NTIRE2020图像去模糊冠军方案分享,首次解决跨设备部署问题
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~

paper:https://arxiv.org/abs/2004.12599
你还在为
困惑于空有高性能AI模型而无法进行手机端部署困惑吗?不妨看一下该文的思路,也许它会为你提供一个不错的思路。本文是联发科的研究员结合其所设计的NTIRE2020图像去模糊(智能手机赛道)竞赛冠军模型而总结的一份心得,笔者真心觉得这篇文章写得不错,虽然有些地方写得比较简单笼统。
摘要
近年来,图像增强与复原功能(如超分、去模糊等)已成为终端设备(如手机、电视、平板等)的重要功能。然后,大部分SOTA网络存在极高的计算复杂度问题,这导致其难以在终端设备部署(主要原因:推理延迟难以接受)。与此同时,还在这样的现象:相同的模型在不同的终端设备上存在极大的推理延迟差异(原因:不同设备的加速器各不相同,如华为的麒麟芯片、小米的骁龙芯片、苹果的A13芯片等)。
在这篇文章中,联发科的研究员们做了这样的总结:跨手机设备具有更好的质量-延迟这种的轻便型网络架构(portable network architectures)搜索。作者还进一步分析了常用网络优化技术在图像去模糊任务上的有效性。这篇文章提供了详尽的实验与比较分析以更好的挖掘图像质量-推理延迟的均衡问题。通过上述所有工作,作者成功的采用深度学习加速技术将图像去模糊方案在手机端进行部署。
据笔者微薄经验所知,该文当属首篇解决图像去模糊跨设备部署问题的研究。基于该文所提提出的部署指南而设计的模型取得了NTIRE2020图像去模糊(智能手机赛道)竞赛冠军。笔者只能深深的竖个大拇指,赞!
背景介绍
基于深度学习的图像复原与增强取得了前所未有的性能与直觉感知突破,其中图像超分、图像去模糊又是手机设备重要特性。但由于手机拍照图像的高分辨率、任务的pixel-to-pixel特性,导致相关深度学习方法需要非常高的计算复杂度与内存,进一步导致手机端的部署成为极大挑战。
为更好的促使图像复原类深度学习方法的产品化落地,社区举办了PRIM2018(以Razer与华为P20作为测评硬件平台)与NITRE2020(采用Google Pixel4作为测评硬件平台)竞赛;不同的公司与机构均花费精力研发AI芯片(如苹果A13芯片、华为麒麟芯片、联发科魔石芯片、高通骁龙芯片、三星猎户座芯片);一些研究机构还提出并搭建的AI Benchmark;与此同时,学术界也在尝试轻量型网络架构的设计以降低计算复杂度(比如FALSR、IMDN、CARN等);另一种加速方案是模型优化(含模型剪枝、模型量化)。
然而图像复原类的模型优化却甚少有研究见稿,更进一步,模型的性能与硬件设备存在高度相关性。因此,模型的可移植性是其手机端部署的另一个关键影响因子。最后一点,现有的Benchmark缺乏能真实反映实际应用场景(如720p输入分辨率)的设置。
在这篇文章中,作者从图像质量与推理延迟角度,对不同图像去模糊方法跨手机设备时的性能比较分析,从实际应用场景方向去调整配置信息。该文的主要贡献包含:
-
可移植网络架构:作者对跨设备且具有更好质量-延迟性能的可移植网络架构进行了调研,为实际应用场景提供了一组可实用的应用配置; -
模型优化:作者分析主流模型优化技术在图像去模糊任务上的有效性,证实:感知INT8量化会存在明显的性能下降,而16bit后量化则可以取得媲美FP32的性能; -
跨设备 质量-延迟分析:从图像质量-推理延迟角度出发,作者对不同图像去模糊网络跨设备的性能进行评估。基于该研究,作者成功的在三款手机设备(配合深度学习加速芯片)上成功部署图像去模糊。
正文
在进行正文内容介绍之前,先提供一些更实际的应用配置说明。
-
测试图像的分辨率为720p,即 ;
-
从定性(视觉感知)与定量(PSNR)两个角度进行分析;
-
为构建公平的跨设备评测,作者采用NNAPI框架作为推理度。
图像去模糊数据集
图像去模糊是该研究的一个基准参考点,其训练数据采用REDS(NTIRE2020也采用的该数据集),该数据集包含300个视频片段(每个片段包含100帧
大小的图像),其中240用于训练,30用于验证,30用于测试。
可移植网络架构搜索

以上图为例进行说明,首先对EDSR、SGN、RND、UNet等架构进行魔改以适配图像去模糊任务,这是准备阶段的工作。
-
Step-1:该步工作是为了寻找具有最高PSNR的网络结构,从中选出了UNet架构; -
Step-2:目标转向提升UNet跨手机设备的可移植性。在硬件加速器中,相关优化往往仅聚焦在有限的操作,比如卷积、池化、激活等等。因此,具有高定性或定量质量的模型可能具有非常有效的可移植性,因其 OP可能在设备上未进行优化。借助于神经网络优秀的近似能力,可以通过其他优化过的OP进行替代。基于该步的研究,我们可以自由的根据需要(高质量或者低延迟)选择最适配的网络。 -
Step-3:该步工作从模型剪枝角度进一步提升模型的可部署性。作者采用结构化剪枝进行了实验对比分析,见上图的Step-3信息。注:结构化剪枝有助于提速、减少MAC。 -
Step-4:该步工作主要是采用量化技术进一步提升模型的可部署性。尝试了两种量化技术: Post-training quantization与Quantization-aware training。
部署环境:软件与硬件
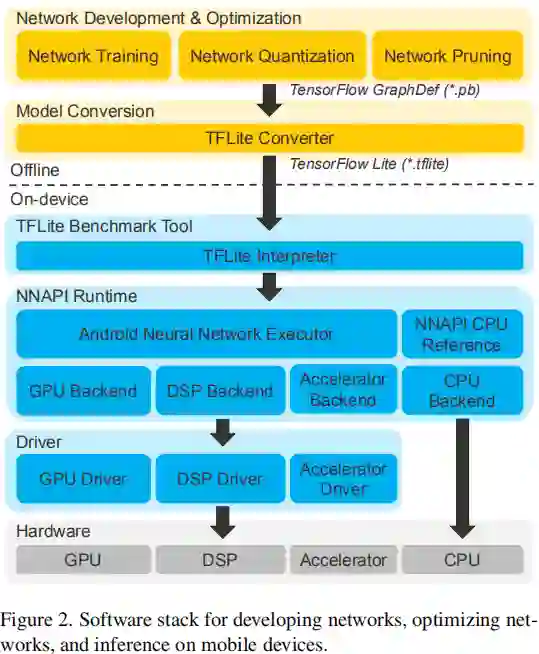
如上图所示,该文采用TFLite与TFLite Benchmark Tool评估不同手机设备的推理延迟。NNAPI (它为TFLite提供底层支持)是不同平台广泛支持的统一推理框架。为更公平的进行比较,作者采用NNAPI进行手机端部署。最后需要补充的是:作者将优化过的可移植网络跨设备部署并进行实验分析。
-
TFLite Benchmark Tool:可用于PC端与安卓端模型延迟评估。它提供有多种手机端加速,比如ARM-CPU与GPU下的浮点加速库XNNPACK。NNAPI在安卓端支持浮点与INT8定点推理;Hexagon支持高通DSP的INT8定点推理。基于上述工具,作者进行了不同设备的延迟推理分析。 -
Android NNAPI:它是安卓端加速深度学习操作的库。它为多种深度学习框架(如TFLite、Caffe2)提供底层支持。平台使用者可以为NNAPI设定加速策略:浮点型或者INT8定点性。 -
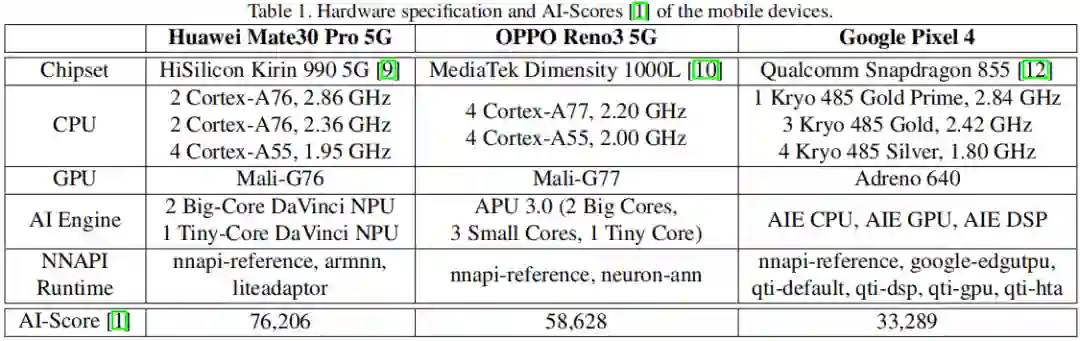
硬件加速:本文研究主要聚焦于三款带AI芯片的手机:华为Mate30Pro,OPPO Reno3,Google Pixel4.下表给出了不同型号手机的硬件参数配置以及AI评分。
实验结果与分析
该部分内容从模型训练与评价、网络架构选择、OP层面的可移植性分析、网络与优化方法之间的相互影响讨论等方面展开分析与介绍。
模型训练与评价
作者采用Tensorflow进行模型训练,训练数据方面每个训练数据被crop成15个patch,每个patch大小为 ,共计360000训练数据。验证数据参考NTIRE2020,每10帧挑1帧,共计300帧用于计算PSNR。
所有模型分别在2080Ti显卡上训练1M步,BatchSize=16,选择
损失,Adam优化,初始学习率设为
,权值衰减因子0.98,学习率指数下降,每5K迭代进行指数衰减。所有卷积层的参数通过Xavier方法进行初始化。
为评估设备端的延迟,作者采用TFLite Benchmark Tool,相关参数设置为use_nnapi=True, allow_fp16=True, num_runs=10, num_threads=4,同时,作者还采用taskset命令行降低CPU时间的差异性。
质量引导的网络架构
为搜索不同的网路架构,作者采用了几种主流的架构:UNet、Inception-ResNetV2-FPN、EDSR、RDN、DBPN、SGN等。为更公平的对比,对所选择网络结构进行了魔改(比如移除EDSR与RDN中的上采样单元,移除DBPN中的首个up-projection单元)以适配图像去模糊任务,同时具有相近的MAC(
)。与此同时,作者并未考虑含形变卷积、自注意力的网络(手机端设备不支持这些OP)。除了前面所提到的以外,对训练方案不做限制,比如可以采用GAN进行训练。
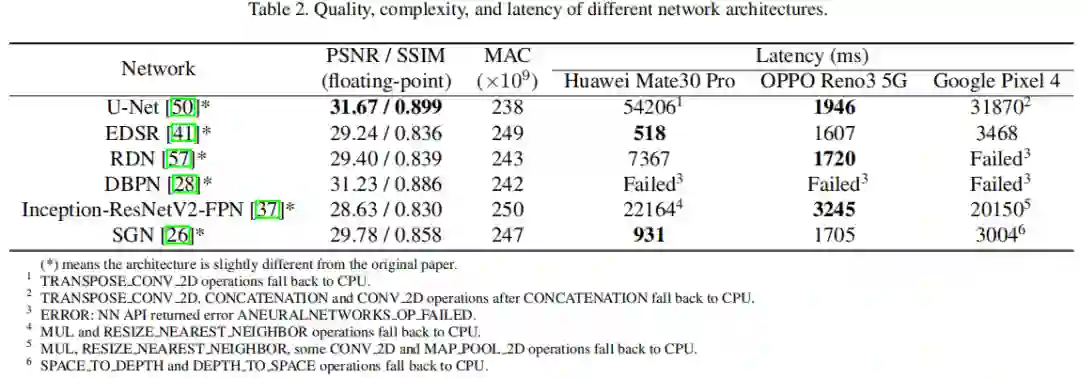
上表总结了候选网络的PSNR、MAC信息以及在三款手机设备上的推理延迟。从图像质量角度来看,UNet架构优于其他架构,具有更高的PSNR。作者还观察到一个有意思的发现:不被加速器支持的操作Transpose_conv_2d会导致数据退回到CPU端进行推理计算,这导致了相关网络的无法进行加速,进而导致高延迟。
延迟引导的可移植OP
前面讨论了跨设备不支持的OP会导致不可思议的高延迟。Transpose_conv_2d的作用是进行上采样,因此为更好的进行跨设备部署,需要采用其他方案(DepthToSpace、ResizeBilinear)进行替代。作者还对这种替代协同ReLU与PReLU进行分析。
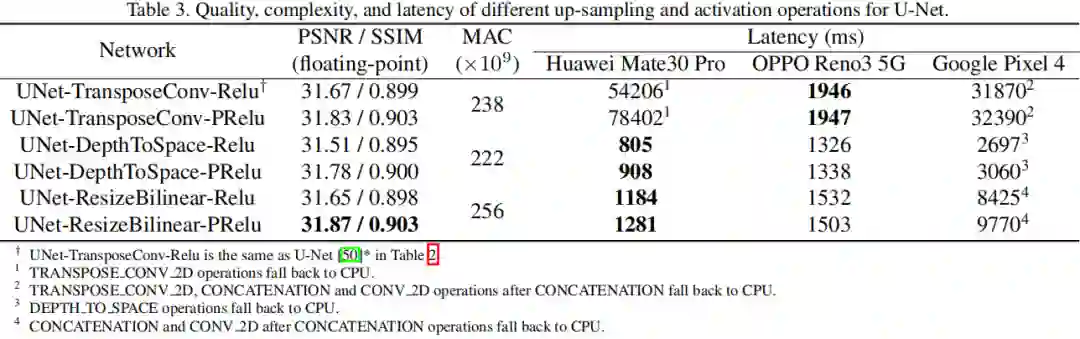
正如上图所示,这种替代可以最大可能地避免回退到CPU端推理发生。通过这种替代方式,我们可以从中选择具有最佳性能与推理延迟模型。作者选择UNet-ResizeBilinear-PReLU进行后续的实验分析。
模型优化
接下来,作者UNet-ResizeBilinear-PReLU进行模型优化以进一步提升其性能。相关实验结果见下图。
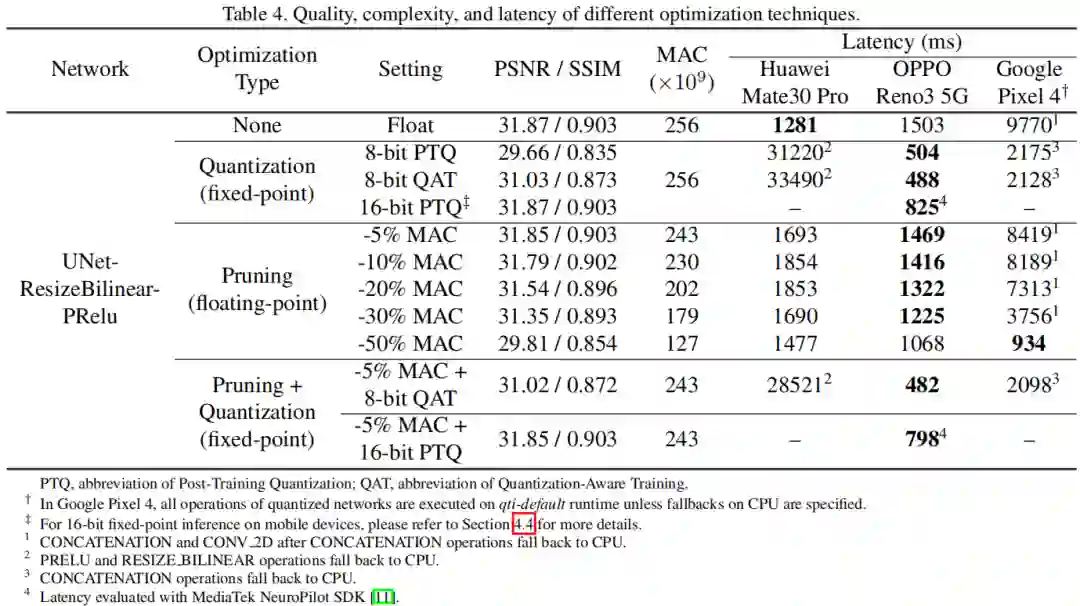
从上图可以看出:
-
8-bit-PTQ会导致2dB的PSNR指标下降;8-bit-QAT仍会导致0.8dB的PSNR指标下降;而16-bit-PTQ则可以保持与FP32相同的性能。
-
除了华为手机外,OPPO与Google手机都可以看到量化加速,主要原因:华为Mat30手机的AI芯片不支持量化 Resize_Bilinear。
-
需要注意的一点:NNAPI不支持16-bit定点推理,因此需要平台提供者提供配套的SDK(高通的SNPE支持16-bit定点推理,但需要HTA硬件,而HTA运行库并不支持Google Pixel4;而对于华为的HiAI SDK尚未发现支持16bit定点推理的信息)。故而,作者仅记录了 联发科 NeuroPilotSDK的16-bit定点推理速度(OPPO手机采用的联发科芯片)。
-
在不同MAC配置下,除了华为手机外,其他手机军科院看到不同程度的推理改善。令人惊讶的是:在Google Pixel4上,30%MAC降低,可以取得60%推理加速而仅造成0.5dB的PSNR指标降低。一个潜在研究方向: 硬件相关的网络架构搜索。
-
量化与剪枝组合可以进一步改进推理延迟。
质量引导的消融实验
这部分内容将从最大化图像角度角度进行模型优化的选择性分析。

从上图可以看出:16-bit-PTQ可以完美的保留浮点模型的视觉质量,而8-bit-PTQ与8-bit-QAT则会导致不同程度的量化误差。当通过剪枝导致50%MAC下降时,可以看到明显的模糊现象。
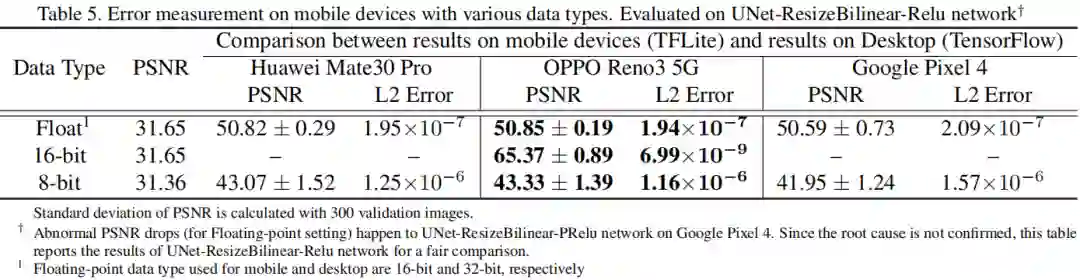
上图给出了浮点模型与量化模型结果的L2逐像素误差与PSNR差异。从中可以看出:8-bit量化模型的误差明显高于16-bit量化模型和FP32模型。一般来讲,手机端与PC端的误差越小,两者的结果越相近。该部分实验为手机端量化模型部署提供更为深入的质量评价分析。
讨论与总结
通过对比三个平台的软件、硬件差异,本文对几种部署问题进行总结与归纳。相关结论可以归纳为以下三点:
-
在进行跨平台部署时, 推理延迟存在高度不一致性问题,某些平台呈现出高延迟现象。幸运的是,我们可以通过 OP即的替代进行更好的移植部署;
-
模型优化技术并不会保持跨平台推理延迟一致性下降,比如华为Mate30Pro甚至会导致更高的延迟,Google Pixel4的推理延迟与MAC并未呈现线性关系。
-
推理延迟并不与输入分辨率保持线性关系,见下图。当分辨率提升到 时,Google Pixel4呈现出巨大的推理延迟提升。

上述所提到的性能陷阱(performance pitfalls)使得模型的手机端部署极具挑战。需要从多个维度(架构的可移植性、模型优化、质量-推理跨设备均衡)同时考虑优化以确保模型的手机端部署。
在 极市平台 后台回复 deploy 即可获取本文论文下载链接。
推荐阅读:

△长按关注极市平台,获取最新CV干货

觉得有用麻烦给个在看啦~



