点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达![]()
2020 年 2 月 7 日-2 月 12 日,AAAI 2020 将于美国纽约举办。
不久之前,大会官方公布了今年的论文收录信息:
收到 8800 篇提交论文,评审了 7737 篇,接收 1591 篇,接收率 20.6%。
为向读者们分享更多的优质内容、促进学术交流,在 AAAI 2020 开幕之前,机器之心策划了多期线上分享。
上周四,华中科技大学白翔教授组的刘哲为我们介绍他们的 AAAI Oral 论文《TANet: Robust 3D Object Detection from Point Clouds with Triple Attention》,本文对此论文进行了详细解读。
该研究提出了新型三元注意力模块和 Coarse-to-Fine Regression,实现了检测性能和稳健性的提升。
![]()
论文链接:https://arxiv.org/abs/1912.05163
代码链接:
https://github.com/happinesslz/TANet(即将开源)
华中科技大学和中科院自动化所的研究者近期合作了一篇论文,探讨了点云 3D 目标检测的稳健性,这在现有方法中很少提及。
该研究发现两个重要现象:
1)难以检测的对象(如行人)的检测准确率不够好;
2)添加额外的噪声点后,现有方法的性能迅速下降。
为了缓解这些问题,该研究提出新方法 TANet,它主要包含三元注意力(Triple Attention,TA)模块和 Coarse-to-Fine Regression (CFR) 模块。
TA 模块联合考虑通道注意力、点注意力和体素注意力,从而增强目标的关键信息,同时抑制不稳定的点。
此外,新型堆叠 TA 模块还可以进一步利用多级特征注意力。
而 CFR 模块可在不过度消耗计算成本的情况下提升定位准确率。
在 KITTI 数据集验证集上的实验结果表明,在难度较大的噪声环境中(即在每个对象周围添加额外的随机噪声点),TANet 的性能远远超过当前最优方法。
此外,在 KITTI 基准数据集上执行 3D 目标检测任务后发现,TANet 仅使用点云作为输入,即在「行人」(Pedestrian)类别检测中取得 SOTA 的成绩。
其运行速度约为每秒 29 帧。
点云 3D 目标检测有大量现实应用场景,尤其是自动驾驶和增强现实。
一方面,点云提供可靠的几何结构信息和精确深度,那么如何高效利用这些信息就是一个重要问题。
另一方面,点云通常是无序、稀疏、不均匀分布的,这对于准确目标检测是一项巨大挑战。
近年来,3D 目标检测社区提出了多种基于点云的方法。
PointRCNN 直接基于原始点云运行,用 PointNet 提取特征,然后用两阶段检测网络估计最终结果。
VoxelNet、SECOND 和 PointPillars 将点云转换成规则的体素网格,然后应用一系列卷积操作进行 3D 目标检测。
尽管现有方法实现了不错的检测准确率,但在难度较高的情形下这些方法仍然无法获得令人满意的性能,尤其是对于难以检测的对象,如行人。
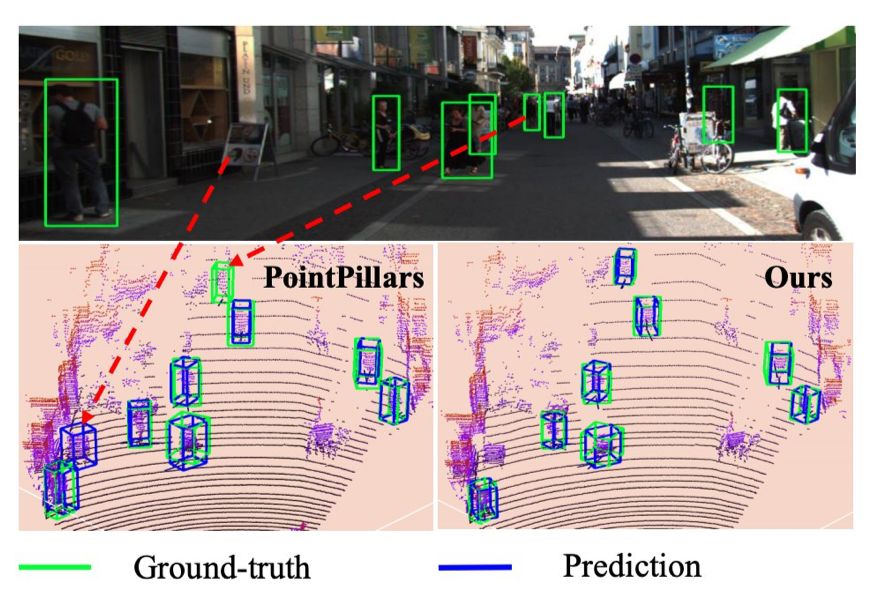
如下图 1 所示,PointPillars 漏掉了一个行人,还对一个对象的预测为假正例。
研究者从两个方面揭示了预测错误的本质原因:
1)行人的体积小于汽车,因此激光雷达扫描到的有效点较少。
2)行人频繁出现在大量场景中,因此多种多样的背景物体(如树、灌木丛、电线杆等)可能与行人很接近,这给准确识别行人带来极大难度。
因而,在复杂点云中执行目标检测仍然是一项极有难度的任务。
![]()
图 1:行人检测结果。第一行展示了对应的 2D 图像,第二行分别展示了 PointPillars 和 TANet 的 3D 检测结果。红色箭头标示出 PointPillars 漏掉和错误的检测对象。
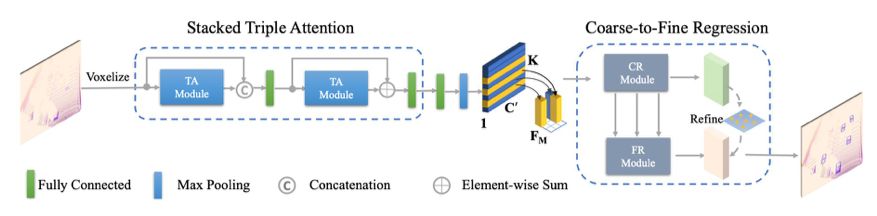
这篇论文提出了一种新型架构——Triple Attention Network (TANet),如图 2 所示。
它主要包含三元注意力(Triple Attention,TA)模块和 Coarse-to-Fine Regression (CFR) 模块。
该方法的直接动力是,在严重噪声环境下,一组包含有用信息的点可为后续的回归提供足够的线索。
为了捕捉到这类包含有用信息的线索,TA 模块增强判别点,并抑制不稳定的点。
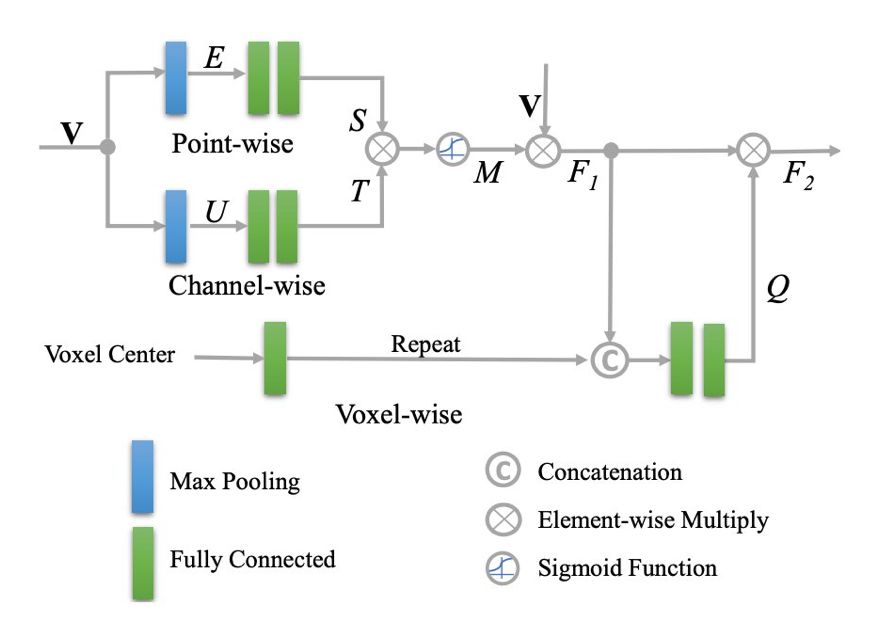
具体来说,TA 模块分别学习点注意力和通道注意力,然后利用元素相乘将它们结合起来。
此外,研究者还考虑体素注意力,即体素的全局注意力。
![]()
图 2:TANet 的整体流程图。首先,将点云均匀分割成包含一组体素的体素网格。然后用堆叠 TA 模块分别处理每个体素,获得更具判别性的表示。之后,用最大池化方法聚集每个体素内的点,从而为每个体素提取紧凑的特征表示。研究者根据体素在网格中的原始空间位置排列体素特征,从而得到体素网格的特征表示 C' × H × W。最后,使用 CFR 模块生成最终的 3D 边界框。
在噪声环境下,仅应用单个回归器模块(如一阶 RPN)做 3D 边界框定位的效果不尽如人意。
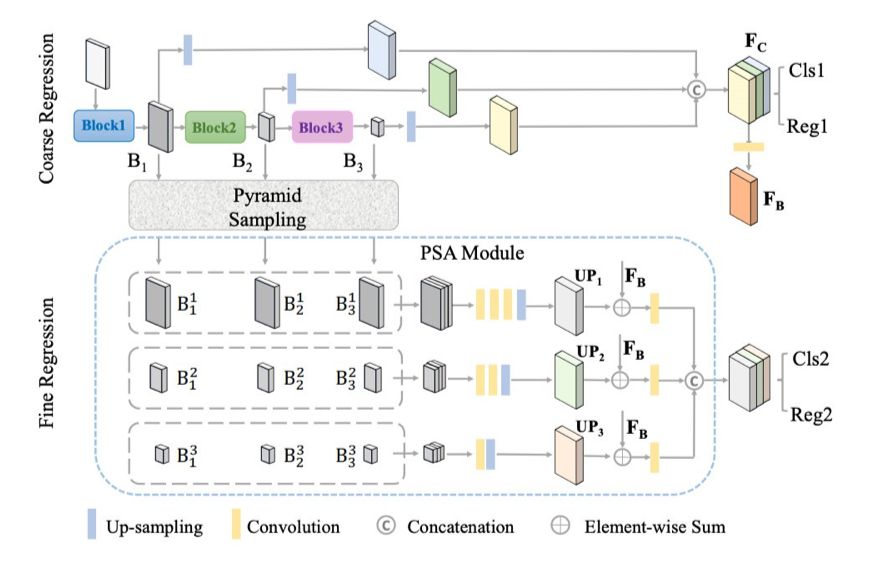
为了解决这一问题,该研究提出一种端到端可训练的 coarse-to-fine regression (CFR) 机制。
其中,粗糙步按照 (Zhou and Tuzel 2018; Lang et al. 2019) 的方法对对象进行粗略估计。
然后,利用新型 Pyramid Sampling Aggregation (PSA) 融合方法得到跨层特征图。
细化基于融合后的跨层特征图实现,从而得到更精细的估计结果。
TA 模块和 CFR 机制对于 3D 检测器的稳健性都很关键,而 3D 检测器的稳健性对自动驾驶真实场景非常重要。
由于 KITTI 数据集中并非所有数据都受噪声所扰,因此研究者在实验评估过程中,通过在每个对象周围添加随机噪声点来模拟噪声环境。
大量实验证明,TANet 方法在 KITTI 基准 Pedestrian 类别检测中取得了最优的检测结果,这进一步证明了 TANet 检测器的稳健性。
1. 提出新型 TA 模块,该模块联合考虑通道注意力、点注意力和体素注意力,并执行堆叠操作从而获得多级特征注意力,进而得到对象的判别表示;
2. 提出新型 coarse-to-fine regression 机制,基于粗糙回归结果,在包含有用信息的融合跨层特征图上执行细化回归(fine regression);
3. 该方法在难度较高的噪声环境中取得了不错的实验结果,在 KITTI 基准数据集上的量化比较结果表明,TANet 方法获得了当前最优性能,且其推断速度很快。
如图 2 所示,TANet 包含两个主要部分:
堆叠 TA 模块和 CFR 模块。
![]()
图 3:TA 模块架构图。
研究者利用粗糙回归(Coarse Regression,CR)模块和细化回归(Fine Regression,FR)模块执行 3D 边界框估计。
![]()
图 4:CFR 架构图。金字塔采样(Pyramid Sampling)表示一系列下采样和上采样操作,它们通过池化和转置卷积来实现。
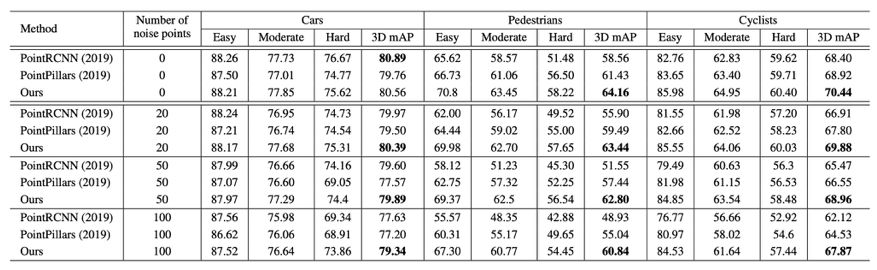
下表 1 展示了 TANet 与当前最优方法在噪声环境下的定量结果。
尽管 PointRCNN 检测 Cars 类别的 3D mAP 比 TANet 高出 0.43%,但在噪声环境下,TANet 方法展现出更强大的稳健性。
在添加 100 个噪声点的情况下,TANet 获得了 79.34% 的 3D mAP,比 PointRCNN 高出 1.7%。
对于 Pedestrians 类别,TANet 的性能分别比 PointPillars 和 PointRCNN 高出 5.8% 和 11.9%。
从中我们可以看出,TANet 方法对噪声具备强大的稳健性,尤其是对难以检测的样本,如 Pedestrians、hard Cyclists 和 hard Cars。
![]()
表 1:在 KITTI 验证集上,TANet 和 PointRCNN、PointPillars 对 Cars、Pedestrians 和 Cyclists 类别的 3D 目标检测性能对比情况。3D mAP 表示每个类别的平均准确率。
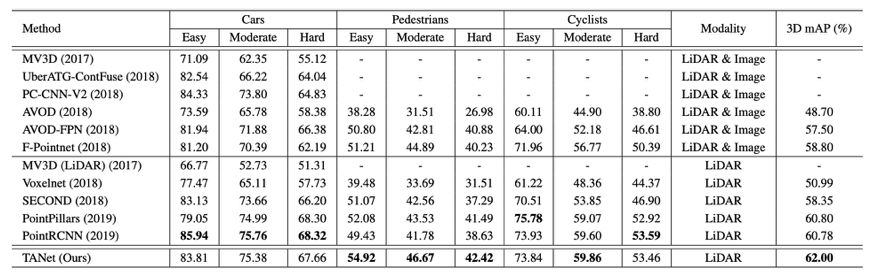
下表 2 展示了不同方法在 KITTI 官方测试数据集上的实验结果。
TANet 对三个类别的 3D mAP 是 62%,比当前最优方法 PointPillars 和 PointRCNN 分别高出 1.20% 和 1.22%。
尤其对于难以检测的对象(如行人),TANet 的性能比 PointPillars 和 PointRCNN 分别高出 2.30% 和 4.83%。
![]()
表 2:在 KITTI 测试数据集上,TANet 新方法和之前方法对 Cars、Pedestrians 和 Cyclists 类别的 3D 目标检测性能对比情况。3D mAP 表示模型对这三个类别的 3D 目标检测平均准确率。
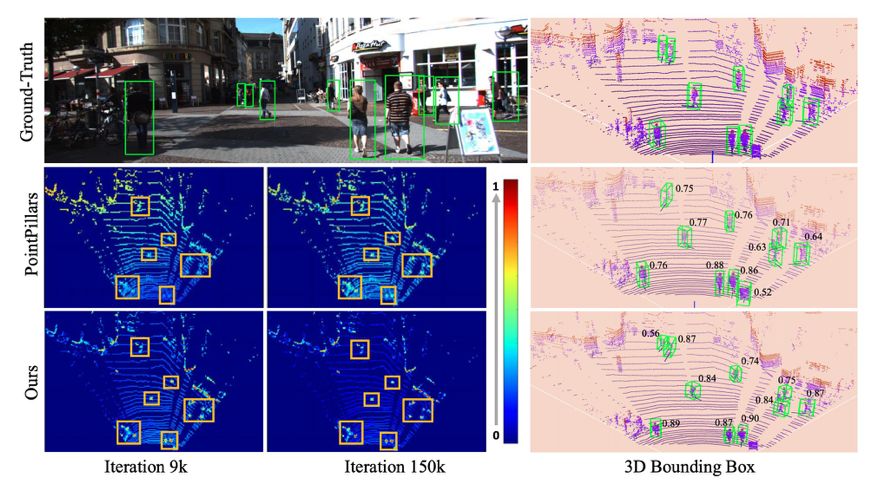
下图 5 展示了模型学得特征图和模型预测置信度得分特征的可视化图。
![]()
图 5:模型学得特征图和模型预测置信度得分的可视化图示。
![]()
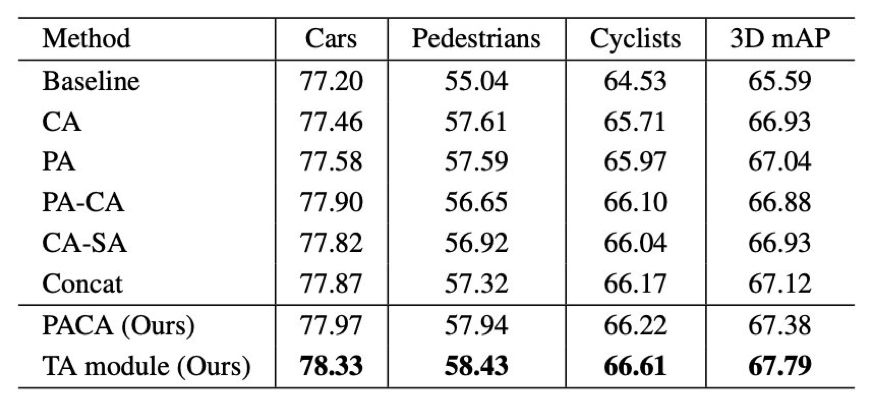
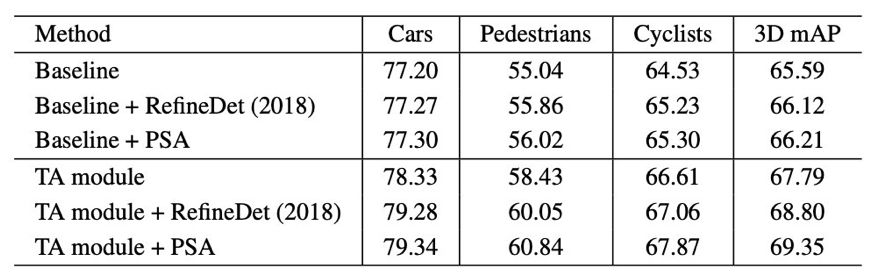
表 3:对通道注意力、点注意力和体素注意力及其不同组合的效果进行控制变量实验。所有实验都在不使用 FR 模块的前提下实施。
![]()
CVer 推荐阅读
等待YOLOv4的期间,它还在更新
周志华教授:如何做研究与写论文?
一文看尽9篇目标检测最新论文(MFPN/CR-NAS/Scale Match/Dense RepPoints等)
重磅!CVer-目标检测交流群已成立
扫码可添加CVer助手,可申请加入CVer大群和细分方向群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
![]()
▲长按加群
![]()
▲长按关注我们
麻烦给我一个在看!