编辑:LRS
【新智元导读】视频语言数据集的规模又刷新记录了!来自MSRA的8位华人联合发布史上最大的视频语言数据集HD-VILA-100M,也是首个高分辨率大规模数据集!文中还提出一个训练模型,基于这个数据训练的模型性能直接提升53.6%!
回想几年前网上信息大部分还是静态的,例如图片、小说。
但随着各大视频网站和短视频的兴起,用户在互联网上浏览视频的数量近年来显著增加,并且视频创作的质量、分辨率和内容多样性也越来越高!
把旅游、体育、音乐等日常生活拍成视频分享已经成为了新常态,并且通常还会配上一段文字。
所以AI研究也是紧随其后,进入文本+视频的多模态时代,例如视频搜索,视频推荐,视频编辑都需要这种多模态建模的能力!
然而,现有的视频语言理解模型(video-language understanding models)的发展实际很大程度上是受到了数据集的规模和覆盖范围的限制。
早期的数据集如MSR-VTT、DiDeMo、EPIC-KITCHENS都是由人类手工标注的视频和文本描述组成,由于引入了人工标注,所以数据集的构造成本也是急剧上升,导致这些数据集的规模也无法做的很大。
此外这些数据集中只包含了一些描述性的语句,那么数据集的复杂性和多样性也受到了很大限制,间接影响了后续开发模型的泛化性能。
也有一些研究人员直接使用经过语音识别(ASR)后的视频一起进行训练,由于省去了人工标注视频文本的过程,数据集的规模得到了大大提升。一个最有代表性的例子就是HowTo100M数据集,包含了百万级的视频文本语料。
自动标注的视频数据不管是在质量上,还是语义多样性上都和真实场景中的视频存在着很大差距。
为了更好地理解视频和解决上面提到的数据问题,来自微软亚洲研究院MSRA 的8位华人最近共同发表了一篇论文,主要研究了联合视频和语言(joint video and language)的预训练并提出了一个新的数据集HD-VILA-100M(High-resolution and Diversified VIdeo and LAnguage)。
数据集中的视频类别(video category)覆盖范围十分广泛,对后续的应用如文本到视频的检索(text-to-video retrieval)和视频问答(video QA)场景十分有用。
数据集中包含了来自300万个视频中的1亿个视频文本对,视频时长合计达到了37万个小时,比前面提到的HowTo100M的视频时间还要长2.8倍,平均句子长度也比HowTo100M长8倍。
前面提到ASR生成的视频字幕普遍质量不高,并且没有标点符号。为了克服这个问题,研究人员使用GitHub的一个工具puntuator2将字幕切分成多个完整的句子,然后通过动态时间规整(Dynamic Time Warping)使用Youtube自带的字幕时间戳对视频片段和句子进行对齐。
处理后,HD-VILA-100M数据集中视频片段的平均时长为13.4秒,每个句子平均包含32.5个词。
数据集中的所有视频分辨率都是720p,而目前主流的视频文本数据集的分辨率只有240p和360p。
数据集涵盖了YouTube上的15个最流行的视频类别,例如体育、音乐、汽车等。并且研究人员还对各个类别下的视频数量进行了平衡。
但由于内存、计算能力等多种现实因素上的限制,以前的工作要么采用简单的基于视频帧的端到端的编码器来进行视觉编码和多模态融合,要么使用一些训练好的时空(spatio-temporal)编码器来一步步实现对视觉编码和多模态信息的融合。
几乎没有研究工作在端到端视频语言预训练模型中对时空视频进行联合编码(joint spatio-temporal video representation)。
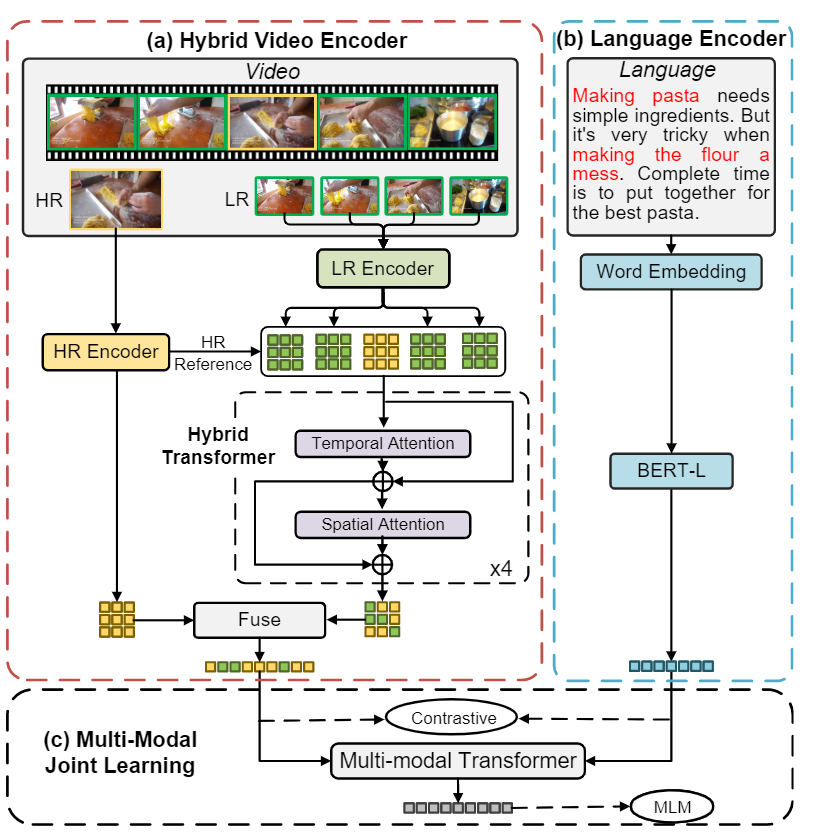
研究人员提出了一个新的模型,模型的输入是混合图像序列(hybrid image sequence),序列中包含少量高分辨率(HR)视频帧和大量的低分辨率(LR)的视频帧来进行多视频学习的任务(multiple video learning task)。
这样的模型设计能够实现高分辨率时空视频表征的端到端训练,并且在模型设计中解决了两个主要的问题:
研究人员首先随机从一个视频片段(video clip)中随机采样一些HR视频帧来确保最终学习到的视频特征具有足够的鲁棒性。
LR视频帧从HR视频帧的附近帧中平均采样抽取得到,也保证了中间的HR视频帧包含了和LR相似的空间信息,这个操作对于时序特征的学习也是非常关键。
研究人员对HR和LR视频帧分别编码,并且使用一个hybrid Transformer将把编码后的HR特征和LR特征映射到同一个embedding空间。这种设计方式也能确保视频中的时空信息能够以一种可学习的方式同时覆盖HR和LR视频帧。
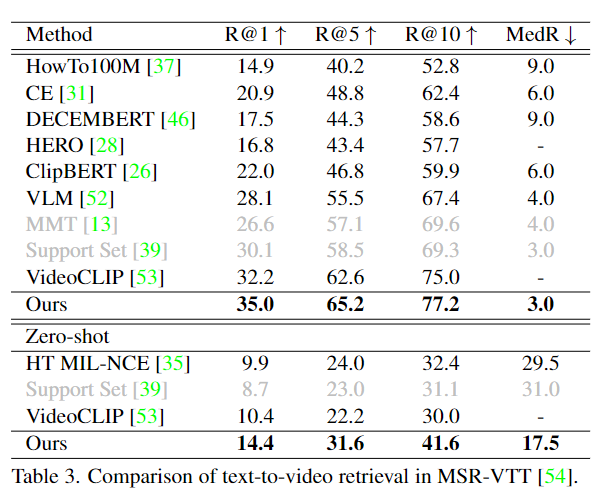
研究人员对video-text retrieval任务进行了实验,可以看到文中提出的HD-VILA模型在MSR-VTT数据集上以极大的优势超越了以往在HowTo100M数据集上训练的模型。
在z
ero-shot的设置下,HD-VILA甚至比VideoCLIP的R@1的性能好38.5%(10.4->14.4),也表明了模型学习到的视频表征具有足够的泛化能力,并且微调后的模型已然超越了所有的基线模型。
在电影数据集LSMDC中,模型相对其他基线模型甚至取得了更大的性能收益(53.6%)。
由于电影与HowTo100M里的视频风格可以看出明显不同,所以在HowTo100M上预训练的模型很难适应电影领域。
并且由于LSMDC中的视频数据分辨率普遍较高,
而HD-VILA相对其他模型处理高分辨率视频的效果也更好,所以性能提升也更大。
在DiDeMo和ActicityNet数据集上的实验中,HD-VILA也取得了更好的性能。这两个数据集的主要特点就是规模更大、视频类别更丰富,每个视频的时间也更长,在这种情况下,模型需要更好的时序理解能力才能召回正确的结果,也符合HD-VILA的训练目标。
在text-to-visual生成实验中,研究人员对比的模型为StyleCLIP和TediGAN,这两个模型都是利用跨模态的预训练来完成语言引导的图像生成任务,并且图像生成质量在业界也是广受好评。视觉生成结果的质量一定程度上也可以反映跨模态embedding的质量。
在text-guided manipulation任务的第一个例子中,虽然三个模型都成功将头发变得更加大波浪,但HD-VILA是唯一一个遵循文本的要求给人物涂上口红的模型。
在图像超分辨率(super-resolution)任务中, HD-VILA和SR3, pSp模型同时从16×16的超低分辨率中生成1024×1024的图像,由于输入图像的分辨率特别低,所以任务也是相当有挑战性。
实验结果中可以看到,SR3和pSp仅利用视觉信息并不能重建高质量的人脸,而HD-VILA能够在预训练模型的支持下,借助文本描述能够准确地重建口红、直发等人脸特征。
文章的作者郭百宁博士现为微软亚洲研究院常务副院长,负责图形图像领域的研究工作。
于1999年加盟微软中国研究院(即微软亚洲研究院前身)。
此前他是美国英特尔公司硅谷总部研究
院的资深研究员,拥有美国康奈尔大学硕士和博士学位,北京大学学士学位。
郭百宁博士的研究兴趣包括计算机图形学、计算机可视化、自然用户界面以及统计学习。他在纹理映射建模、实时渲染以及几何模型等领域取得的研究成果尤为突出。
参考资料:
https://arxiv.org/abs/2111.10337
![]()