一分钟劝退word2vec
原文发表于公众号:一个算卦工程师的自白,欢迎拉到文末关注,接收作者各种靠谱和不靠谱的推送。
前段时间读了一篇文章:https://multithreaded.stitchfix.com/blog/2017/10/18/stop-using-word2vec/
很霸气的名字,或许可以翻译成“别TM再用word2vec了!”哈哈。核心思想是提出了一种通过计数加上矩阵分解得到词向量的方法,这种方法非常简单直观,相比word2vec又是Negative Sampling又是Hierarchical Softmax的,无论是理解起来还是实现起来都要简单很多。下面分别介绍几个主要步骤。
构建Skipgram概率
要构建Skipgram概率,首先需要构建Skipgram计数,就是两个词在指定距离之内共同出现多少次,如下图所示:

有了这个之后,Skipgram概率指的就是这个计数除以所有的Skipgram pair数。
计算PMI
PMI=Point-wise Mutual Information,计算方法是将如下的结果取log:

这个算式的含义是:分子是两个词的skip计数,分子是两个词边缘概率的乘积。所以能看出PMI反应的是两个词的紧密关系,如果两个词关系很紧密,那么这个比值会很大,如果相对独立,则比值接近1,如果是反向相关,则比值会远小于1。
构造PMI矩阵
这一步很简单,就是把上一步得到的词之间两两的PMI构造成一个矩阵,但需要注意的是,因为很多不相关的词之间PMI很低,所以需要将这些值设为0,得到一个稀疏矩阵。阈值可以根据数据集效果来定。
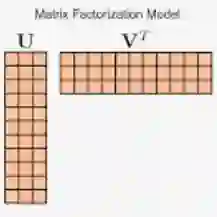
对PMI矩阵做SVD分解
SVD分解之后在第一个矩阵中就得到了每个词对应的向量表示,其中向量大小可以通过参数来控制。这个向量就可以用来计算相关性了。
有一点比较有趣的是,SVD分解之后的向量是正交的,而具有正交性质的两个向量可以解释类似king-queen=man-woman的,因为可以理解为king和man在性别这个坐标轴上是位置相同的。
总结
所以总结起来这种方法不仅实现简单,同时还保留了word2vec可以进行向量运算的良好性质。但不太确定的是这样得到的向量能否用在DNN网络训练中,例如嵌入表示的初始化。这种方法还有一个潜在问题就是词汇量太大的话SVD的O(n^3)的计算复杂度会承受不了,但所幸有基于SGD的SVD优化方法,可以缓解这种问题。
但话虽这么说,效果好不好,各位看官还是要在自己的数据上试过才知道。
猜你喜欢:【读论文】Neural Word Embedding as Implicit Matrix Factorization