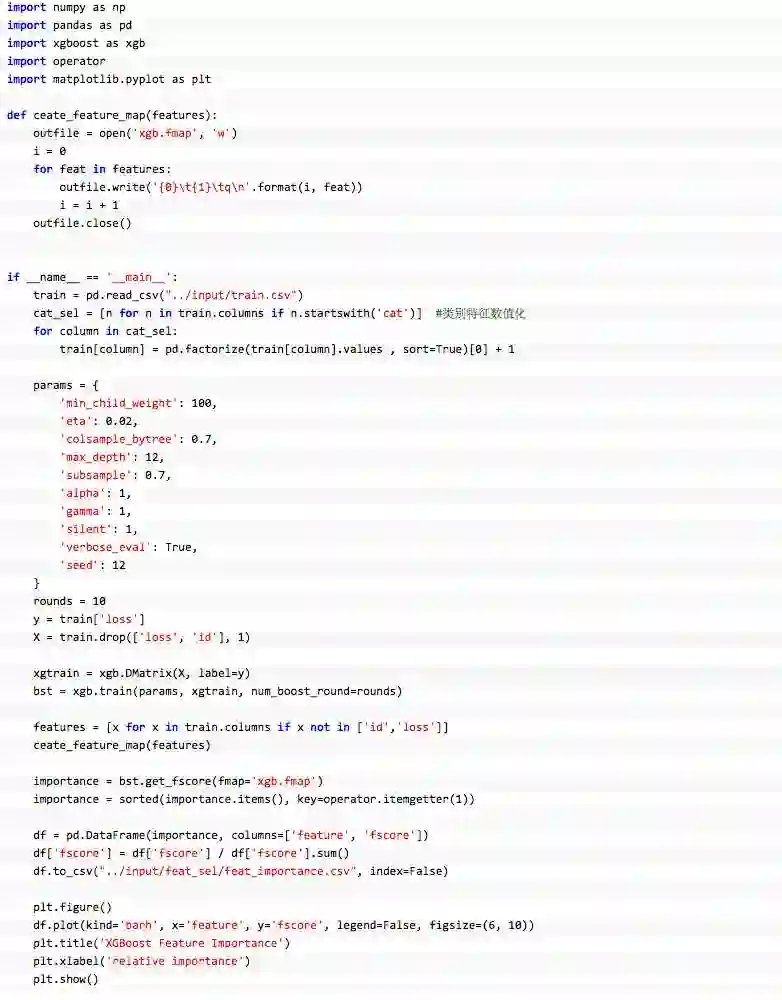
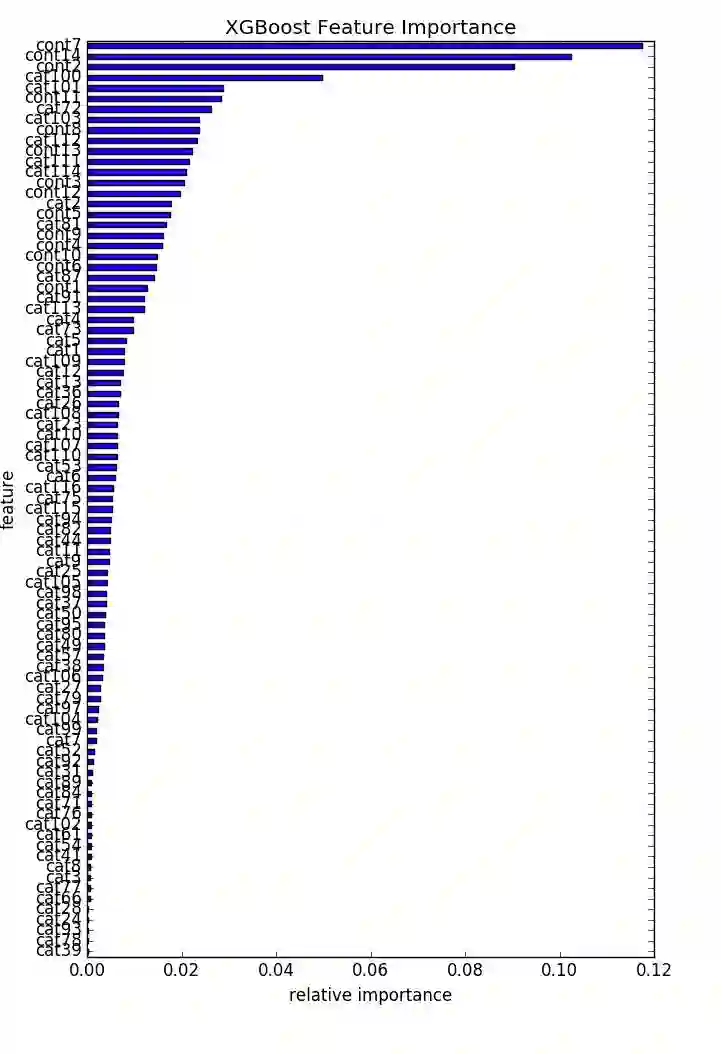
http://blog.csdn.net/qq_34264472/article/details/53363384
人工智能大数据与深度学习
搜索添加微信公众号:weic2c

长按图片,识别二维码,点关注
大数据挖掘DT数据分析
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注




