加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
在此之后,ResNeSt也引发了大家的讨论,有人非常认同这一工作,认为ResNeSt理论与工程价值都非常高;也有开发者对这一工作提出质疑,直至23日ECCV2020评分结果出炉,ResNeSt再次引起了大家的关注。
本文转载整理了ResNeSt的作者张航博士对于这一工作的近期成果和观点,以及开发者对此提出的一些有价值的想法,同时在文末引用了张博本人的回复,旨在对ResNeSt的贡献与值得改进之处进行一个综合论述。
登顶目标检测/实例分割/全景分割的ResNeSt
本部分内容来源:张航@知乎,https://zhuanlan.zhihu.com/p/140236141
在上一篇关于语义分割在 ADE20K 数据集文章发布之后,我们又测试了 Cityscapes 和 Pascal Context,均达到了 SoTA 水平。
首先感谢小伙伴们 (Chongruo
@吴冲若, Jerry @张钟越 , Yi @朱毅) 的努力工作 ,还有沐神 @李沐 的大力支持。
我们最近使用 ResNeSt 对各项下游应用进行测试,发现仅需使用经典算法作为基础,使用 ResNeSt 作为主干网络,就可以在各项应用中轻松获得 SoTA 水平,下面是几个相关的应用:
因为最近小伙伴们都比较忙,我们就不详细赘述了,这里主要是展示一下我们取得的结果。希望给准备打 COCO+LVIS比赛的小伙伴有所帮助,代码和模型都已经开源 (主仓库github.com/zhanghang198 ,Detectron模型:github.com/zhanghang198)。末尾有一些彩蛋,有兴趣可以看一下。
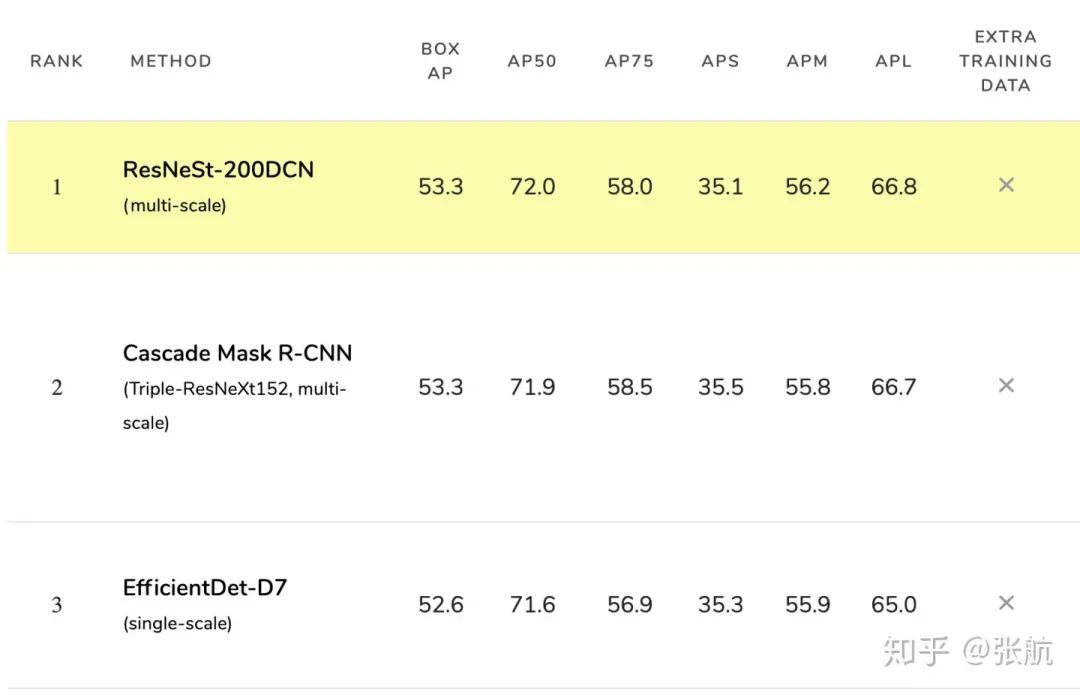
我们使用了 Cascade R-CNN + ResNeSt200DCN 在 MS-COCO 目标检测 test-dev 数据集上的结果如下:
这个表现追平了之前的 CBNet,与CBNet使用 3 个 backbone 不同,我们的模型只使用了单一的 ResNeSt-200 + DCN 的 backbone,所以有更好的推理速度。
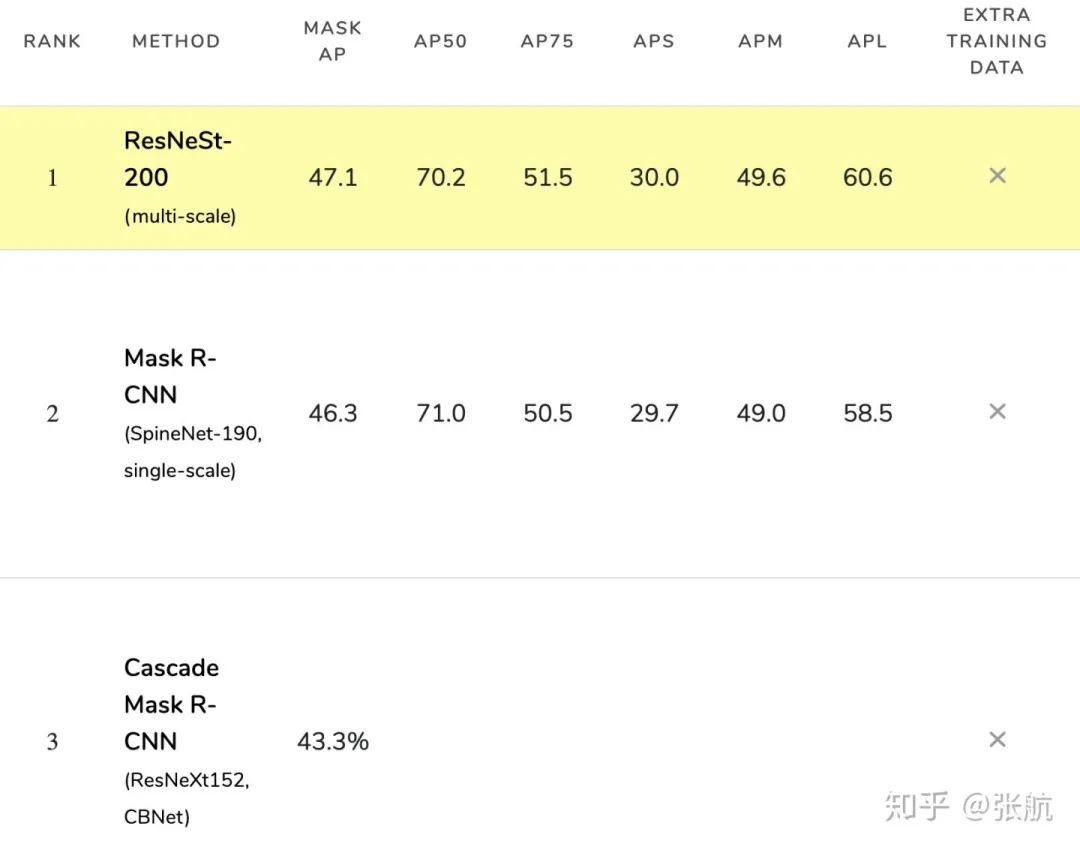
在 MS-COCO 实例分割的 test-dev 数据集上的结果如下:
我们超过了 SpineNet 和 CBNet。在全景分割上,我们大幅超越前人工作:
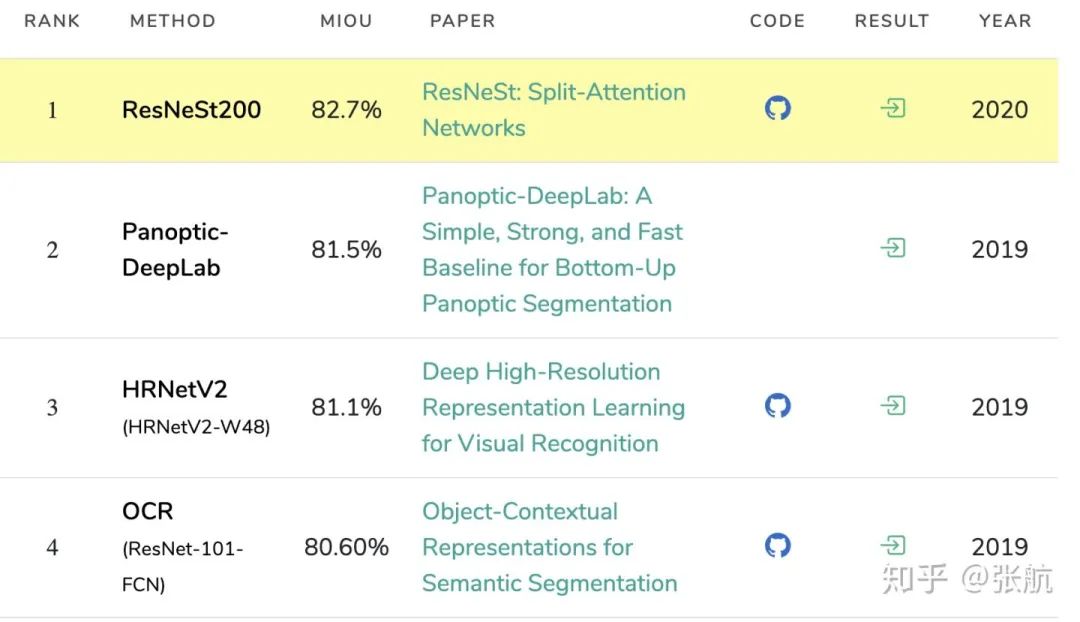
最后补充一下上一篇没有提到的语义分割上的结果,在Cityscapes验证集上:
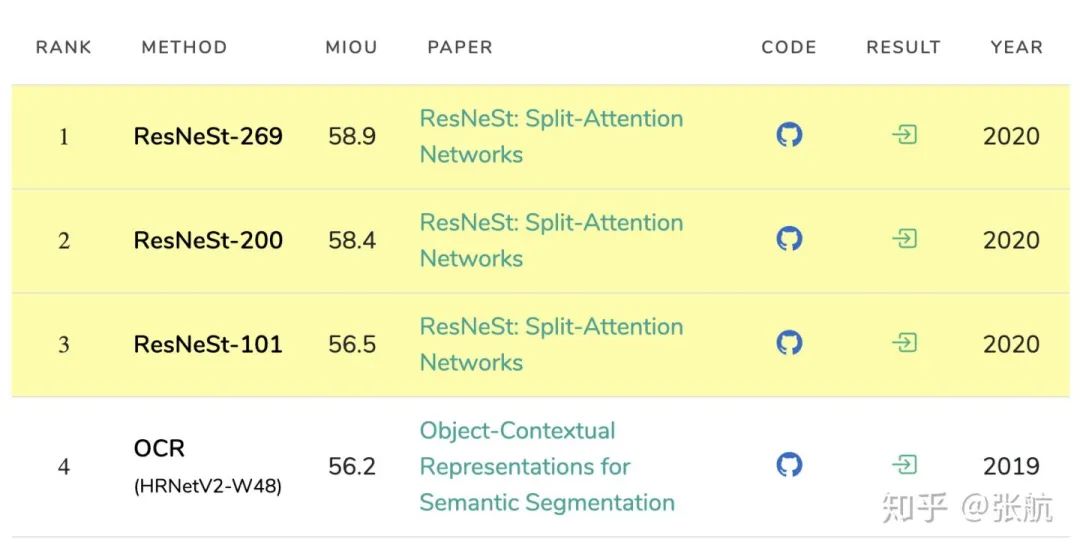
在 Pascal Context 验证集上 (我们没有找到 test server):
写在后面:
之前有公众号高调宣传我们的 ResNeSt paper,有朋友在评论区指责我们给 reviewer 压力,所以我们选择在审稿意见出来之后再继续宣传。而且我们很惊喜地收到一个 strong reject,关心这个审稿意见怎么写的朋友,可以去那个指责我们给 reviewer 压力的评论,翻译成英文是一模一样的。
关于这篇文章,当时投稿的时候,在 ImageNet 确实 Ablation Study 做得有许多不到位的地方,但是之前的文章也没有把所有前人提出的网络都按照相同 setting 训练一遍,而且这位 reviewer 还问为什么不比一下 SKNet + ResNet50D 这个不曾出现在前人工作中的网络。我觉得一定是出于对学术的严谨性给出的 strong reject,我非常感谢大家对我们工作的严格要求,在改投之前一定会把补充实验补充好(其实最近已经在做了)。
我之前也说过,这篇文章不是要解决分类问题,因为我认为分类问题是已经解决了的问题。最近领域内的基础网络研究和下游应用脱节。EfficientNet 很成功,但是它与下游应用已有的算法不兼容。我们训练网络中使用了一些 EfficientNet 的训练方法,比如 Auto Augment,但是请问为什么 ResNet 系列就不能用训练技巧。而且 Ablation Study 里面已经展示了,我们并没有使用精度最好的 setting 来做backbone,而是选择一个 latency 较小的,主要就是为了下游应用考虑。
我们不重复造轮子
,希望做的网络能够和前人工作最好地兼容起来。这个网络替换原有 ResNet,可以提高3%左右,甚至在不使用任何技巧的情况下,直接在各个下游应用的主流数据集中取得 SoTA 的结果。希望这个网络能够对领域内的工作有所启发,其实我们并没有真正在意多一篇顶会文章。
网友评价:ResNeSt之于SKNet,如同ResNeXt之于ResNet
本部分内容作者:Happy@知乎,https://zhuanlan.zhihu.com/p/143214871
首先声明一点:本文纯粹是笔者从个人角度出发,结合个人多年工作经历与感触而写的一点体会,非喜勿喷。
笔者当时主要提出了两点:(1) ResNeSt与SKNet的相似性;(2) ResNeSt代码实现错误问题。除了上述两点外,还有一点:ResNeSt的刷榜到底是架构调整的原因还是各种tricks的原因?无论是广大CVers还是reviewer,关于ResNeSt的质疑大多在于第一点与第三点。
关于第一点疑问,作者也曾正面回复过:这篇文章主要是基于SENet、SKNet与ResNeXt,把attention做到了group level。也就是说,ResNeSt是在SKNet的基础上针对其存在的缺点(多分枝,不易模块化,推理速度慢等原因)做的改进,关于SKNet与ResNeSt的区别与联系,各位小伙伴可以去笔者之前的文章了解以下,见关于ResNeSt的点滴疑惑。
关于第三点疑问,ResNeSt刷榜是网络结构之功还是tricks之果。确实,ResNeSt的训练过程中用到了非常多的trick,比如标签平滑,auto数据增强,大batch,cos learning rate decay,大epoch,混合样本训练等各种涨点手段。知乎上也有不少人对此存在一些质疑。
针对第三点,我来谈一下个人的看法:这篇论文的理论与工程价值都非常高,reviewer过于吹毛求疵了。
从理论角度来看,ResNeSt之于SKNet,就好比ResNeXt之于ResNet。先来看看其他三大论文的投稿情况:ResNet投稿于CVPR2016并获得最佳论文奖(历年各大顶会奖项可以见:https://www.thecvf.com/?page_id=413#ECCVBest),同时也是公认的深度学习里程碑式的成果;ResNeXt投稿于CVPR2017,贡献虽不如ResNet那么大,但也是公认的标杆成果;SKNet投稿于CVPR2019,也是深度学习领域标杆性的成果。ResNeSt却被ECCV2020评审给出了strong reject的结果,着实有些说不过去。笔者没发过顶会paper,也达不到reviewer的高度,就不对reviewer的结论做评价了。
从工程角度来看,ResNeSt为AI算法工程化提供一个坚实的benchmark。论文提到的各种tricks,网络结构方面的调整思考,算法计算流程方面的各种优化思考(如cardinal转radix实现),这些不都是该文的贡献吗?
当然论文也存在一些不足,消融实验部分确实不够充分,这点作者也认可。但是在极为有限的时间内,能给出论文中的所有实验结果已经非常能够说明该论文的价值了。用ImageNet数据集训练过模型的小伙伴应该很清楚训练一个好的模型大概需要多少时间,哪怕是亚马逊这样公司也没有那么多资源去把所有可能的消融实验都做一遍吧。虽然笔者也是CV方面的算法研发人员,但我确确实实没有用ImageNet从头到尾训练过哪怕一个模型(太耗GPU了,我急需GPU啊,谁能支援几个GPU啊,我可以用idea换,哈哈),最多是用ImageNet的验证集测试不同模型的指标。
极市对ResNeSt这一工作也非常关注,看到大家的讨论后,我们与张航博士进行了沟通交流,以下是张博对此的回复:
我觉得对我们工作严格要求是审稿人出于严谨的态度,希望我们能做得更好。
有一些争议来自于我们paper使用的很多trick,之前resnet系列没有使用。我个人观点 1. 现在imagenet 上的竞争是全方位的,任何地方不足都无法达到EfficientNet这样的高度,还是希望大家可以给 ResNet 系列解放思想上的枷锁。2. 下游应用的对照实验不足,我们只是想展示一下,仅仅使用我们的主干网络,经典算法都可以轻松SoTA,当然这些提升有网络结构的改善,有预训练方法上的提高。
大家对论文严格要求是好事,可以推动科研的进步,但是还是希望可以保持一个比较 consistent 的标准,我就不举例了。
不论如何,ResNeSt都是一个非常好的backbone,这也是大家都认可的。另外,对待科研,认真严谨的态度和自由的精神缺一不可。有意义的观点不被束缚,问题提出的过程客观而不失偏颇,只有在这样的环境中,有价值的工作才能不断进步,进而作出更大的贡献。
![]()
添加极市小助手微信
(ID : cv-mart)
,备注:
研究方向-姓名-学校/公司-城市
(如:AI移动应用-小极-北大-深圳),即可申请加入
AI移动应用极市技术交流群
,更有
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、
干货资讯汇总、行业技术交流
,
一起来让思想之光照的更远吧~
![]()
△长按添加极市小助手
![]()
△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~ ![]()