FedJAX:使用 JAX 进行联邦学习模拟


发布人:Google Research 软件工程师 Jae Hun Ro 和 研究员 Ananda Theertha Suresh
联邦学习是一种机器学习设置,允许多个客户端(即移动设备或者整个组织,取决于正在参与的任务)在一个中央服务器的编排下,协同训练同一个模型,同时还能保持训练数据的离散性。例如,通过联邦学习,可以基于永远不会从移动设备中消失的用户数据训练虚拟键盘语言模型。
联邦学习
https://ai.googleblog.com/2017/04/federated-learning-collaborative.html
训练虚拟键盘语言模型
https://arxiv.org/abs/1811.03604
要实现这点,联邦学习算法首先需要初始化服务器中的模型,然后完成以下对于每一轮训练而言都非常关键的三步:
1. 服务器将模型发送到一组采样客户端。
2. 这些采样客户端在本地数据中训练模型。
3. 训练完成之后,客户端将更新后的模型发送到服务器,然后服务器将所有这些模型汇总在一起。
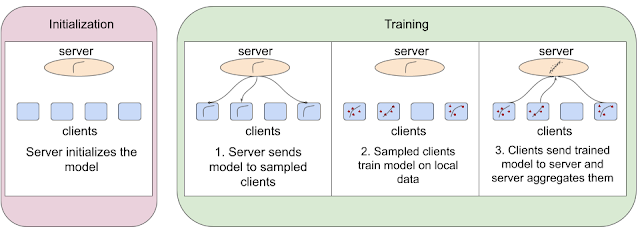
一个拥有四个客户端的联邦学习算法示例
随着人们对隐私和安全的日益注重,联邦学习已成为一个尤为活跃的研究领域。对于这个日新月异的领域,能够轻松将想法转换为代码、快速迭代,以及比较和复制现有基线的重要性不言而喻。
日新月异的领域
https://research.google/pubs/pub49232/
因此,我们很高兴为大家介绍 FedJAX。FedJAX 是一个基于 JAX 的开源库,适用于注重研究易用性的联邦学习模拟。FedJAX 拥有适用于执行联邦算法、预打包的数据集、模型和算法以及高模拟速度的简单基本模块,旨在让研究员能够更快速、更容易地开发和评估联邦算法。
FedJAX
https://github.com/google/fedjax
JAX
https://github.com/google/jax
在这篇文章中,我们将讨论 FedJAX 的库结构和内容。我们会证明,在 TPU 中,FedJAX 可通过 EMNIST 数据集的联合平均,在几分钟内就能训练完模型。而通过 Stack Overflow 数据集的标准超参数 (Hyperparameter),则需要将近 1 小时。
EMNIST
https://github.com/google/fedjax/blob/main/fedjax/datasets/emnist.py
联合平均
https://fedjax.readthedocs.io/en/latest/fedjax.algorithms.html#module-fedjax.algorithms.fed_avg
Stack Overflow
https://github.com/google/fedjax/blob/main/fedjax/datasets/stackoverflow.py


FedJAX 注重易用性,因此仅引进了少量新概念。使用 FedJAX 编写的代码与学术论文用于描述新颖算法的伪代码类似,因此极易上手。除此之外,虽然 FedJAX 提供了联邦学习的基本模块,但用户可以将其替换为最基本的实现(仅使用 NumPy 和 JAX),并且仍然可以将整体训练速度保持在一个合理的区间。
与学术论文用于描述新颖算法的伪代码类似
https://github.com/google/fedjax/blob/main/README.md#quickstart
NumPy
https://numpy.org/
在当前联邦学习研究领域,存在各种各样常用的数据集和模型,例如图像识别 (Image recognition)、语言建模 (Language modeling) 等。越来越多这样的数据集和模型无需安装即可直接用于 FedJAX,因此用户无需从头开始编写预处理数据集和模型。这不仅有利于对不同的联邦算法进行有效比较,还加速了新算法的开发。
目前,FedJAX 与以下数据集和示例模型一起打包:
EMNIST-62,一项字符识别任务
https://github.com/google/fedjax/blob/main/fedjax/datasets/emnist.py
Shakespeare,一项下一字符预测任务
https://github.com/google/fedjax/blob/main/fedjax/datasets/shakespeare.py
Stack Overflow,一项下一字词预测任务
https://github.com/google/fedjax/blob/main/fedjax/datasets/stackoverflow.py
除了以上标准设置,FedJAX 还提供用于创建新数据集和模型的工具,这些新数据集和模型可以与库的其余内容共同使用。
工具
https://fedjax.readthedocs.io/en/latest/fedjax.html#federated-data
此外,FedJAX 支持联合平均的标准实现,也支持用于在分散式示例上训练共享模型的其他联邦算法,例如自适应联邦优化器、不可知联合平均以及 Mime,从而让比较和评估现有算法变得更加简单。
自适应联邦优化器
https://fedjax.readthedocs.io/en/latest/fedjax.algorithms.html#module-fedjax.algorithms.fed_avg
不可知联合平均
https://fedjax.readthedocs.io/en/latest/fedjax.algorithms.html#module-fedjax.algorithms.agnostic_fed_avg
Mime
https://fedjax.readthedocs.io/en/latest/fedjax.algorithms.html#module-fedjax.algorithms.mime
我们在两项任务上对自适应联合平均的标准 FedJAX 实现进行了基准测试:图像识别任务(测试联邦 EMNIST-62 数据集)和下一字词预测任务(测试 Stack Overflow 数据集)。联邦 EMNIST-62 数据集较小,由 3400 名用户和他们创建的示例(共 62 个拉丁字母数字字符)构成;而 Stack Overflow 数据集较大,由数百万问题和答案构成(这些问题和答案来自于拥有成千上万名用户的 Stack Overflow 论坛)。
自适应联合平均
https://openreview.net/pdf?id=LkFG3lB13U5
联邦 EMNIST-62 数据集
https://github.com/google/fedjax/blob/main/fedjax/datasets/emnist.py
Stack Overflow 数据集
https://github.com/google/fedjax/blob/main/fedjax/datasets/stackoverflow.py
我们在专门用于机器学习的各种硬件上测量性能。对于联邦 EMNIST-62,我们在 GPU (NVIDIA V100) 和 TPU(Google TPU v2 上的 1 个 TensorCore)加速器上对单一模型进行了 1500 轮训练(每轮 10 个客户端)。
对于 Stack Overflow,我们在 GPU (NVIDIA V100)、单核 TPU(Google TPU v2 上 1 个 TensorCore)及多核 TPU(Google TPU v2 上 8 个 TensorCore)上对单一模型进行了 1500 轮训练(每轮 50 个客户端)。其中,在 GPU 上使用 jax.jit,在单核 TPU 上仅使用 jax.jit,而在多核 TPU 上使用 jax.pmap。在下方图表中,我们记录了每轮训练的平均完成时间、完整评估测试数据所需时间以及整体执行时间(整体执行包含训练和完整评估)。
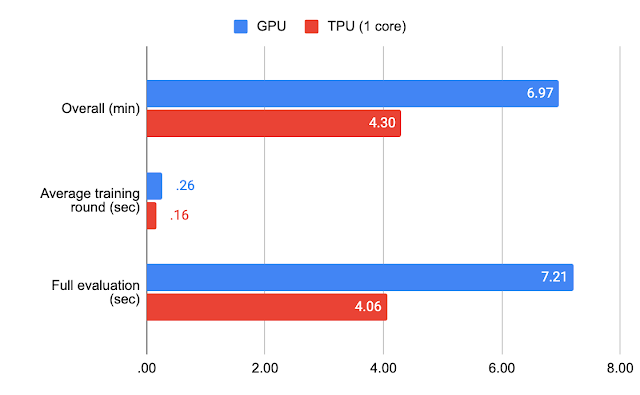
联邦 EMNIST-62 的基准测试结果
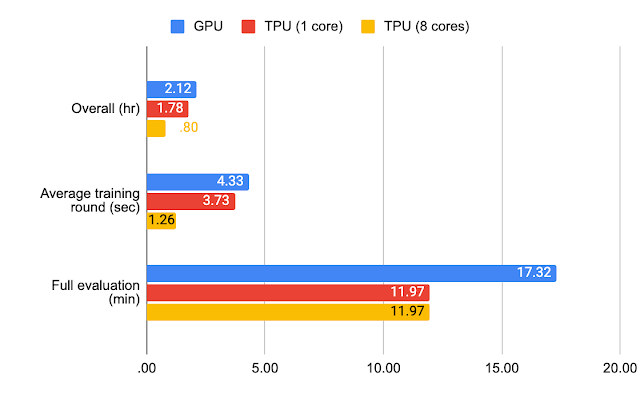
Stack Overflow 的基准测试结果
通过标准超参数和 TPUs,联邦 EMNIST-62 的整个实验可以在几分钟之内完成,而 Stack Overflow.的实验需要 1 小时左右的时间。
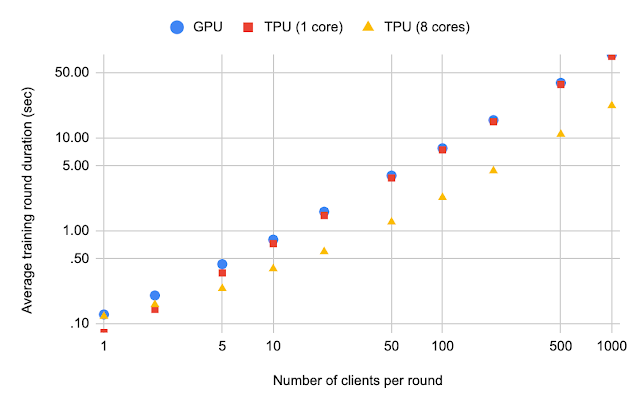
随着每轮客户端数量增加, Stack Overflow 的平均每轮训练时长
我们还评估了随着每轮客户端数量增加之后的 Stack Overflow 平均每轮训练时长。通过比较图表上 8 核 TPU 与单核 TPU 的平均每轮训练时长,我们很容易就能发现,如果每轮参与的客户端数量较多,则使用多核 TPU 能极大缩短运行时间(对微分化的不公开学习等应用来说非常有帮助)。
微分化的不公开学习
https://openreview.net/forum?id=BJ0hF1Z0b
在这篇文章中,我们介绍了 FedJAX 这种适用于研究、速度较快且简单易用的联邦学习模拟库。我们希望 FedJAX 能推动联邦学习的深入研究,同时引起人们对于该领域的更多关注。未来,我们计划继续发展现有算法集、聚合机制、数据集和模型。
欢迎各位随时查阅我们的教程笔记本,或者亲自体验 FedJAX!
教程笔记本
https://fedjax.readthedocs.io/en/latest/
亲自体验 FedJAX
https://github.com/google/fedjax/blob/main/examples
若想进一步了解 FedJAX 及其与 Tensorflow Federated 等平台的关系,请参阅我们的论文、README 或常见问题解答。
Tensorflow Federated
https://tensorflow.google.cn/federated
论文
https://arxiv.org/abs/2108.02117
README
https://github.com/google/fedjax/blob/main/README.md
常见问题解答
https://github.com/google/fedjax/blob/main/FAQ.md
感谢 Ke Wu 和 Sai Praneeth Kamireddy 在开发期间对 FedJAX 与各种讨论作出的贡献。
也感谢 Ehsan Amid、Theresa Breiner、Mingqing Chen、Fabio Costa、Roy Frostig、Zachary Garrett、Alex Ingerman、Satyen Kale、Rajiv Mathews、Lara Mcconnaughey、Lara Mcconnaughey、Brendan McMahan、Mehryar Mohri、Krzysztof Ostrowski、Max Rabinovich、Michael Riley、Vlad Schogol、Jane Shapiro、Gary Sivek、Luciana Toledo-Lopez 以及 Michael Wunder 提供的宝贵意见和贡献。

推荐阅读



点击“阅读原文”访问 TensorFlow 官网

不要忘记“一键三连”哦~

分享

点赞

在看




