91.3%!首个将Transformer解码器应用于多标签图像分类的方法Query2Label

极市导读
随着Transformer模型在视觉领域的成功,由于其所具有的各种优秀的性质,本文作者将其应用到了多标签图像分类任务中,提出了Query2Label方法,使用Transformer解码器来查询每个标签的存在性,由于其框架简单且性能强劲,在多个公开数据集上取得了SOTA。 >>加入极市CV技术交流群,走在计算机视觉的最前沿

论文地址:https://arxiv.org/pdf/2107.10834v1.pdf
开源地址:https://github.com/SlongLiu/query2labels
多标签图像分类(Multi-label image classification)一直以来都是很重要的研究领域,可以从一张图片中获得比单标签分类更丰富的信息,在如图像检索、人像分组、医学图像识别、场景理解等多个领域都有广泛应用。在我们熟悉的ImageNet数据集分类任务上,2021年timm团队提出的训练策略可以将ResNet50模型的分类准确率提升到Top1-80%以上,其中也用到了多标签分类相关的技术(BCELoss+Mixup+CutMix)。
1. 简介
多标签分类
为了照顾到一部分没有相关知识的小伙伴,我先对多标签图像分类做一个简单的回顾。
首先,多标签分类(Multi-label classification)是相对于单标签分类(Single-label classification)而言的。一张图片,对应一个标签,这就是单标签分类,我们熟悉的ImageNet就是一个单标签标注的数据集,我们常说的ImageNet上的分类准确率也指的是模型为一张图片预测一个标签的准确率。而多标签分类时,一张图片,对应多个标签,且标签数量不确定,一般我们将存在的标签记为1,不存在的标记为0,当标签一共有N类时,我们会输出一条N维的由0/1组成的向量,每一项对应了一个标签的存在与否。
对于多标签分类任务,我们最常用的方式是使用Sigmoid+BCELoss。
在单标签分类时,由于模型只需要预测一个结果,我们希望让模型在正确标签上的置信度越高越好,所以采用了SoftMax+CrossEntropy的组合,SoftMax的性质保证了输出结果在0~1之间,且最大的那一项尽量趋近于1,其余项尽量趋近于0,最后通过Argmax得到置信度最高那一项所在的位置;而多标签分类时,我们把全连接层输出的特征通过Sigmoid让每一项都在0~1之间,再通过二分类交叉熵进行优化。
问题
相较于单标签分类,多标签分类的问题主要在于两点:
-
如何处理标签数量差异带来的类别不均衡问题
-
如何区分不同兴趣区域的特征
问题1在于,我们的batch size是有限的,每张图片对应的标签数也是不确定的,因而当标签类别很多的时候(即图片带有的标签数远小于总标签类别数),会导致这个batch中大部分标签是0,只有很少一部分是1,也就是正负样本不均衡问题。
问题2在于,标签对象分布在图片的不同位置上,大小也不一定,我们很难针对性地提取特征,如果我们按照单标签图片特征的提取方式,直接对整张图片提一个特征,会导致有些目标的特征被稀释,比如在图片中较小、较不显著的、画质较差的目标。
随着多标签分类研究的发展,目前所提出的方法主要可以归纳为三个方向:
-
改进损失函数
-
对标签相关性进行建模
-
定位兴趣区域
改进损失函数
通过改进损失函数来缓解正负样本不均衡问题是常见的做法,在目标检测领域,Kaiming提出的Focal Loss就是在BCELoss的基础上进行修改,通过减少高置信度样本的权重,使得模型在训练时更专注于难样本的学习,在正负样本不均衡的数据中,这种方法可以让模型减少对负样本的过拟合,专注于学习数量较少的正样本。
但由于Focal Loss是通过使用同一个参数gamma来调节学习权重,其形式会导致模型在降低简单负样本权重的时候,也会同样减少简单正样本的贡献,换句话说,Focal Loss的本质还是对难易样本的区别对待,对于正负样本不均衡问题并不是百分百适配。因此在ASL(Asymmetric Loss)工作中,对正负样本的权重调节参数gamma进行了解耦,在减弱负样本权重的同时,能保留正样本的贡献能力。
建模标签相关性
由于一张图片对应多个标签这样的性质,有研究者提出,标签与标签之间是存在相关性的,有些标签大概率会一起出现(比如乒乓球拍和乒乓球,雨伞和人等等),这种先验知识可以被利用起来提升预测的准确率。
在过去有研究者使用图卷积网络(GCN)来专门建模这种标签相关性,而在Transformer出现后,其自注意力机制天生就具有相关性建模能力。
然而需要注意的是,这种方法的有效性是存在争议的,尤其是当数据规模不够大的时候,这种统计得到的共现关系就可能是虚假的。
定位兴趣区域
在早期的工作中,大家很自然地想到,可以通过裁剪等方式来将多标签问题简化为多个单标签问题,定位和裁剪方式也五花八门,如BBox、响应区域等,但这些方法的定位准确度不够高,不可避免地会引入背景信息。
2. 方法
随着Transformer模型在视觉领域的成功,由于其所具有的各种优秀的性质,本文作者将其应用到了多标签图像分类任务中,提出了Query2Label方法,使用Transformer解码器来查询每个标签的存在性,由于其框架简单且性能强劲,在多个公开数据集上取得了SOTA,在比较具有代表性的MS-COCO数据集上,2020年的SOTA方法mAP为88.4%,而本文取得了91.3% 。
本文的贡献在于:
-
本文是第一个使用Transformer解码器结构在分类任务中的工作。
-
实验显示了Transformer解码器中的交叉注意力模块可以自适应地提取目标特征,配合多头注意力机制能进一步学习目标的不同视角、不同部位,从而来带了更好的性能。
-
在多个公开数据集上实验证明了本文方法的有效性和优越性。
Query2Label
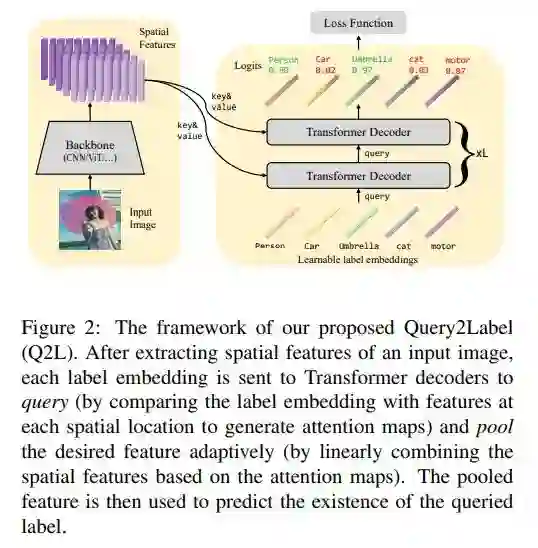
首先框架上,Query2Label是一个两阶段框架,第一阶段将图片通过一个骨干网络提取特征图,第二阶段将图片特征和标签特征一起送入Transformer解码器中,图片特征作为key和value,标签特征作为query,将Transformer输出的query特征经过自适应特征池化和线性投影后预测标签存在性。
对于第一阶段,骨干网络作为一个特征提取器是可以自由替换的,可以使用CNN-based网络,也可以使用ViT等Transformer-based。
对于第二阶段,自适应池化和线性投影都是很常见的操作,一般是通过GlobalAvgPool+FC来实现。
Query updating
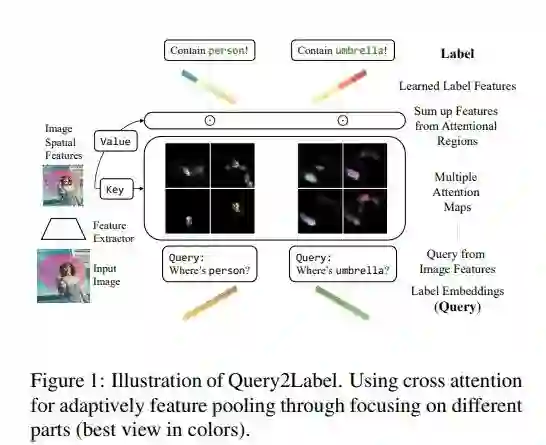
不同于大部分ViT-like模型使用Transformer编码器模块,本文使用的是解码器结构,每一层解码器模块中包含了一个自注意力模块,一个交叉注意力模块,和一个带位置编码的前馈网络。

通过初始化可学习的参数来学习每个标签的特征向量,在计算自注意力模块时,query,key,value三个值都是标签特征,而在交叉注意力模块中key和value时图片特征,而query是标签特征。
解码器结构对于多标签分类任务有很多好处,首先是自注意力模块全部计算标签特征,能学到标签之间的相关性,而交叉注意力模块使每一个标签的特征能自适应地与图片特征匹配。而独立为每个标签建立可学习参数这一做法,使得每个标签特征语义十分明确。
最终标签特征经过Transformer层输出的特征向量,直接通过线性投影即可得到对应的logits,进行Sigmoid+LossFunction监督。
Loss Function
损失函数部分,本文采用了一个简化版的ASL,如前文改进损失函数中所述,在Focal Loss上对正负样本采用不同的调节权重,最终取得了比BCELoss和Focal Loss更好的效果。
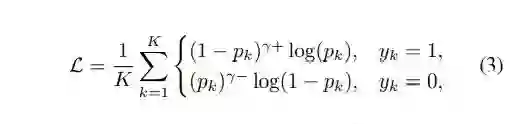
实验
ASL作为上一个SOTA,采用的Backbone是TResNetL,为了跟ASL的结果进行公平对比,本文也基于TResNetL进行了实验。由于Backbone可以随意替换,本文又实验了其他更强的Backbone,在MS-COCO数据集上结果如下:
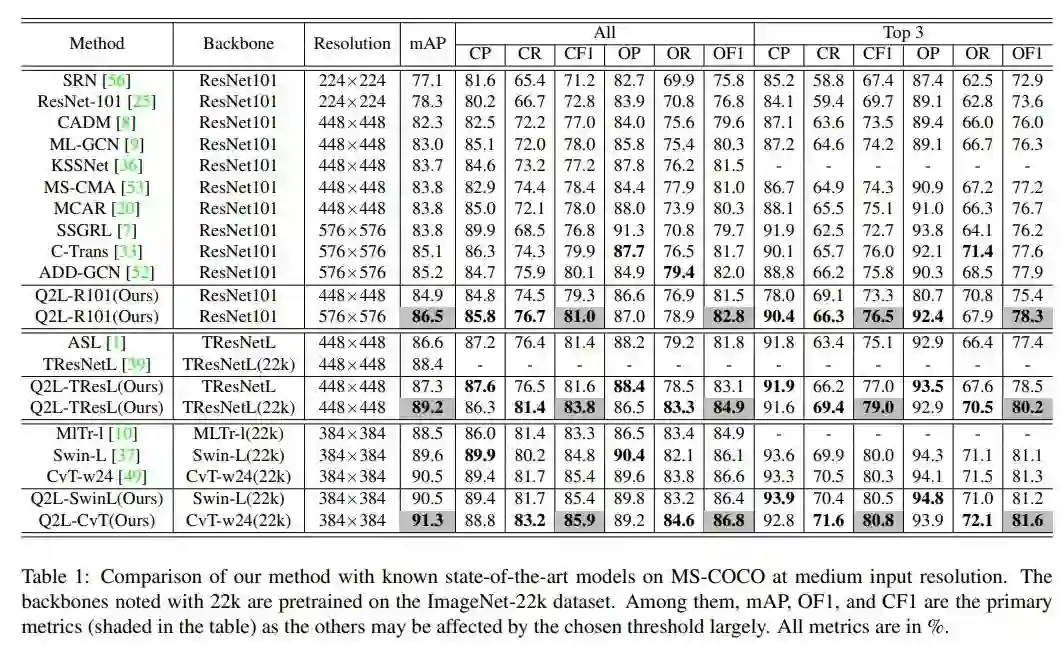
可以看到经过了ImageNet22k预训练的模型可以取得更高的性能,但同等条件下横向对比,Query2Label方法超越了ASL等其他方法。
如果对更多的实验结果感兴趣可以自行查阅原文,在这里就不一一贴出了。
不同尺寸目标
由于不同目标在图中的尺寸不同,本文进行了更详细的实验对比,将小于32x32的目标视为小目标,小于96x96之间的为中目标,大于的为大目标,与Baseline相比在所有尺度上均有优势。
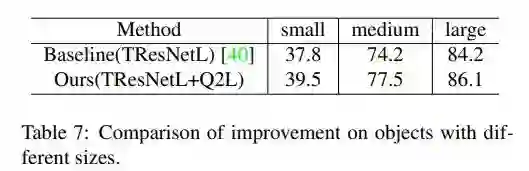
但是我注意到这里对比的是基于TResNetL的Baseline而非ASL,可能是由于相较于ASL的优势不那么明显。
可视化
通过对交叉注意力图进行可视化,我们可以看到不同标签特征可以很好地捕捉到对应目标。

而跟Baseline的对比可以发现,Query2Label方法的注意力区域更加集中、更加准确,引入了更少的无关背景。

公众号后台回复“数据集”获取30+深度学习数据集下载~

# 极市平台签约作者#

Tau
知乎:镜子
计算机视觉算法工程师
研究领域:姿态估计、轻量化模型、图像检索
持续学习,乐于实验总结,分享学术前沿,注重AI技术实用性和产品化
作品精选




