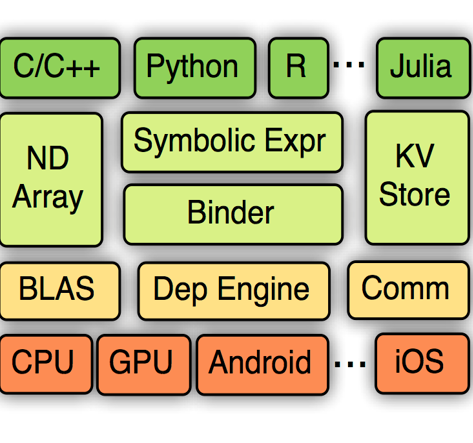
GluonNLP — 自然语言处理的深度学习工具包

最新模型的结果为何难以重现?去年项目的代码为何已经罢工?本该直截了当的基准模型为何如此难做?请看今天的走进科学之,自然语言处理那点事。
故事的主人公小 A 是个乐观开朗的炼丹师,正开始研究机器翻译。这天他看到时下最热门的一篇谷歌论文 “Attention Is All You Need” 介绍基于注意力机制的 Transformer 模型。小A上网搜了搜发现, Tensorflow 的 Tensor2Tensor 包里已经有了这篇论文的实现。 身 (she) 经 (shi) 百 (wei) 战 (shen) 的小 A,于是决定立刻就拿这个包跑一下,想在当天下午重现一下这个最新的黑科技。
很快,小 A 发现这份官方提供的包和参数跑不出论文里的结果。老 (tian) 道 (zhen) 的炼丹师小A心想,简单换个几组参数再跑跑看应该就行了吧?
然而三天过去了……他占满了实验室所有 GPU,跑了很多组参数,以至于被实验室师兄投诉,却依然没有重现出论文结果。小 A 十分抓狂,难以理解自己哪里做错了,愤怒地跑上 Tensor2Tensor 的 Github 写 issue 报告问题。不久,有几个其他用户在他的 issue 上回复说遇到了一样的问题,但是也没有解决方案。
半个月过去了……终于,项目维护者出现了,回复说会看一下这个问题,然后便杳无音信。

三个月过去了……只有小 A 还在无助地问,”请问有进展了吗”……

在亚马逊云服务 AWS 做了一段时间深度学习和自然语言处理之后,我发现其实身边不乏这样的男默女泪的故事。自然语言处理的模型重现之所以难,与数据处理和模型搭建中需要解决的茫茫多技术点有很大关系:从各种语言的文本文件编码解码 (encoding/decoding),读取,分词 (tokenization),词向量转化 (embedding),到输入给神经网络前的填充位 (padding),截长 (clipping),再到神经网络模型里处理变长输入数据和状态,一直到模型预测解码后的输出的 BLEU score 等等表现评估方法,每处都会有坑。如果工具不到位,每次做新模型开发都要经历各种大坑小坑的洗礼。
有一次和 MXNet 其他几位 NLP 小伙伴们偶然聊起这些坑,大家都顿时表达出强烈的共鸣。明知山有虎,偏向虎山行,我拉上几位码力强劲的小伙伴,约定要搞一个能帮助大家轻松在 Gluon 中重现实验结果和开发模型的自然语言处理的工具包。于是说干就干,在 Xingjian Shi (@sxjscience), Chenguang Wang (@cgraywang), Leonard Lausen (@leezu),Aston Zhang (@astonzhang),Shuai Zheng (@szhengac),和我(@szha)一阵猛烈的键盘敲击之后,便有了GluonNLP。
✘ 症状:自然语言处理论文难以重现。网上的重现代码质量没保证,维护者弃坑。
√ GluonNLP 处方:提供新的研究成果的重现。重现代码定期刷新,提供脚本,运行参数,log,保证不弃坑。
比不能重现结果更惨的,是曾经能重现。理论上代码虽然不会变质,但经验上大家都碰到过放坏了的老代码。其中很重要的原因之一是,底下的深度学习框架的接口会变。为了研究不同框架接口会变这一现象,我们使用了专家权威推荐的,十 (wan) 分 (quan) 有 (mei) 科学依据的统计量–“X API break”的搜索引擎结果条目数。
| X | 搜索结果数 |
|---|---|
| MXNet | ~17k |
| Tensorflow | ~81k |
| Keras | ~844k |
| Pytorch | ~23k |
| Caffe | ~110k |
虽然 MXNet 已经很努力了,但是仍然有 17k 之多。为了保证不坑用户,我们此次做包,特意提高警觉度。我们把重现脚本的质量把控整合进我们的自动测试,目标是保证只要有坑,我们先踩,确保代码不过期。
✘ 症状:重现代码对 API 更改敏感,易过保质期。
√ GluonNLP 处方:对重现代码关键部分进行自动测试,遇到框架 API 更改立刻修,保证不过期。
去年做自然语言处理服务的项目的时候,我的硬盘上曾经有过5份长得都差不多的却又各不相同束搜索 (beam search) 的代码。其中的原因是,在做不同应用的时候经常都会用到这同一个模块,而在用这同一个模块的时候却因为一开始没有仔细思考接口,导致要做一点点微调。我的这 5 份代码,区别都仅仅在如何进行单步的打分上,然而每次都因为赶时间,所以没有花精力去搞一份各个应用都能用的代码。
要得到一个可重用易拓展的接口,通常需要花很多精力去研究各种用例,并且常需要几个开发者热烈讨论。我们在 GluonNLP中,不仅会试着重现已有的例子,更会在研究这些例子的基础上做出更易于开发和拓展的接口和工具,为未来新的研究铺路。
✘ 症状:为了赶项目时间,来不及设计接口,只能拷贝旧项目的模块再做微调。
√ GluonNLP 处方:GluonNLP 小分队组团研究各个项目中的用例,做易用易拓展的接口。
最近做新项目,发现一个新趋势是好的资源不集中。大家都知道预训练的词向量和语言模型对很多应用有帮助,而哪个预训练模型更有用则是需要实验来验证的。在做这些验证时,开发者常常需要装许多不同的工具。比如 Google 的 Word2vec 需要装 gensim ,而 Salesforce 做的 AWD 语言模型是用 PyTorch 实现的,且暂不提供预训练模型, Facebook 的 Fasttext 则是自己开发的一个独立的包。为了能把这些资源凑齐在自己心爱的框架里使用,用户往往需要花费大量的精力在安装上。
对于一个社区来说,资源共享是最重要的功能之一。GluonNLP 中,我们不仅希望能为 NLP 爱好者提供一个社区,更希望能通过整合各个平台已有的资源来保证爱好者们能轻松获取这些资源,从而提高开发效率。
✘ 症状:NLP 资源分散,做一个项目要装十个包。
√ GluonNLP 处方:整合和共享有用的公开资源,提供一键下载预训练的词向量,语言模型,各个应用的公共的标杆数据集及预训练模型等。
给个代码看看
我们这里分别用 GluonNLP 载入 GloVe 词向量和预训练的语言模型中的词向量,用娃的两种写法(英文)来看哪个词向量在衡量相似性上更好。
import mxnet as mx
import gluonnlp as nlp
# 载入GloVe词向量
glove = nlp.embedding.create('glove', source='glove.6B.50d')
# 找到 'baby' 和 'infant' 的GloVe词向量
baby_glove, infant_glove = glove['baby'], glove['infant']
# 载入预训练AWD LSTM语言模型并获取其中词向量
lm_model, lm_vocab = nlp.model.get_model(
name='awd_lstm_lm_1150',
dataset_name='wikitext-2',
pretrained=True)
baby_idx, infant_idx = lm_vocab['baby', 'infant']
lm_embedding = lm_model.embedding[0]
# 找到 'baby' 和 'infant' 在语言模型中的词向量
baby_lm, infant_lm = lm_embedding(
mx.nd.array([baby_idx, infant_idx]))
# cos相似度
def cos_similarity(vec1, vec2):
return mx.nd.dot(vec1, vec2) / (vec1.norm() * vec2.norm())
print(cos_similarity(baby_glove, infant_glove)) # 0.74056691
print(cos_similarity(baby_lm, infant_lm)) # 0.3729561项目在哪里
最新的 GluonNLP 发布在 http://gluon-nlp.mxnet.io。
我们会在接下来的版本里不断加入新的特性和模型。如果对哪些模型特别感兴趣,请戳文末链接给我们留言。
下一步
扫描或者长按下面QR码来关注我们:

公众号里回复下面关键词获取信息:
课程 -- 《动手学深度学习》课程视频汇总
论坛 -- 深度学习论坛地址
资源 -- 所有中文资源汇总
请点击下面链接来参与公开讨论: