水下目标检测算法赛解决方案分享 | 2020年全国水下机器人(湛江)大赛 -
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

我们团队在此分享下在 “2020年全国水下机器人(湛江)大赛 - 水下目标检测算法赛” 这一比赛中的实验过程及心得体会。不足之处,还望批评指正。

-
李智敏:华中科技大学 研一 -
罗文斌:电子科技大学 研一 -
艾宏峰:曼彻斯特大学 应届研究生 *特别感谢 南京会否网络科技有限公司提供硬件上的支持

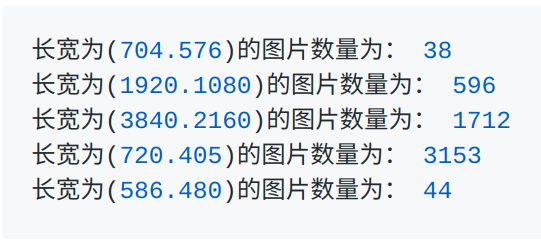
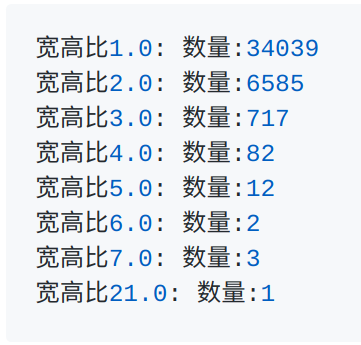
-
训练和测试多尺度:增强模型鲁棒性,同时小图被放大后能利于被模型捕捉到。 -
Soft NMS:对重叠目标的检测更加友好。 -
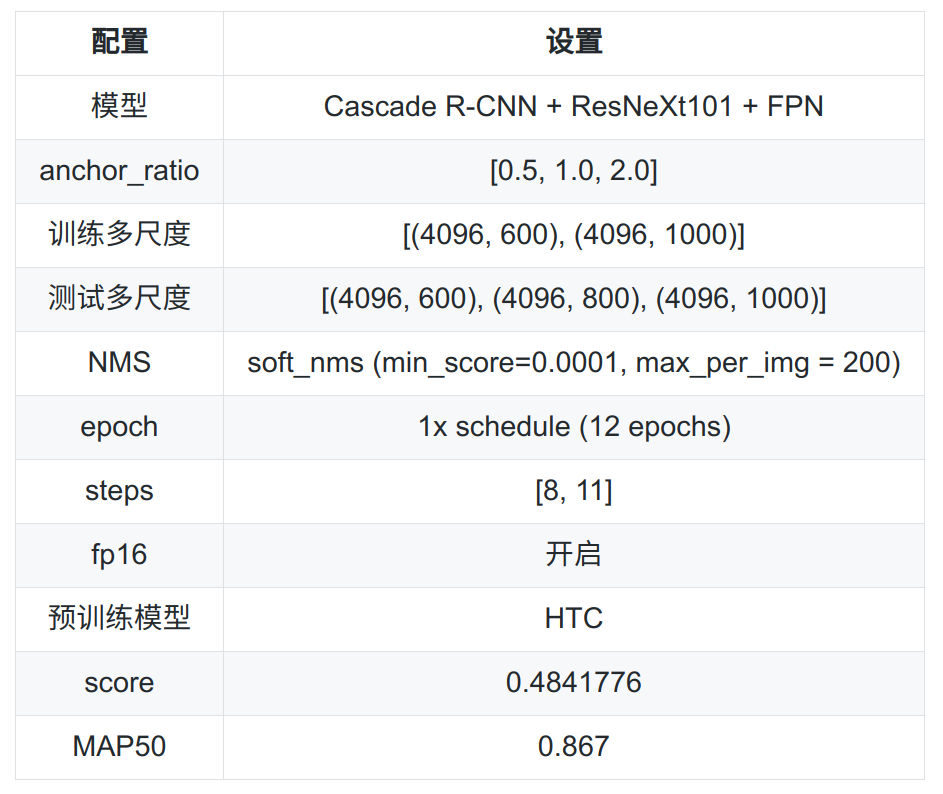
HTC [4] 预训练模型权重:mAP高的预训练模型对于后续模型收敛有很好的帮助,同时好的预训练模型也能增加模型的鲁棒性,HTC预训练模型权重是在COCO和COCO-stuff数据集上完成,而且还使用了multi-scale进行训练,所以它是个很好的提分点。
-
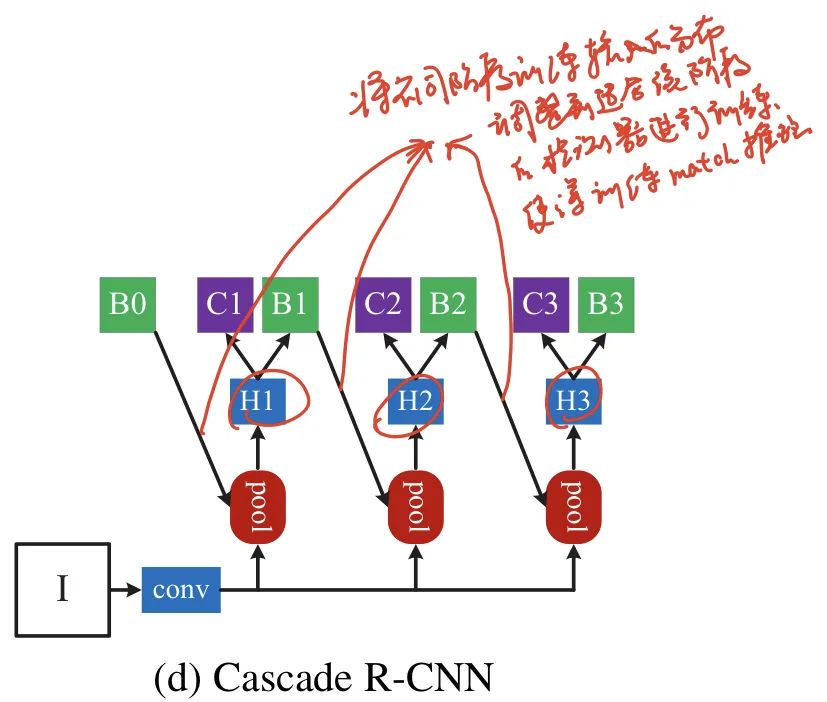
扩大短边上限:在mmdetection论文 [5] 中,作者有提到,在设置训练多尺度时,提高短边上限能带来提升,我们将原短边上限1000,提高到1400。同样地,测试尺度也相应变更为[(4096, 600), (4096, 1000), (4096, 1400)],模型有提升。这里设长边为4096,是为了放开Resize对长边的依赖,这样尺度的变化完全都是由短边进行控制的,尺度变化更加和谐些。具体的计算方法如图7所示:

-
放大学习率:我们是单gpu输入单张图片,四个GPU下的学习率应为0.005(计算过程见图8),但我们使用了0.01。
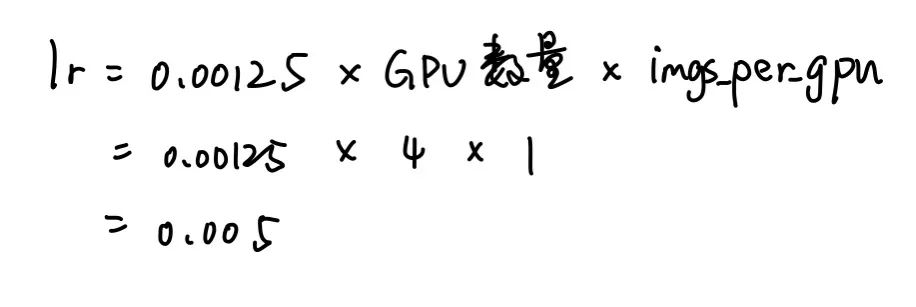
-
使用Albumentations数据增强:我们尝试了几个Albu手段,最有用的是:CLANE,IAASharpen, IAAAEmboss和RandomBrightnessContrast。
-
CLAHE(对比度受限的自适应直方图均衡):自适应直方图均衡化(AHE)用来提升图像的对比度的一种计算机图像处理技术。和普通的直方图均衡算法不同,AHE算法通过计算图像的局部直方图,然后重新分布亮度来改变图像对比度。因此,该算法更适合于改进图像的局部对比度以及获得更多的图像细节。AHE有过度放大图像中相同区域的噪音的问题,另外一种自适应的直方图均衡算法即限制对比度直方图均衡(CLAHE)算法,它能有限的限制这种不利的放大。

-
IAASharpen:基于形态学的一种数据增强,图像锐化主要影响图像中的低频分量,不影响图像中的高频分量。图像锐化的主要目的有两个:(1)增强图像边缘,使模糊的图像变得更加清晰,颜色变得鲜明突出,图像的质量有所改善,产生更适合人眼观察和识别的图像;(2)希望通过锐化处理后,目标物体的边缘鲜明,以便于提取目标的边缘、对图像进行分割、目标区域识别、区域形状提取等,进一步的图像理解与分析奠定基础。IAASharpen锐化输入图像,并将结果与原始图像重叠。不仅保留了原有细节且使边缘更加鲜明。

-
IAAEmboss:基于形态学的一种数据增强,压印输入图像,并将结果与原始图像重叠。对图像执行某一程度浮雕操作,通过某一通道将结果与图像融合。其目的和锐化融合一个道理也是一种不错的数据增强的方法。
-
RandomBrightnessContrast:随机光照强度及对比度增强,这是一种将光照和对比度增强的方法融合到一起的方法,通过对比度和光照强度的一定范围内的随机改变增加图片的多样性,提高模型的泛化能力。

-
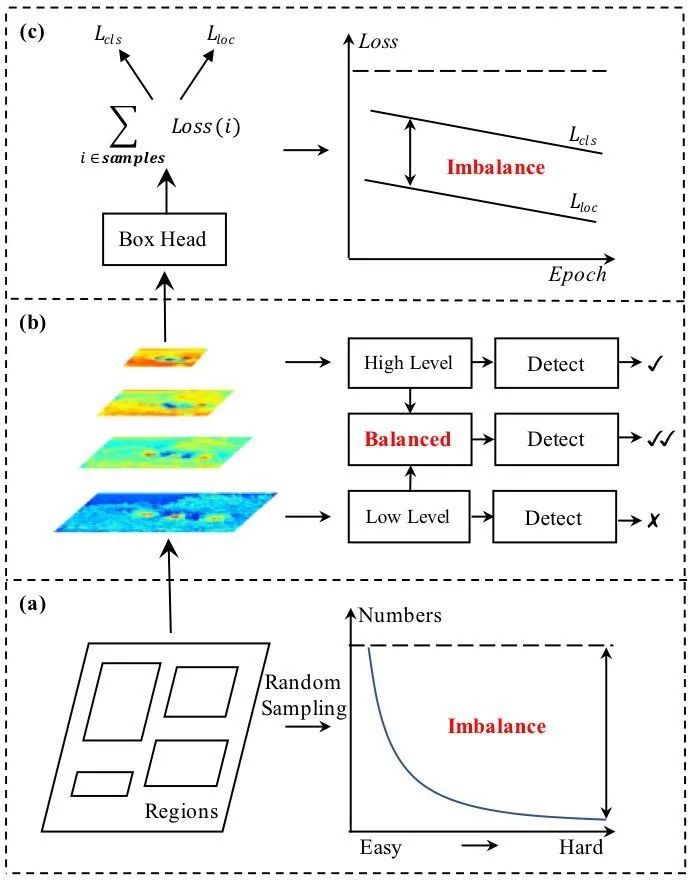
训练加入海草标注:由于在去海草数据集训练后,发现数据集中的海草常会被认为海胆(黑圆团海草)和海参(波浪边缘的条状海草),所以为了增加模型在海草和其他目标海产上的区分能力,把数据集中82个海草标注加入进行训练,最后预测结果对海草进行剔除即可。该方法给模型带来很大的提升,但由于原本数据集海草标注本身没有认真标注,这里带来的提升也可能是因为多了一个类别后,缓解了模型过拟合,增加了模型通用性。
-
Mixup -
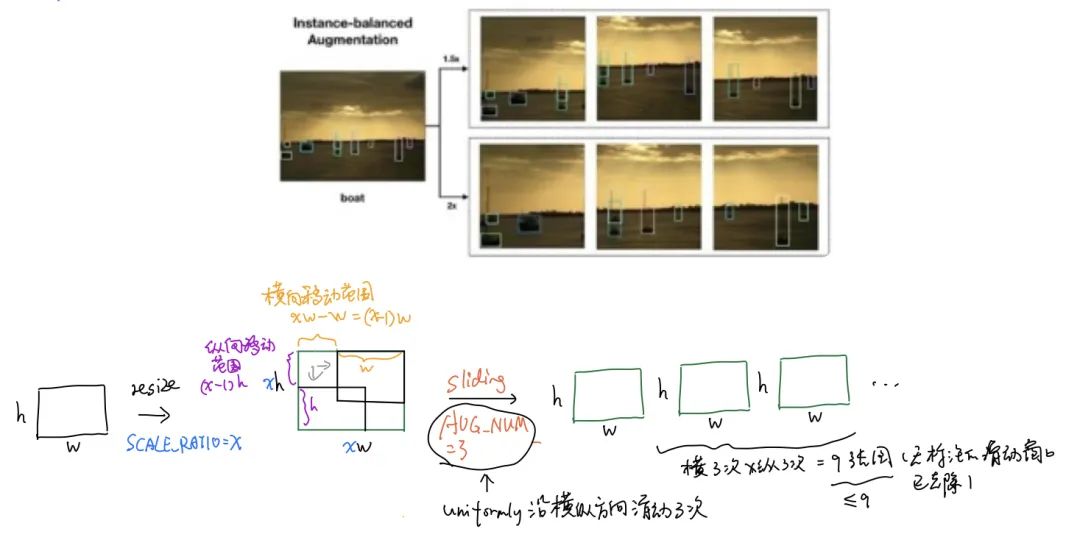
实例平衡增强 -
模糊(Median Blur和 Motion Blur) -
Retinex -
泊松融合 -
标签平滑

-
w<=750, 核大小为10-20; -
750<w<2000,核大小为20-60; -
w>=2000, 核大小为100-140。
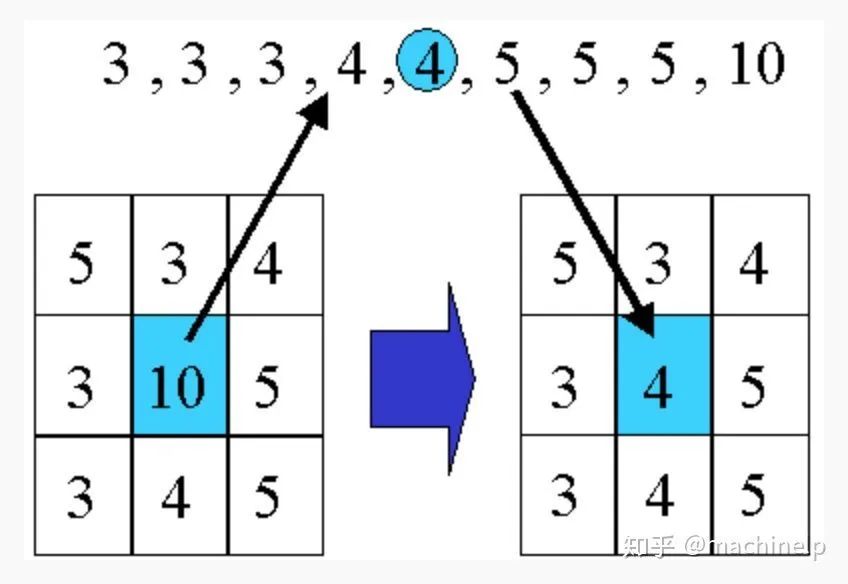


-
不同的高斯kernel对图像的影响。sigma = 300,使用GIMP的MSRCR算法,单尺度,Dynamic = 2。 -
高斯模糊在这里主要起到模拟光照成像,认为光照的成像是稳定的,变化是缓慢的,是低频的,对应背景和轮廓。所以用低通滤波器。 -
sigma确定时,kernel的size越小,生成的入射成像越清晰,频带更宽,通过了部分高频,原图-生成的图(滤掉少量的高频) =得到的就是滤过的少量的高频细节和噪声,相当于高通。 -
sigma确定时,kernel的size越大,生成的入射成像越模糊,频带更窄,阻碍了高频,原图-生成的图(留下低频背景轮廓) = 得到的就是滤过的高频细节(剪掉轮廓,图像更清晰)。
-
size越小,得到的低频混杂更多高频(高频阻碍的少)—> 模拟的低频稳定,光照杂质细节更多,相减就剩下了少量的细节 -
size越大,得到的低频更纯净(高频阻碍的越多)-> 模拟的低频稳定光照成像更完美

-
使用高斯函数对原始图像进行低通滤波 -
将原始图像与滤波后图像转换到对数域做差,得到对数域的反射图像 -
多尺度重复1,2步骤,将对数域的反射图像在像素层面上进行图像求和,得到MSR结果 -
颜色恢复:
-
在通道层面,对原始图像求和,作为各个通道的归一化因子 -
权重矩阵归一化,并转换到对数域,得到图像颜色增益。(原始图像乘以颜色修复的非线性因子,这里取2.0,再除以归一化因子) -
MSR结果按照权重矩阵与颜色增益重新组合(连乘)
-
图像恢复:颜色恢复后的图像乘以图像像素值改变范围的增益,加图像像素值改变范围的偏移量,得到最终结果
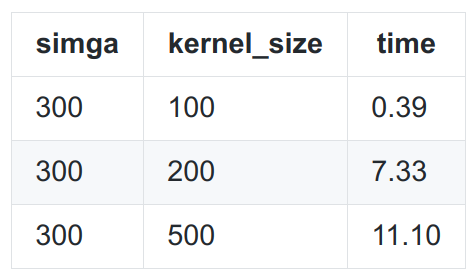
-
使用图像金字塔,使用5*5的高斯滤波器,逐层对高斯金字塔滤波,并下采样,下采样后,sigma减半,用于下一层滤波 -
不断递归,直到由sigma算出来的滤波器的size小于10 -
当递归到,滤波器的大小小于10后,分x轴y轴对对应的下采样图进行高斯运算,这个图是经过一次次高斯模糊降采样得到的。 -
反向逐层上采样,得到与输入原图同样分辨率,滤波结束

-
准备原图source和背景图target,用mask扣除原图中的ROI,需要点P指定这个ROI放到背景图某个位置,注意P点为ROI的中心点所在位置; -
计算ROI和背景图target的梯度场; -
计算个融合图像的梯度场,就是用ROI的梯度场替换背景图相应处的梯度场; -
计算融合图的散度场Laplace; -
用这个laplace和原图求解泊松等式,也就是求解Ax=b。这里A是由泊松方程得到的,b是散度,x就是融合图像的像素值。


-
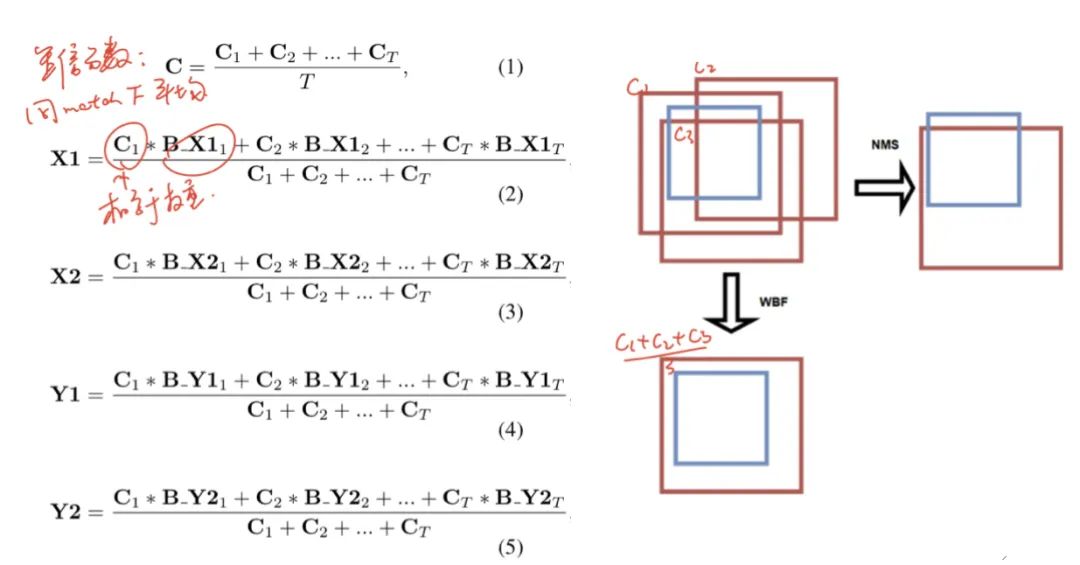
WBF融合分为两块:框和置信度。各自聚类匹配框和其置信度的融合权重是score × weight。
-
如果WBF是在softNMS的结果上做融合,会因为某目标上存在冗余低分框拉低融合后的框分数,而框的位置也是平均了冗余框得到。解决方法有两个:
-
使用论文的方法,使用NMS输出的结果上实施WBF,@spytensor推荐NMS的score_thr = 0.001,这样NMS只是保留当前模型下唯一的高分框,这样最后平均融合后不会受冗余低分框影响。 -
在softNMS下,改置信度融合方法conf_type为max,这样在两个模型预测结果中选择其中最大的置信度作为平均融合框的置信度。
-
以上两种方法中,框坐标的融合都是采用score x weight然后平均的方式,只是置信度不一样,前者使用avg(NMS),后者max(SoftNMS)。需要注意的是以上两种方法不建议使用weights=[2,1],因为如果一个框0.9,一个框1.0,最后融合conf=(0.9x2+1.0)=1.4>1.0,分数会不正常。因此后续推荐使用weights=[1,1]。 -
如果模型1在某处预测了一个框(置信度为C),但模型2在某处没有预测到这个框,WBF代码会通过(C=C×某cluster上框数T/模型数量)降低其置信度,这里即融合后框的置信度是C/2。 -
作者在论文提到模型如果服从不同的概率分布,例如有些模型大部分会给0.8~0.9的置信度,而其他模型可能会给0.00008~0.00009,但它们是有相似的mAP的,因为mAP的计算个是使用框排序的方式,但融合后会影响分,这个问题可以通过confidence normalization进行结果(开源代码并没有加入这块内容)。
-
追加海草难样本标注:由于海草在全数据集上只有82个标注且很多海草并没有被认真标注,且存在海草被误认做海胆和海参,对此的猜测是海草标注不清楚带来了模型辨认上的困难。为了清除这个遗漏,我们先将当前最优模型预测训练集并可视化框在图上,之后将训练集中被误检成其他类且无标注的海草目标进行框的绘制,之后补充到原数据集中,5千多张图最后补充了额外800多个海草标注,提交结果比最优实验少了5w的标注。但最后模型提交结果并不是很好,可能是因为在减少误检和提高查全率(即检测出更多框)之间,mAP在此数据上更加偏向于后者。 -
结果替换:根据验证集表现,将不同类别上表现最好的模型结果进行拼凑,但提交结果都不太好。其实应该在上面第4点的专家模型提到的建议去做结果替换会有好的效果,但后面时间上来不及了。 -
cosine lr decay:我们使用后发现该方法下,损失下降的更加低了,说明在cosine学习率衰减策略下,模型收敛更好,但提交结果不好,可能是学习率放大后再用cosine lr decay导致了模型过拟合,由于时间紧凑,并没深入下去。
重磅!CVer-目标检测 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,目前已汇集3800人!涵盖2D/3D目标检测、小目标检测、遥感目标检测等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
麻烦给我一个在看!
登录查看更多
相关内容

Arxiv
3+阅读 · 2018年12月13日




相关VIP内容
相关资讯
相关论文
Arxiv
3+阅读 · 2018年12月13日