CVPR 2018 | 中科大&微软提出立体神经风格迁移模型,可用于3D视频风格化
选自arXiv
作者:Dongdong Chen等
机器之心编译
参与:Nurhachu Null、刘晓坤
近年来,在自然图像上再现名画风格的风格转换技术成为内容创作的热门话题。例如,最近的电影「至爱梵高」是第一部完全由训练有素的艺术家制作的动画电影。然而,目前还没有将风格转换应用于立体图像或视频的技术。现有的风格迁移方法会使左右视图不一致的风格化纹理,研究者通过解决该问题,突破了立体风格迁移的一大瓶颈。
立体 3D 正在成为一种大众消费媒体,例如 3D 电影、电视以及游戏。现在,随着头戴式 3D 显示器(例如 AR/VR 眼镜)和双镜头智能手机的发展,立体 3D 越来越受关注,并激发了许多有趣的研究工作,例如立体修复 [36,27]、视频稳定 [15],以及全景 [39]。在这些研究中,创建立体 3D 内容总是令人感兴趣的。
近年来,在自然图像上再现名画风格的风格转换技术成为内容创作的一个热门话题。例如,最近的电影「至爱梵高」是第一部完全由训练有素的艺术家制作的动画电影。受卷积神经网络 ( CNN ) 能力的启发,Gatys 等人的开创性工作 [ 13 ] 提出了一种将指定作品的风格自动转换为任何图像的通用解决方案。[ 21,19,34,12,11 ] 提出了许多后续工作,以改进或扩展该项目。这些技术还被应用于许多成功的工业应用 (例如,Prisma [ 1],Ostagram [2] 和 Microsoft Pix [3])。
然而,据作者介绍,目前还没有将风格转换应用于立体图像或视频的技术。在这篇论文中,作者通过首次提出立体神经风格转换算法来应对这种新兴 3D 内容的需求。他们首先独立地仔细检验了现有的风格转换方法在左视图和右视图上的简单应用。
他们发现往往这些方法很难在两个视图上产生几何一致的风格化纹理。结果就是,它会引起有问题的深度感知,并且造成观看者的 3D 疲劳(如图 1 所示)。因此我们需要生成和和两个视图一致的风格化纹理。此外,还需要一个快速的解决方案,尤其是在实际的实时 3D 显示中(例如 AR/VR 眼镜)。最后但不是最不重要的一点,作为进一步扩展的立体视频中的风格转换应当同时满足时间的连贯性。
本文提出了第一个用于快速立体风格转换的前馈网络。除了广泛使用的风格损失函数 [13,19] 之外,作者还引入了一个附加的视差一致性损失,用它来惩罚风格化结果在非遮挡区域的偏差。具体而言,在给定双向视差和遮挡掩膜的情况下,可以建立左视图和右视图之间的对应关系,并且惩罚了两个视图中都可见的重叠区域的风格不一致。
作者首先在基于优化的解决方案 [13] 中验证了这个新的损失项。如图 1 所示,通过在优化过程中联合考虑风格化和视差一致性,该方法可以为两个视图生成更加一致的风格化结果。然后作者进一步将这种新的视差损失结合在了为立体风格化所设计的前馈深度网络中。
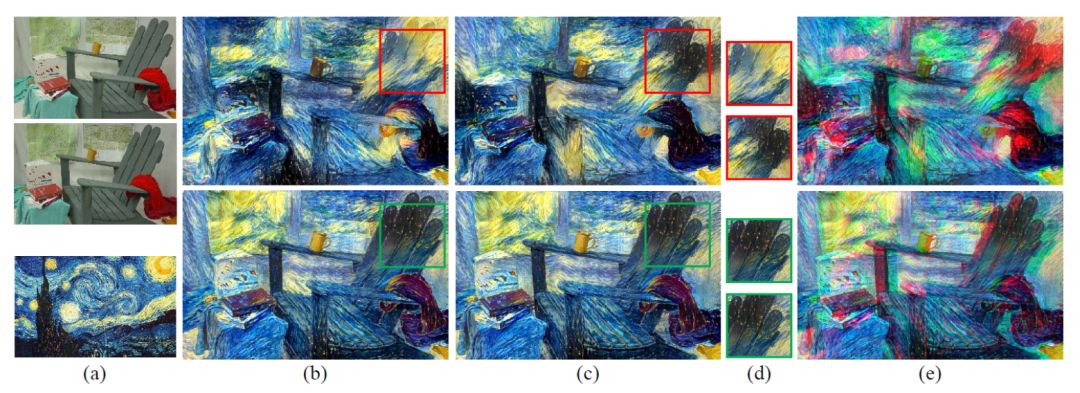
图 1. 图(a)给出立体图像对和一副风格图像,立体图像的左右视图都被进行了风格化(第一行),左视图的风格化结果(b)和右视图的风格化结果(c)会在空间对应区域(d)不一致。这会导致不期望的垂直差异和不正确的水平差异,进而在立体图像(e)中造成 3D 疲劳。相对而言,通过引入新的视差一致性约束,本文的方法(第二行)可以为两个视图生成一致的风格化结果。
本文提出的网络由两个子网络组成。一个是风格化子网络 StyleNet,它使用了和 [19] 中一样的架构。另一个是视差子网络 DispOccNet,它可以估计出输入立体图像对的双向视差图和遮挡掩膜。这两个子网络被集成在特征级别的中间域中。它们首先分别接受各自任务的独立训练,然后作为一个整体接受联合训练。
该新视差子网络具有两个优点:
1 ) 与使用缓慢全局优化技术的一些最先进的立体匹配算法 [ 33,22 ] 相比,它能够实现实时处理;
2 ) 它是第一个同时估计双向视差和遮挡掩模的端到端网络,而其它方法 [ 26,38 ] 在每个前向过程中仅估计单个双向视差图,并且需要后处理步骤来获得遮挡掩模。文章的 5.2 部分展示了这种双向设计优于单向设计的原因。
该网络还可以很容易地通过集成 [10] 中的子网络扩展到立体 3D 视频中。这样,最终的风格化结果不仅可以保持每个时间步的水平空间一致性,而且可以保持相邻时间步之间的时间连贯性。这项工作可能会启发电影创作者考虑自动地将 3D 电影或电视转变为名画风格。
实验结果表明,该方法无论在数量上还是在质量上都优于这个领域中的基准结果。总体而言,本文主要贡献由以下四部分组成:
通过将新的视差一致约束结合到原始的风格损失函数中,本文提出了第一个立体风格转换算法。
本文提出了第一个用于快速立体风格转换的前馈网络,它把风格化、双向视差和遮挡掩码结合成了一个端到端系统。
本文提出的视差子网络是第一个可以同时估计双向视差图和遮挡掩码的端到端网络。
考虑到视差一致性和时间连贯性,本文通过集成一个附加的子网络把该方法扩展到了立体视频的风格转换上。
本文的剩余部分将首先总结一些相关的工作。在该方法中,研究者使用了基于基线优化的方法验证了新提出的视差约束,然后介绍了快速立体风格转换的前馈网络,并将其扩展到立体视频。实验结果表明了该方法的有效性,还展示了对该方法的一些控制变量分析。在本文最后作者作了进一步讨论。
4. 立体风格转换网络
本文提出了一个快速立体风格转换的前馈网络。整个网络由两个子网络组成:一个是与现有的风格化网络 [ 10,11,12,16 ] 相似的风格化网络 StyleNet,另一个是同时估计双向视差图和遮挡掩码的 DispOccNet。这两个子网络被集成在一个特征级中间域中,使左视图和右视图完全对称。
StyleNet:作者使用了 [19] 最早提出的,并在其他工作中 [10, 11, 12, 16] 得到广泛应用的默认风格网络结构。该架构基本上类似图像自动编码器,它由若干个指定步幅的卷积层 (将图像编码到特征空间中)、五个残差模块和少数指定步幅的卷积层 (将特征解码为图像) 组成。在该实现中,遵循了与 [ 10 ] 相同的设置,其中第三个残差块 (包括第三个残差块) 之前的层被视为编码器,而剩余层被视为解码器。
DispOccNet:最近,Mayer 等人引入了称为 DispNet 的端到端卷积网络,它被用于视差估计 [26]。然而,它只能预测每个前向的单向视差图 DI ( l→r )。在本文中,作者使用类似的网络结构,但在扩展部分中为每个分辨率 ( 1 / 64,...1 / 2 ) 增加了三个分支。这三个分支用于回归视差 Dr 和双向遮挡掩码 Ml 和 Mr。
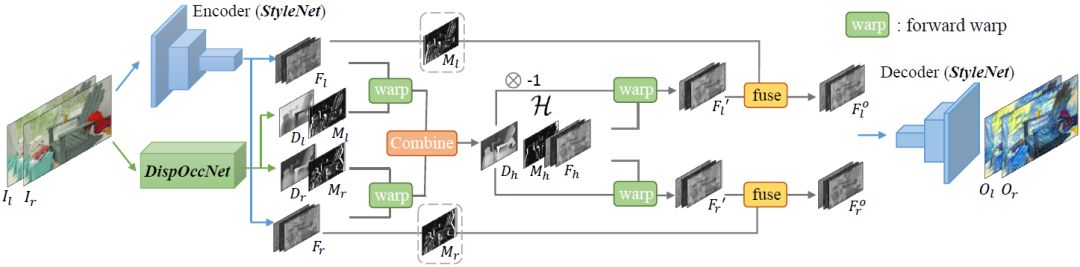
图 3. 快速立体风格迁移的总体网络结构。它包含两个子网络:StyleNet 和 DispOccNet,它们被集成在特征级别中间域 H 中。
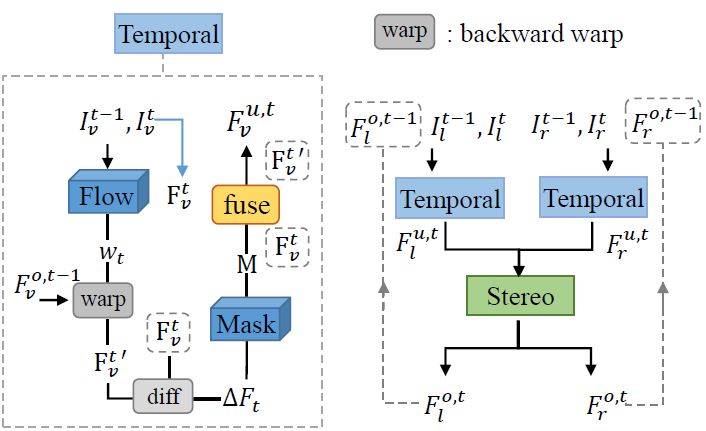
图 4. 立体视频风格迁移的总体结构。左边是时间网络的简化工作流。右边是用于结合上述立体网络和左边附加的时间网络的递归公式。

图 6. 与使用 [10] 中所用方法(第一行)的一个类似变体的结果对比,该变体方法存在重影和风格化不一致的问题。中间行是使用了本文的方法构成掩码替换的结果,重影消失了,但是不一致性仍然存在。相比之下,本文的结果(最底行)没有上述问题。
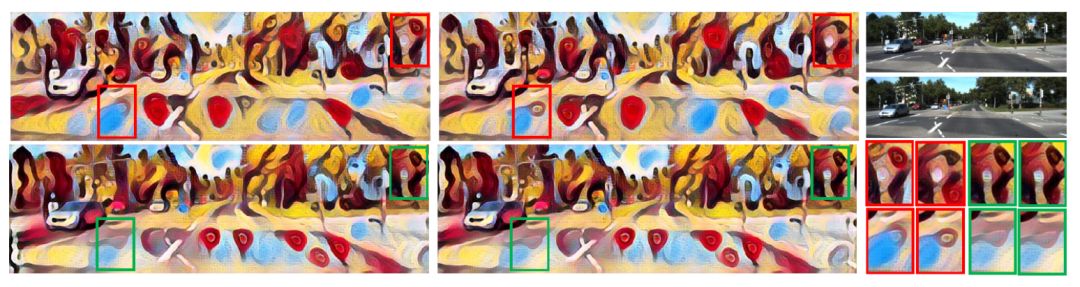
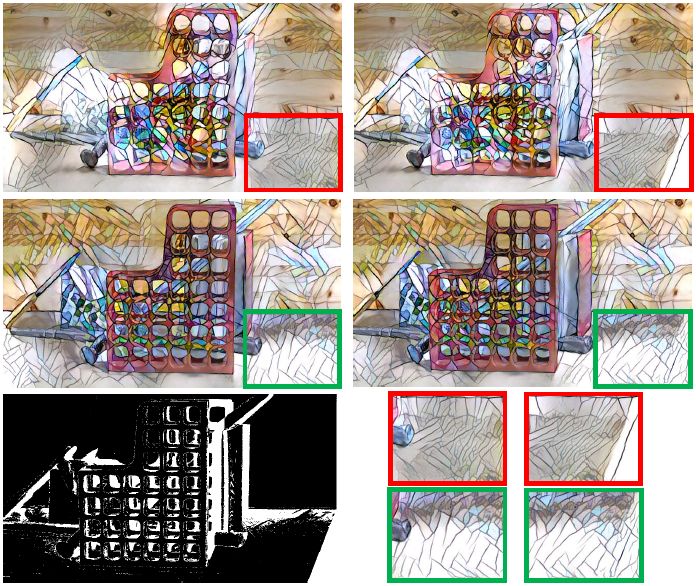
图 7. 与真实街道视图立体图像对的基准进行比较。第一行中带有红色标记框是基准结果,底行含有对应的绿色框的是本文的结果。显然,本文的结果具有更好的视差一致性。
论文:Stereoscopic Neural Style Transfer(立体神经风格转换器)

论文链接:https://arxiv.org/abs/1802.10591
摘要:本文首次尝试实现立体神经风格转换,以应对 3D 电影或 AR/VR 的新需求。我们首先仔细检验了将现有的分别应用于立体图像的左视图和右视图的单目风格转换方法,表明在最终的风格化结果中不能很好地保持原始的视差一致性,这给观看者造成了 3D 疲劳。为了解决这个问题,我们通过在非遮挡区域中加强双向视差约束,向广泛采用的风格损失函数中加入了一个新的视差损失。为了得到实用的实时性解决方案,我们提出了第一个前馈网络:它联合训练一个风格化子网络和一个视差子网络,并将它们集成在一个特征级的中间域中。我们的视差子网络也是用于同时估计双向视差和遮挡掩码的首个端到端网络。最后,综合考虑时间连贯性和视差一致性,我们将该网络有效地扩展到立体视频上。实验结果表明,该方法无论在数量上还是质量上都明显优于基准算法。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


