双向最大匹配和实体标注:你以为我只能分词?

一 :内容预告
前几天,我看了叉烧同学写的文章:
文章介绍了一种实体自动打标的方法:实体词典+最大逆向匹配。
啥叫实体打标呢?
举叉烧同学文章里的例子,有一句话:宫保鸡丁和红烧牛肉哪个好吃,我们需要给句子中的两个实体 [宫保鸡丁, 红烧牛肉] 打上 Food 标签,非实体打上 O 标签。
做法是,首先准备一个实体词典,实体词典包含这两个实体在内的食物名,然后用这个词典和最大逆向匹配算法,给实体打标签。
打好标签的句子,可以直接作为实体提取的最终结果,也可以作为训练实体识别模型的样本。
用于构造样本时,打标签的结果如下:
""" 1:句子 """
宫保鸡丁和红烧牛肉哪个好吃
""" 2:标注结果 """
宫 B-Food
保 I-Food
鸡 I-Food
丁 I-Food
和 O
红 B-Food
烧 I-Food
牛 I-Food
肉 I-Food
哪 O
个 O
好 O
吃 O我之前也做过实体自动打标签的活,不过用的方法是:实体词典+jieba词性标注。
jieba词性标注应该用到了双向最大匹配,所以其实我之前做的,就是掉包实现了以上打标的方法。
这次准备了一个医疗实体词典(带标签)和若干医疗文本,用python实现双向最大匹配算法,并结合实体词典进行实体自动打标,作为训练实体识别模型的样本。
同时也整理了实体词典+jieba词性标注进行实体自动打标的方法。
代码已上传github地址:
https://github.com/DengYangyong/medical_entity_recognize
本文主要关注以下四方面的内容:
双向最大匹配算法的思路
双向最大匹配算法的代码实现
实体词典+双向最大匹配算法做实体打标
实体词典+jieba词性标注做实体打标
二:双向最大匹配算法
前向最大匹配算法和后向最大匹配算法是基于规则(词典)的分词方法,二者按照一定的规则结合使用,就是双向最大匹配算法。
双向最大匹配算法不仅可以用于分词,也可以用于序列标注,速度快且准确率高,不会分出奇怪的词或实体,但也难以正确处理未登录词。
由于完全依赖词典,通用性不强,所以比较适用于处理具体领域的任务,比如医疗领域。
首先拿到一个词典,比如实体词典,每一行是一个实体和对应的标签:
""" 词典(包含:实体和标签) """
肾抗针,DRU
肾囊肿,DIS
肾区,REG
肾上腺皮质功能减退症,DIS
肾性高血压,DIS
肾性贫血,DIS
肾血管,ORG
肾脏,ORG
伴脓性渗出,NBP
生理反射存在,NBP然后计算词典中实体的最大长度,作为截取句子片段的最大长度。
为什么叫最大匹配呢?
对句子进行分词和标注的一个原则是:单个词(实体)的长度尽可能大。所以会先按最大长度从句子中截取片段,去词典中匹配,匹配中了,就切分出来。
按最大长度匹配不中,那么最大长度减一,再去截取句子片段,去词典中匹配,直到匹配中,或者截取的长度减小至一。
为什么叫前向呢?
前向的意思是,从句子中截取片段是从左向右进行的。
更多的细节,来看一个例子。
患者的电子病历上写着:我最近双下肢疼痛,我该咋办。
句子中有个两个实体,出现在实体词典中:双下肢疼痛、疼痛。
句子的长度为14(包括标点符号),实体词典中的最大长度为10。
第一轮遍历未匹配中,把第一个字切分出来:[我]。
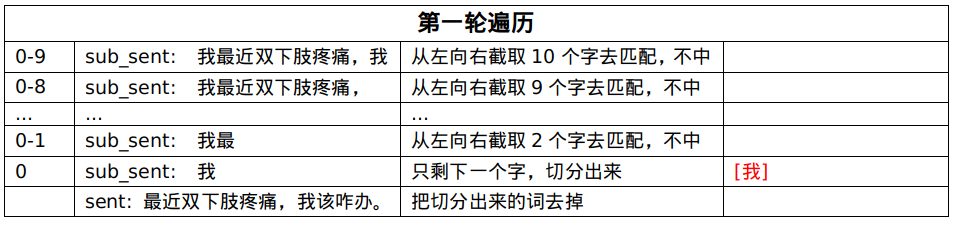
第二轮遍历未匹配中,把第二个字切分出来:[我,最]。
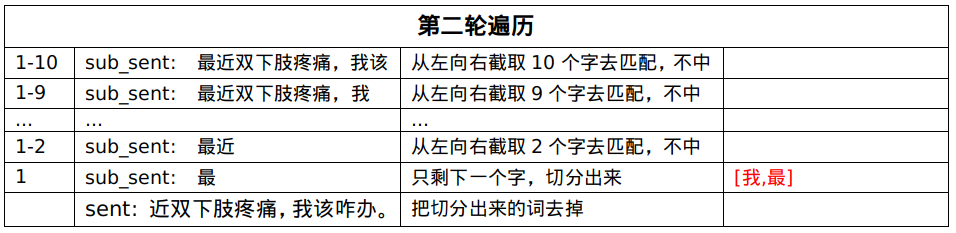
第四轮遍历,匹配中了[双下肢疼痛],就把这个实体从句子中剔除,拿剩下的句子继续匹配。
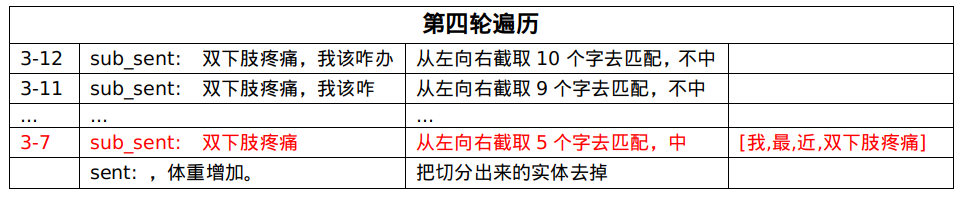
最终的实体打标结果为:

可以看到,[疼痛] 这个实体没有被匹配出来,因为[双下肢疼痛]的粒度更大,表达的含义更明确,这也是最大匹配的意义。
前向最大匹配的python实现如下:
#coding:utf-8
import pandas as pd
class PsegMax:
def __init__(self, dict_path):
self.entity_dict, self.max_len = self.load_entity(dict_path)
def load_entity(self, dict_path):
"""
加载实体词典
"""
entity_list = []
max_len = 0
""" 实体词典: {'肾抗针': 'DRU', '肾囊肿': 'DIS', '肾区': 'REG', '肾上腺皮质功能减退症': 'DIS', ...} """
df = pd.read_csv(dict_path,header=None,names=["entity","tag"])
entity_dict = {entity.strip(): tag.strip() for entity,tag in df.values.tolist()}
""" 计算词典中实体的最大长度 """
df["len"] = df["entity"].apply(lambda x:len(x))
max_len = max(df["len"])
return entity_dict, max_len
def max_forward_seg(self, sent):
"""
前向最大匹配实体标注
"""
words_pos_seg = []
sent_len = len(sent)
while sent_len > 0:
""" 如果句子长度小于实体最大长度,则切分的最大长度为句子长度 """
max_len = min(sent_len,self.max_len)
""" 从左向右截取max_len个字符,去词典中匹配 """
sub_sent = sent[:max_len]
while max_len > 0:
""" 如果切分的词在实体词典中,那就是切出来的实体 """
if sub_sent in self.entity_dict:
tag = self.entity_dict[sub_sent]
words_pos_seg.append((sub_sent,tag))
break
elif max_len == 1:
""" 如果没有匹配上,那就把单个字切出来,标签为O """
tag = "O"
words_pos_seg.append((sub_sent,tag))
break
else:
""" 如果没有匹配上,又还没剩最后一个字,就去掉右边的字,继续循环 """
max_len -= 1
sub_sent = sub_sent[:max_len]
""" 把分出来的词(实体或单个字)去掉,继续切分剩下的句子 """
sent = sent[max_len:]
sent_len -= max_len
return words_pos_seg后向的意思是,从句子中截取片段是从右往左进行的。
还是来看上面的那个例子。
第一轮遍历未匹配中,把最后一个字切分出来:[。]。
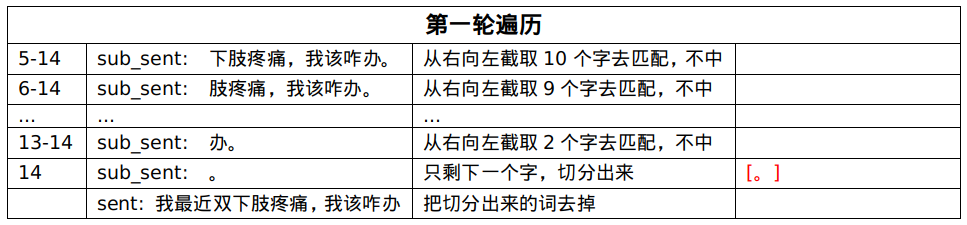
第二轮遍历未匹配中,把倒数第二个字切分出来:[办,。]。
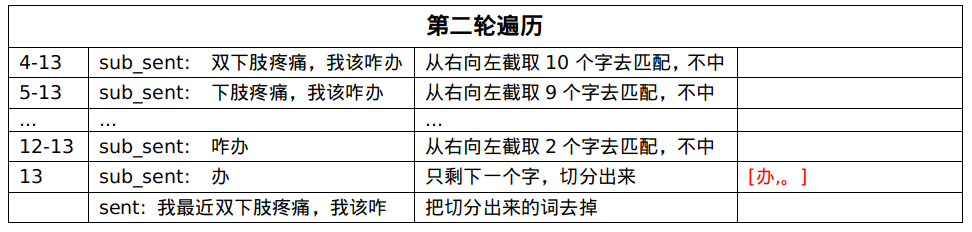
直到第七轮遍历,匹配中了[双下肢疼痛],就把这个实体从句子中剔除,拿剩下的句子继续匹配。

最终的实体打标结果和前向最大匹配的结果一致。
这个例子没反映出前向最大匹配和后向最大匹配的差别,感觉在实体标注这一块,二者的结果差别不大。
有资料统计,在分词时,仅使用前向最大匹配的错误率为 1/169,而使用后向最大匹配的错误率为 1/245,可见使用后向最大匹配可以提高分词或标注的准确率。
后向最大匹配的python实现如下:
#coding:utf-8
import pandas as pd
class PsegMax:
def __init__(self, dict_path):
self.entity_dict, self.max_len = self.load_entity(dict_path)
def load_entity(self, dict_path):
"""
加载实体词典
"""
def max_forward_seg(self, sent):
"""
前向最大匹配实体标注
"""
def max_backward_seg(self, sent):
"""
后向最大匹配实体标注
"""
words_pos_seg = []
sent_len = len(sent)
while sent_len > 0:
""" 如果句子长度小于实体最大长度,则切分的最大长度为句子长度 """
max_len = min(sent_len,self.max_len)
""" 从右向左截取max_len个字符,去词典中匹配 """
sub_sent = sent[-max_len:]
while max_len > 0:
""" 如果切分的词在实体词典中,那就是切出来的实体 """
if sub_sent in self.entity_dict:
tag = self.entity_dict[sub_sent]
words_pos_seg.append((sub_sent,tag))
break
elif max_len == 1:
""" 如果没有匹配上,那就把单个字切出来,标签为O """
tag = "O"
words_pos_seg.append((sub_sent,tag))
break
else:
""" 如果没有匹配上,又还没剩最后一个字,就去掉右边的字,继续循环 """
max_len -= 1
sub_sent = sub_sent[-max_len:]
""" 把分出来的词(实体或单个字)去掉,继续切分剩下的句子 """
sent = sent[:-max_len]
sent_len -= max_len
""" 把切分的结果反转 """
return words_pos_seg[::-1]双向最大匹配就是,将前向最大匹配的切分结果,和后向最大匹配的结果进行比较,按一定的规则选择其一作为最终的结果。
按照什么规则来选择呢?
(1)如果前向和后向切分结果的词数不同,则取词数较少的那个。
(2)如果词数相同 :
切分结果相同,则返回任意一个;
切分结果不同,则返回单字较少的那个。
网上看到一个非常好的例子,前向和后向切分后,词数相同,结果不同,返回单字少的那个结果(例子中为后向最大匹配)。

双向最大匹配的python实现如下:
#coding:utf-8
import pandas as pd
class PsegMax:
def __init__(self, dict_path):
self.entity_dict, self.max_len = self.load_entity(dict_path)
def load_entity(self, dict_path):
def max_forward_seg(self, sent):
def max_backward_seg(self, sent):
def max_biward_seg(self, sent):
"""
双向最大匹配实体标注
"""
""" 1: 前向和后向的切分结果 """
words_psg_fw = self.max_forward_seg(sent)
words_psg_bw = self.max_backward_seg(sent)
""" 2: 前向和后向的词数 """
words_fw_size = len(words_psg_fw)
words_bw_size = len(words_psg_bw)
""" 3: 前向和后向的词数,则取词数较少的那个 """
if words_fw_size < words_bw_size: return words_psg_fw
if words_fw_size > words_bw_size: return words_psg_bw
""" 4: 结果相同,可返回任意一个 """
if words_psg_fw == words_psg_bw: return words_psg_fw
""" 5: 结果不同,返回单字较少的那个 """
fw_single = sum([1 for i in range(words_fw_size) if len(words_psg_fw[i][0])==1])
bw_single = sum([1 for i in range(words_fw_size) if len(words_psg_bw[i][0])==1])
if fw_single < bw_single: return words_psg_fw
else: return words_psg_bw
if __name__ == "__main__":
dict_path = "medical_ner_dict.csv"
text = "我最近双下肢疼痛,我该咋办。"
psg = PsegMax(dict_path)
words_psg = psg.max_biward_seg(text)
print(words_psg)最终的实体打标结果为:
三:实体自动标注
接下来就两种方法来做实体自动打标,构造训练实体识别模型的样本。
一是用:实体词典+双向最大匹配,
二是用:实体词典+jieba词性标注。
医疗实体词典的格式如下,每一行是实体词和对应的标签:
肾抗针,DRU
肾囊肿,DIS
肾区,REG
肾上腺皮质功能减退症,DIS
肾性高血压,DIS
肾性贫血,DIS
肾血管,ORG
肾脏,ORG
伴脓性渗出,NBP
生理反射存在,NBP未标注的电子病历内容如下:
| 患者精神状况好,无发热,诉右髋部疼痛,饮食差,二便正常,查体:神清,各项生命体征平稳,心肺腹查体未见异常。右髋部压痛,右下肢皮牵引固定好,无松动,右足背动脉搏动好,足趾感觉运动正常。 |
首先导入必要的包,max_seg.py 就是上面写好的双向最大匹配算法。
#encoding=utf8
import os,jieba,csv,random,re
import jieba.posseg as psg
from max_seg import PsegMax
""" 医疗实体词典, 每一行类似:(视力减退,SYM) """
dict_path = "medical_ner_dict.csv"
psgMax = PsegMax(dict_path)
c_root = os.getcwd() + os.sep + "source_data" + os.sep
""" 实体类别 """
biaoji = set(['DIS', 'SYM', 'SGN', 'TES', 'DRU', 'SUR', 'PRE', 'PT', 'Dur', 'TP', 'REG', 'ORG', 'AT', 'PSB', 'DEG', 'FW','CL'])
""" 句子结尾符号,表示如果是句末,则换行 """
fuhao = set(['。','?','?','!','!'])然后把医疗实体和标签加载到jieba中,同时为了保证由多个词组成的实体不被切开,我们为实体设置较高的权重。
def add_entity(dict_path):
"""
把实体字典加载到jieba里,
实体作为分词后的词,
实体标记作为词性
"""
dics = csv.reader(open(dict_path,'r',encoding='utf8'))
for row in dics:
if len(row)==2:
jieba.add_word(row[0].strip(),tag=row[1].strip())
""" 保证由多个词组成的实体词,不被切分开 """
jieba.suggest_freq(row[0].strip())我们可以选择用jieba还是双向最大匹配来标注。
def sentence_seg(sentence,mode="jieba"):
"""
1: 实体词典+jieba词性标注。mode="jieba"
2: 实体词典+双向最大匹配。mode="max_seg"
"""
if mode == "jieba": return psg.cut(sentence)
if mode == "max_seg": return psgMax.max_biward_seg(sentence)我们来看实体标注(词性标注)的效果:
sentence = "我最近双下肢疼痛。"
""" 1: 不加词典的jieba词性标注 """
[pair('我', 'r'), pair('最近', 'f'), pair('双下肢', 'n'), pair('疼痛', 'n'), pair('。', 'x')]
""" 2: 加词典的jieba词性标注 """
[pair('我', 'r'), pair('最近', 'f'), pair('双下肢疼痛', 'SYM'), pair('。', 'x')]
""" 3: 双向最大匹配的标注 """
[('我', 'O'), ('最', 'O'), ('近', 'O'), ('双下肢疼痛', 'SYM'), ('。', 'O')]这次一共有100篇电子病历,我们按7:2:1的比例划分为训练集、验证集和测试集。
def split_dataset():
"""
划分数据集,按照7:2:1的比例
"""
file_all = []
for file in os.listdir(c_root):
if "txtoriginal.txt" in file:
file_all.append(file)
random.seed(10)
random.shuffle(file_all)
num = len(file_all)
train_files = file_all[: int(num * 0.7)]
dev_files = file_all[int(num * 0.7):int(num * 0.9)]
test_files = file_all[int(num * 0.9):]
return train_files,dev_files,test_files然后进行样本自动标注,采用的实体标注格式为BIO。
BIO格式就是说,对于实体词,第一个字标注为B,其他的字标注为I;对于非实体词,每个字都标注为O。
还有一个小细节是句与句之间要留空格。
例子如下:
我 O
最 O
近 O
双 B-SYM
下 I-SYM
肢 I-SYM
疼 I-SYM
痛 I-SYM
。 O
怎 O
么 O
办 O
? O我们把每个字的标注结果,作为一行,写入到文件中。
代码实现如下:
def auto_label(files, data_type, mode="jieba"):
"""
不是实体,则标记为O,
如果是句号等划分句子的符号,则再加换行符,
是实体,则标记为BI。
"""
writer = open("example.%s" % data_type,"w",encoding="utf8")
for file in files:
fp = open(c_root+file,'r',encoding='utf8')
for line in fp:
""" 按词性分词 """
words = sentence_seg(line,mode)
for word,pos in words:
word,pos = word.strip(), pos.strip()
if not (word and pos):
continue
""" 如果词性不是实体的标记,则打上O标记 """
if pos not in biaoji:
for char in word:
string = char + ' ' + 'O' + '\n'
""" 在句子的结尾换行 """
if char in fuhao:
string += '\n'
writer.write(string)
else:
""" 如果词性是实体的标记,则打上BI标记"""
begin = 0
for char in word:
if begin == 0:
begin += 1
string = char + ' ' + 'B-' + pos + '\n'
else:
string = char + ' ' + 'I-' + pos + '\n'
writer.write(string)
writer.close()
def main():
""" 1: 加载实体词和标记到jieba """
add_entity(dict_path)
""" 2: 划分数据集 """
trains, devs, tests = split_dataset()
""" 3: 自动标注样本 """
for files, data_type in zip([trains,devs,tests],["train","dev","test"]):
auto_label(files, data_type,mode="max_seg")
if __name__ == "__main__":
main()标注好的样本的部分内容如下:
部 O
分 O
脱 O
痂 O
。 O
双 B-ORG
侧 I-ORG
瞳 I-ORG
孔 I-ORG
正 O
大 O
等 O
圆 O哈哈,感觉很多人都是用医疗领域的数据来学习实体识别,是因为在其他领域做实体识别的效果不好吗?
五月份要认真整理一下实体识别的模型,不然就是个假NLPer。
祝大家五一节快乐啊!
END
推荐阅读
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
深度学习如何入门?这本“蒲公英书”再适合不过了!豆瓣评分9.5!【文末双彩蛋!】
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
可解释性论文阅读笔记1-Tree Regularization
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。





