CVPR 2022 Oral | 即插即用!语义感知的域泛化语义分割模型:SAN-SAW
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文转载自:阿柴的算法学习日记
本文分别基于Instance Normalization (IN)与Instance Whitening (IW) 提出了两个用于编码器与解码器之间的即插即用模块:Semantic-Aware Normalization (SAN)与Semantic-Aware Whitening (SAW),能够极大的提示模型的泛化能力。在面临各种与训练数据的分布不一致的测试数据时,SAN与SAW仍能帮助模型尽可能的维持模型的性能,可以说是竞赛乃至现实应用中的一大提点利器。

Semantic-Aware Domain Generalized Segmentation
论文地址: https://arxiv.org/pdf/2204.00822.pdf 代码地址: https://github.com/leolyj/SAN-SAW
一、Motivation
语义分割中的无监督域适应(UDA)基于目标域影像数据可知但对应标签数据不可得这一前提。但是一个更为现实的前提是我们无法得知包括图像数据在内的目标域任何信息,换句话说,就是模型在测试时可能会面临各种各样数据分布的图片,如果模型的泛化能力不够,那么其性能肯定会出现很大的波动。
增强模型的泛化能力一个最常用的方式就是数据增强,即把训练数据转换为各种各样的形式使得模型在训练阶段就见过各种各样的数据分布,从而提高模型的泛化能力。但是寄希望于数据增强能够使得转换后的训练数据覆盖所有测试数据的分布是不现实的。因此,数据增强的方式来增强模型的泛化能力具有其固有的缺陷。

图 1 应用不同的方法后,同一模型的编码器所提取的来自不同数据分布(不同域)的测试图片的特征分布。
另一个方向来增强泛化能力的方式是使用Normalization 和 Whitening,该方向的方法利用实例归一化(Instance Normalization, IN)或实例白化(Instance Whitening,IW)对不同样本的特征分布进行标准化。IN分别对单个图像的每个通道的特征进行标准化归一化,以减轻由于样式变化引起的特征不匹配。IN的具体过程可以由以下公式来表示:
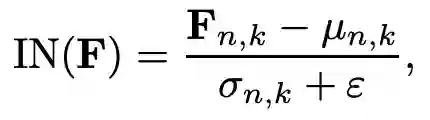
|
|
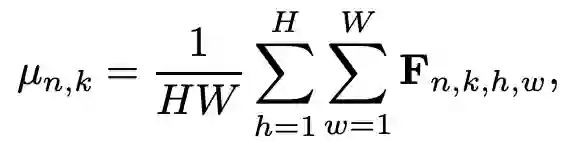
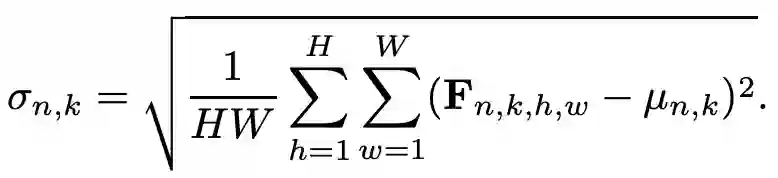
其中,F_n,k,h,w 表示一个 mini-batch 对应的特征图 F 中第 n 个 sample 的第 k 个通道特征图上空间位置为(h,w)上的特征值。但是如图1 (a)所示,使用IN只实现了特征分布的中心对齐,但是无法对齐特征的联合分布。而如图1 (b)所示, 由于IW 可以消除各通道特征间的线性相关性,所以使用 IW 后可以形成均匀分布的良好聚类特征。IW的具体工程可以由以下公式来表示:
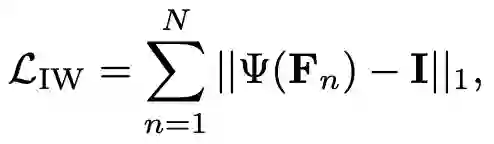
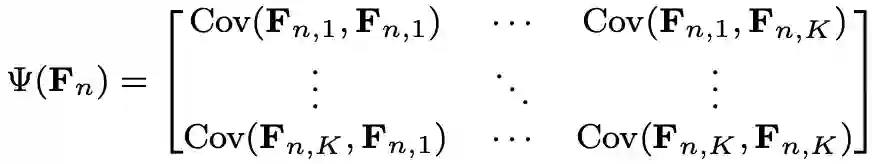
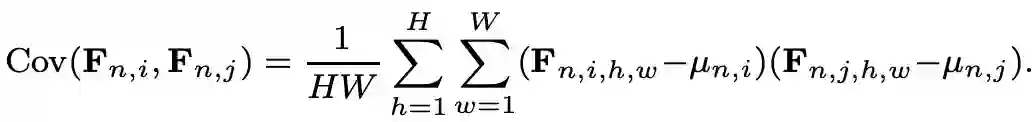
其中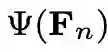
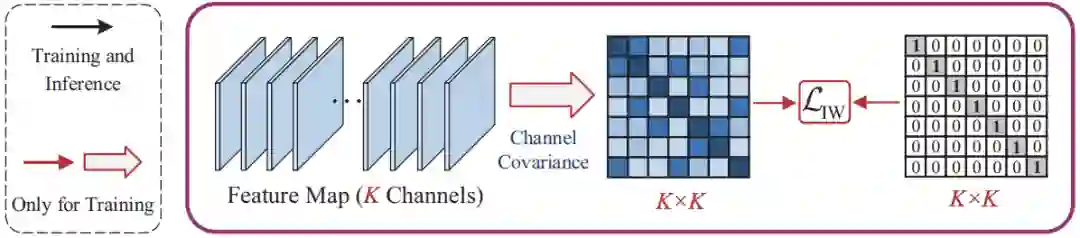
图2 IW的示意图
从如图1 (b)也可观察得到,特征虽然均匀分布了,但是却也没有对齐特征的联合分布。最近有论文研究表明,如图1 (c)所示,联合IN与IW后,能够对齐来自不同域(即数据分布不同)的联合特征边缘分布。然而,图1 (c)中也可以观察到虽然特征边缘分布得到了对齐,但是条件分布却依然处于没有对齐的状态,每个类别的分布仍然混合在一起以至于难以区分。
那么由此引出了本文的出发点:既要对齐特征的全局边缘分布,也要对齐条件分布,从而使得每个类别的分布在特征空间能够被很好的区分开。具体做法便在于在IN与IW的基础上引入了类别信息。下面来看一下具体方法设计。
二、方法
整体的框架如图3所示。
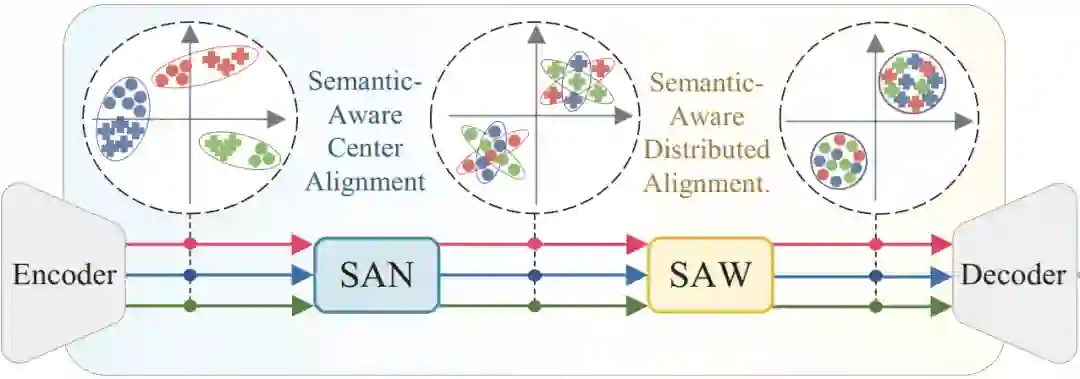
图3 模型总体框架图。
也就是说,在原有分割模型编码器-解码器的结构框架上插入了两个即插即用的模块:Semantic-Aware Normalization (SAN)与Semantic-Aware Whitening (SAW)。它们分别基于IN与IW而设计:
Semantic-Aware Normalization (SAN)
SAN的总体框架如图4所示。
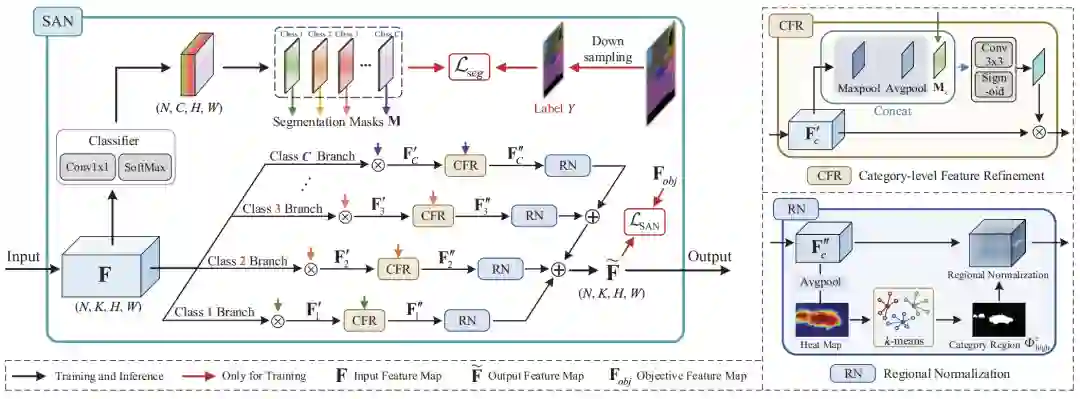
图4 SAN框架图
该模块看似很复杂,但是其本质内容却很简单。
SAN模块设置了一个归一化后的特征图真值F_obj, 它是通过对编码器提取的特征图 F 进行如下类别级别的实例归一化后得到的:
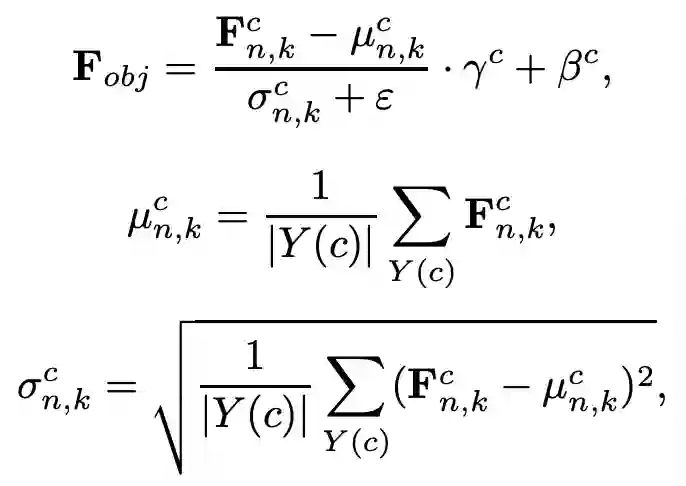
其中,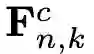
但是,之所以 F_obj 能够得到类别级别的归一化是因为有真值标签 Y。然而测试阶段真值标签是不可得的。所以,SAN中添加了一个预分割的分支,受到下采样的真值标签的监督,以引入相对正确的语义类别信息。编码器提取的特征图 F 会分别与预分割分支的对应类别的通道相乘以强调特征图中对应语义类别区域的特征。
但是由于预分割分支的分割可能不那么准确,这种直接相乘后的特征图可能会错误的强调一些不属于当前类别的的区域的特征,因此,作者提出了一个类别级别的特征优化模块(CRF)来改善特征。CRF的具体操作图示很清楚,可能需要注意的是这里的Maxpool和Avgpool是在通道维度上展开的。这样能够一定程度上的平滑预分割引入的错误信息。
经过CRF优化后的特征会送入区域归一化(Regional Normalization,RN)中进行最终的归一化操作。RF与IN的区别在于不是整个原始特征图上进行归一化,而是针对每一个类对应的区域进行归一化。这里其实CRF输出的特征图上如同图示中的heatmap一般会高亮对应语义类别的区域。为了进一步细化以及最终分割出对应语义类别的区域,会先对heatmap进行k-means聚类(k是超参数,论文里设置为5),然后选择其中的第一个类别作为对应语义类别的区域。选中的区域记为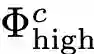
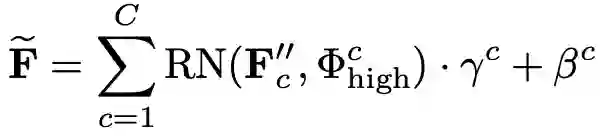
其中,RN对应区域归一化。原文中没有写清楚RN的具体操作,代码实际上还处于没开源的状态。我猜测RN就是对应
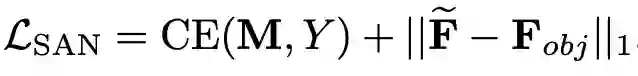
其中CE应该就是图4中的L_seg,而第二项的作用在于使得SAN的归一化结果在没有真值标签的情况下逼近F_obj.
Semantic-Aware Whitening (SAW)
SAW的通体框架如图5所示。
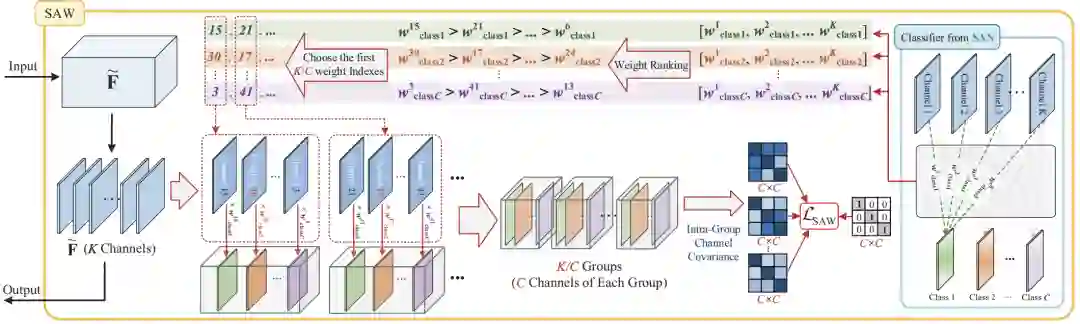
图5 SAW框架图示意
SAN中归一化后的特征会送入SAW中进行进一步的处理以对齐全局边缘分布与条件分布。从图上来看,又是一个看似很复杂的模块,实际上也不复杂。
SAW基于IW的改进版本GIW(分组实例白化)而来。GIW认为直接采用IW这种严格去除所有通道之间相关性的强白化方式可能会损害语义内容,导致关键的领域不变信息的丢失。因此,如图6所示,GIW将特征图分为了几个组,只去除组内的特征通道之间的相关性。
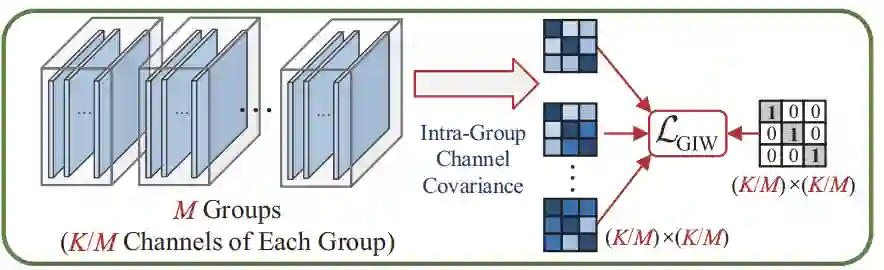
图6 GIW的示意图,其中L_GIW形式上与图2中的L_IW类似,只是重复了M次
然而,GIW只对相邻通道特征图进行去相关性操作,却没有考虑寻找更合适的通道组合。我们知道,每个通道的特征实际上提取的是对应某一个类别的关键语义信息。因此,我们可以以语义类别的信息来进行分组。这个语义信息就来自SAN中的Classier中的权重。它代表了特征图中每个通道的特征图对不同类别的重要程度。对这个进行排序,然后依次取出对应的特征图便可以得到分组后的特征。一共选取了K/C组,每组C个通道。分组之后计算与图6中的L_GIW形式一致的损失函数L_SAW即可。
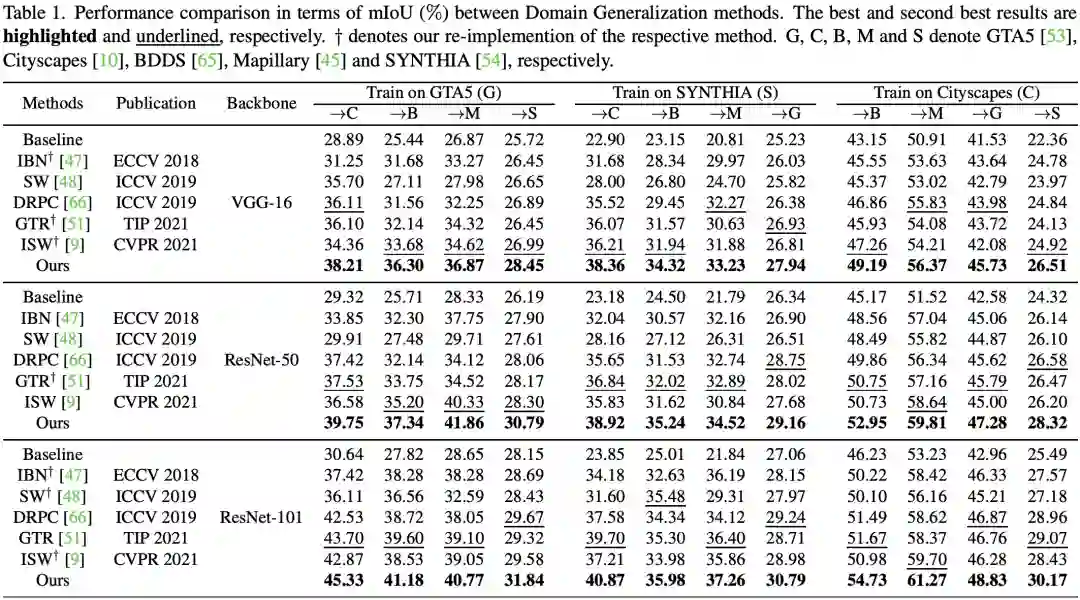
三、试验
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
图像分割和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-图像分割或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如图像分割或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号

整理不易,请点赞和在看

