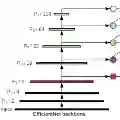
谷歌大脑 Mingxing Tan、Ruoming Pang 和 Quoc V. Le 提出新架构 EfficientDet。EfficientDet检测器是单次检测器,非常类似于SSD和RetinaNet。骨干网络是ImageNet预训练的EfficientNet。把BiFPN用作特征网络,该网络从骨干网络获取3-7级{P3,P4,P5,P6,P7}特征,并反复应用自上而下和自下而上的双向特征融合。在广泛的资源限制下,这类模型的效率仍比之前最优模型高出一个数量级。具体来看,结构简洁只使用了 52M 参数、326B FLOPS 的 EfficientDet-D7 在 COCO 数据集上实现了当前最优的 51.0 mAP,准确率超越之前最优检测器(+0.3% mAP),其规模仅为之前最优检测器的 1/4,而后者的 FLOPS 更是 EfficientDet-D7 的 9.3 倍。
精品内容
没有数据了, 换个别的吧!