全网第一SoTA成绩却朴实无华的Pytorch版EfficientDet
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
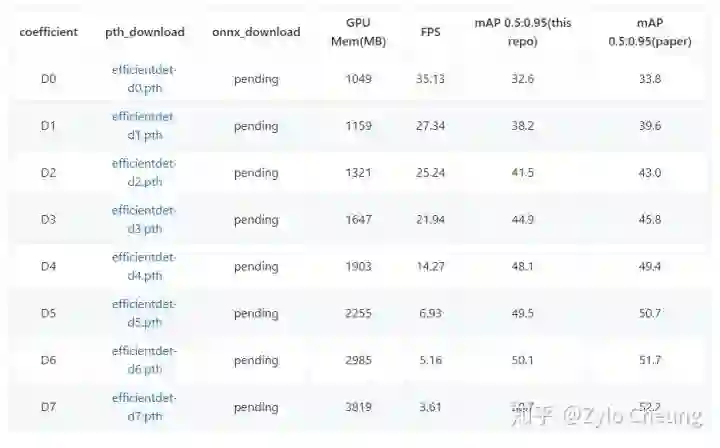
-
为什么之前都没有人复现efficientdet的成绩? -
高star的efficientdet之间的差异? -
那么多个民间efficientdet,我应该用哪个?

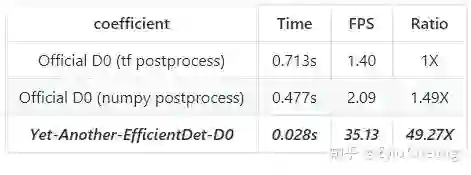
-
这个作者的BN实现有问题,BatchNorm是有一个参数,叫做momentum,用来调整新旧均值的比例,从而调整移动平均值的计算方式的。而问题来了,人家官方efficientdet用的tensorflow。。。tensorflow的momentum定义和pytorch不一样。。。没想到吧!!!这就是我的坑人方法啊!这个套路熟悉吗?而这个作者沿用了论文写到的0.997,所以在pytorch里面,就是等于说新的输入的mean、std的系数是0.997。。。整个移动参数,都被新输入给主导了,被破坏了,所以BN的表现非常糟糕。
momentumpytorch = 1 - momentum_tensorflow
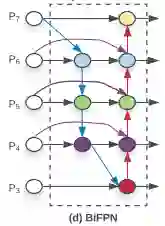
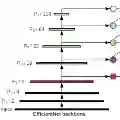
illustration of a minimal bifpn unit
P7_0 -------------------------> P7_2 -------->
|-------------| ↑
↓ |
P6_0 ---------> P6_1 ---------> P6_2 -------->
|-------------|--------------↑ ↑
↓ |
P5_0 ---------> P5_1 ---------> P5_2 -------->
|-------------|--------------↑ ↑
↓ |
P4_0 ---------> P4_1 ---------> P4_2 -------->
|-------------|--------------↑ ↑
|--------------↓ |
P3_0 -------------------------> P3_2 -------->
参考


△长按添加极市小助手

△长按关注极市平台,获取最新CV干货

登录查看更多
相关内容
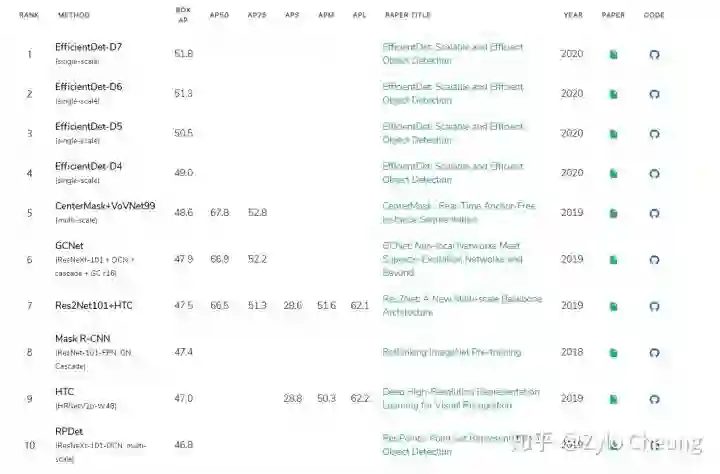
谷歌大脑 Mingxing Tan、Ruoming Pang 和 Quoc V. Le 提出新架构 EfficientDet。EfficientDet检测器是单次检测器,非常类似于SSD和RetinaNet。骨干网络是ImageNet预训练的EfficientNet。把BiFPN用作特征网络,该网络从骨干网络获取3-7级{P3,P4,P5,P6,P7}特征,并反复应用自上而下和自下而上的双向特征融合。在广泛的资源限制下,这类模型的效率仍比之前最优模型高出一个数量级。具体来看,结构简洁只使用了 52M 参数、326B FLOPS 的 EfficientDet-D7 在 COCO 数据集上实现了当前最优的 51.0 mAP,准确率超越之前最优检测器(+0.3% mAP),其规模仅为之前最优检测器的 1/4,而后者的 FLOPS 更是 EfficientDet-D7 的 9.3 倍。
专知会员服务
27+阅读 · 2019年11月24日


相关VIP内容
专知会员服务
27+阅读 · 2019年11月24日
相关资讯
相关论文