ECCV 2020 | 南京大学王利民团队提出MOC:时空动作检测新框架
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文作者:王利民
https://zhuanlan.zhihu.com/p/164968681
本文已由原作者授权,不得擅自二次转载

作者单位:南京大学
论文:https://arxiv.org/abs/2001.04608
代码:https://github.com/MCG-NJU/MOC-Detector

Demo1
1. 任务介绍
今天介绍一篇我们在时空动作检测领域的工作MOC (Actions as Moving Points),本文提出了一套全新的时空动作检测 (spatio-temporal action detection) 框架,首先简单介绍一下什么是时空动作检测任务。
时空动作检测属于视频领域的任务,视频领域常见的任务有动作识别、时序动作检测、时空动作检测。
动作识别 (action recognition) : 是对每个输入视频进行分类,识别出视频中人物做出的动作。即输入视频序列,得到视频对应的类别;
时序动作检测 (temporal action detection) :任务的输入是一个未经裁剪的视频 (untrimmed video),即在这个视频里有些帧是没有动作发生的,因此需要检测出动作开始和结束的区间,并判断区间内动作的类别。即输入未经裁剪的视频序列,得到动作出现的区间和对应的类别;
时空动作检测 (spatio-temporal action detection) :相比于时序动作检测略有不同,时空动作检测不仅需要识别动作出现的区间和对应的类别,还要在空间范围内用一个包围框 (bounding box)标记出人物的空间位置。
早期的时空动作检测是先逐帧处理 (frame-level detector),得到每帧内人物的包围框和动作类别,然后再沿时间维度将这些框连起来,形成时空动作检测结果,但这样逐帧处理的方式导致沿时间连接比较困难,且因为缺乏时序信息的利用导致动作识别精度不高;近期工作中 (ACT,T-CNN,STEP) 提出了基于tubelet的检测方式 (tubelet-level detector),此类检测器每次输入连续K帧并产生连续K帧的检测结果action tubelet(tubelet内相邻帧的框已连接),再将这些tubelet在时序上进行连接,得到视频级别的时空动作检测结果action tube。
2. 研究动机
目前的时空动作检测框架主要是基于anchor-based目标检测方法,例如faster rcnn,ssd等。这些方法会预先设计大量的anchor,尽管他们已经在图片领域取得很好的成果,但是仍然存在超参敏感 (e.g. box size, aspect ratio, and box number) 和密集设置anchor造成的效率低下的问题,当扩展到视频领域需要设计3D anchor时,随着输入tubelet长度增加,可能的anchor数目急剧增加,超参数目增多,对于训练和测试都是一种挑战。受到最近anchor-free object detector的影响,我们提出了一个简洁、高效、准确的action tubelet detector, 称为MovingCenter detector (MOC-detector)。
3. 方法
基于运动信息可以有效提高识别精度,协助人物定位的分析,我们将动作实例建模为每一帧动作中心点沿时序的运动轨迹,依照这种对动作的简化建模方式,流程图如下:
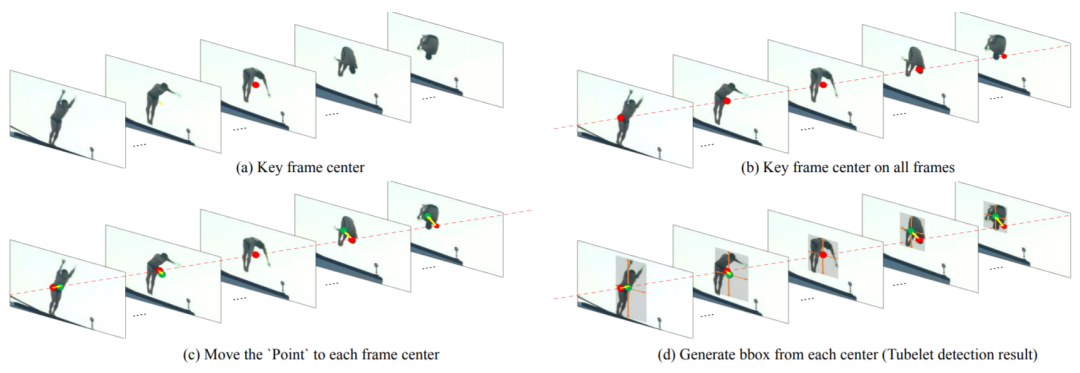
具体来讲,首先将连续K帧图像分别输入共享的2D Backbone提取每一帧的高层语义特征,即K张特征图,然后由三个分支共同协作来完成时空动作检测,我们的网络结构如下图:
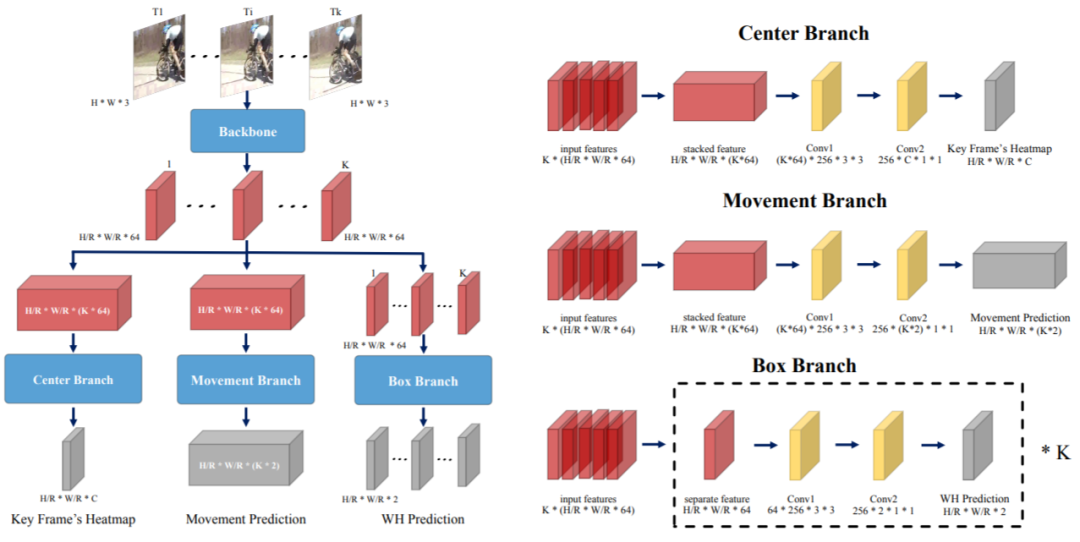
三个分支处理过程为:
(1)中心点预测分支 (Center Branch) 用于检测每个tubelet中间帧动作实例中心点的空间位置和所属类别。将K张特征图沿通道拼接,经过一个3x3卷积得到时空融合特征,再通过一个1x1卷积得到K帧图像序列中间帧的“heatmap”,响应高的点对应中间帧动作实例中心点的位置和类别。
(2)运动估计分支 (Movement Branch) 用于估计中间帧动作实例中心点到相邻帧对应动作实例中心点的运动矢量,形成中心点运动轨迹。将(1)中预测的中间帧动作中心点移动到当前帧的对应中心点。至此可以形成连续K帧内每个动作实例中心点的运动轨迹。
(3)包围框回归分支 (Box Branch) 在每一帧的预测中心点直接回归bbox大小来得到动作实例在空间上的包围框。逐帧处理,输入单帧特征图,预测由(2)得到的当前帧动作中心点对应动作的包围框大小。
这三个分支可以相互协作生成tubelet检测结果,并采用现有的link算法。在同等实验设置下,UCF101-24和JHMDB数据集上得到了当前最好的结果,尤其是对于更精确的检测要求(高IoU, 如IoU=0.75)。且因为同一个视频中每一帧的特征只需提取一次,之后对于不同的视频序列可重复使用,MOC-detector的效率也很高双流速度达25FPS。同时由于我们采用了在线的link算法,MOC可以实时处理在线视频流,单流RGB速度达53FPS。
4.实验结果
与SOTA的对比:
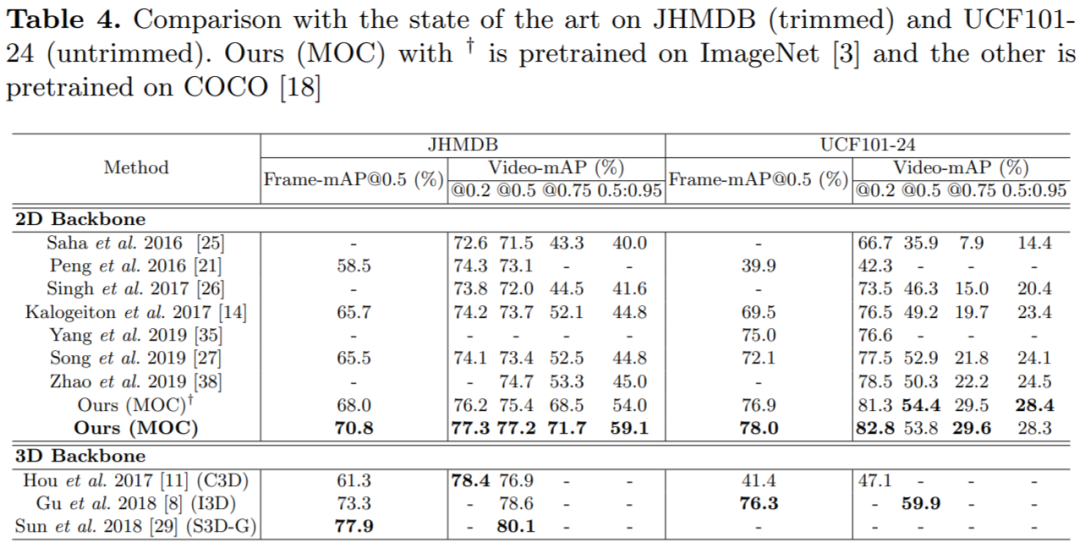
我们将MOC和其他方法的结果在UCF101-24和JHMDB上进行对比,[23. 19. 24]都是frame-level的detector,[12, 32, 35, 25]是tubelet-level的detector,我们的方法均优于这些方法,尤其是对于high IOU video mAP,可见我们的anchor-free tubelet detector MOC可以比anchor-based tubelet detector更精确地从短时序视频片段中定位动作。我们和基于3D backbone[9, 7, 27]的方法效果差不多,这些方法通常将action detection分为两个步骤,person detection (ResNet50-based Faster RCNN pretrained on ImageNet) 和action classification (I3D/S3D-G pretrained on Kinetics+ROI pooling),和tubelet detector相比无法提供一个简单的框架。
Runtime分析:
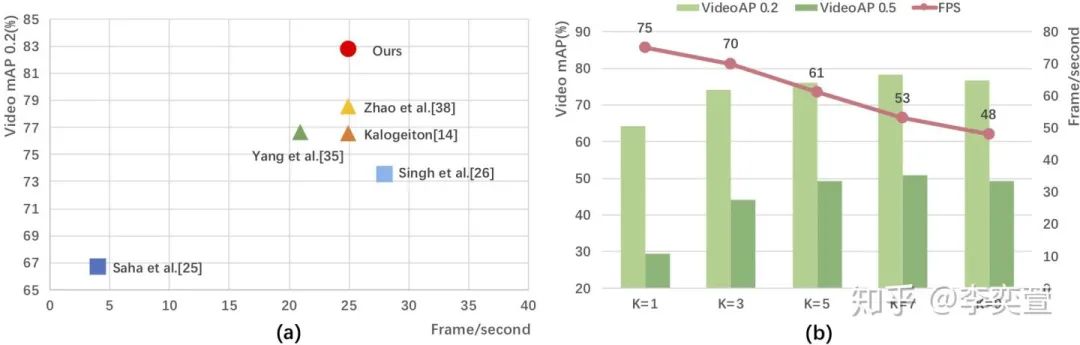
根据ACT,不加光流计算时间,MOC双流K=7可达到25fps,在左侧的图中,我们将MOC和在原论文中报了自己速度的方法进行对比,其中[14, 35, 38]都是tubelet action detector,我们发现MOC效率高而且准确率也高。我们的MOC也可以用于处理在线视频流。对于视频流,MOC只使用之前的K-1帧和当前帧作为输入,由于每帧的特征只需提取一次,我们将之前K-1帧的特征保存在缓冲区中。当一个新的帧到来时,MOC的backbone会立即提取出它的特征,总共K帧的特征会由MOC的三个分支联合操作产生K帧的tubelets,link算法立即将这些tubelets和之前的结果连接得到视频级别的检测结果tubes,单流RGB速度达53FPS。
Movement Branch的有效性探究:

Movement Branch影响了bbox的位置和大小,我们对其有效性进行了探究。Movement Branch将key frame的中心点移动到其他帧来定位bbox的中心点位置,被称为Move Center策略。Box Branch在当前帧的中心点而不是在key frame中心点估计的bbox的大小,被称为Bbox Align策略。我们将MOC和另外两个detector,No Movement和Semi Movement进行对比。如上图所示,No Movement直接去掉了Movement Branch,所有帧都在key frame的中心点生成bbox;Semi Movement首先在key frame的中心点生成bbox,然后根据Movement Branch的轨迹预测结果对框的位置进行调整,Full Movement是MOC采用的方式,Full Movement和Semi Movement的区别就在于Full Movement是在每帧对应中心点估计框大小,而Semi Movement是在key frame的中心点估计框大小。通过No Movement和Semi Movement的对比我们可以看出Movement分支的必要性,并且movement对于video AP的影响更大,因为在link算法的过程中,单帧造成的误差会逐渐积累,造成video AP受到了很大的影响。Semi Movement和Full Movement差距较小,可以证明我们的Box Branch比较鲁棒,估计bbox size时微小的位置扰动不会干扰太多Box Branch的结果。
估计Movement方式的探究:
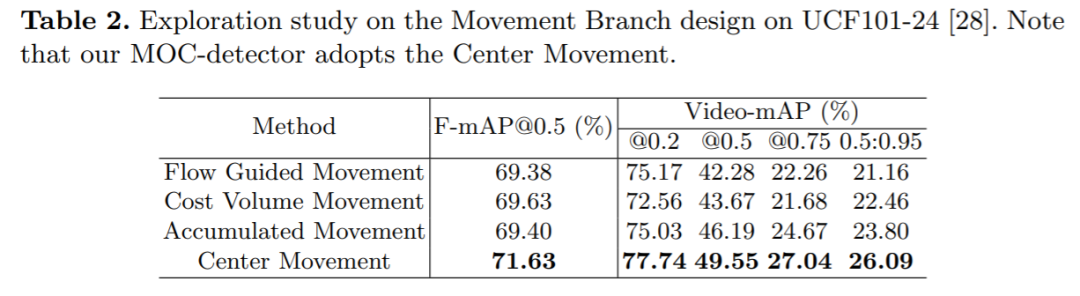
我们分别尝试了用光流和costvolume来代替网络估计Movement,同时也尝试了估计相邻帧之间的movement(MOC估计的是到key frame的movement),通过累积的方式得出中心点运动轨迹,发现MOC中用的方式最高效。
输入长度对结果影响的探究:
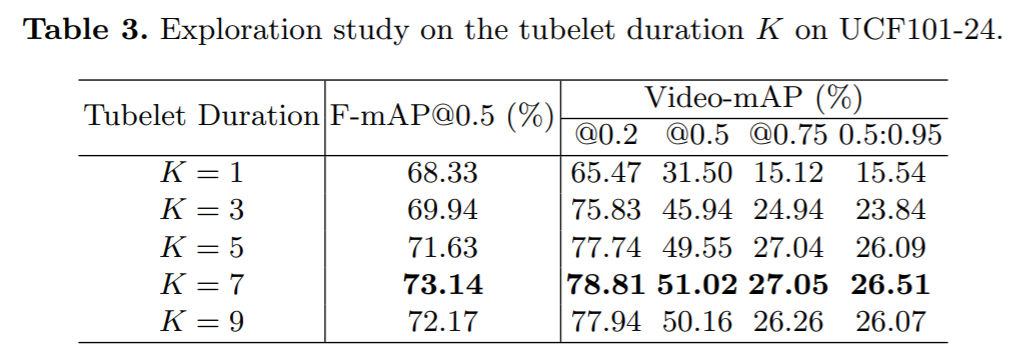
我们改变输入长度进行探究,发现K=1时,MOC变为一个frame-level的detector,效果差了很多尤其是video mAP,验证了tubelet detector确实效果更优。并且发现K=7的时候效果最好,在MOC模型中我们设置K=7。
下载
在CVer公众号后回复:MOC,即可下载论文
下载1
在CVer公众号后台回复:OpenCV书籍,即可下载《Learning OpenCV 3》书籍和源代码。注:这本书是由OpenCV发起者所写,是官方认可的书籍。其中涵盖大量图像处理的基础知识介绍,虽然API还是基于OpenCV 3.x,但结合此书和最新API,可以很好的学习OpenCV。

下载2
在CVer公众号后台回复:CVPR2020,即可下载CVPR2020 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2000+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!

