7 papers | AI新方法解高数;Ross、何恺明等人渲染思路做图像分割
机器之心整理
参与:杜伟
本周的论文既有利用定向声波黑掉智能音箱的进一步探索,也有 CMU 杨植麟解决 softmax 的新方法 Mixtape 以及应用 seq2seq 模型解决高数问题的 AI 新方法。
目录:
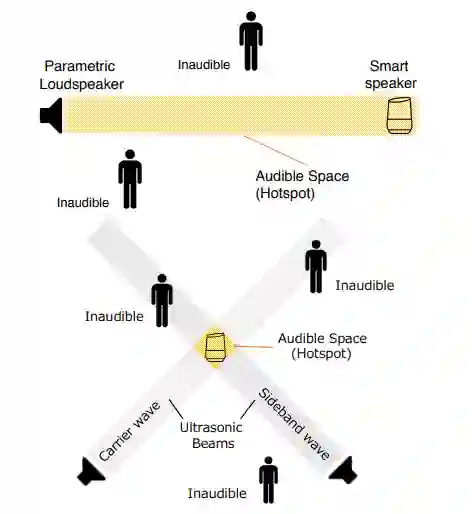
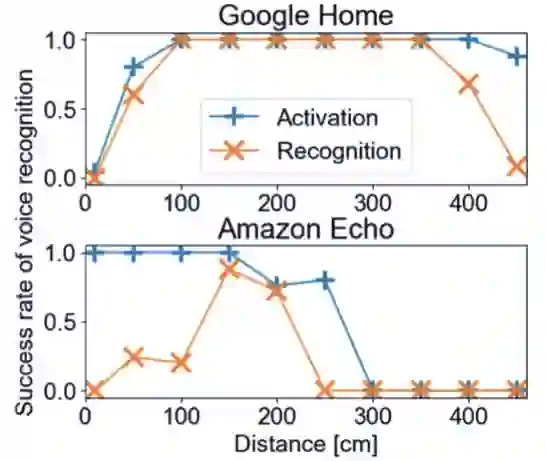
作者:Ryo Iijima、Shota Minami、Yunao Zhou、Tatsuya Mori 等
论文链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8906174

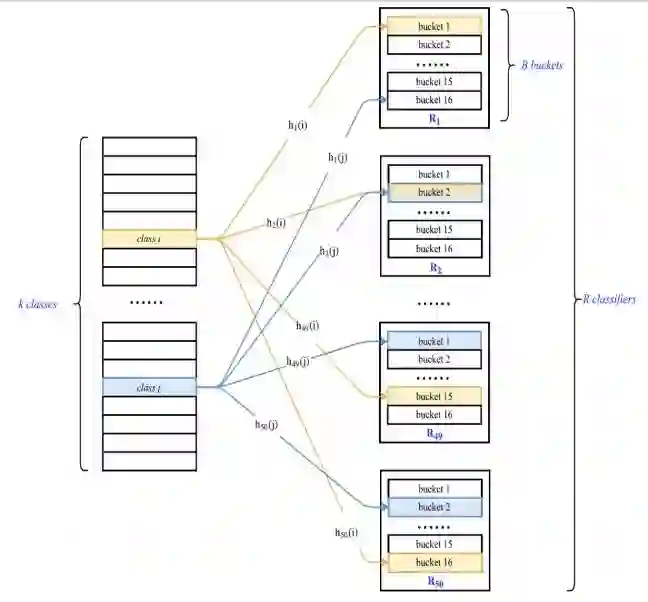
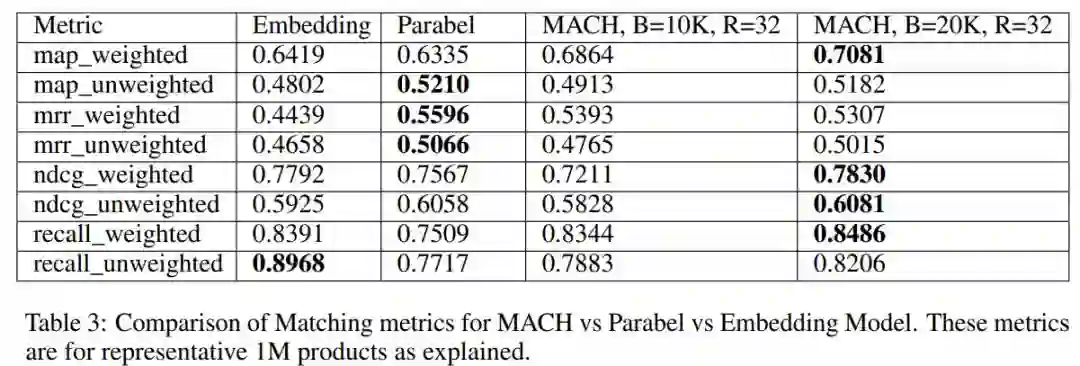
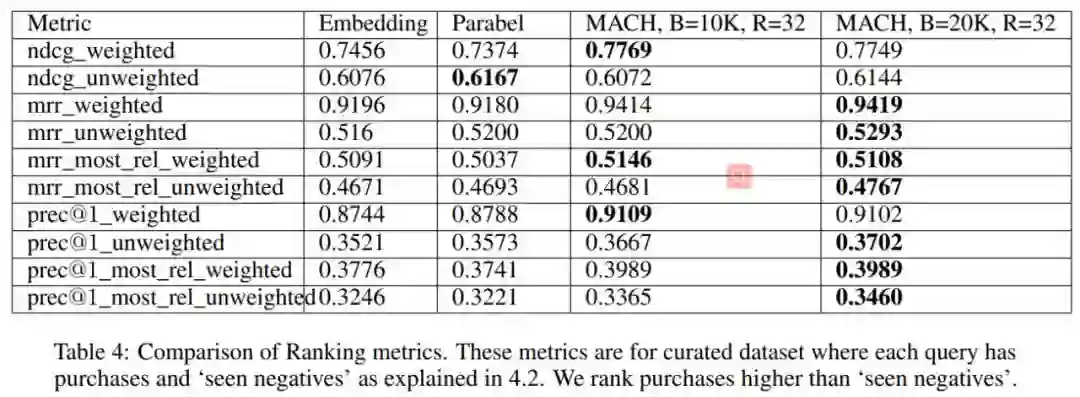
作者:Tharun Medini、Qixuan Huang、Yiqiu Wang、Vijai Mohan、Anshumali Shrivastava
论文链接:https://papers.nips.cc/paper/9482-extreme-classification-in-log-memory-using-count-min-sketch-a-case-study-of-amazon-search-with-50m-products.pdf
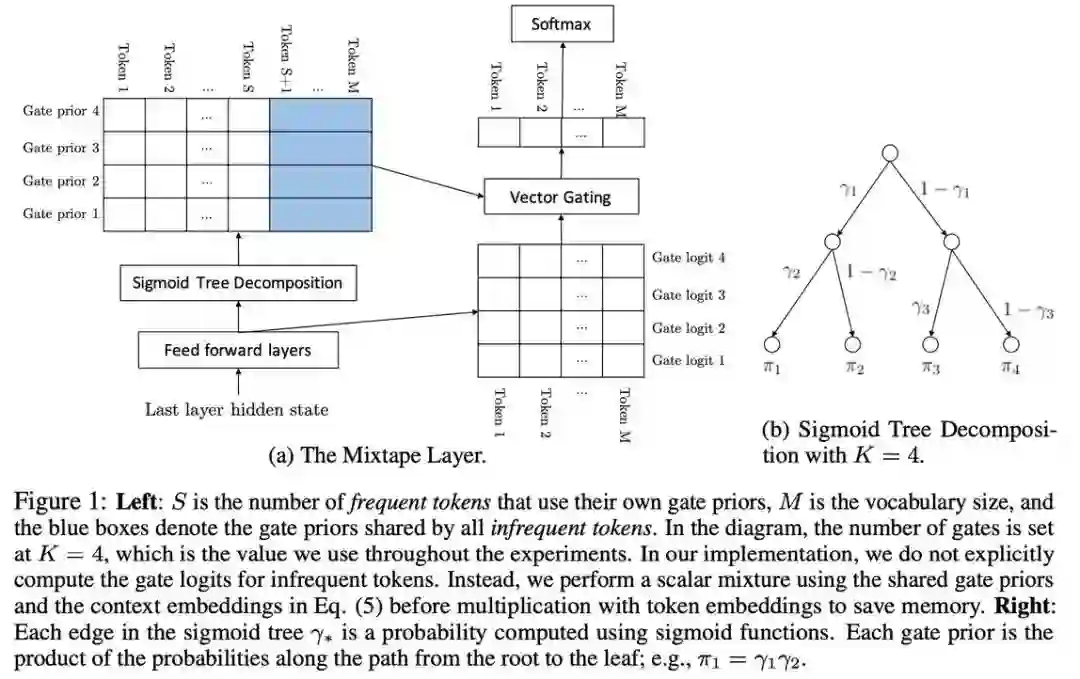
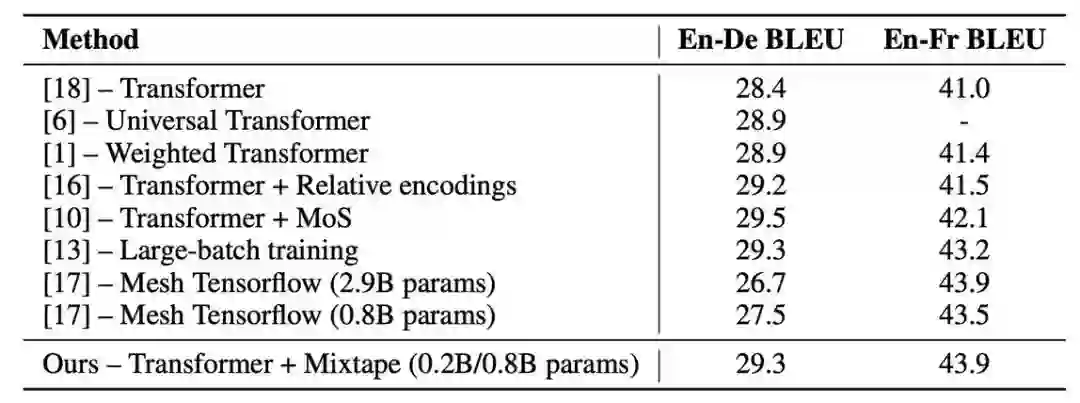
作者:Zhilin Yang、Thang Luong、Ruslan Salakhutdinov、Quoc Le2
论文链接:https://papers.nips.cc/paper/9723-mixtape-breaking-the-softmax-bottleneck-efficiently.pdf
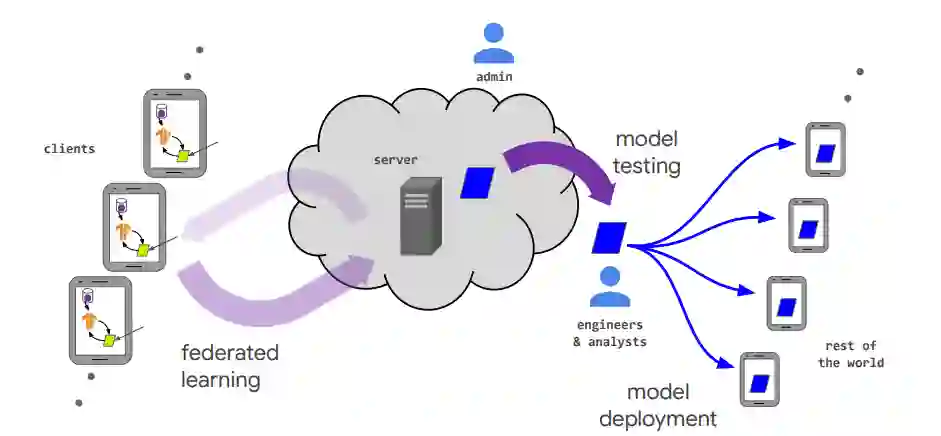
作者:Peter Kairouz、H. Brendan McMahan、Brendan Avent 等
论文链接:https://arxiv.org/pdf/1912.04977.pdf
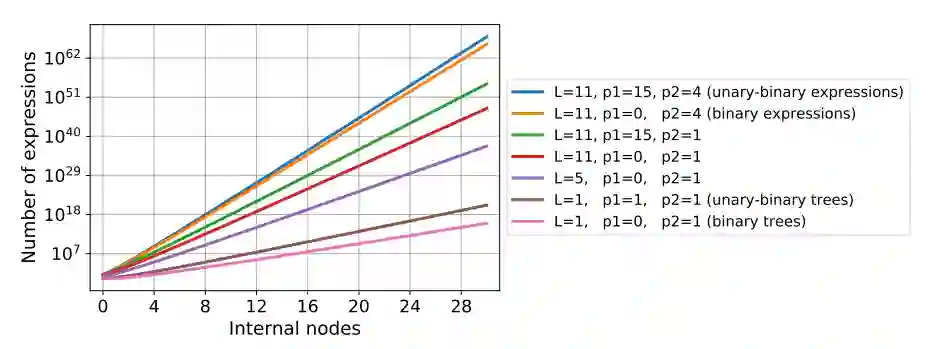
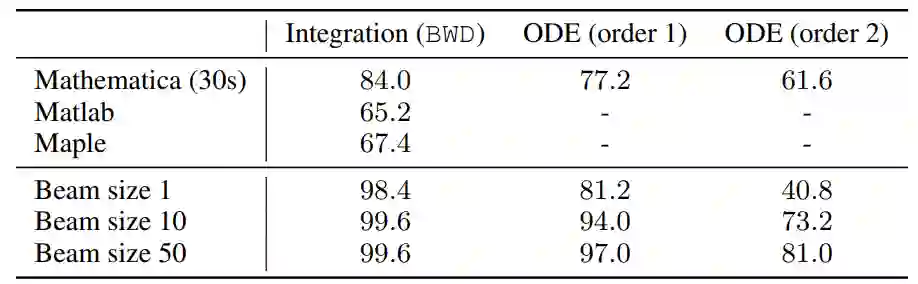
作者:Guillaume Lample、Francois Charton
论文链接:https://arxiv.org/pdf/1912.01412.pdf
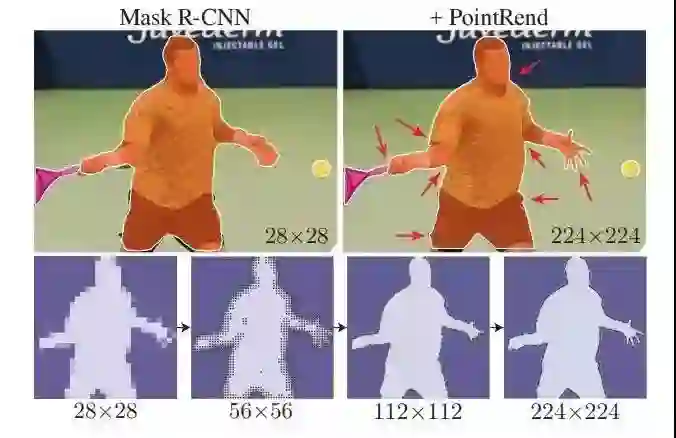
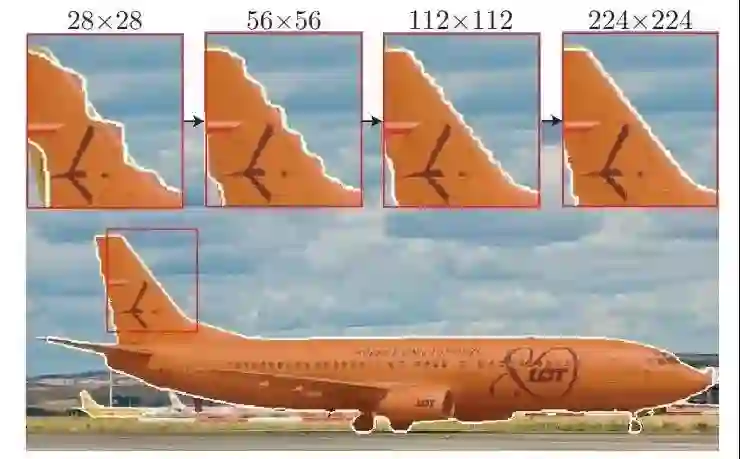
作者:Alexander Kirillov、吴育昕、何恺明、Ross Girshick
论文链接:https://arxiv.org/pdf/1912.08193.pdf

作者:Tero Karras、Samuli Laine、Miika Aittala、Janne Hellsten 等
论文链接:https://arxiv.org/abs/1912.04958






