应用实践 | 电商应用——一种基于强化学习的特定规则学习模型
本文转载自公众号:浙大KG。
作者:汪寒,浙江大学硕士,主要研究方向为知识图谱和自然语言处理。
应用场景
在电商实际应用中,每个商品都会被挂载到若干个场景,以图结构中的节点形式存在。商品由结构化信息表示,以键值对(Property:Value)形式(后称PV)存在。场景(LifeStyle)的价值则在于打通商品实体之间的联通,提供跨域的实体搭配,因此新的商品必须要通过规则库中的规则挂载到特定的场景才能进入电商的运营体系。商品场景的样例如下图所示。
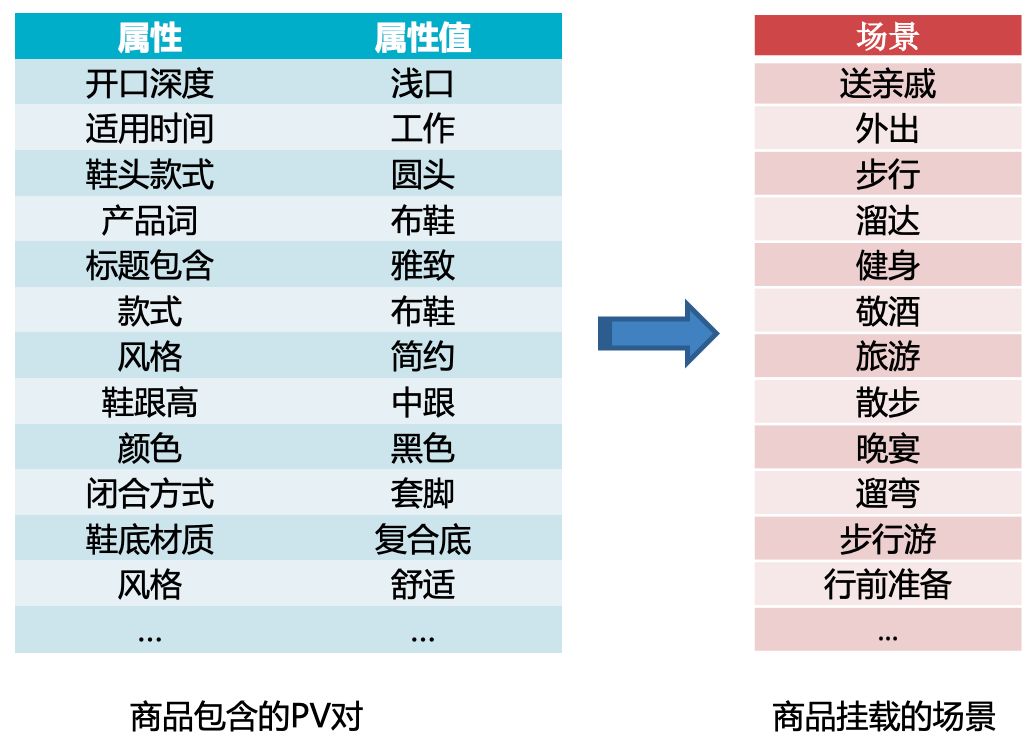
图1 商品场景样例

Motivation
目前业界常用的规则学习baseline是关联规则挖掘,用于发现数据集中项与项之间的关系,通过挖掘数据集中存在的频繁项集来生成规则。这种方法适合数据项之间没有差异的数据集,比如著名的购物篮分析应用中,不同的商品都可以看作是同种item。而在实际应用中常常需要挖掘不同类型数据项之间的规则,数据集中的元素项之间存在差异,不能简单地将所有数据项都看作同种item,分析商品场景挂载数据可以看出,商品的 PV 对与场景之间存在差异,若将其视为同种数据项,用通用的规则挖掘算法学习,就舍弃了商品 PV 对与场景之间的挂载关系信息以及差异。
且关联规则挖掘是通用的规则生成算法,在频繁项挖掘阶段需要耗费大量时间挖掘无关的频繁项,无法针对特定的规则进行优化,所以关联规则挖掘算法无论是效率还是产出结果的指标都偏低。因此,针对商品场景挂载数据生成规则,需要用到task-specific 算法,算法需要考虑到商品 PV 对与场景之间的差异以及挂载关系信息,且生成的规则应满足 Body 部分为 PV 对,Head 部分为单个场景的形式。
算法描述
首先分析数据,商品由20-50个PV对组成,每个商品会挂载到若干个场景,而输出的规则的body部分为1-5个PV对,head部分为单个场景。因此可以认为,对一个商品的PV对赋予不同的权重就可以让这个商品挂载到不同的场景,输出那些权重超过阈值的PV对作为body部分就可以得到一条规则,从而就可以得到一个算法,就是用一个神经网络来对PV对赋予权重,在训练完毕后将高权重的PV输出作为规则的body部分。
因此,首先要解决的问题是如何设计一个神经网络模型来为PV对赋予权重,PV对的权重是离散值0或1,0表示舍弃当前PV对,1表示选择当前PV对作为body部分。把商品包含的PV对看作序列,赋予权重的过程就是一个经典的序列决策过程,而这个序列决策过程是没有标注数据的,所以无法用监督学习训练,但整个序列是有标注的,即权重赋予后的PV对序列能否挂载到当前场景。因此,可以把整个问题建模成一个强化学习问题,训练一个智能体来完成权重赋予的过程。
然后,要解决的第二个问题是如何为这个智能体返回reward,即如何判断智能体输出的PV对子序列可以让商品挂载到特定场景,且这个子序列的长度不超过5。判断挂载是否正确可以看作是一个分类问题,预训练一个FastText网络作为分类器,输入为PV对序列,输出为PV对序列所对应的类(即场景),来判断当前PV子序列能否分类到对应场景。同时,在reward function中加入子序列长度项,让智能体尽可能选择较短的子序列。
模型
模型包括两个部分,一个用于对PV输出action的智能体Agent和一个用于返回reward的FastText模型,结构图如图2所示。Agent由三个模块组成:Input Module,Memory Module,Action Module。Input Module包括Property embedding,Value embedding以及LifeStyle Embedding,Property embedding和Value embedding拼接起来当作当前PV的embedding,作为Memory Module的输入;Memory Module则由一个双向LSTM组成,利用LSTM网络的记忆功能,让每个时间步输出的隐状态都能包含上下文的信息;Action Module则包含一个单向LSTM和一个全连接层,网络输入包含Memory Module在当前时间步的输出,Agent在上一次输出的action以及当前商品所对应的LifeStyle embedding。
在Agent对所有PV做完决策之后,将action输出为1的PV作为FastText的输入,FastText会输出当前输入的分类结果(也就是场景挂载),若分类正确则返回一个reward给Agent更新参数。
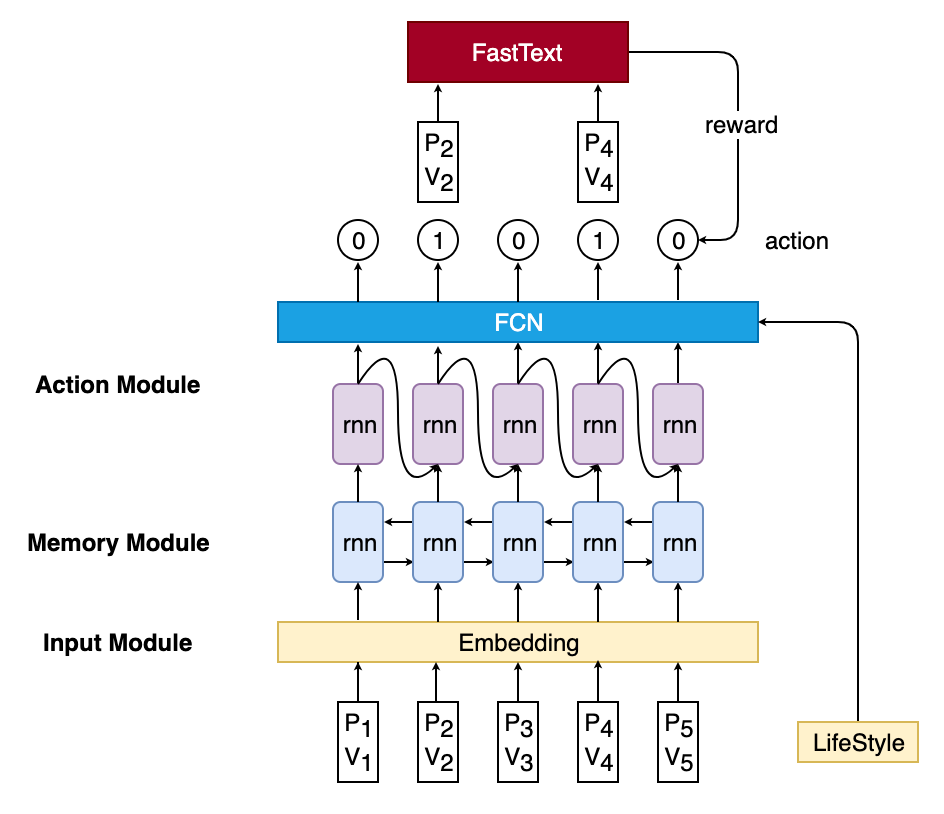
图2 模型结构图
模型训练
首先需要预训练一个FastText模型来为Agent返回reward。所以要先把商品挂载场景构造成一个分类任务,而在前面已经提到,一个商品可能会挂载到多个场景,对应到文本分类任务,就是一个样本会有多个标签,所以这里就把挂载数据构造成了一个多标签分类任务,用的目标函数也是文本分类任务里常使用的交叉熵损失函数,具体来说,单个样本的损失函数为:
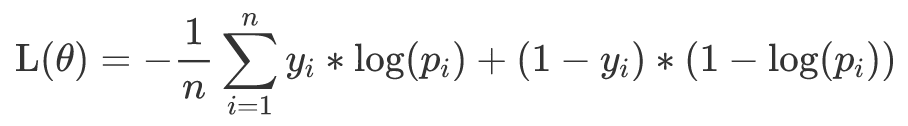
这里n表示标签的个数,y_i 表示样本是否属于当前类,p_i表示当前label对应的概率值,由sigmoid计算后得到。
而智能体的参数更新方式是policy gradient,在监督学习中,本文通常用交叉熵作为简化版的KL散度来衡量两个分布的差异,单个样本的交叉熵损失函数如下:
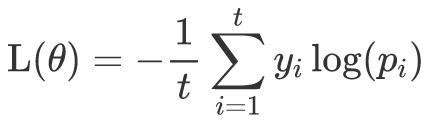
这里t表示样本的长度,y_i表示当前label,p_i表示当前label对应的概率值,由softmax计算后得到。
而强化学习则是没有label的,用当前action所得到的reward来代替,单个样本的损失函数如下
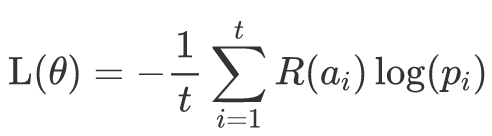
这里a_i表示当前时间步Agent输出的action,这个时候损失函数的作用就不是衡量两个分布的差异,而是最大化得到正reward的动作的概率。
实验
实验所用商品挂载数据集来自某电商网站的一个类目,在实验开始前先对实验数据做了一些必要的预处理实验数据的预处理包括:
1. 对标题进行分词,去掉停用词,无关的标点符号以及单个字。
2. 对包含多项的属性值进行切分,切分成k个部分就形成k个PV。
3. 去掉了一些没有信息量的属性项及其对应的属性值。
4. 增加了属性项:拥有属性,对应属性值为该商品拥有的属性项。
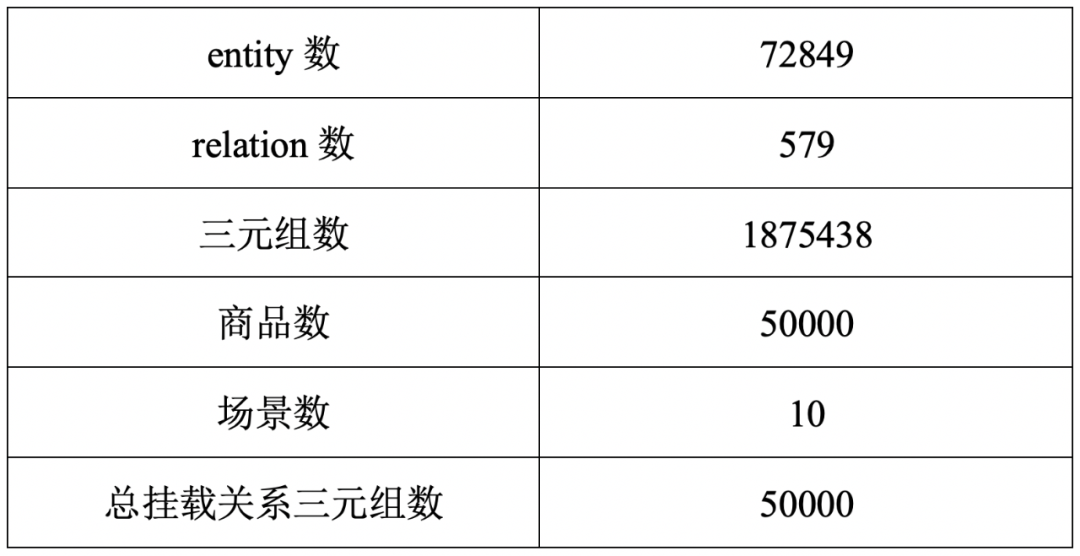
预处理结束后的数据集信息如表1所示
在规则输出阶段,智能体不再是从动作空间中按概率采样一个动作,而是直接选择概率最大的动作,得到所有预测正确的PV序列后,计算每条raw规则的HC和Conf,将满足要求的作为备选规则。最后生成的备选规则的body平均长度仅为2.12,这十分符合规则的要求,模型输出的规则样例如表2所示
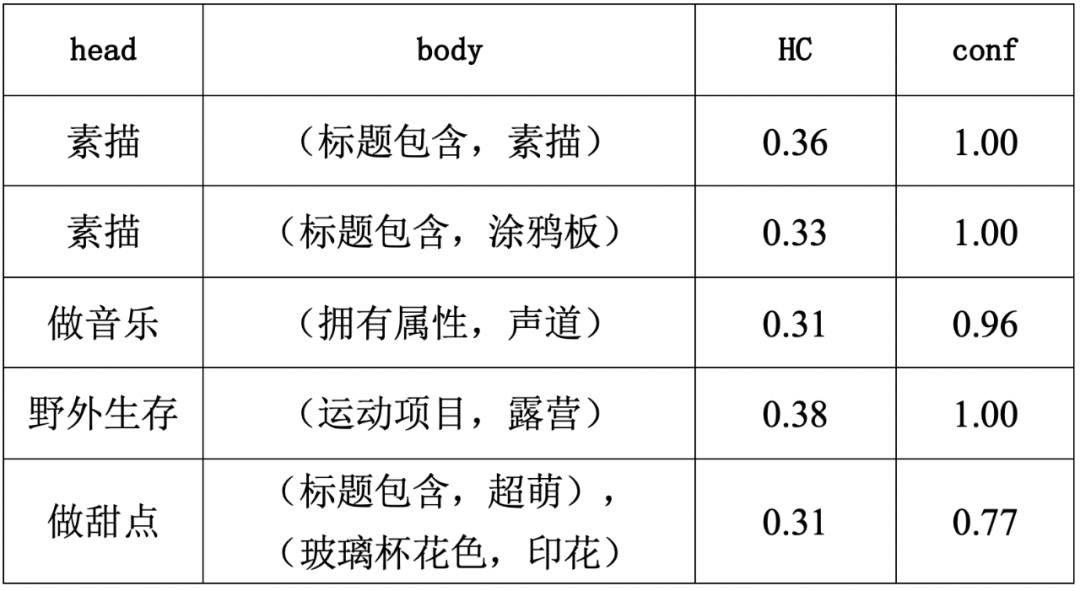
从样例中可以看出,智能体确实可以找到一到两个与某场景关联度极高的PV,这证明了reward function中对输出PV序列长度的惩罚的有效性,且规则从直观上看就很具有可行性,说明本模型确实找到了商品PV与场景之间存在的模式,并以规则的形式输出。最终模型生成了845条备选规则。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。




