Uber AI 研究院深度解构 ICLR 2019 最佳论文「彩票假设」!

AI 科技评论按: 作为某种程度上的技术黑盒,神经网络的诸多工作原理仍然有待探索。年初,Frankle 和 Carbin 的论文「 The Lottery Ticket Hypothesis:Finding Sparse,Trainable Neural Networks」提出了一种生成稀疏的高性能网络的简单方法,可以有效进行网络剪枝,这一突破性进展也让这篇论文成为 ICLR 2019 最佳论文的得主之一。在本文,Uber AI 研究院对这一「彩票假设」成果进行了深度解构,意外得到了具备强大剪枝能力的通用「超级掩模」(Supermask)!雷锋网 AI 科技评论编译如下。
在 Uber,我们利用神经网络从根本上提升我们对城市中的人和物的运动的理解。在其他用例中,我们使用神经网络,通过自然语言模型来加速客户服务响应速度,并通过跨城市需求的时空预测来缩短用户等待时间。在此过程中,我们已经开发出了相应的基础设施来扩展模型的训练并支持更快的模型开发。
尽管神经网络是强大且被广泛使用的工具,但它们的许多微妙的属性仍然鲜为人知。随着世界各地的科学家在理解网络的基本属性方面取得的重要进展,Uber AI 的大部分研究也在这个方向上迅速跟进。相关工作包括评估内在的网络复杂性,寻找更自然的输入空间以及揭示流行模型中的隐藏缺陷。
我们最近发布了一篇论文「Deconstructing Lottery Tickets: Zeros, Signs, and the Supermask」(https://arxiv.org/abs/1905.01067),就旨在揭开神经网络神秘的面纱。我们基于 Frankle 和 Carbin 提出的引人关注的「彩票假设」展开这项研究。他们的工作展示了一个非常简单的算法删除其较小的权重并进行重训练,可以在性能与全网络相当的大型网络中找到稀疏的可训练子网络或「彩票」,给很多研究者带来了惊喜。然而他们(和通常发生在出色的研究中的情况一样)提出了与它们回答的问题一样多的问题,而且也尚未很好地理解许多底层的机制。我们的论文提出了对这些机制的解释,揭示了这些子网的有趣的特殊模式,引入了与「彩票」算法相竞争的变体,并获得了意外发现的衍生品:「超级掩模」。
· 「彩票假设」 ·
首先,我们简要总结 Frankle 和 Carbin 的论文「 The Lottery Ticket Hypothesis:Finding Sparse,Trainable Neural Networks」(https://arxiv.org/abs/1803.03635),论文标题简写为「LT」。在本文中,作者提出了一种生成稀疏的高性能网络的简单方法:在对网络进行训练后,将所有小于某个阈值的权重设置为「0」(对其进行剪枝),将其余权重重置回其初始配置,然后在保证被剪枝的权重处于冻结状态的情况下(未经过训练),从这个起始配置重新训练网络。通过使用这种方法,他们得到了两个有趣的结果。
首先,他们证明了剪枝后的网络性能良好。经过深度剪枝的网络(剪掉了 95% 到 99.5% 的权重)与规模较大的未经剪枝的网络相比,性能并没有下降。此外,仅仅被适度剪枝的网络(剪掉了 50% 到 90% 的权重)的性能往往还优于未剪枝的竞争模型。
其次,除了这些让人眼前一亮的结果,剩余网络的结构和权重的特征同样有趣。通常情况下,如果你使用经过训练的网络,通过随机权重对其重新进行初始化,然后重新训练它,其性能将与之前大致相当。但是对于精简的骨架彩票(LT)网络来说,这个特性并不成立。只有当网络重新回到其初始状态时(包括使用的特定初始权重),网络才能很好地训练。用新的权重重新初始化会导致训练效果不佳。正如 Frankle 和 Carbin 的研究所指出的那样,剪枝掩模的特定组合(对于每个权重来说,显示是否删除该权重的 0-1 值)和掩模之下的权重构成了一个在更大的网路中找出的幸运子网络。或者正如最初的研究中所命名的那样,这是一个通往胜利的「彩票」模型。
我们发现这个例子很有趣,因为所有人都不知道为什么会出现这样的结果。LT 网络是如何使它们表现出更好的性能?剪枝掩模和初始权重集合为何如此紧密的耦合,而重新初始化的网络较难训练?为什么直接选择较大的权重是选择掩模的有效标准?其它创建掩模的标准是否也有效呢?
· 奇怪而有效的掩模 ·
在开始调查研究时,我们观察了一些需要解释的奇怪现象。在训练 LT 网络时,我们观察到许多重置的、用掩模处理过的网络的准确率可能明显高于初始化。也就是说,对未经训练的网络应用特定掩模会得到一个部分工作的网络。
这可能会让人感到意外,因为如果你使用一个随机初始化的、未经训练的网络来进行诸如对 MNIST 数据集(https://en.wikipedia.org/wiki/MNIST_database)中的手写数字进行分类的任务,你会发现这样得到的准确率并不比随机运行要好(准确率大约为 10%)。但是现在,假设你将网络权重与一个仅仅包含「0」、「1」的掩模相乘。在这种情况下,权重要么维持不变,要么完全被删除,但最终得到的网络现在就可以达到近 40% 的准确率了!这很奇怪,然而在使用选择具有较大最终值权重的 LT 论文中的步骤(我们称之为「large final」的掩模准则)来应用创建好的掩模时,确实发生了这样的情况:

图 1:未经训练的网络随机运行的结果(例如,如图所示,在 MNIST 数据集上的准确率为 10%),如果这些网络被随机初始化、或随机初始化并被随机地进行掩模处理。然而,应用 LT 掩模会提高网络的准确率,使其超过随机的情况。
我们将具备「可以在不训练底层权重的情况下,立即生成部分工作的网络」的特性的掩模称为超级掩模(Supermask)。
如图 1 所示,在随机初始化网络和带有随机掩模的随机初始化网络中,权重和掩模都不包含任何关于标签的信息,因此其准确性不一定能比随机的情况更好。在具有 LT「large final」掩模的随机初始化网络中,得到优于随机情况的性能并非不可能,因为掩模确实是在训练过程中产生的。但这还是有些出乎意料,因为从训练回传到初始网络的唯一信息是通过「0-1」掩模传输的,并且应用掩模的标准只是选择有大最终值的权重。
· 掩模运算是需要训练的,为什么「0」很重要? ·
那么,为什么我们认为,只需应用 LT 掩模就可以大大提高测试的准确率呢?
LT 论文中实现的掩模运算过程将执行两个操作:将权重设置为零,以及冻结这些权重。通过确定这两个部分中的哪一个会提高训练好的网络的性能,我们还发现了未经训练网络的这种独特性能的底层原理。
为了分开上述两个因素,我们进行了一个简单的实验:我们复现了 LT 迭代剪枝实验,其中网络权重在交替的「训练/掩模/重置」的循环中被掩模处理,但我们还尝试了其它的处理方式:将「零掩模」处理的权重冻结为其初始值,而不是将其冻结为零。如果零不是特殊的,那么这两种方法得到的性能应该相似。我们遵循 Frankle 和 Carbin(2019)的做法,在 CIFAR-10 数据集上训练三个卷积神经网络(CNN),Conv2,Conv4 和 Conv6(具有 2/4/6 卷积层的小型 CNN,这与 LT 论文中使用的相同)。
下方图 2 为实验结果,通过剪枝操作(或者更准确地说:「冻结为一定的值」)将左侧的未剪枝的网络修改为右侧的修剪后的网络。水平黑线表示原始未剪枝网络五次运行的平均性能。此处和其他图中的不确定性代表五次运行中的最小值和最大值。蓝色实线代表使用将剪枝后的权重设置为零并冻结它们的 LT 算法训练的网络。蓝色虚线则代表使用没有将剪枝权重冻结成其初始值的 LT 算法训练的网络:
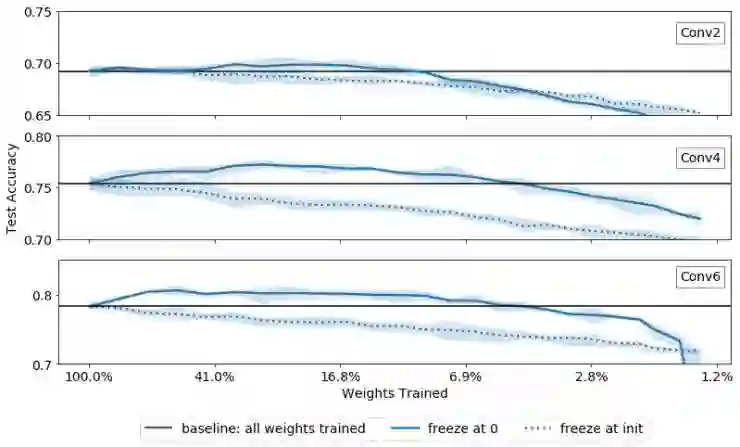
图2:当在 CIFAR-10 数据集上测试上述的三个卷积神经网络时,我们发现具有被冻结为其初始值的剪枝后权重的网络的准确率比具有被设置为零的剪枝后权重的网络的准确率明显要低一些。
我们看到,当权重被特意冻结为零而不是随机初始值时,网络的表现更好。对于通过 LT「final large」标准进行掩模处理的这些网络,当它们具有小的最终值时,将权重设置为零似乎是非常好的选择。
那么为什么零是理想的值?一种假设是,我们使用的掩模标准倾向于将那些趋向于零的权重通过掩模处理为零。为了验证这个假设,让我们考虑一种新的冻结方法。我们在前两个实验之间插入另一个实验:对将要被冻结的任意权重,如果它在训练过程中趋向于零,我们会将它冻结为零;而如果它逐渐远离零,那么我们将它冻结为其随机初始值。结果如下面的图 3 所示:
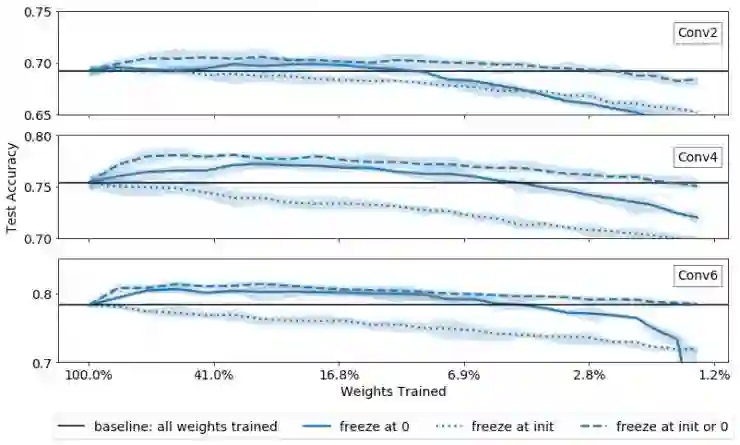
图3:根据权重在训练期间移动的方向,有选择性地将权重冻结为其初始值或零,会得到比将所有权重一律初始化为零或其初始值更好的性能。
我们看到这种处理方法的性能比将所有权重冻结为零或初始值更好!这印证了我们的假设,即将值冻结为的性能较好,是由于这些值无论如何都会趋向于零的事实。如果了解关于为什么「final large」掩模标准偏向于选择那些趋向于零的权重的深入讨论,请参阅我们的论文(https://arxiv.org/abs/1905.01067)。
因此,我们发现对于某些诸如「large final」的掩模标准,掩模是在训练中得出的:掩模操作倾向于将权重朝着它们在训练时移动的方向移动。
这同时解释了为什么存在「超级掩模」,并间接说明其它的掩模标准可能会得到更好的「超级掩模」(如果它们能优先将在训练中趋向于为零的权重掩模为零)。
· 其它的掩模标准 ·
现在我们已经对原始的 LT 掩模标准「large final」表现出色的原因进行了探索,那么我们不妨想想还有什么其它的掩模标准也会有很好的性能。「large final」标准保留具有较大最终值的权重并将其余权重设置为零。我们可以将这种剪枝标准和许多其它的标准视为将二维(w i =初始权重,wf =最终权重)空间划分为对应于应该保持的权重(「1」掩模)与应该剪枝的区域(「0」掩模)。工作原理如图 5 所示:
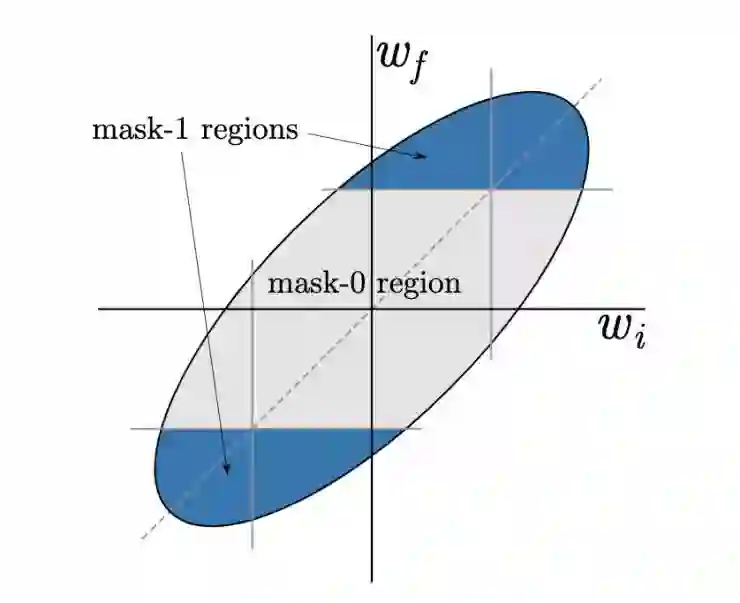
图 5:不同的掩模标准可以被认为是将(wi,wf)空间分割成与掩模值「1」或「0」相对应的区域。椭圆以动画的形式表示出某给定层的正相关的初始值和最终权重占据的区域。图中的掩模对应于LT论文中使用的「large final」标准:保持具有大的最终值的权重,并且对具有接近零的最终值的权重进行剪枝。请注意,此标准忽略了权重的初始值。
在上一部分中,我们展示了一些证据来支撑下面的假设:将已经趋向于零的权重设置为零会得到很好的网络性能。该假设表明,如果他们遵循这一基本规则,这对其它的掩模标准可能也有效。其中一个此类掩模标准是:优先保持那些移动得离零最远的权重,我们可以将其写为评分函数 |wf|-|wi| 的形式。我们将此标准称为「magnitude increase」,并将其与其他标准一起表示为图 6 中的条件控制示例,如下所示:
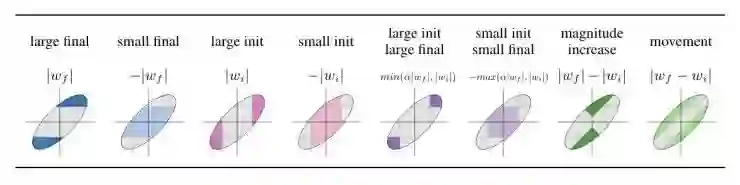
图 6:从 LT 论文中出现的「large final」标准开始,从左到右依次为本研究中考虑的八个掩模标准。我们给出了用来指代各种方法的名称以及将每个(wi,wf)对投影到一个分数上的公式。我们保留具有最高分数(彩色区域)的权重,并且对具有最小分数(灰色区域)的权重进行剪枝。
这种「magnitude increase」标准与「large final」标准一样有效,在某些情况下明显还要更好一些。对于全连接(FC)和 Conv4 网络,所有标准的结果如图 7 所示;要想了解其他网络的性能结果,请参阅我们的论文(https://arxiv.org/abs/1905.01067)。作为对比基线,我们还显示了使用随机剪枝标准得到的结果,该标准直接选择具有所需的剪枝百分比的随机掩模。请注意,八个标准中的前六个标准形成了三对相反的情况:在每种情况下,我们看到当该对中的一个成员比随机基线表现更好时,相对的另一个成员的性能就比随机基线更差。
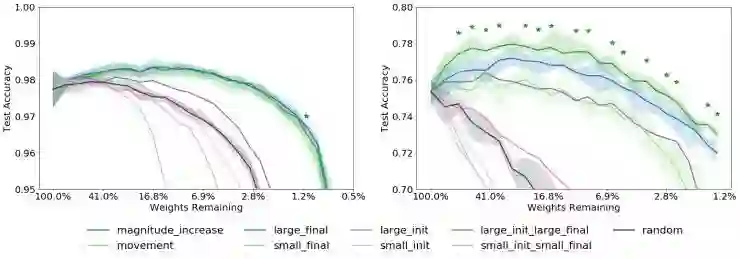
图 7:两个网络的准确率与剪枝百分比的测量结果,MNIST 数据集上的全连接网络(左图)和 CIFAR-10 数据集上的 Conv4 网络(右图)。表明多个掩模标准——「large final」,「magnitude increase」,以及另外两个标准,确实优于黑色的随机剪枝基线。在Conv4网络中,「magnitude increase」的性能提升大于其他掩模标准; 星号标记出了「large final」和「magnitude increase」之间的差异在 p = 0.05 的水平上具有统计显着性的情况。
通常而言,我们观察到,那些倾向于保留具有较大最终值的权重的方法能够发现高性能子网络。
· 真正起作用的是符号! ·
我们已经探索了各种方法,用来选择应该对哪些权重进行剪枝以及应该将剪枝后的权重设置为何值。现在,我们将考虑应该将保留下来的权重设置为何值。特别是,我们想研究 Frankle 和 Carbin(2019)的工作中一个有趣的观察结果,该结果表明,当你将其重置为原始初始值时,经过剪枝的骨架 LT 网络可以很好地进行训练。但是,当你随机重新初始化网络时,训练的性能会降低。
为什么重新初始化导致 LT 网络训练不佳?初始化过程中的哪些因素很重要呢?
为了找到问题的答案,我们评估了一些重新初始化了的变体。
「Reint」实验:基于原始的初始化分布重新初始化保留的权重。
「Reshuffle」实验:在遵循该层中剩余权重的原始分布的情况下进行重新初始化,这是通过重新调整保留下来的权重的初始值来实现的。
「Constant」实验:通过将剩余权重值设置为正或负的常量来重新初始化,将常量设置为每层的原始初始值的标准差。
所有重新初始化实验都是基于相同的原始网络实现的,并使用了「large final」掩模标准和迭代剪枝。我们将原始 LT 网络(权重重置,使用了 large ginal 标准)和随机剪枝网络作为对比基线。
我们发现这三种变体中没有一种能够像原始 LT 网络那样进行训练,如下图 8 中的虚线所示:
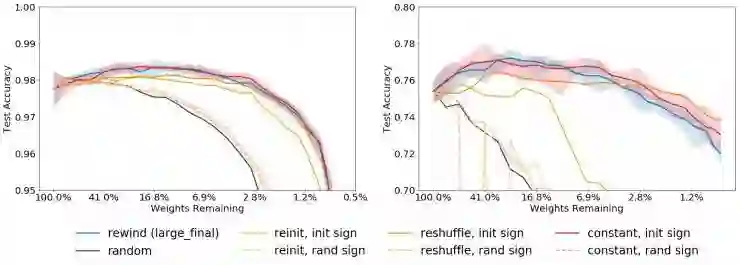
图 8:我们展示了测试准确率与两个网络的剪枝百分比,全连接网络(左图)和 Conv4 (右图),同时使用不同的重新初始化方法。在遵循符号一致性的那些与不符合符号一致性的初始化方法之间的明显的性能区别表明,保留权重的特定初始值并不像它们的符号那么重要。
然而,当我们通过确保「为保留下来的权重重新分配的值与其原始的初始值具有相同符号」来控制符号的一致性时,所有三种变体都能取得更好的性能。图 8 中显示的纯色实线说明了这种情况。显然,使得所有变体的性能都比随机情况更好的共同要素(包括原始的「重置」方法)就是符号!这表明只要你保持符号一致,重新初始化就不会损害模型的性能。事实上,只要我们沿用原始的符号,即使直接将所有保留的权值设置为常量也能得到很好的模型效果!
· 更好的「超级掩模」 ·
在文章的开头,我们介绍了「超级掩模」的概念,它是二值掩码,当应用于随机初始化网络时,无需进行额外的训练即可得到比随机情况更高的测试准确率。我们现在将注意力转而投向寻找可以得到最佳的「超级掩模」的方法。
我们可以评估图 7 中所示的相同剪枝方法和剪枝百分比,来查看「超级掩模」的潜能。我们还可以考虑为生成「超级掩模」而优化的其它掩模标准。基于对 LT 权重的初始符号的重要性的观察以及使权重接近其最终值的想法,我们引入了一个新的掩模标准,该标准选择具有大的最终值的权重,该权重也在训练的最后保持相同的符号。这种方法被称为「large final, same sign」,如图 9 所示。我们还添加了「large final, same sign」作为条件控制案例,它会寻找在训练结束时符号有所改变的权重。

图9:「large final, same sign」的掩模标准在本研究中得到了性能最好的「超级掩模」。与图 5 中的「large final」掩模相反,请注意该标准对 wi 和 wf 符号不同的象限进行了掩模运算。
通过使用「large final, same sign」的简单掩码标准,我们可以创建在 MNIST 数据集上获得性能卓越的具有 80% 测试准确率的网络。在不进行训练的情况下,可以在 CIFAR-10 数据集上获得 24% 的测试准确率。另一个奇妙的观察结果是,如果我们将掩模应用于有符号常数(如上一节所述)而不是实际的初始权重,我们可以在 MNIST 数据集上得到高达 86% 的更高的测试准确率,在 CIFAR-10 数据集上得到 41% 的测试准确率。

图 10:我们评估了应用各种掩模时,在 MNIST 数据集上单个全连接网络的初始条件下(没有经过训练)得到的准确率。X 轴代表网络中剩余权重的百分比;所有其余的权重都被设置为零。「large final, same sign」的掩码可以创建性能远高于其他方法的「超级掩模」。请注意,除了为绘制此图生成不确定带的五次独立运行之外,绘图上的每个数据点都使用了相同的底层网络,只不过应用了不同的掩码。
我们发现这样的「超级掩模」是存在的,并且可以通过这样简单的标准找到它是非常有趣的。除了是一个科学上的有趣发现,这还可能对迁移学习和元学习产生影响——可以对网络进行近似求解。例如,只需使用不同的掩码,就可以求得 MNIST 输入像素的任何排列和输出类的排列。它们还为我们提供了一种网络压缩方法,因为我们只需要保存二值掩码和单个随机种子就可以重建网络的全部权重。
如果你想了解我们能够在多大程度上提升这些「超级掩模」的性能,请参阅我们的论文(https://arxiv.org/abs/1905.01067),在论文中我们尝试了直接对它们进行训练的方法。
via https://eng.uber.com/deconstructing-lottery-tickets/
由中国计算机学会主办、雷锋网和香港中文大学(深圳)联合承办的 2019 全球人工智能与机器人峰会( CCF-GAIR 2019),将于 2019 年 7 月 12 日至 14 日在深圳举行。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。




