AAAI 2019 | 把Cross Entropy梯度分布拉「平」,就能轻松超越Focal Loss
机器之心专栏
来源:PaperWeekly
单阶段物体检测(One-stage Object Detection)方法在模型训练过程中始终面临着样本分布严重不均衡的问题,来自香港中文大学的研究者们在论文 Gradient Harmonized Single-stage Detector 提出了一个新的视角——梯度分布上看待样本数量和难易不均衡。直接把 cross entropy 产生的 gradient distribution 标准化到 uniform 就可以轻松训练单阶段物体检测模型。
该论文已经被 AAAI 2019 会议接受为 Oral 论文,基于 PyTorch+MMDet 的代码已经放出。
作者丨Lovely Zeng
学校丨CUHK
研究方向丨Detection


引言
物体检测的方法主要分为单阶段与两阶段两大类。虽然两阶段的物体检测器在准确率上的表现往往更优,但单阶段检测器因其简洁的结构和相对更快的速度同样得到了研究者们的重视。
在 2017 年,Focal Loss 的作者指出了单阶段检测器中样本类别(前景与背景)严重不均衡(class imbalance)的问题,并通过设计一个新的损失函数来抑制大量的简单背景样本对模型训练的影响,从而改善了训练效果。
而在这篇论文中,研究者对样本不均衡的本质影响进行了进一步探讨,找到了梯度分布这个更为深入的角度,并以此入手改进了单阶段检测器的训练过程。
实际上,不同类别样本数不同并不是影响单阶段检测器的训练的本质问题,因为背景样本虽然大部分非常容易识别(well classified),但其中也会存在着比较像某类物体的难样本(hard negative),而前景类中也有许多网络很容易正确判断的样本(easy positive)。所以产生本质影响的问题是不同难度样本的分布不均衡。
更进一步来看,每个样本对模型训练的实质作用是产生一个梯度用以更新模型的参数,不同样本对参数更新会产生不同的贡献。
在单阶段检测器的训练中,简单样本的数量非常大,它们产生的累计贡献就在模型更新中就会有巨大的影响力甚至占据主导作用,而由于它们本身已经被模型很好的判别,所以这部分的参数更新并不会改善模型的判断能力,也就使整个训练变得低效。
基于这一点,研究者对样本梯度的分布进行了统计,并根据这个分布设计了一个梯度均衡机制(Gradient Harmonizing mechanism),使得模型训练更加高效与稳健,并可以收敛到更好的结果(实验中取得了好于 Focal Loss 的表现)。
梯度均衡机制
首先我们要定义统计对象——梯度模长(gradient norm)。考虑简单的二分类交叉熵损失函数(binary cross entropy loss):
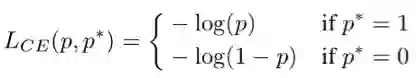
其中 p=sigmoid(x) 为模型所预测的样本类别的概率,p* 是对应的监督。则其对 x 的梯度(导数)为:
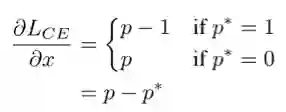
于是我们可以定义一个梯度模长,g=|p-p*|。
对一个交叉熵损失函数训练收敛的单阶段检测模型,样本梯度模长的分布统计如下图:
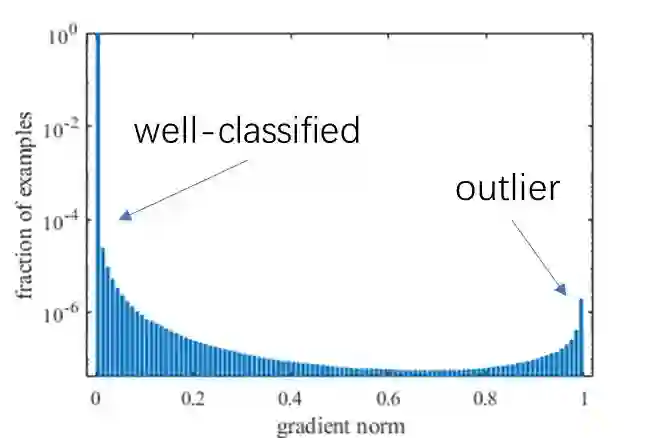
可以看到,绝大多数样本都是十分容易预测的(well-classified),这些可以被准确预测的样本所占的比重非常大,正因如此图中采用对数坐标来更清楚地展示分布。
此外,还可以发现在 g 接近 1 的时候,样本比例也相对较大,研究者认为这是一些离群样本(outlier),可能是由于数据标注本身不够准确或是样本比较特殊极难学习而造成的。对一个已收敛的模型来说,强行学好这些离群样本可能会导致模型参数的较大偏差,反而会影响大多数已经可以较好识别的样本的判断准确率。
基于以上现象与分析,研究者提出了梯度均衡机制,即根据样本梯度模长分布的比例,进行一个相应的标准化(normalization),使得各种类型的样本对模型参数更新有更均衡的贡献,进而让模型训练更加高效可靠。
由于梯度均衡本质上是对不同样本产生的梯度进行一个加权,进而改变它们的贡献量,而这个权重加在损失函数上也可以达到同样的效果,此研究中,梯度均衡机制便是通过重构损失函数来实现的。
为了清楚地描述新的损失函数,我们需要先定义梯度密度(gradient density)这一概念。仿照物理上对于密度的定义(单位体积内的质量),我们把梯度密度定义为单位取值区域内分布的样本数量。
具体来说,我们将梯度模长的取值范围划分为若干个单位区域(unit region)。对于一个样本,若它的梯度模长为 g,它的密度就定义为处于它所在的单位区域内的样本数量除以这个单位区域的长度 ε:
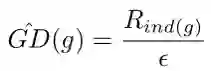
而梯度密度的倒数就是样本计算 loss 后要乘的权值:
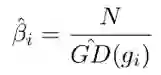
这里乘样本数量 N,是为了保证均匀分布或只划分一个单位区域时,该权值为 1,即 loss 不变。
由于这个损失函数是为分类设计的,所以记为 GHM-C Loss。下面我们通过与传统交叉熵算是函数以及 Focal Loss 的比较,来进一步解释 GHM 的作用:

左图为样本梯度模长的分布。中图为不同损失函数对样本梯度产生的作用,横坐标为在交叉熵(CE)损失函数下样本的梯度模长,纵坐标为新的损失函数下同样的样本新的梯度模长,由于范围较大所以依然采用对数坐标展示。其中浅蓝色的线为交叉熵函数本身,作为参考线。
可以看到,Focal Loss 本质上是对简单样本进行相对的抑制,越简单的样本受抑制的程度越大,这一点和 GHM-C 所做的均衡是十分相似的。此外,GHM-C 还对一些离群样本进行了相对的抑制,这可以使得模型训练更具稳定性。
右图为不同损失函数下,各种难度样本的累计贡献大小。由此可以看出,梯度均衡机制的作用就是让各种难度类型的样本有均衡的累计贡献。
在分类之外,研究者还对于候选框的回归问题做了类似的统计并设计了相应的 GHM-R Loss。
需要指出的是,由于常用的 Smooth L1 Loss 是个分段函数,在 L1 的这部分倒数的模长恒定为 1,也就是偏差超过临界值的样本都会落到 g=1 这一点上,没有难度的区分,这样的统计并不合理。为了解决这个问题,研究者引入了 ASL1 Loss:
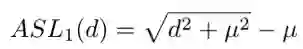
在此基础上对梯度模长的分布进行统计并实施均衡化的操作。
实验结果
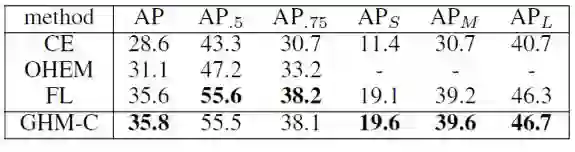
在 COCO 的 minival 集上,GHM-C Loss 与标准 Cross Entropy Loss,使用 OHEM 采样下 Cross Entropy,以及 Focal Loss 的比较如下:
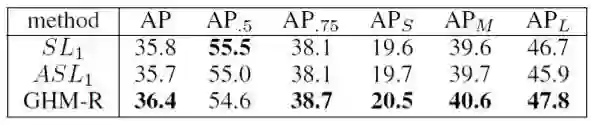
GHM-R 与 Smooth L1 Loss 以及 ASL1 Loss 的 baseline 比较如下:
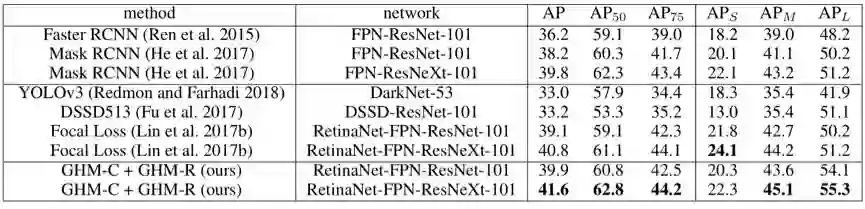
在 COCO test 集上,GHM 与其他 state-of-the-art 的方法比较如下:
此外,在 AAAI 2019 的演示文稿中,研究者还展示了在 pascal voc 2007 这样的小数据集上,GHM 相对于 Focal Loss 不需要过多的 warmup iteration 就可以保持训练的稳定:

讨论
这篇研究的主要贡献是提供了一个新视角,较为深入地探讨了单阶段检测中样本分布不均衡所产生的影响及解决方案。
此研究对梯度模长的分布进行统计并划分单位区域的方式,实际上可以看作是依据梯度贡献大小对样本进行聚类的过程。而这里的梯度只是模型顶部获得的偏导数的大小,并不是全部参数对应的梯度向量,所以聚类依据可能有更严谨更有区分度的选取方式,然而统计整体参数的梯度分布会极大增加计算量,所以本研究中的统计方式仍是一种快速且有效的选择。
此研究进行均衡化操作实际上是以各梯度模长的样本产生均匀的累计贡献为目标的,但是这个目标是否就是最优的梯度分布,暂时无法给出理论上的证明。从实验结果上,我们可以认为这个目标是明显优于无均衡的分布的。然而研究者认为,真正的最优分布难以定义,并需要后续的深入研究。

本文为机器之心专栏,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com