WDSR (NTIRE2018 超分辨率冠军)【深度解析】
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者 | 木盏
编辑 | 小极
来源 | https://blog.csdn.net/leviopku/article/details/85048846
原文 | http://bbs.cvmart.net/articles/291
s超分辨率(super-resolution)的通俗解释就是:将低分辨率的图像通过算法转换成高分辨率图像。听起来似乎很神奇,这样是不是可以把低清电影转换成高清了?就现在来看,基于深度学习的超分辨率(简称SR)已经达到了amazing的效果。
这篇博文要解析的算法叫做WDSR,来自UIUC的华人学生JiaHui Yu的论文。在SR界有一个比赛,叫做NTIRE,从2016年以来也才举办三届,不过自2017年开始,NTIRE就逐渐被全球学者所关注。NTIRE的冠军基本是保送CVPR的,NTIRE成长为SR界的COCO也是指日可待的。
NTIRE2018链接:http://www.vision.ee.ethz.ch/ntire18/
而WDSR就恰好是NTIRE2018的冠军,所以,目前看来WDSR就是SR界的state-of-the-art。WDSR文章目前只是挂在arxiv上,未来也许会发表在CVPR2019或ICCV2019上,所以,我们可以在论文正式发表之前了解到这篇优质算法。
介于很多同学更迫切的期待是实现而不是理解,所以我会在近期出一个复现教程。而这篇博文呢,主要讨论WDSR的算法思想。本文目的在于使得各种基础的同学看过都能有所收获,所以,我会花不少篇幅来介绍算法背景,有一定基础的同学可以跳着看。
首先按照国际惯例,直接给论文地址:https://arxiv.org/abs/1808.08718
前言
通常的超分辨率分两种:SISR和VSR。前者叫做单图像超分辨率,后者叫做视频超分辨率。我们通常理解的超分辨率都是指SISR,我们只需要输入一张低分辨率图像而获得高分辨率图像的输出。 而VSR会利用视频的时间关联性来获得对某一帧的SR。本文的算法就是针对前者。
最早将深度学习用到SISR的居然是Kaiming大神等人在ECCV2014年提到的SRCNN,那时并没有像NTIRE这样相关的比赛,只有少量开源数据集可以玩玩。至此,对kaiming大神的敬仰又多了一分。
ECCV2018有一篇关于小物体目标检测的论文让人印象深刻,迅速引起了大家的关注,这篇文章叫SOD-MTGAN,文中巧妙利用了SR对小物体进行放大,然后得到更高的小物体检测准确率。这也是木盏开始研究SR的原因,因为SR被证明是有利于目标检测和跟踪的。
SOD-MTGAN论文地址:
http://openaccess.thecvf.com/content_ECCV_2018/papers/Yongqiang_Zhang_SOD-MTGAN_Small_Object_ECCV_2018_paper.pdf
我觉得在前言里面可以给出实现效果,这样可能更容易激起同学们想要探索这个算法的兴致。以下是我复现的算法效果:


一目了然,左图是低分辨率图像,右图是对WDSR retrain之后,复现的效果。这里的scale=2,就是边长放大两倍,即像素密度增加4倍,在下文中我会用X2来描述这种upscale。同理,X3表示边长放大3倍,X4表示边长放大4倍。一般来说,X2,X3和X4这三种规模用得比较多。上图是X2效果图。
评价指标
如果来描述SR效果呢?业界有个约定俗成的指标,叫做PSNR,即峰值信噪比。这个指标可以比较你SR结果图和ground truth(即原高清大图)之间的差距;此外,还有一个指标叫做SSIM,即结构相似性。这个指标与PSNR一样,也可以评价你SR的恢复效果。
数据集
SR的数据集是数据来源最容易的数据集了,没有之一。因为你无须标注,只需准备一些高清图像,然后通过下采样把高清变成低清图像,这样就获得了一一对应的counterpart。就可以用以训练了。当然,对训练数据不同的下采样方法也会影响最后的算法性能,在这里不做重点讨论。
NTIRE2018指定的训练数据集是DIV2K,这个数据集只有1000张高清图(2K分辨率),其中800张作为训练,100张作为验证,再100张作为测试。DIV2K也提供了对高清图bicubic采样的低清图像,供以训练,就是说,下采样获得低分辨率图像这一步不用自己做了。
自制的数据对比样本:

WDSR
在这里正式对WDSR算法进行剖析。这里的W表示的是wide,即具有更宽泛的特征图。怎么理解更宽泛的特征图呢?作者对激活函数之前的特征图channel数增多,称为特征图更宽泛。这个描述怪怪的,不过就是这么个意思。
很多同学会认为SR算法一般会跟生成式算法GAN产生联系,然而事实并不是这样。确实有利用GAN来做SR的,不过目前顶尖的SR算法都是基于CNN的,WDSR也不例外。WDSR是基于CNN的SR算法。
为什么基于CNN能做到SR?这个疑问先留在这里,待会儿好好解答。
基于CNN的SR算法自2014年何恺明大神的SRCNN以来,逐渐发展成如今的SR,具有四大法宝:
1. 上采样方法。我们从低分辨率图像转换到高分辨率图像,是不是要涉及上采样呢?100x100到400x400肯定要涉及上采样方法的。如果研究过自编码器等算法的同学会知道反卷积是图像深度学习种常用的上采样方法,在yolo v3中用到的上采样方法也是反卷积。事实上,反卷积这种上采样方法在目前一线的SR算法中是遭到鄙视的(虽然SOD-MTGAN中还在用)。不用反卷积用什么呢,有一种叫做pixel shuffle的新型卷积方法在CVPR2016年被提出来,也叫做sub-pixel convolution。这种新型卷积就是为SR量身定做的,这也解释了为什么目前基于CNN的SR能比基于GAN效果更好了;
2. 超级深度&循环神经网络。神经网络深度的重要性相比无须多言了,在不少前辈们的研究成果表现,神经网络的深度是影响SR算法性能的关键因素之一。同时,利用循环神经网络的方法,可以增加权重的复用性。WDSR并没有用到RNN,可以跳过这个;
3. 跳跃连接。就如果Resnet做的那样,将前层输出与深层输出相加连接。一来呢,可以有效解决反向传播的梯度弥散,二来呢,可以有效利用浅层特征信息。目前的一线SR算法都会含有resblocks,WDSR也不例外。
4. 标准化层。BN层已经是说烂了的trick之一了,各种算法似乎都离不开BN。但batch normalization也不是唯一的normalization方法。如我其他博文中提到的LN,IN还有kaiming大神提出的GN。而WDSR算法采用了weight normalization的方法。
基于上面四个trick,作者提出了WDSR-A模型结构,我们可以看看长什么样子:
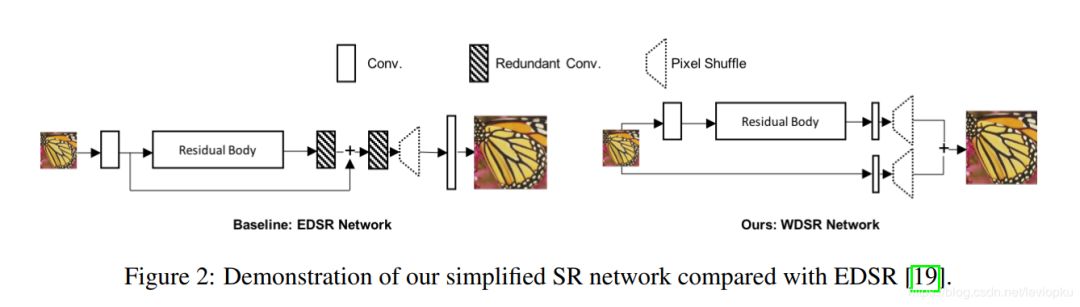
左边的EDSR呢,是NTIRE2017的冠军,自然要被2018的冠军吊打的。我们直接看右边,网络结构是超级简单的, residual body就是一系列的resblock组到一起,可以看作是一个自带激活函数的非线性卷积模块。上图的模块只包含三种:res模块,conv模块和pixel shuffle模块。只有pixel shuffle模块要特别注意。
WDSR在EDSR上的结构提升,一方面是去除了很多冗余的卷积层,这样计算更快。另一方面是改造了resblock。我们一分为二来看,去除冗余的卷积层(如上图阴影部分)作者认为这些层的效果是可以吸收到resbody里面的,通过去除实验之后,发现效果并没有下降,所以去除冗余卷积层可以降低计算开销。
改造resblock的方法如下:
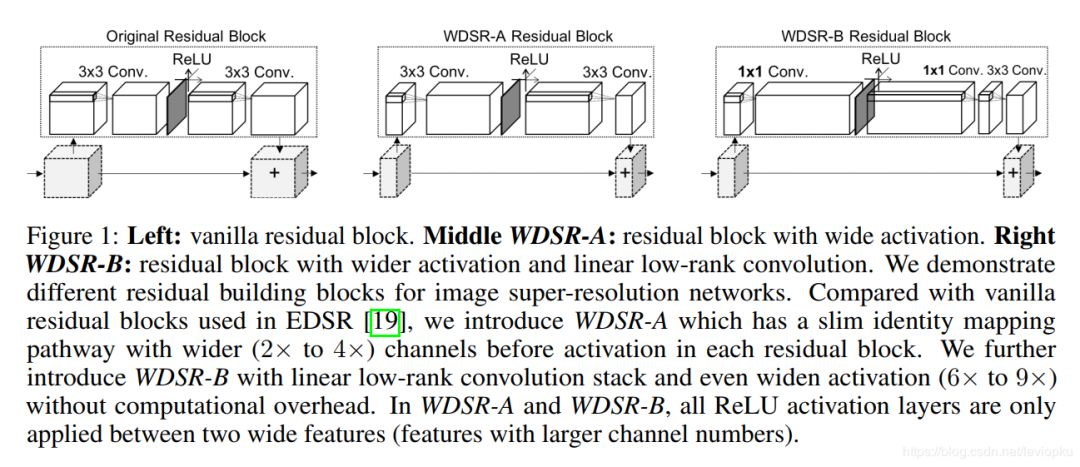
左图呢就是ESDR的原始resblock,中间是WDSR-A,右边的是WDSR-B。作者在文中提出了两个版本的WDSR,这两个版本的区别就是resblock不同而已。 对于EDSR中的resblock,我们成为原始resblock,relu是在两个卷积运算中间,而且卷积核的filter数较少;而WDSR-A是在不增加计算开销的前提下,增加relu前卷积核的filter数以增加feature map的宽度。怎么理解这个操作呢?我们有神器neutron,用neutron分别打开ESDR和WDSR的结构图我们可以看到:
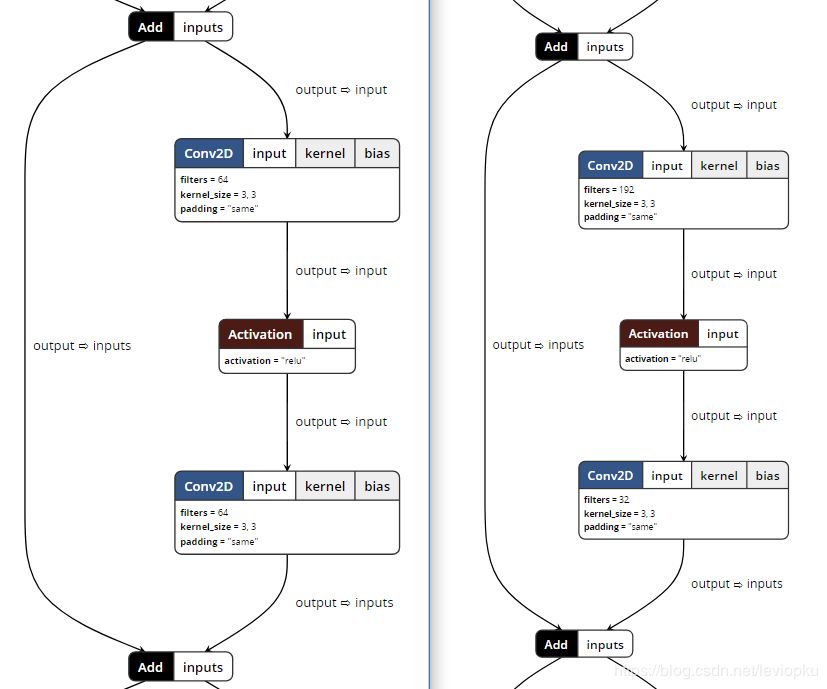
上图左边就是ESDR,右边就是WDSR-A。我们可以从relu前卷积核的filter数看到, 后者(192)是前者(64)的3倍。不过前者在relu后的filter数是后者的2倍。作者主要提的trick就是增加激活函数前的特征图的channel数。这样效果会更好。同样,我们可以对WDSR-B一目了然:
WDSR-B进一步解放了计算开销,将relu后的大卷积核拆分成两个小卷积核,这样可以在同样计算开销的前提下获得更宽泛的激活函数前的特征图(即channel数可以更多)。
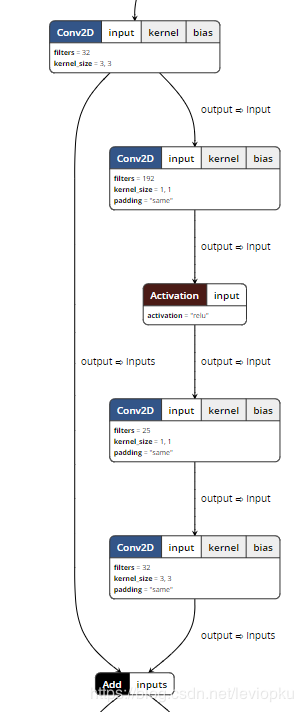
所以,对于同样计算开销的前提下,表现性能是:WDSR-B > WDSR-A > ESDR。
Weight Normalization vs Batch Normalization
WN应该算是WDSR的最后一个重要的trick了。WN来自openAI在NIPS2016发表的一篇文章,就是将权重进行标准化。
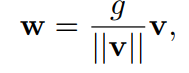
对于WN我只是粗略了解,做一个简单的||v||表示v的欧几里得范数,w, v都是K维向量,而g=||w||,是一个标量。w是v的次态。 g/||v||这个标量就是为了线性改变向量v,从而使得||w||更靠近g。这样来使得权重w的值在一个规范的范围内。注意,WN和BN的操作有很大的不同。
根据作者的实验表明,WN可以用更高的学习率(10倍以上),而且可以获得更好的训练和测试准确率。
实验结果
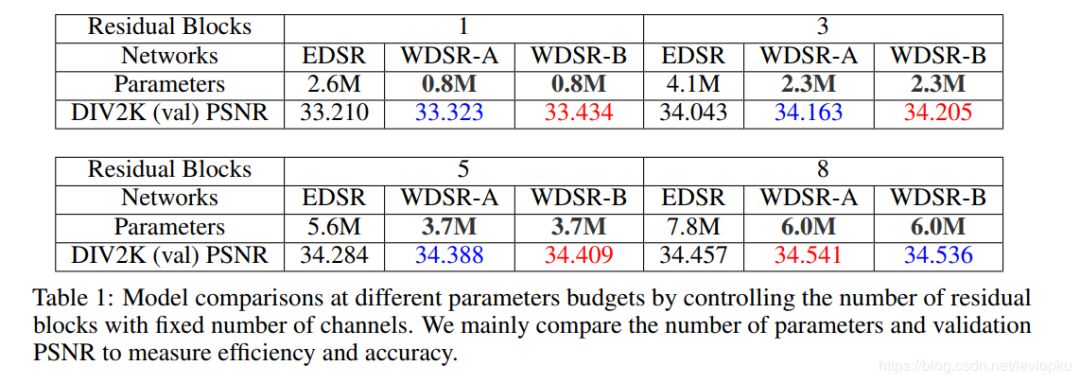
上表数据主要是用PSNR作为指标进行比较,同时,特别讲究参数量,因为参数量直接决定计算开销。上述结果还是有些谦虚的,我用6M参数的WDSR-A测试DIV2K的val PSNR可以达到37多。 就我目前看的所有SR文章来看,对于DIV2K数据集能达到PSNR 35+的算法也就WDSR了。
总结
WDSR具有以下创新点:
提高relu前的特征图channel数;
将大卷积核拆分成两个低级卷积核,节省参数,进一步在同参数的情况下提高relu前的特征图channel数;
加入weight norm。
*延伸阅读
超分辨率技术如何发展?这6篇ECCV 18论文带你一次尽览
极市干货|闫霄龙-基于开源ImagePy工具的图像处理算法解析(视频+PPT)
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~

觉得有用麻烦给个好看啦~




