单机超越分布式?!强化学习新姿势,并行环境模拟器EnvPool实现速度成本双赢
机器之心编辑部
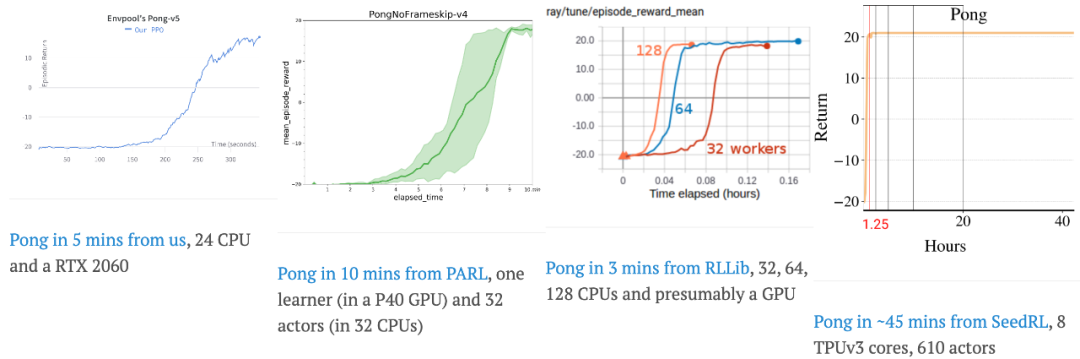
在训练强化学习智能体的时候,你是否为训练速度过慢而发愁?又是否对昂贵的大规模分布式系统加速望而却步?来自 Sea AI Lab 团队的最新研究结果表明,其实鱼和熊掌可以兼得:对于强化学习标准环境 Atari 与 Mujoco,如果希望在短时间内完成训练,需要采用数百个 CPU 核心的大规模分布式解决方案;而使用 EnvPool,只需要一台游戏本就能完成相同体量的训练任务,并且用时不到 5 分钟,极大地降低了训练成本。

-
项目地址:https://github.com/sail-sg/envpool -
在线文档:https://envpool.readthedocs.io/en/latest/ -
arXiv 链接:https://arxiv.org/abs/2206.10558
-
Atari games -
Mujoco(gym) -
Classic control RL envs: CartPole, MountainCar, Pendulum, Acrobot -
Toy text RL envs: Catch, FrozenLake, Taxi, NChain, CliffWalking, Blackjack -
ViZDoom single player -
DeepMind Control Suite
-
对于上游的强化学习环境而言,目前最多使用的是 OpenAI Gym,其次是 DeepMind 的 dm_env 接口。EnvPool 对两种环境 API 都完全支持,并且每次 env.step 出来的数据都是经过 numpy 封装好的,用户不必每次手动合并数据,同时也提高了吞吐量; -
对于下游的强化学习算法库而言,EnvPool 支持了目前 PyTorch 最为流行的两个算法库 Stable-baselines3 和 Tianshou,同时还支持了 ACME、CleanRL 和 rl_games 等强化学习算法库,并且达到了令人惊艳的效果(在笔记本电脑上,2 分钟训练完 Atari Pong、5 分钟训练完 Mujoco Ant/HalfCheetah,并且通过了 Gym 原本环境的验证)。
import numpy as np, envpoolenv = envpool.make_gym("Pong-v5", num_envs=100)observation_space = env.observation_spaceaction_space = env.action_space
obs = env.reset() # should be (100, 4, 84, 84)act = np.zeros(100, dtype=int)obs, rew, done, info = env.step(act)
while True:act = policy(obs)obs, rew, done, info = env.step(act, env_id)env_id = info["env_id"]
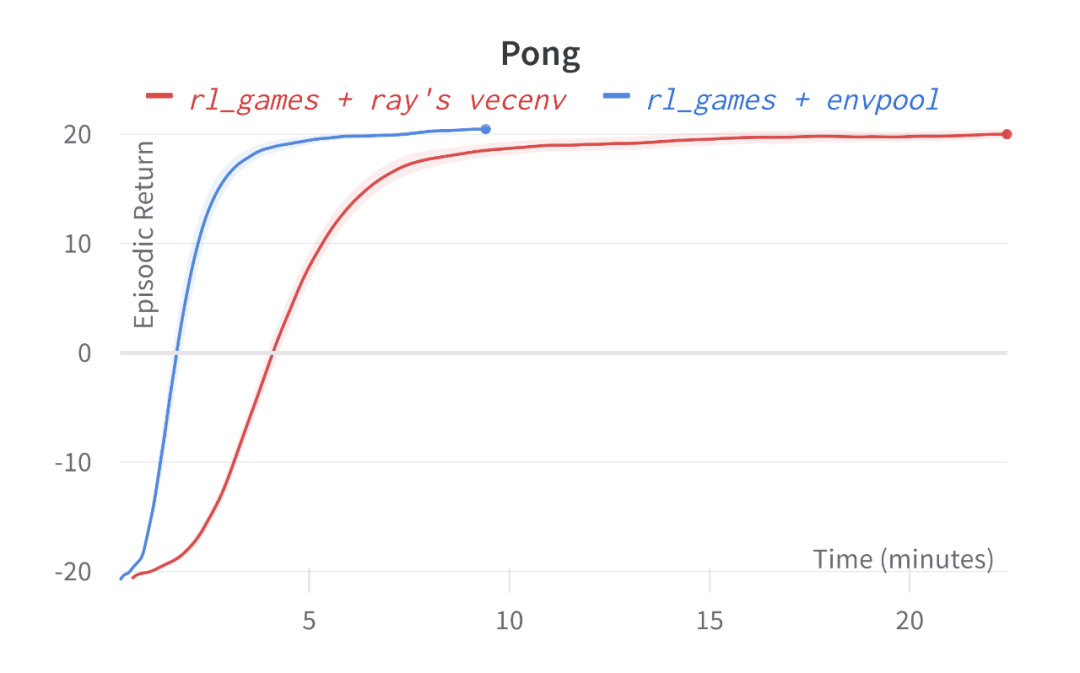
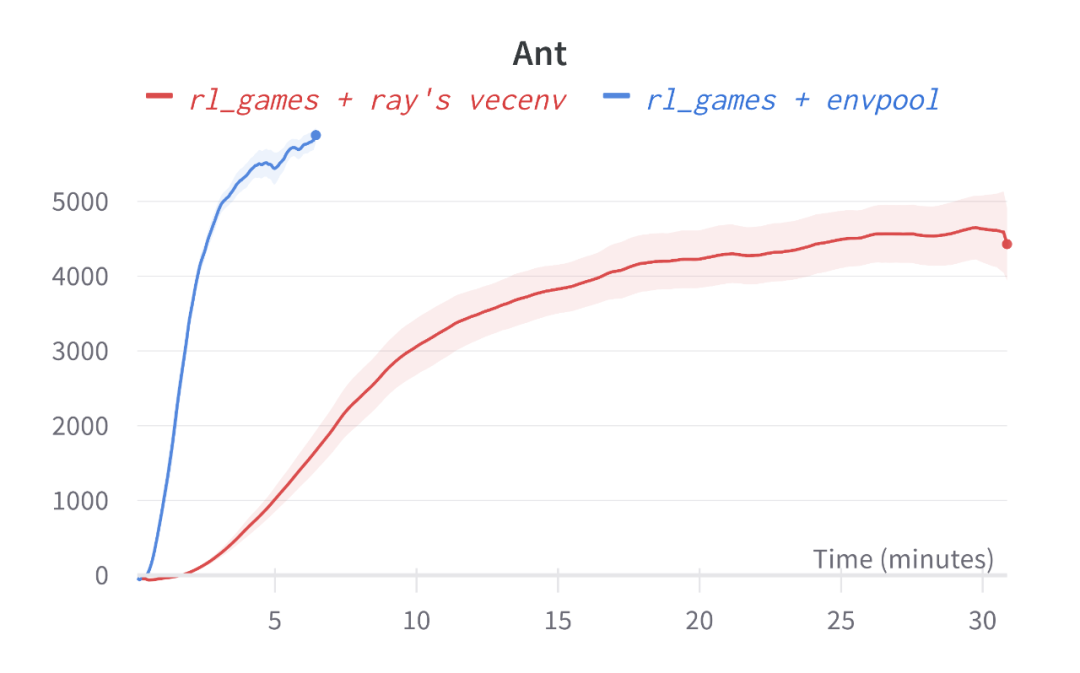
-
Pong:https://colab.research.google.com/drive/1iWFv0g67mWqJONoFKNWUmu3hdxn_qUf8?usp=sharing -
Ant:https://colab.research.google.com/drive/1C9yULxU_ahQ_i6NUHCvOLoeSwJovQjdz?usp=sharing
-
OS: Debian GNU/Linux 11 (bullseye) x86_64 -
Kernel: 5.16.0-0.bpo.4-amd64 -
CPU: AMD Ryzen 9 5950X (32) @ 3.400GHz -
GPU: NVIDIA GeForce RTX 3080 Ti -
Memory: 128800MiB
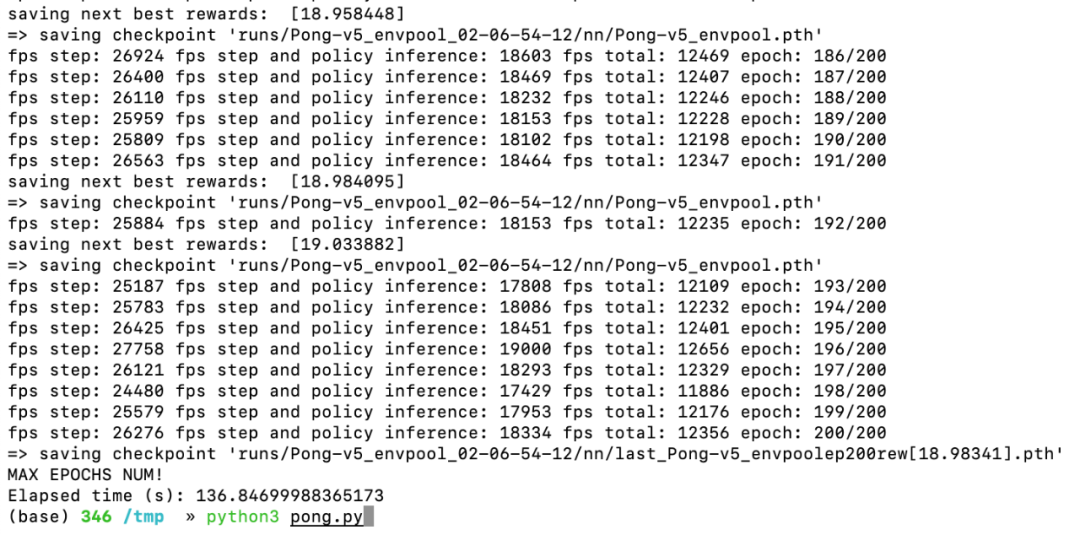
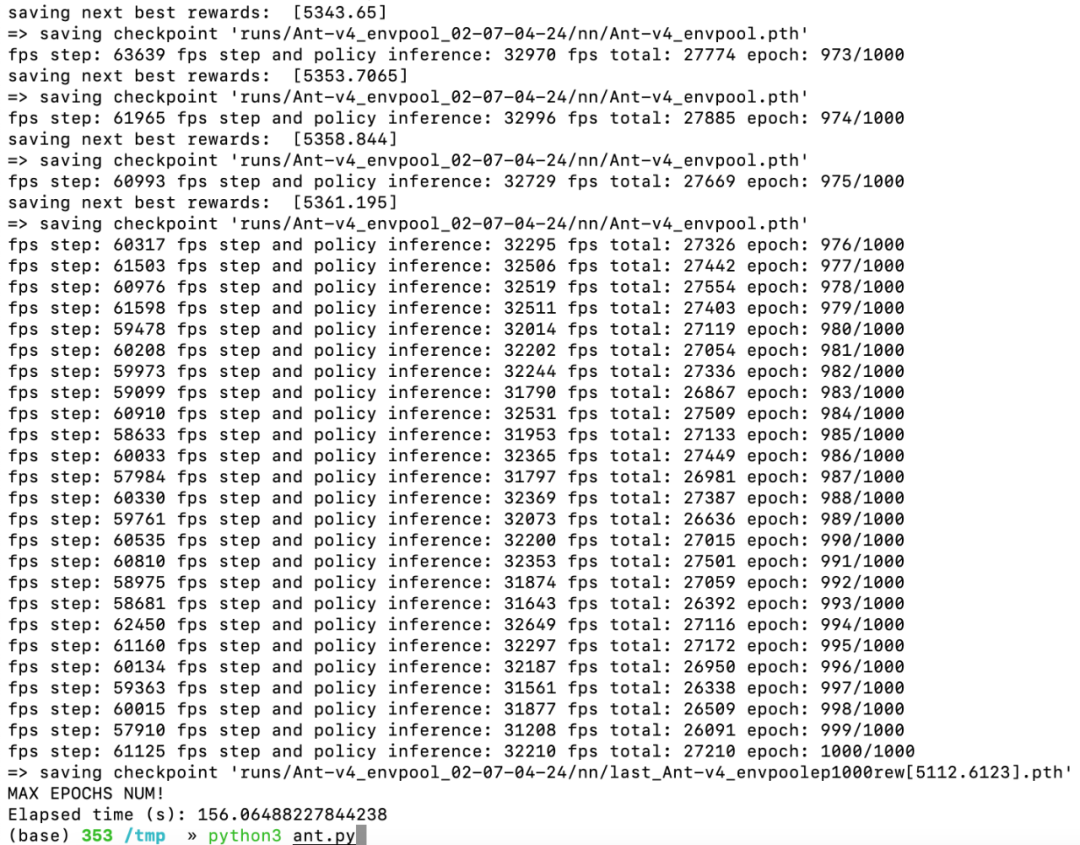

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
登录查看更多
相关内容
Arxiv
0+阅读 · 2022年9月6日
Arxiv
0+阅读 · 2022年9月6日
Arxiv
0+阅读 · 2022年9月5日
Arxiv
0+阅读 · 2022年9月5日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年9月6日
Arxiv
0+阅读 · 2022年9月6日
Arxiv
0+阅读 · 2022年9月5日
Arxiv
0+阅读 · 2022年9月5日