来源丨https://zhuanlan.zhihu.com/p/544346080
本文首先讨论了把pseudo labeling和consistency training直接迁移到目标检测中的不适配现象,然后再解释如何通过FPN的错位训练实现高效半监督目标检测,并取得SOTA的表现。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
![]()
论文链接:
https://arxiv.org/abs/2203.16317
代码链接:
https://github.com/ligang-cs/PseCo
Preliminary
半监督目标检测是研究,在有一部分标注数据的前提下,如何利用大量的
无标注数据来提升检测器性能。广泛采用的pipeline是Mean-Teacher,即,通过EMA来实时生成teacher model,然后,让teacher model生成伪标签,用于监督student model的训练。但是,Mean-Teacher的范式,很容易出现over-confidence的问题,student model很容易过拟合teacher model的预测。为了缓解over-confidende,FixMatch提出了对teacher和student分别使用不同强度的数据增广,具体地,对teacher的输入采用
弱数据增广(flip, scale jitter等),保证伪标签的质量;而对student的输入,采用
强数据增广(rotate, color jitter,一些几何形变等),增加student的训练难度,防止过拟合。
1. Motivation
Pseudo labeling和consistency training是半监督学习里面的两个关键技术,但是直接迁移到目标检测上,会出现一些不适配的现象。我们详细分析了一下,具体的不适配有哪些:
1.1 Pseudo Labeling
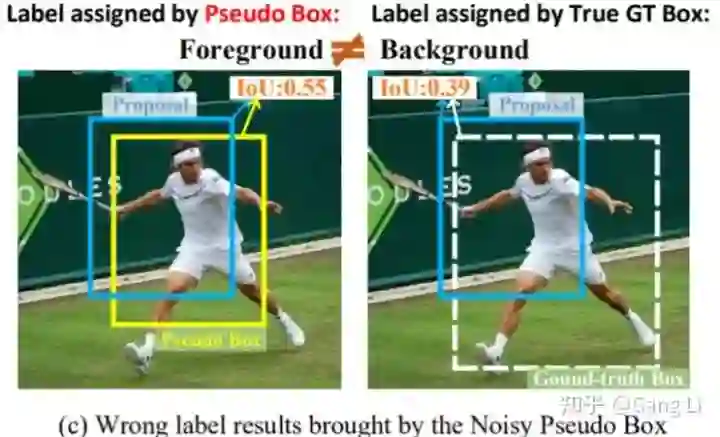
pseudo labeling通过设置一个较高的score threshold,把Teacher model预测的置信度较高的检测结果保留下来,作为伪标签(pseudo boxes)。但是在目标检测中,分类score和box的定位质量往往没有强相关,score较高的pseudo box可能定位并不准。所以,Pseudo box中难免存在一些定位不准的box框。那么,定位不准的pseudo box会给半监督训练带来哪些影响呢?1. 会影响IoU-based label assignment;如下图1,质量很差的proposal会被错误地assign成正样本,模糊正负样本的分类边界。2. 不准确的Pseudo Box不适合用来训练bbox回归的任务。
为了缓解这两个影响,我们分别设计了Prediction-guided Label Assignment (预测引导的标签分配, PLA)和Positive-proposal Consistency Voting (正样本一致性投票,PCV),来实现比较鲁棒的
带噪伪标签学习。其中,PLA根据Teacher prediction来分配正负样本,减少了对IoU的依赖;PCV根据proposal的预测一致性,来反映pseudo box的定位质量,抑制定位不准的pseudo box。
![]() 图1 coarse pseudo box (黄色框)会误导label assignment
图1 coarse pseudo box (黄色框)会误导label assignment
1.2 Consistency Training
consistency training通过在student训练过程中,加入一些扰动,让模型的预测结果对扰动保持 鲁棒,从而学到一些重要的不变性。尺度不变性(scale invariance)作为目标检测最重要的几个属 性之一,一直收到广泛的关注。但是以前的工作,仅仅采用random resize来学习尺度不变性,对 输入图像做比例为
的缩放,同时也会对ground truth做相应比例
的缩放,我们把这种一致性 叫作label-level consistency.
除了这种label-level的尺度不变性外,其实目标检测网络还有 feature层面的尺度不变性。通俗的说就是,对于同一张image,我们把它放缩到两种不同的scale (比如 scale
, scale
),如果能让它们的feature拥有一样的shape,即 Feat scale
的tensor维 督。得益于FPN的金字塔结构,feature层面的对齐很容易实现。我们提出了一种Multi-view Scale-invariant Learning (多视角尺度不变性学习,MSL),同时从label- and feature-level consistency的角度,学习尺度不变性,实现了高效的半监督学习。
2. Method
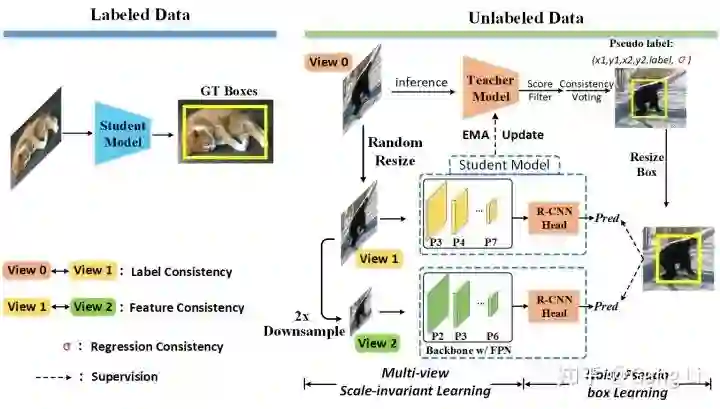
![]() 图2 PseCo的framework
PseCo的framework如图2所示。在unlabeled data上,我们对输入图像分别做不同的scale jitter,构建出view 0和view 1,其中,view 0是teacher model的输入,而view 1是student model的输入,通过view 0 - view 1 pair的学习,label-level consistency被实现,这也就是之前大家常用的random resize. 接着,
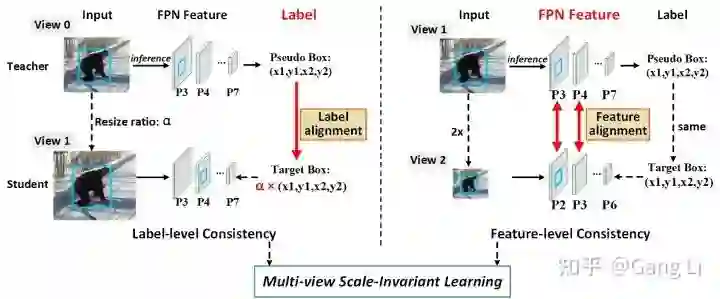
我们对view 1做2倍下采样,得到view 2。由于FPN的特征金字塔,view 1的P3-P7 features和view 2的P2-P6 features,可以实现完美的对齐。我们用相同的Pseudo Boxes来监督view 1的P3-P7层和view 2的P2-P6层。这个可以理解成FPN的错位训练。至此,我们在一个网络中,通过label-level and feature-level consistency,实现了更加全面的尺度不变性学习。关于两种consistency的比较,可参考图3.
图2 PseCo的framework
PseCo的framework如图2所示。在unlabeled data上,我们对输入图像分别做不同的scale jitter,构建出view 0和view 1,其中,view 0是teacher model的输入,而view 1是student model的输入,通过view 0 - view 1 pair的学习,label-level consistency被实现,这也就是之前大家常用的random resize. 接着,
我们对view 1做2倍下采样,得到view 2。由于FPN的特征金字塔,view 1的P3-P7 features和view 2的P2-P6 features,可以实现完美的对齐。我们用相同的Pseudo Boxes来监督view 1的P3-P7层和view 2的P2-P6层。这个可以理解成FPN的错位训练。至此,我们在一个网络中,通过label-level and feature-level consistency,实现了更加全面的尺度不变性学习。关于两种consistency的比较,可参考图3.
![]() 图3 label-level和feature-level consistency比较。feature level的对齐,可以通过移动FPN pyramid level来实现
对于Pseudo labeling的改进,我们提出了PLA和PCV,分别从分类任务和回归任务的角度,来实现鲁棒带噪标签学习。PLA (prediction-guided label assignment)提出了一种label assignment的方式,比传统的IoU-based策略,更适合应对带噪的标签。PLA对每个GT,先构造了一个更大的candidate bag,包含了所有的、有潜力成为正样本的proposals (or candidates),然后根据teacher model在这些candidates上的预测结果,来评判每个candidate的质量,最后选取质量最高的top-N个candidates作为正样本。PLA减少了label assignment对IoU的依赖,避免了不准确的pseudo box对label assignment的消极影响。
此外,PCV(positve-proposal consistency voting) 直接对Pseudo Box的定位精度做出了判断,定位准确的Pseudo Box会被分配比较大的regression loss weight,反之,就分配小的reg loss weight. 细节上,因为在目标检测中,1个GT往往会匹配多个positive proposals,我们发现这些positive proposals的回归一致性能够反映出对应的pseudo box的定位精度,更多细节请参考论文。
图3 label-level和feature-level consistency比较。feature level的对齐,可以通过移动FPN pyramid level来实现
对于Pseudo labeling的改进,我们提出了PLA和PCV,分别从分类任务和回归任务的角度,来实现鲁棒带噪标签学习。PLA (prediction-guided label assignment)提出了一种label assignment的方式,比传统的IoU-based策略,更适合应对带噪的标签。PLA对每个GT,先构造了一个更大的candidate bag,包含了所有的、有潜力成为正样本的proposals (or candidates),然后根据teacher model在这些candidates上的预测结果,来评判每个candidate的质量,最后选取质量最高的top-N个candidates作为正样本。PLA减少了label assignment对IoU的依赖,避免了不准确的pseudo box对label assignment的消极影响。
此外,PCV(positve-proposal consistency voting) 直接对Pseudo Box的定位精度做出了判断,定位准确的Pseudo Box会被分配比较大的regression loss weight,反之,就分配小的reg loss weight. 细节上,因为在目标检测中,1个GT往往会匹配多个positive proposals,我们发现这些positive proposals的回归一致性能够反映出对应的pseudo box的定位精度,更多细节请参考论文。
3. Experiments
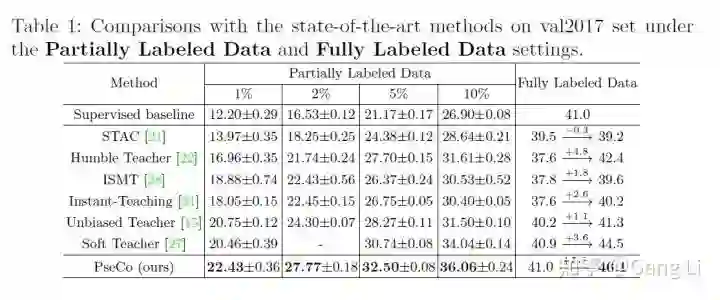
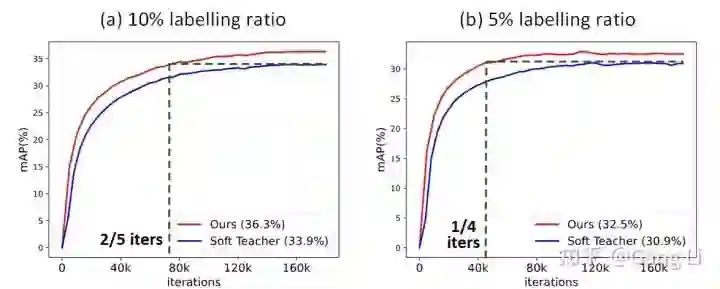
我们在partial labeled和full labeled settings下,都取得了SOTA的性能。此外,我们的训练效率也非常高,如图4所示,在5%和10%标签比例下,
我们都仅用了不到一半的训练时长,就达到了Soft Teacher的精度。虽然我们增加了一个view 2,但是因为view 2的图片分辨率非常小,增加的训练开销很小,每个iteration增加的的训练时长不到20%.
![]() 图4 PseCo收敛速度
图4 PseCo收敛速度
4. 碎碎念
(1) unlabeled data上的strong augmentation,一方面可以使得模型学习到一些重要的不变性,另一方面,可以增加训练难度,有效缓解over-confidence。如果不加强aug的话,训练后期会出现一个现象:拟合pseudo label会拟合得越来越好,但是mAP就是不涨。本文提出的MSL,或者叫FPN错位训练,其实也是提供了一种强aug,让student model同时处理两种训练模式,不容易过拟合:一种是高分辨率输入,P3-P7训练;另一种是低分辨率输入,P2-P6训练。其实,MAE的masked image也可以看做强aug,似乎可以融入到半监督中。
(2) 在实际使用中,unlabeled data更可能是out-of-distribution的,和labeled data不在同一个domain。如何从ood的unlabeled data中高效学习出有用的信息,是比较难的。比如,如果做人脸检测,labele data用WiderFace,unlabeled data用MS COCO,可能这个设定下的半监督学习就是无效的。甚至,会因为网络更多地拟合unlabeled data的domain,导致掉点。
(3) 现在Teacher model仅仅提供pseudo box给student model训练,这种pseudo box是比较稀疏的监督信息。在此基础上,我们提出了Dense Teacher Guidance (
https://arxiv.org/abs/2207.05536),研究如何从Teacher prediction中挖掘出更多的监督信息。
公众号后台回复“ECCV2022”获取论文分类资源下载~
![]()