在AI眼里,谁会是中国新说唱的冠军

作者:阿翘,平安科技资深产品经理
微信公众号:阿翘AKIU
题图来自 Unsplash ,基于 CC0 协议
全文共 3956 字 8 图,阅读需要 8 分钟
今年夏天,最近热播的大型音乐节目《中国新说唱》又一次掀起了全民说唱的热潮。
虽然节目播出以来总是争议不断,但不可否认的是:《中国新说唱》带领观众进入了说唱的世界,感受说唱带来的魅力。
随着节目的进行,最终《中国新说唱》终于来到了四强的角逐。四强选手新秀、大傻、黄旭以及杨和苏都是非常厉害的说唱歌手,不仅台风强硬而且发挥稳定,深受观众的喜爱;因此他们四个都有机会成为冠军。
作为产品经理的我自然会想:能不能利用AI技术,帮我预测谁会是今年中国新说唱的总冠军呢?
那么问题来了:
怎么样才能体现每个歌手的综合实力?
有没有合适的算法可以帮我们做这件事情?
如果有合适的算法,那么需要什么样的数据?
有了数据以后,如何让AI知道每首歌的优劣之分?
预测夺冠这件事情,其实早在体育领域也有类似的场景。
几年前,已经有很多机构采用AI的方式预测世界杯的夺冠热门。而在预测说唱冠军这个场景上,我们也可以借鉴AI帮助我们做决策。
因为体育与音乐的差异性,我们需要准备的数据以及模型都有一些改变——决策树、回归分析以及深度学习都是可以尝试的方法,但在这里,我们选择使用比较广泛的随机森林算法。
数据是为模型服务的,需要哪些数据取决于我们搭建模型的方式。
如何采用一种合理的方式,让模型判断不同歌手的能力呢?
最简单的方式是:给四位冠军候选人的歌曲全部打分,然后丢到模型中运行,由此判断谁的夺冠概率更高。
但是,这种做法毫无意义。
原因在于:
模型并不能理解每首歌的歌词写的是什么内容,也没法判断什么样的歌词是好的歌词。
另外,一首歌的歌词可能很简单,但是某些观众就是喜欢这种走心的歌曲。
因此,我们必须帮助模型将感性的猜想一步步抽象成定量的数据,让模型知道具有什么特点的歌手才是好歌手;在这个基础上,才有可能预测出哪位选手最有可能成为冠军。
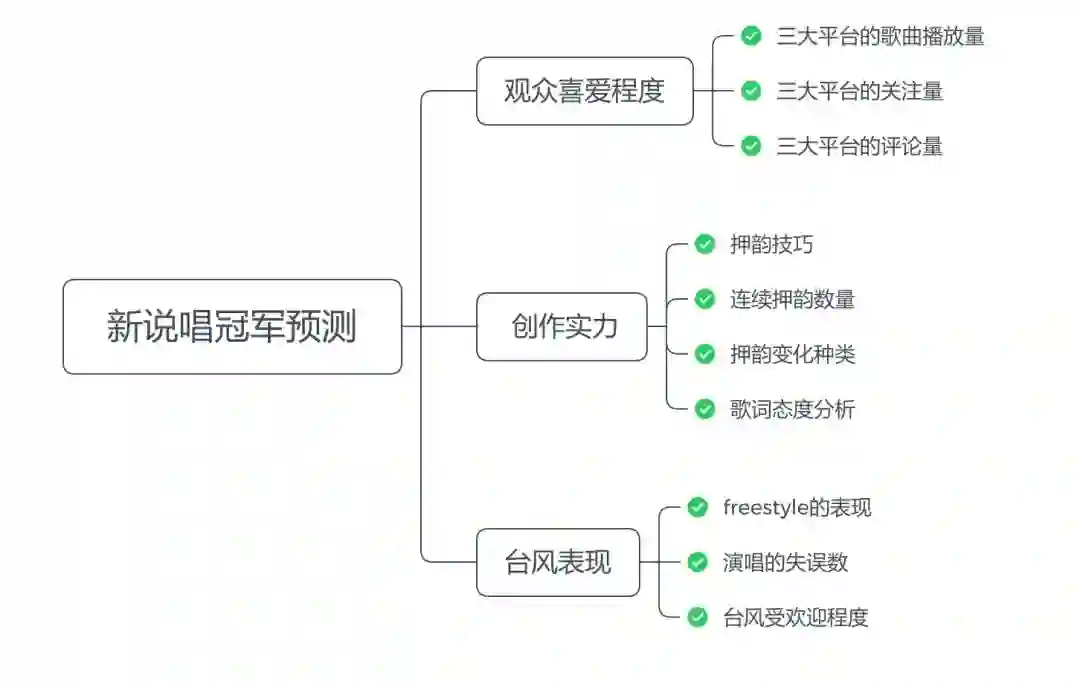
我们都知道,说唱实力、观众人气是决定一位说唱歌手的比赛成绩的关键因素,因此我们可以根据说唱歌手这两方面的表现制作特征,用数据体现歌手的综合实力:
接下来的问题是:怎么样体现说唱歌手的观众人气?
我们都知道:
播放量能反映一个歌手的歌是否受大家欢迎;
粉丝量和互动量更能反应一个歌手是否受大家欢迎。
我们首先采集网易云音乐、QQ音乐以及虾米音乐上,四位冠军候选人所有单曲播放量以及评论量、粉丝量数据:
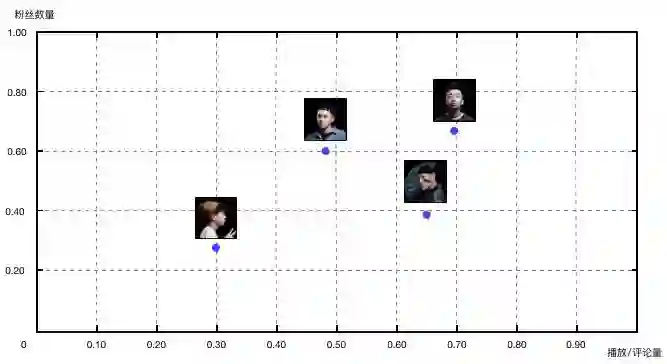
说唱实力相对来说比较容易评判。
虽然普通中文流行歌也有简单的押韵结构,但是说唱是真正让押韵变成一种技术和艺术的音乐类型。押韵不仅增加了作词难度,也提升了韵律上的美感;因此我们可以从歌曲的押韵技术统计,体现歌手的说唱实力。
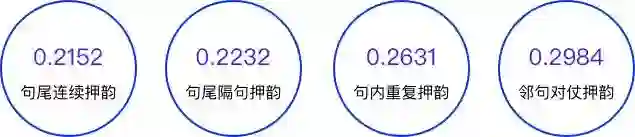
根据现在流传甚广的押韵检查规则和音乐游戏得分规则,通常需要统计以下押韵方式:
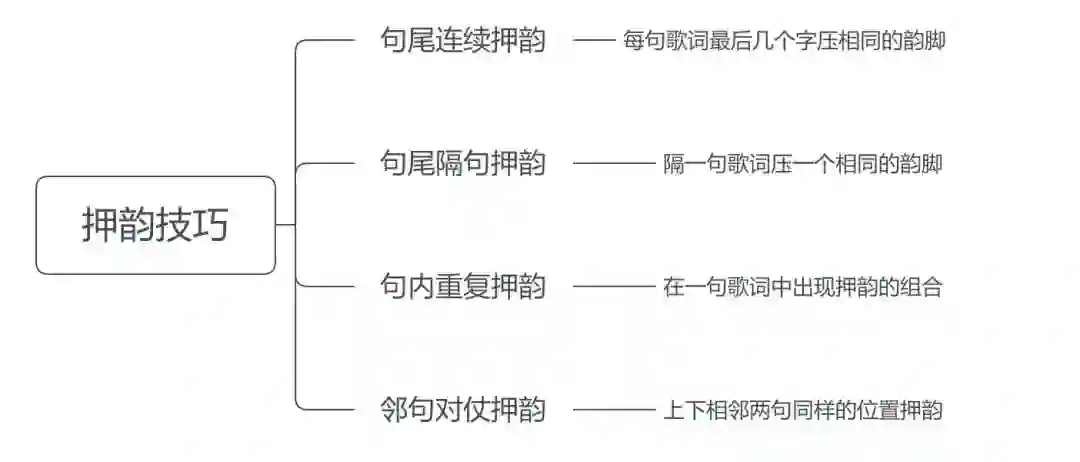
连续押韵是歌手最常用的写词技巧,但是不同的押韵技巧在创作难度上有很大的差异。
例如:
句尾连续押韵只需要每句歌词最后几个字韵脚相同即可,四句歌词可以采用同样的韵母,写起来比较简单;
但是隔句连续押韵就需要在四句歌词中至少采用两个韵母,难度相对大一些。
——如果我们简单地把这些押韵统计给模型去处理,模型根本不知道这些押韵方式有什么区别。
为了让模型能够理解不同押韵技巧的难易之分,我们需要设计一个难度系数,让模型理解哪些押韵方式代表这个说唱歌手的技巧更好,从而更客观地表现说唱歌手的创作实力。
在学习阶段,我们还需要准备很多以往两届所有参赛歌手的特征,通过前两届冠军歌手的技术特点,判断这些技巧的难易程度,以及一首歌里什么样的押韵方式更受大众欢迎。
这里我们需要用到多元回归分析算法,计算出不同押韵技巧的系数。
多元回归是一种建立多个变量之间数学关系并利用样本数据进行分析的统计方法,可以帮助我们有效评判不同押韵技巧的接受程度:
除了押韵这么硬核的技术指标以外,歌词的内容也是评判大众喜不喜欢这首歌的依据之一。
一首内容引人向上的歌曲可能会比内容空洞的歌曲更受欢迎,而爱情类的歌曲可能会比抒发感情类的歌曲更容易被大伙接受;更重要的是:一首歌的内容如果能够引发听众的共鸣,也能够引起观众巨大的反响。
如何让模型读懂这这首歌在唱什么呢?
我们借助自然语言处理技术,分析这首歌的内容。
自然语言处理技术是一种让计算机理解人类语言文本意义的技术,是一个综合性的学科,主要包含了语义分析、词法分析、情感倾向分析、相似度分析以及关键词提取等等。
一个中文文本从形式上看是由汉字组成的一个字符串:由字可组成词,由词可组成词组,由词组可组成句子,它们中的大多数都可以根据相应的语境和场景的规定读懂文本的含义。
在这个场景下,我们需要分析前两届冠军歌手以及四位冠军候选人的5首热门歌曲中表达的情感倾向与歌曲主题,将这些数据量化后,算出前冠军歌手歌曲与冠军候选人歌曲的情感相关性系数以及主题相关性系数。
这里的数据比较复杂,就不在此处展示。
数据准备完以后,我们可以将数据放入随机森林模型中进行训练,最后将四位冠军候选人的数据放入训练好的模型中运行。
从结果来看,杨和苏拥有更大获胜概率,新秀与黄旭在这场评选中稍占下风:
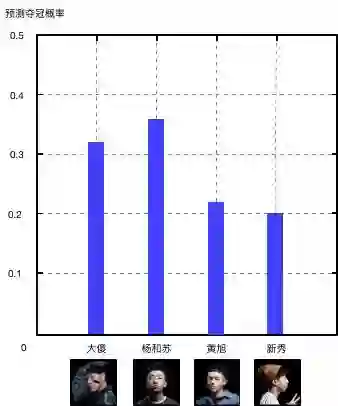
那么,这个结果是否准确呢?
我尝试将本届新说唱全国9强选手的数据都放入模型中计算,有意思的是:从评分来看,模型判断能够进入四强的选手分别是杨和苏、Vex、黄旭、刘炫廷。
这个结果和新说唱的四强结果相差有点大,模型到底是哪里出了问题呢?
仔细思考后发现:因为《中国新说唱》是一个比赛,除了歌手的人气因素以及说唱实力以外,临场的表现也是一个很重要的决定因素。
很多歌手人气很高并且实力强劲,却因为现场的失误以及不稳定的发挥最终没有进入下一轮比赛;在模型中,我们需要考虑现场表现这个维度对歌手成绩的影响。
现场表现,我们可以从临场发挥的表现、演唱的失误数以及台风受欢迎程度这三个方面体现:
临场发挥的表现以及台风受欢迎程度是比较难量化的,因此我们需要分析每位歌手演唱完后导师的评价,采用自然语言处理技术分析出导师评价的正面程度,以此计算哪位歌手的临场表现更好。
而台风受欢迎程度,我们可以用每首歌曲演唱过程中观众欢呼的次数来代替:一首歌的表现越好,现场观众的欢呼次数越多。
加入了台风表现的数据后,我们再次尝试运行模型:
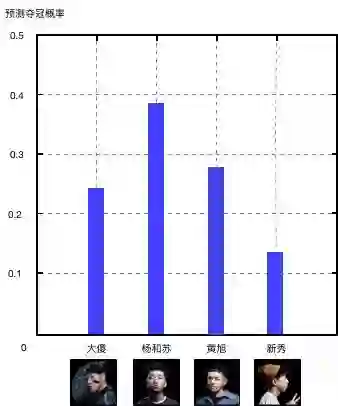
从这次的结果可以看出来,杨和苏与黄旭的夺冠概率增加了许多;如果用本届新说唱全国9强选手的数据放入模型计算的话,能够进入四强的选手是杨和苏、黄旭、大傻与新秀,这个结果还是比较符合现实结果的。
由此可见:现场的表现对歌手的成绩非常重要,也能够说明模型的准确度得到了明显的提升。
上述过程,实际上就是产品经理使用机器学习的模型解决一个问题的过程,机器学习是一个从已知数据发现、学习潜在规律的过程。
《中国新说唱》冠军的预测,其实就是从过去两届的比赛分析出特征与结果的关系,让模型学习出来往届的冠军有什么特点,并计算这一届哪个选手最接近这个特点,从而实现预测的能力。
从这个例子可以看出来,产品经理在AI项目的研发过程中发挥着巨大的作用:
在前期寻找场景,评估需求的阶段,产品经理首先需要评估现在面对的问题,有没有合适的技术手段可以解决。
想要预测《中国新说唱》谁是冠军,必须要有合适的方法才能解决问题。如果目前的技术不足以支持预测,那么是否可以用机器学习的方式分析出往届冠军具备什么样的特点,或者是哪种类型的歌曲更受大众欢迎。
在模型研发的准备阶段,产品经理需要结合技术与现实场景之间的关系,思考这个模型需要什么样的数据,哪些数据更重要,哪些数据对模型可能更有帮助。
如果我们将数据全部丢给工程师,最后模型出来的结果肯定不会太好——因为工程师不知道不同押韵技巧之间的差别,也不知道哪种方式能够体现不同选手的强弱;只有产品经理才能根据自身对场景以及需求的理解提供有效的帮助。
想要做到以上几点,成为一位合格的AI产品经理有一个大前提:首先得成为一位懂技术的产品经理。
我刚开始接触人工智能的时候,学习算法的过程非常痛苦:国内外所有与人工智能相关的教材几乎都是面向工程师编写的,通篇都是公式的推导与计算,很少有老师能将原理讲通透,将场景讲明白——这对于产品经理来说可不友好,晦涩难懂的公式实在是难以下咽。
2018年,在电子工业出版社郑柳洁编辑的盛情邀请下,我便萌生了为产品经理写一本算法入门书的想法。
在写作过程中,我一直在思考采用什么形式才能将算法的本质讲得通俗易懂,减少读者学习的压力。最终决定以案例讲原理,用生动的比喻代替枯燥的公式,让产品经理更容易接受、更容易理解。
这也是这本书起名《产品经理进阶:100个案例搞懂人工智能》的原因。
如果你想成为人工智能领域的产品经理,但又不懂技术、不懂算法,那么本书能够让你对人工智能的算法与应用有新的认知和理解,不会再觉得人工智能是一个高不可攀、遥不可及的领域。
相反,人工智能是普通人也可以理解、学习和实现的,没有技术背景的产品经理也能通过学习此书,成为一名优秀的人工智能产品经理。
今天,人人都是产品经理联合出版社给大家带来《产品经理进阶:100个案例搞懂人工智能》首发优惠,可以通过5折专属优惠直接购买,也可以通过参与活动免费获得哦~
留言赠书
懂人工智能的产品经理,在职场上有多少优势?
在评论中留下你的高质量留言,截至到8月27日零点,点赞数不少于40个且处于前5名的用户将赠送《产品经理进阶:100个案例搞懂人工智能》一本。
专属优惠
本书为人人都是产品经理/起点学院联合推荐,由平安科技资深产品经理林中翘力作,七大机器学习基础算法,深度学习应用、自然语言处理等应知应会,你都能在书中找到答案。
今日首发,5折特惠回馈用户,仅限今天,限量100本,先到先得:

▼ 点击“阅读原文”立即抢购