用深度学习做个艺术画家 ——模仿实现PRISMA

本书节选自图书《机器学习之路——Caffe、Keras、scikit-learn实战》
文末评论赠送本书,欢迎留言!
丰富的实战案例讲解,介绍如何将机器学习技术运用到股票量化交易、图片渲染、图片识别等领域。
本文将探索深度学习落地到图像处理领域的方案,适合有一定深度学习实践经验的读者进阶阅读。
使用深度学习作画的起源是有三个德国研究员想把计算机调教成梵高,他们研发了一种算法,模拟人类视觉的处理方式。具体是通过训练多层卷积神经网络,让计算机识别,并学会梵高的“风格”,然后将任何一张普通的照片变成梵高的《星空》。

图9-1 deep art
后来他们开创了Deep Art公司,在Deep Art公司,负责绘画的程序员是卷积神经网络(CNN)。输入一个艺术作品,比如梵高的《星空》,卷积神经网络就会自动提取出这幅画作的“风格特征”,并转换成风格模板保存下来。也就是说,卷积神经网络可以被看作是一个机器艺术家。
Prisma第一次将这项艺术作画技术成功商业化。Prisma诞生于俄罗斯,是一个仅有4个年轻人历时一个半月开发出的图片处理应用。他们充分考虑了智能手机覆盖率的飞速增长,并且细致研究了用户行为。Prisma接入的是以亿数量级的市场,俄国总统梅德韦杰夫也成为了Prisma的用户,他在Instgram上晒出了一张Prisma作品,迅速获得8.7万个赞。
Google的Deep Dream也是一个会画画的计算机。它能够自动识别图像,筛选其中一些部分,进行夸张,以创造出一种迷幻效果。Deep Dream完全开源,在几个主流的深度学习库如Keras、Caffe的官方example中,都有Deep Dream的实现Demo。
本章我们将探索实现类似Prisma的效果。
备注:
本章完整项目地址:https://github.com/bbfamily/prisma_abu
本项目演示视频:m.v.qq.com/play.html?&vid=v0397sv1fab,也可以在公众号abu_quant中直接观看视频。
机器学习初探艺术作画
好的艺术家模仿皮毛,伟大的艺术家窃取灵魂。 ——毕加索
本节介绍机器学习作画的简单原理,并展示输出效果。
艺术作画概念基础
第6章介绍了CNN如何提取图片中的图形特征,进而识别图片实物。现在,假设这里已经训练好了一个“识别毕加索绘制的猫”的深层卷积神经网络模型,如果把一张完全不同的照片输入模型,比如一张狗的照片,会发生什么呢?
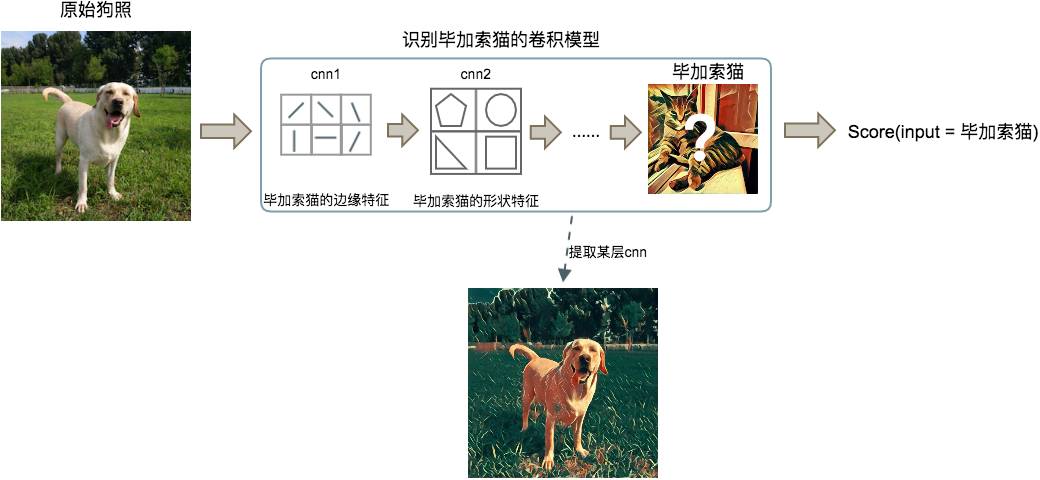
图9-2 CNN反馈修改输入图片
模型会给你反馈一个概率分数,表示它相信这是一张“毕加索猫”照片的程度。这中间经历了很多CNN层,每层CNN都在狗狗照片上寻找输入样本是毕加索猫的图形特征证据,越底层的神经元分析的特征越具体,越高层越抽象。当然,最后模型会给出很低的分数。
上面在狗照上识别毕加索猫的过程中,如果让模型能够修改输入的样本又会怎样呢?
给模型网络中加一个反馈回路,让每一层网络可以朝着使最后分数变大的方向上修改狗狗照片。每次迭代网络中的每层都会在狗照上增加一些毕加索猫的特征痕迹,可以迭代很多次,让狗狗照片中加入越来越多的毕加索猫的实物特征。
这就是使用卷积神经网络艺术作画的概念基础,让艺术风格模型的CNN按图形特征修改输入图片,叠加艺术效果。大致的实现思路如下:
输入特征图像,训练风格模型,让计算机学会艺术风格。
输入待处理图,风格模型引导修改输入图片,生成新的图像,输出“艺术画”。
接下来将模拟Prisma的效果,实现艺术作画。
直观感受一下机器艺术家
这里我们展示一下机器艺术作画的效果,原图如图9-3所示。

图9-3 原图
下面我们用这几个浅层神经元对原图风格化的效果进行展示(备注:代码实现见本书Git库),如图9-4所示。

图9-4 机器风格作画效果展示
有没有感觉到特征的识别由浅入深的一步一步增强,也就是从edge,到shape,再到复杂的shape循序渐进的过程,这里主要是卷基层把每层的特质放大进行夸张凸显。
图9-5展示了更多其他风格作画。

图9-5 机器艺术作画效果图
一个有意思的实验
如果用Prisma做出一个图像,然后将它作为特征图像去引导新的图像生成会有什么效果呢?
guide = np.float32(
tp.resize_img(PIL.Image.open('../prisma_gd/106480401.jpg')))
PrismaHelper.show_array_ipython(guide)
输出:

图9-6 引导图
如图9-7所示,有些特征还是挖掘到了。
PrismaHelper.show_array_ipython(tp.fit_guide_img(s_file, gd_path, resize=True, size=640, iter_n=1500))
输出:

图9-7 效果图
机器艺术作画的愿景
当机器能够根据图像的平面特征作画时,很多灵感也随之而来。比如我们可以从引导图中发现图像特征,从多个特征中寻找出存在的对象,并将这个特征融合到另一个图像中做特征融合。如果能够将特征识别融合做到极致,就可以完成如下假想场景。
抬起头看到天边一朵云,看起来好像我家拉布拉多犬呢,是不是可以替换一下呢?
用手机拍下这朵云,将狗狗的照片和云的照片发到云端进行特征识别融合。
云端将融合好后的图像发回给用户。

图9-8 特征融合的愿景图
回顾
本节我们介绍了深度学习艺术作画的原理,并展示了直观的效果,在使用Deep Dream等开源项目实现上述效果时,速度非常缓慢,所以从9.2节开始我们将使用自己的方式实现快速Prisma,实现秒级作画。
实现秒级艺术作画
天下武功,唯快不破。互联网竞争的利器就是快。——雷军
和Deep Art相比,Prisma的优势在于大大缩短了图像处理的时间,每张照片在Prisma系统内的处理时间控制在秒级别。而Deep Art更像是精工细作的手艺人,算法跑得虽然慢一些,但在细节表现力上更胜一筹。
在本书写作之前,笔者参考了几个艺术作画开源项目,都达不到真实Prisma的速度要求,本节将要使用的方式都是笔者原创的方法。首先笔者并不知道Prisma到底使用了什么方式使图像效果又好,速度又快,但是大概猜测的方向包括这几种可能:
大量的多CPU、GPU的机器(绝对不现实,成本根本无法控制)。
未知的算法优化、网络框架优化(就算是这样,这也是我们没有能力突破的黑盒)。
拥有很大的图像数据库,可以很快地检索出与输入图像相似度最高的图像,之后相似特征提取、权重渲染。
针对图像的部分区域使用机器学习算法将特征层放大,配合一些图像处理技术,提升渲染速度。
第三种方式是说在拥有海量图片数据的前提下,作一个分类模型。对于一个输入图片,模型先分类出这是哪种类型,根据类型选择固定的特征提取方式进行渲染。而第四种方式是使用一些图片预处理技术减少机器学习算法的工作量。
由于我们没有足够的图片资源,而且第三点实现方式的速度瓶颈会在检索和相似度计算上,所以下面讲的内容是针对第四点展开试验的,可以在速度及渲染效果上都达到比较满意的效果。而唯一的缺陷就在适用性上,实际使用时需要调整一下参数,所以在实际使用中可以结合上述第三种方式,针对一定数量的样本作为训练集x,对应的y是效果参数,对输入进行分类,再配合使用相似度等提高自动适配的能力。
主要实现思路分解讲解
下面还是使用abu1这张图片作为输入:
from PrismaCaffe import CaffePrismaClassimport PrismaHelperimport numpy as npimport PIL.Image
abu1_file = '../sample/abu1.jpg'cp = CaffePrismaClass(dog_mode=False)
PrismaHelper.show_array_ipython(
np.float32(cp.resize_img(PIL.Image.open(abu1_file))))
输出如图9.9所示。

图9-9 原始图
下一步,挑一张引导特征图像:
gd_path = '../prisma_gd/tooopen_sy_127260228921.jpg'guide_img = np.float32(
cp.resize_img(PIL.Image.open(gd_path), base_width=480,
keep_size=False))
PrismaHelper.show_array_ipython(guide_img)
输出:

图9-10 引导图
如下所示,首先将图像转化为单通道,用otsu寻找mask, 通过mask确定border和edges。
说明:otsu(大津算法, 自适应阈值)
关于skimage otsu等使用请参考:http://scikit-image.org/
关于scipy ndimage等使用请参考:https://docs.scipy.org
输入:
r_img = cp.resize_img(PIL.Image.open(abu1_file), base_width=480,
keep_size=False)
# rgb转化为单通道灰阶图像
l_img = np.float32(r_img.convert('L'))
# filters.threshold_otsu需要(-1, 1)之间
l_img = np.float32(l_img / 255)
r_img = np.float32(r_img)
# 找出大于otsu的阀值作为mask,需找border
mask = l_img > filters.threshold_otsu(l_img)
# 不是适用所有图像都要clear border,比如图像主题大部分需要保留时就不需要
clean_border = segmentation.clear_border(mask).astype(np.int)
coins_edges = segmentation.mark_boundaries(l_img, clean_border)
# 将值再次转换到0-255
clean_border_img = np.float32(clean_border * 255)
clean_border_img = np.uint8(np.clip(clean_border_img, 0, 255))
PrismaHelper.show_array_ipython(clean_border_img)
输出:

图9-11 单通道图
目标就是只想摘取狗狗的图像,其他的都认为是噪音,可以使用ndimage.binary _opening。达到效果了吗,试试看:
clean_border_img = ndimage.binary_opening(
np.float32(clean_border_img / 255),
structure=np.ones((5, 5))).astype(np.int)
clean_border_img = ndimage.binary_opening(clean_border_img).astype(
np.int)
PrismaHelper.show_array_ipython(clean_border_img * 255)
输出:

效果其实不太好,ndimage.binary_opening效果与CNN中的最小池化层相似,目的就是去掉图中的小物体,下面通过自定义简单卷积核来过滤,实现我们的需求。
代码如下:
# 最小的卷积核目的是保留大体图像结构
n = 5
small_window = np.ones((n, n))
small_window /= np.sum(small_window)
clean_border_small = convolve2d(clean_border_img, small_window,
mode="same", boundary="fill")
# 中号的卷积核是为了保留图像的内嵌部分,这里的作用就是狗狗的黑鼻子和嘴那部分
n = 25
median_window = np.ones((n, n))
median_window /= np.sum(median_window)
clean_border_convd_median = \
convolve2d(clean_border_img, median_window, mode="same",
boundary="fill")
# 最大号的卷积核,只是为了去除散落的边缘,很多时候没有必要,影响速度和效果
n = 180
big_window = np.ones((n, n))
big_window /= np.sum(big_window)
clean_border_convd_big = convolve2d(clean_border_img, big_window,
mode="same", boundary="fill")
l_imgs = []
for d in range(3):
# 分别对三个通道进行滤波
rd_img = r_img[:, :, d]
gd_img = guide_img[:, :, d]
# 符合保留条件的使用原始图像,否则使用特征图像
d_img = np.where(np.logical_or(
clean_border_convd_median > 5 * clean_border_convd_big.mean(),
np.logical_and(clean_border_small > 0, clean_border_convd_big \
> 2 * clean_border_convd_big.mean())),
rd_img, gd_img)
l_imgs.append(d_img)
img_cvt = np.stack(l_imgs, axis=2).astype("uint8")
# 对转换出的图像进行一次简单浅层特征放大
d_img = cp.fit_img(nbk='conv2/3x3_reduce', iter_n=10, img_np=img_cvt)
PrismaHelper.show_array_ipython(np.float32(d_img))
输出:

图9-13 最后效果图
代码并不多,主要思路如下:
通过filters.threshold_otsu找出图像的mask。
segmentation.clear_border(mask)抽取图像border、edges。
使用三个卷积核对图像进行滤波处理,这里的三个卷积核的分工请看上面的代码注释。这里的滤波是就是引导特征和原始图像的权重分配。
卷积的意义简单理解就是加权叠加,针对输入的单位相应得到输出。为什么要用卷积呢?工程上理解其实就是为了效率。如果上面的代码从目的出发,知道要滤除什么样的像素点,保留什么样的像素点,将这些编程为计算操作;然后使用for循环针对每一个像素点,在一定范围内(卷积核大小)执行计算操作, 最后使用for循环一步一步前进,其实也能得出结果,但是运算的时间复杂度将大出几个数量级。
1.使用图像特征作为mask
上面的方法是使用otsu寻找图像边缘作为mask的依据,下面使用skimage中的corner_peaks抽取图像特征作为mask。
def show_features(gd_file):
r_img = cp.resize_img(PIL.Image.open(gd_file), base_width=480,
keep_size=False)
l_img = np.float32(r_img.convert('L'))
ll_img = np.float32(l_img / 255)
coords = corner_peaks(corner_harris(ll_img), min_distance=5)
coords_subpix = corner_subpix(ll_img, coords, window_size=25)
plt.figure(figsize=(8, 8))
plt.imshow(r_img, interpolation='nearest')
plt.plot(coords_subpix[:, 1], coords_subpix[:, 0], '+r',
markersize=15, mew=5)
plt.plot(coords[:, 1], coords[:, 0], '.b', markersize=7)
plt.axis('off')
plt.show()
def find_features(gd_file=None, r_img=None, l_img=None, loop_factor=1,
show=False):
if gd_file is not None:
r_img = cp.resize_img(PIL.Image.open(gd_file), base_width=480,
keep_size=False)
l_img = np.float32(r_img.convert('L'))
l_img = np.float32(l_img / 255)
coords = corner_peaks(corner_harris(l_img), min_distance=5)
coords_subpix = corner_subpix(l_img, coords, window_size=25)
r_img_copy = np.zeros_like(l_img)
rd_img = np.float32(r_img)
r_img_copy[coords[:, 0], coords[:, 1]] = 1
f_loop = int(rd_img.shape[1] / 10 * loop_factor)
for _ in np.arange(0, f_loop):
"""
放大特征点,使用loop_factor来控制特征放大倍数
"""
r_img_copy = ndimage.binary_dilation(r_img_copy).astype(
r_img_copy.dtype)
r_img_copy_ret = r_img_copy * 255
if show:
r_img_copy_d = [rd_img[:, :, d] * r_img_copy for d in
range(3)]
r_img_copy = np.stack(r_img_copy_d, axis=2)
PrismaHelper.show_array_ipython(r_img_copy)
return r_img_copy_ret
显示抽取出的图像特征点:
show_features('../prisma_gd/71758PICxSa_1024.jpg')
输出如图9-14所示。

图9-14 原始图
find_features使用ndimage.binary_dilation来放大特征点,使用loop_factor来控制特征放大倍数,目的是结合引导特征做渲染时提升原始图像的特征权重, find_features提取后的结果如下所示。
_ = find_features('../prisma_gd/71758PICxSa_1024.jpg', loop_factor=1,
show=True)
输出如图9-15所示。

图9-15 抽取效果图
下面用IPython Notebook的可交互形式更直观地看一下特征的抽取与放大。
from ipywidgets import interact
def find_features_interact(gd_file, loop_factor):
r_img = cp.resize_img(PIL.Image.open(gd_file), base_width=480,
keep_size=False)
l_img = np.float32(r_img.convert('L'))
l_img = np.float32(l_img / 255)
coords = corner_peaks(corner_harris(l_img), min_distance=5)
coords_subpix = corner_subpix(l_img, coords, window_size=25)
r_img_copy = np.zeros_like(l_img)
rd_img = np.float32(r_img)
r_img_copy[coords[:, 0], coords[:, 1]] = 1
f_loop = int(rd_img.shape[1] / 10 * loop_factor)
for _ in np.arange(0, f_loop):
"""
放大特征点,使用loop_factor来控制特征放大倍数
"""
r_img_copy = ndimage.binary_dilation(r_img_copy).astype(
r_img_copy.dtype)
r_img_copy_ret = r_img_copy * 255
r_img_copy_d = [rd_img[:, :, d] * r_img_copy for d in range(3)]
r_img_copy = np.stack(r_img_copy_d, axis=2)
PrismaHelper.show_array_ipython(r_img_copy)
gd_file = ('../prisma_gd/71758PICxSa_1024.jpg', '../prisma_gd/st.jpg',
'../prisma_gd/g1.jpg', '../prisma_gd/31K58PICSuH.jpg')
loop_factor = (0, 2, 0.1)
interact(find_features_interact, gd_file=gd_file,
loop_factor=loop_factor)
输出如图9-16所示。

图9-16 抽取效果图
工程代码封装结构及使用示例
将上面的代码再次重构到文件PrismaWorker中, 代码详情请查阅PrismaWorker.py。
from PrismaWorker import PrismaWorkerClass
pw = PrismaWorkerClass()
使用两个GTA5的图片,融合摩托车大哥到大部队中,作为图9-23所示的原始图片的引导特征图:
pw.cp.resize_img(PIL.Image.open('../prisma_gd/gta2.jpg'),
base_width=480, keep_size=False)
输出如图9-23所示。

图9-23 原始图片
注意,partial(do_otsu, dd=False)中的dd参数代表otsu后是取内部还是取反向的外部,如下面的黑白mask图,dd=False可以取到骑手,否则将取到外部背景。
_ = pw.mix_mask_with_convd(partial(pw.do_otsu, dd=False),
'../sample/gta4.jpg',
'../prisma_gd/gta2.jpg',
'conv2/3x3_reduce',
enhance='Sharpness', n2=88, n3=1,
convd_median_factor=1.5,
convd_big_factor=0.0, show=True)
输出如图9-24所示。

效果还算不错,除了左下脚两个标准的重叠。
接下来使用批量处理引导图像,预处理、特征放大层等参数排列组合使用PrismaMaster,详情请查询代码PrismaMaster.py。如下代码所示,可以生成所有参数排列组合的输出结果。
import PrismaMaster
cb = False
n1 = 5
n2 = 38
n3 = 1
convd_median_factor = 0.6
convd_big_factor = 0.0
loop_factor = 1.0
std_factor = 0.88
nbk_list = filter(lambda nbk: nbk[-8:-1] <> '_split_',
cp.net.blobs.keys()[1:-2])[:10]
org_file_list = ['../sample/bz1.jpg']
gd_file_list = [None, '../cx/cx3.jpg', '../cx/cx6.jpg',
'../cx/cx7.jpg', '../cx/cx10.jpg']
enhance_list = [None, 'Sharpness', 'Contrast']
rb_rate_list = [0.85, 1.0]
save_dir = '../out/2016_11_24'
PrismaMaster.product_prisma(org_file_list, gd_file_list, nbk_list,
enhance_list, rb_rate_list, 'otsu_func',
n1, n2, n3, std_factor, loop_factor,
convd_median_factor,
convd_median_factor, cb, save_dir)
接下来再做一个GUI的可视化操作界面PrismaController, 使用了traitsui库,详情请查看PrismaController.py。
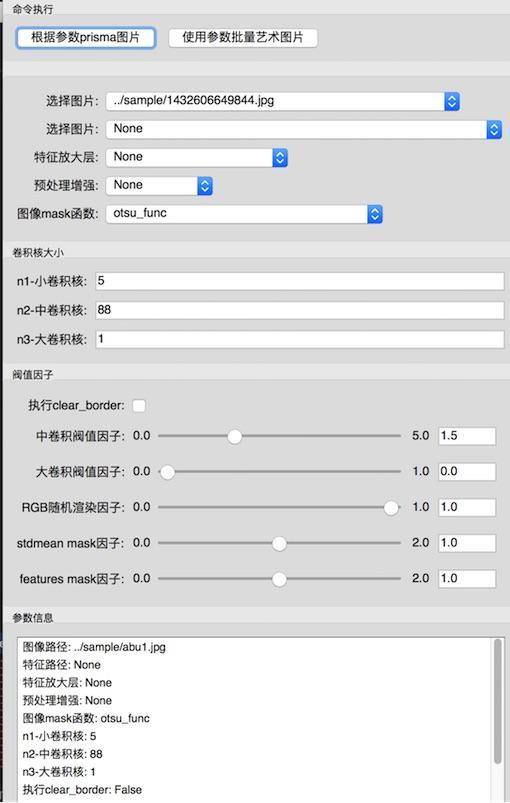
图9-25 GUI控制界面
基于这样一个方便微调的GUI下可以很方便地对图像进行微调,做出很多酷炫的图像,比如图9-26所示的做的两张基于GTA风格的图像。

图9-26 GTA风格效果图
图9-26这张犀利哥和GTA5合体的原图素材如图9-27所示。

图9-27 原始图片
如果你不知道什么样效果最好或者想要所有可能的效果图,那么你可以看到GUI的界面上还有个按钮“使用参数批量艺术图片”,它的作用是使用刚刚调整好的n1, n2, dd等参数作为固定参数,将引导特征图、放大层特征、预处理增强等作为所有可能的排列组合,通过一键生成成百上千张的风格图像,代码详情请查看PrismaController.py。
回顾和后记
本节所讲的这种实现Prisma的方式,不代表任何真实情况,只是一种可能的技术实现思路,并且在这种思路下还需要做很多的工作比如,针对适用性的问题也许要保存大量字典,字典的key可以是图像矩阵特征,value对应着处理参数,然后针对输入的图像进行分类,或者根据特征相似度匹配来认定应该使用哪些参数等种种复杂问题需要处理。
本节的代码并没有过多关心运行效率等问题,比如针对图像保存读取scipy.misc比用PIL的实现方式效率要高得多,但为了代码可读性,本书选择使用PIL。
总的来说,本章只想告诉你,如果希望机器学习技术无缝地落地到某个领域时,需要的不仅仅是深度学习模型技术,还有灵活的思路以及变通的智慧。
《机器学习之路——Caffe、Keras、scikit-learn实战》订购链接(点击阅读原文订购):https://item.jd.com/12138075.html

又赠书啦!!!
留言告诉头条宝宝你想获得这本书的理由,点赞前5名就可获得本书。
开奖截止时间9月28日(本周四)中午12点!



