【MIT智能芯片突破】速度提升30%,能耗降低85%
1 新智元编译
来源:Nature.com; news.mit.edu
编译:熊笑 弗格森
【新智元导读】MIT 计算机科学与人工智能实验室的研究者设计了一个系统,能够在程序运行的同时,对缓存进行重新分配,创造新的“缓存等级”以适应特定程序的需要。这个称为 Jenga 的系统,与表现最好的前代系统相比,将处理速度提高了 20% 至 30%,同时将能耗降低了 30% 至 85%。

几十年来,计算机芯片都是通过使用“缓存”来提升效率:小型的、局部的内存条对频繁使用的数据进行存储,并且会切断与芯片外的内存费时较长、能量消耗大的沟通。
当下的芯片一般都有三层甚至四层的缓存,每一层都比上一层容积大,但是速度却更慢。缓存形状的大小代表了不同程序的需要之前的妥协,但是,要想让它们精确地适配到任何的程序,却是很难的。
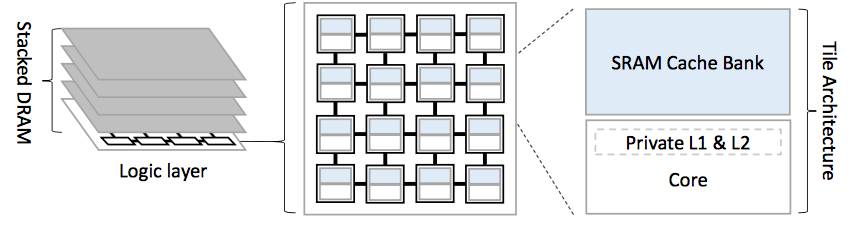
分布式、片上 SRAM 库和 3D-stacked DRAM 缓存的现代多核系统
MIT 计算机科学与人工智能实验室的研究者设计了一个系统,能够在程序运行的同时,对缓存进行重新分配,创造新的“缓存等级”以适应特定程序的需要。
研究人员在具有 36 个内核或处理单元的芯片上对该系统进行了仿真测试。 他们发现,与表现最好的前代系统相比,该系统将处理速度提高了 20% 至 30%,同时将能耗降低了 30% 至 85%。
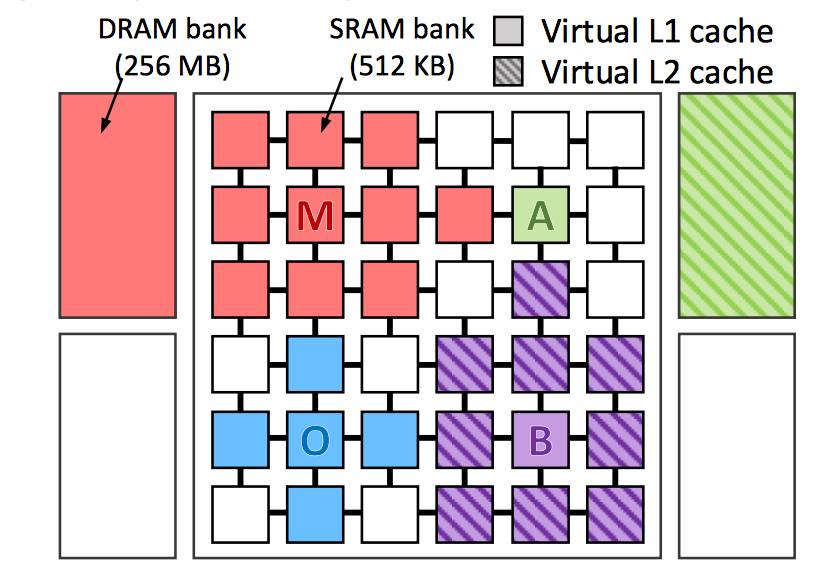
运行了 4 个应用程序的 Jenga 系统
电气工程与计算机科学系(EECS)助理教授DanielSanchez 表示:“我们希望利用这些分布式物理内存资源并构建特定于应用程序的层次结构,以最大限度地提高特定应用程序的性能。”Daniel Sanchez 的团队正是这一新系统的开发者。
“这取决于应用程序中的许多东西。它访问的数据的大小是多少?它是否具有分级重用,以便获益于更大的记忆层次结构?或者它是通过数据结构进行扫描,所以我们最好还是拥有一个单一但非常大的level?访问数据的频率是怎样的?如果我们让数据下到主内存,它的性能会受到多大的损失?这些都需要权衡。“
Daniel Sanchez 及其论文合著者——麻省理工学院EECS 的研究生 Po-AnTsai,以及现在是 CMU 计算机科学助理教授(论文完成时还是麻省理工学院研究生)的Nathan Beckmann,在上周的计算机体系结构国际会议(ISCA) 上介绍了这个被称为 Jenga 的新系统。
在过去10年左右,计算机芯片处理能力的提高来自于增加了更多的内核。今天大部分台式机的芯片有4 核,但是几个主要的芯片制造商已经宣布计划在未来一年内将转为 6核,在高端服务器中,16 核处理器也并不罕见。大多数行业观察家认为内核的数量将继续攀升。
多核芯片中的每个内核通常都有两个级别的专用缓存。所有内核共享第三个缓存,实际上是分解成散落在芯片周围的独立存储器。一些新的芯片还包括所谓的DRAM 缓存,其被蚀刻到安装在第一芯片上端的第二芯片中。
对于一个给定的内核,访问共享高速缓存的最近的存储库比访问更远的内核更有效率。与目前的缓存管理系统不同,Jenga区分组成共享缓存的独立内存库的物理位置。对于每个内核,Jenga 知道从任何芯片存储器中获取信息需要多长时间(即“延迟”的时间)。
Jenga 以Sanchez 团队一个较早的系统为基础,该系统称为Jigsaw,它也能即时快速分配缓存访问。但是 Jigsaw 没有构建缓存层次结构,这使得分配问题变得复杂得多。
对于在每个内核上运行的每个任务,Jigsaw 不得不计算一个延迟空间(latency-space)曲线,这表明内核预期缓存会有多大的延迟。然后,它必须聚合所有这些曲线,以找到最小化芯片整体延迟的空间分配。
而Jenga 同时权衡两层缓存的延迟和空间,这将二维延迟空间曲线转化为三维surface。幸运的是,这个 surface 相当平滑:它可能会起伏,但通常不会有突然的 spike 和dip。
这意味着 surface 上的采样点可以很好地代表整个表面的外观。研究人员开发了一种针对高速缓存分配问题的巧妙采样算法,系统地增加了采样点之间的距离。“这里的想法是,具有相似容量的缓存(例如100 兆字节和101 兆字节)通常具有相似的性能。”Tsai说。“所以几何增加的序列捕获了完整的图景。”
一旦推断了 surface 的形状,Jenga 就可以找到最小化延迟的路径。然后,它提取由第一级高速缓存提供的该路径的组件,这是一个2-D曲线。在这一点上,它可以再次使用 Jigsaw 的空间分配机器。
在实验中,研究人员发现,这种方法产生的总体空间分配,平均来说占据3-Dsurface 完整分析所产生的空间分配的1%以内,这非常耗时。采用捷径的计算方式使得Jenga 每100毫秒就可以更新其内存分配,以适应程序内存访问模式的变化。
Jenga 还具有越来越受到欢迎的DRAM 缓存所驱动的 data-placement 过程。因为靠近访问它们的内核,所以大多数缓存几乎没有带宽限制:它们可以根据内核的需求传送和接收数据。但是更长距离地发送数据需要更多的能量,并且由于DRAM 高速缓存在芯片外,所以它们具有较低的数据速率。
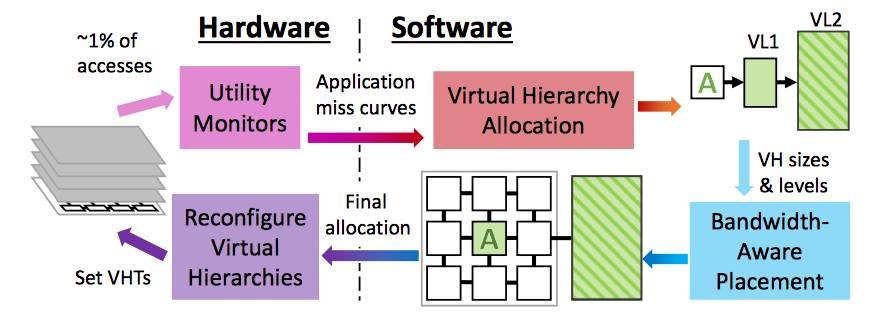
Jenga 重新配置的示意图。硬件配置应用程序; 软件周期性地重新配置虚拟层次结构以最小化总访问延迟。
如果多个内核正在从同一DRAM高速缓存中检索数据,则可能会导致瓶颈现象,产生新延迟。因此,在Jenga 提出了一组缓存分配方案之后,内核不会将所有数据简单地转存到最近的可用内存中。相反,Jenga 一次打包发送一部分数据,然后评估出对带宽消耗和延迟的影响。因此,即使在芯片级高速缓存重新分配之间的100 毫秒间隔内,Jenga会调整每个内核内存分配的优先级。
威斯康星大学麦迪逊分校计算机科学教授 DavidWood 说:“多年来,对于如何正确设计缓存层次结构的研究已经很多了。以前也有一些方案,试图做一些层次结构的动态创建。 而 Jenga不同,因为它真的使用软件来尝试描述工作负载的特征,然后进行资源的最佳分配。从根本上说,这比以前一直在做的更强大。所以我认为这很有趣。”
编译来源:http://news.mit.edu/2017/using-chip-memory-more-efficiently-cache-hierarchies-0707





