微软:我已把显存优化做到了极致,还有谁?

文 | 王思若
大家好,我是王思若。
17年6月Google提出了Transformer架构,这篇目前Citation 4.3万的文章开启了大规模预训练模型时代。
或者,更精确的从18年OpenAI和Google分别基于其中的Decoder和Encoder发布的大规模预训练模型GPT1和BERT开始,各色千亿,万亿模型就在这方舞台上你方唱罢我登场。
20年千亿参数GPT-3, 21年万亿参数Switch Transformer...
巨量参数的大模型不断刷榜各项榜单。
那时候我问实验室小伙伴,你的梦想是什么?他们说训练预训练大模型是每个男孩心中的梦。
确实,这是一个有“一丢丢”昂贵的梦想,Google用2048块TPU训练了Switch Transformer,NVIDIA用4480块A100训练了Megatron(威震天),巨大的计算资源的消耗让这些巨头都有些承担不起。
如何加快模型训练,为万亿级参数的大模型预训练寻找最优解成为了一个热点问题。
而 ZeRO-Offload,作为一种新颖的异构深度学习训练技术,可在单GPU上就可以训练数十亿参数的模型,微软自信表示ZeRO-Offload是目前的最优解:
In fact, ZeRO-Offload can achieve high efficiency during training that is comparable to non-offload training and it is unique optimal, meaning no other solution can offer better memory savings without increasing the communication volume or increasing CPU computation.
那我们就根据这篇文章为矛头追溯一下万亿级参数模型训练优化的漫漫探索之路。值得收藏的干货长文!
论文标题:
ZeRO-Offload: Democratizing Billion-Scale Model Training
论文链接:
https://arxiv.org/pdf/2101.06840.pdf
1. 并行技术
大规模模型优化的本质就是加大并行度,分布式超大规模模型并行技术主要包括:
-
数据并行 Data Parallelism -
模型并行 Tensor Model Parallelism -
流水并行 Pipeline Model Parallelism
数据并行是最通用的并行方式,例如,PyTorch官方提供了DDP(DistributedDataParallel)接口便于用户使用,为每张卡分配不同的数据,多张卡通过Ring Allreduce方法汇总梯度进而对参数进行更新。
模型并行是对Tensor进行切分,每张卡都只是对Tensor的一部分进行操作,最后合并多张卡的结果即可。
流水线并行是按照模型Stage进行划分,将模型的不同层放到不同的计算设备上,降低单个设备的显存消耗,从而训练更大参数的模型。
最简单的模型并行见下图:
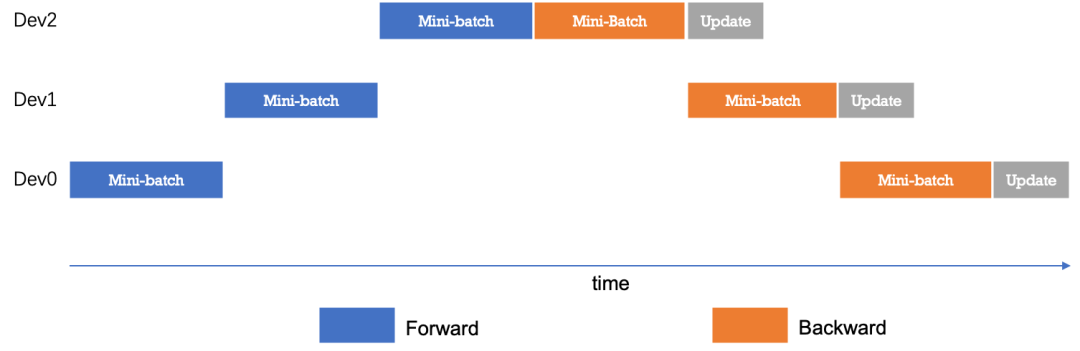
处理一个mini-batch的数据时候只有一台设备处于计算状态,这样设备利用率太差,进一步对mini-batch数据进行划分得到更小粒度的micro-batch,可以很大的提升流水线并行的并发度。
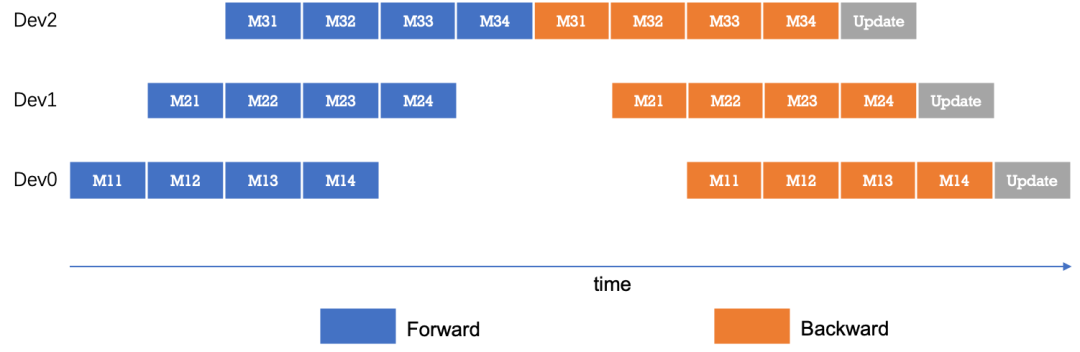
采用梯度累加Gradient Accumulation的方式进行模型训练,得到多个micro-batch的数据训练之后的结果进行梯度累加再去对参数进行更新,似乎看起来并行度已经足够满足要求了,但是这种方法还有非常棘手的问题需要去解决!
每一个micro-batch都会产生前向传播的中间结果(activation)并占据了大量的显存,基于此,陈天奇在《Training Deep Nets with Sublinear Memory Cost》中提出了 Checkpointing(重计算) 和 CPU offload(CPU 卸载) 。
思路很简单,面对Out of Memory, 你愿意用什么来换取减少显存的机会?红蓝药丸选择一个?

Checkpointing选择用额外的计算开销换取显存,本质上很简单,即在前向网络中只保存标记的少量的Tensor(checkpointing的tensor),其余的会在反向传播的时候根据checkpoing的tensor临时重新计算一遍前向得到。
去年在蛋白质结构预测上大放异彩的AlphaFold2就选择了Checkpointing方法来减少显存占用,既然显存不够大,那就浪费点时间嘛。
CPU offload 选择用额外的通讯开销来换取显存, 对于前向传播的中间结果(activation),暂时用不到就先放到内存中(Host Memory),等计算需要的时候再放到显存中,用大量的I/O时间来换取显存。
2. ZeRO (Zero Redundancy Optimizer)
其实很大的痛点是上述的各个方法解释起来如此简单,但是实现的时候对于非分布式训练专家的普通用户却根本无从下手,为了便于用户使用,各个公司都开源了自己的解决方案。
-
NVIDIA 发布了5300亿的威震天Megatron,同时发布了自己的并行化框架 Megatron-LM -
微软提出了ZeRO算法,并借用 Megatron-LM开发了分布式并行框架DeepSpeed -
Google的MeshTensorFlow/Gpipe/Gshard -
FaceBook的FSDP -
百度PaddlePaddle,华为Mindspore,一流科技的Oneflow ...
其中,微软在20年提出的ZeRO算法是其中及其经典的一环,将数据和计算从GPU卸载到CPU中来换取显存,ZeRO-Offload基于该算法进行的改进。
首先,提问一个有意思的现:对于1.5Billion模型参数的GPT-2,使用FP16进行存储只需要3GB内存,但是在模型训练的时候,对于单卡32GB显存依然不能满足模型训练的需求。我们需要思考一个问题:模型训练的时候什么在大量的占用显存?
其实包括四部分:模型权重(Model weights),梯度(Gradients),优化器(Optimizer state)以及前向传播的Activation。
如果采取常用的Adam优化器,以混合精度训练为例,对于10亿 (1 Billion)参数量的模型,其权重和梯度是以FP16(两字节)进行存储的,因此分别需要2GB的存储空间。
并且,为了在后向传播结束后高效的更新参数,要求Adam优化器需要保存FP32的参数和梯度副本、一阶矩样本均值和二阶矩样本方差,又分别需要4GB显存。
这样对于10亿参数的模型,虽然模型参数仅2GB,但是模型训练的时候至少需要20GB的内存。
并且对于每一台机器都需要消耗固定相同的全量内存,出现了严重的内存冗余现象。
既然我们了解了什么在占用大量的内存,ZeRO又是怎么对其进行优化的呢?
每块GPU没必要承担全量内存,可以让上述的内存平均分配到每块GPU上,这样每块GPU只承担模型的一部分即可。
论文将深度学习的内存消耗主要分为三种:Optimizer(优化器状态)、Gradients(梯度)和Parameters(参数)。
这三部分可以部分或者全部平均分配到各个GPU中,ZeRO提出了三种方式:
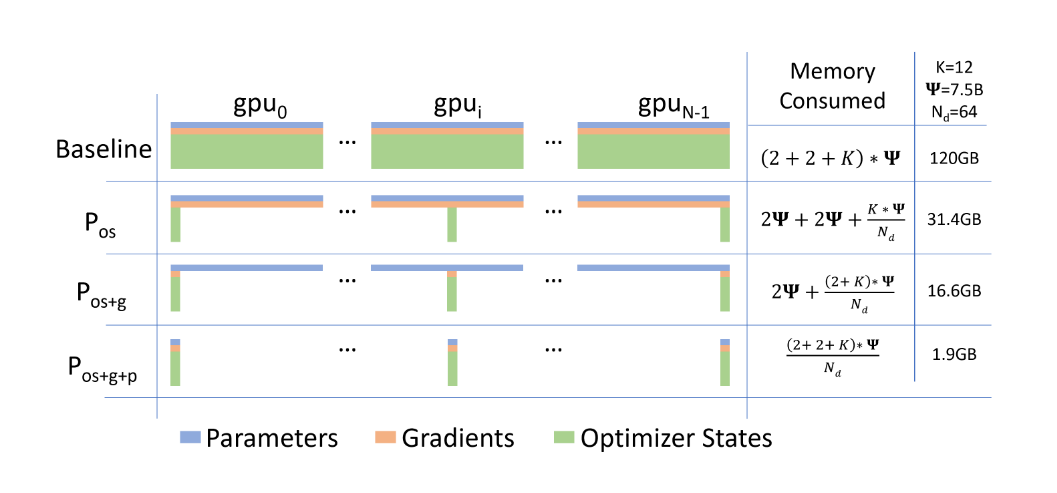
:只将优化器状态进行平均划分。
: 将梯度和优化器状态进行平均划分。
: 将优化器状态,梯度和参数都进行平均划分。
为了形象说明ZeRO的训练流程,以图示的方式展示 (对优化器状态,梯度和参数都进行平均划分)的流程:
以8层Transformer架构的模型在4块GPU上进行训练为例,模型进行数据的并行训练,如果不进行ZeRO的模型优化,每块GPU都需要保存的数据有:
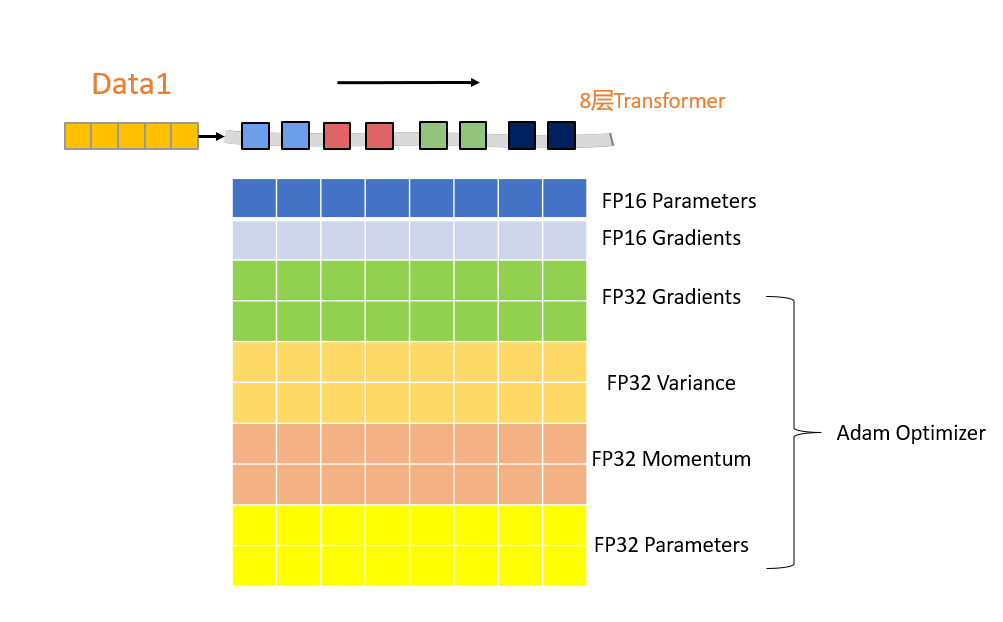
这里有8层Transformer,每一层都对应着相应的数据和参数。
如果模型采用混合精度进行模型训练,模型的参数和梯度都以FP16的形式进行存储,Adam优化器为了能够高效的更新参数,会保存FP32的参数和梯度副本,FP32的一阶矩动量和二阶矩方差。
如果有四块GPU,我们可以将上述的这些参数平均分配到每块GPU中,如下图所示:
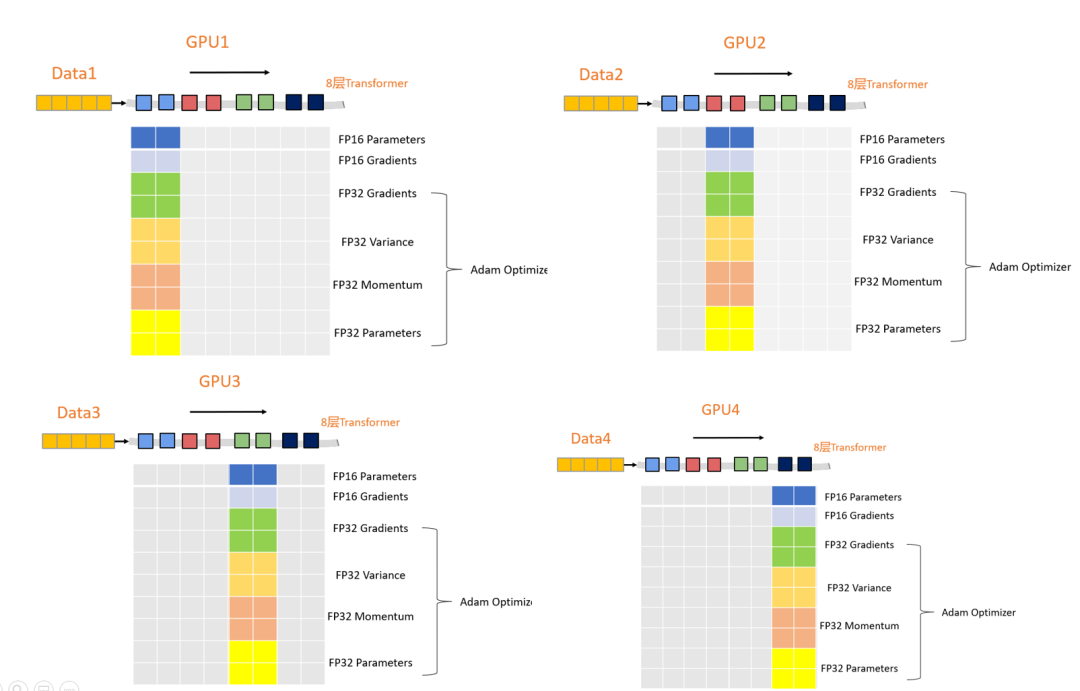
数据前向传播和反向更新参数只需要让保存数据的GPU向其他GPU广播数据即可,通过通信成本来大幅度的节省显存开销。
效果
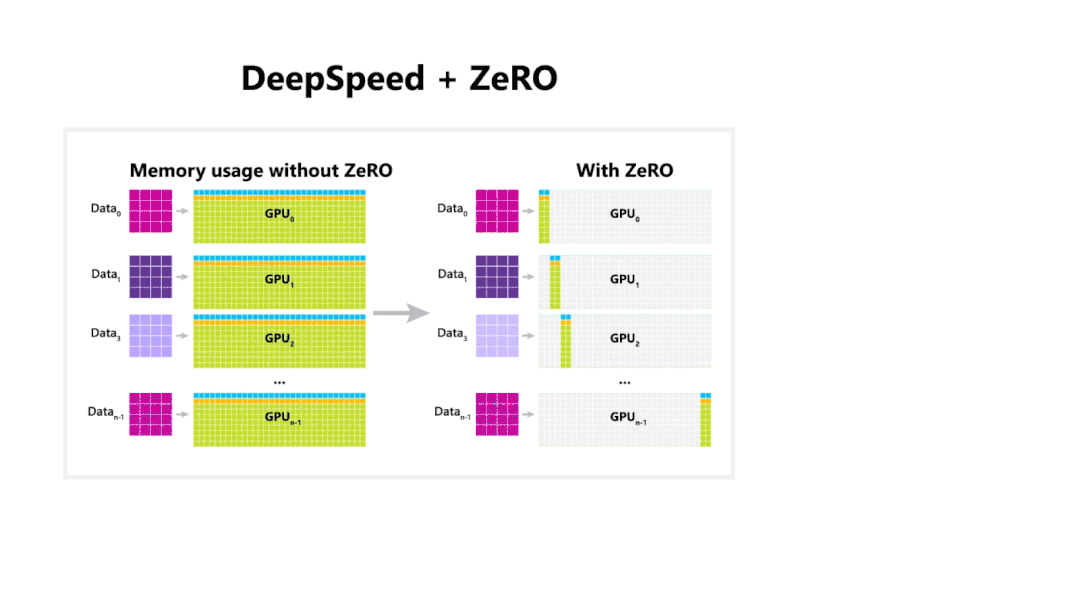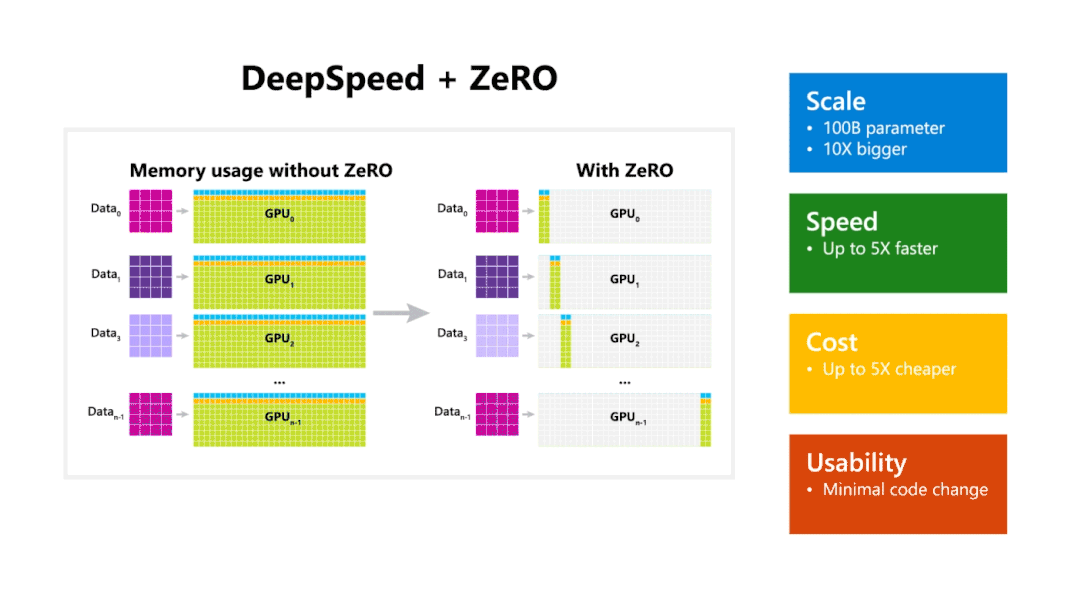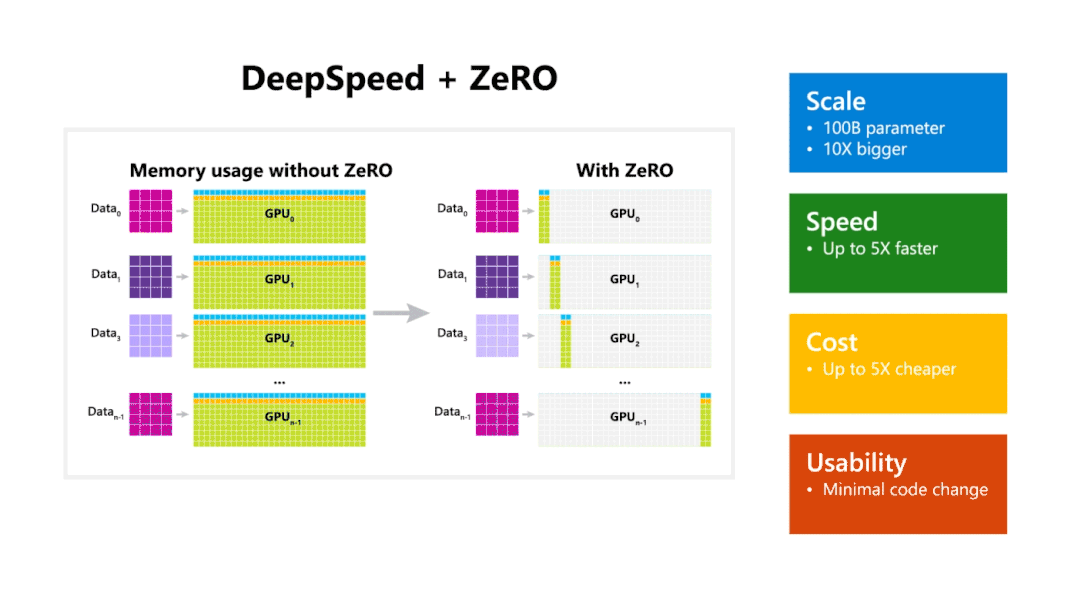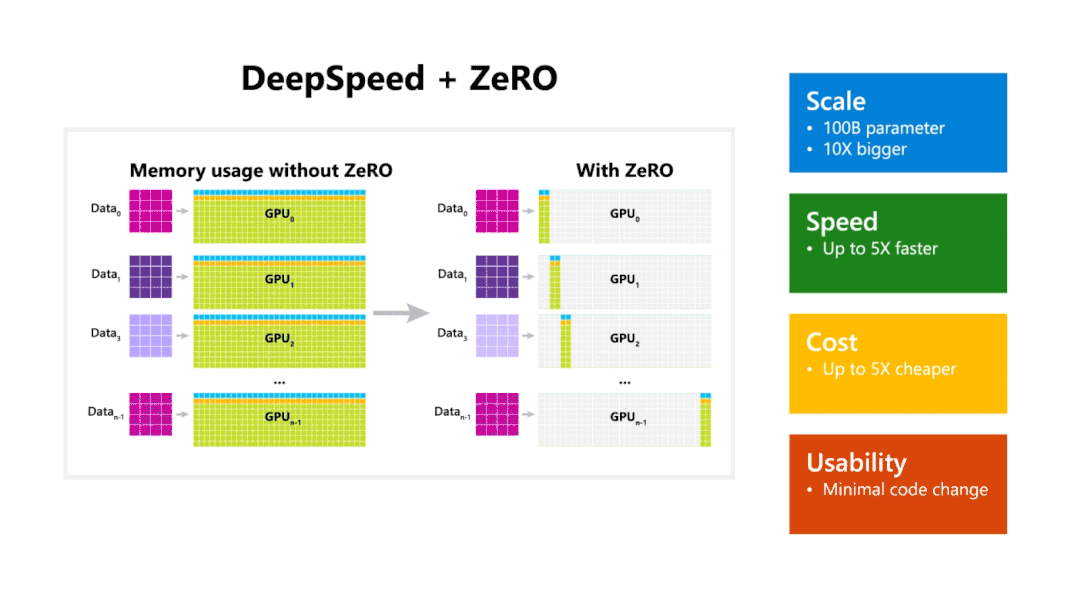
模型使用优化器状态分区 ,节省了4倍显存,和数据并行Baseline有相同通信量;再此基础上添加梯度分区那么 方法可以节省8倍显存,和数据并行Baseline有相同通信量;如果再对参数进行分区的 方法,内存减少量就和GPU数量 成线性关系,例如有64张GPU,显存会减少64倍,但相应的通信量会增加50%。
因此,我们可以看到,在 和 分区情况下,通信量没有增加, 虽然会增加50%的通信量,但是毫无疑问这三种方法都可以大幅度的节省显存开支。
3. ZeRO-Offload
ZeRO-offload是在ZeRO基础上进行的改进,最开始我们就说明了CPU offload即通过将显存卸载到CPU内存中来降低显存消耗,ZeRO + CPU offload其实就诞生了ZeRO-offload。
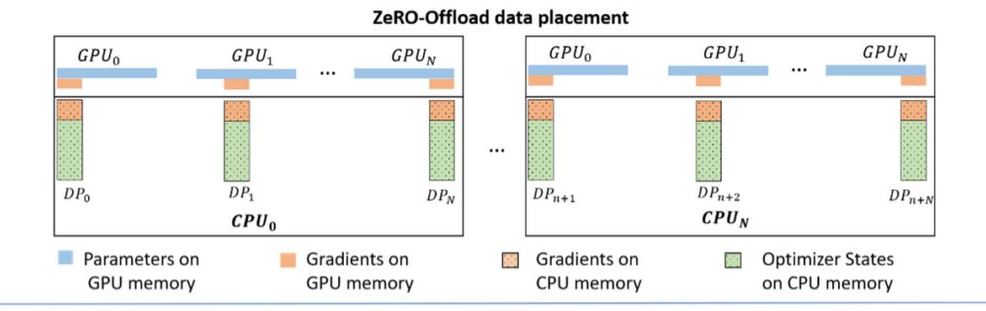
和ZeRO方法对比,ZeRO-Offload进一步把CPU内存(Host memory或CPU memory)纳入了考量,既然要省显存,那不如就多省一些,把占大头的优化器状态数据放到CPU内存中不就行了。
这里,微软提供了自己实验验证最优的一份方案:
模型训练期间,模型参数(Parameters)不会进行分割并保存在GPU中;梯度(Gradients)和ZeRO的方式一致,按照GPU进行平均分割,每个GPU都只保存梯度的一份;对于优化器状态(optimizer states)同样会对其进行分割并始终存储在CPU内存中。
下图就详细的展示了如何按照这种数据划分方式进行模型训练:
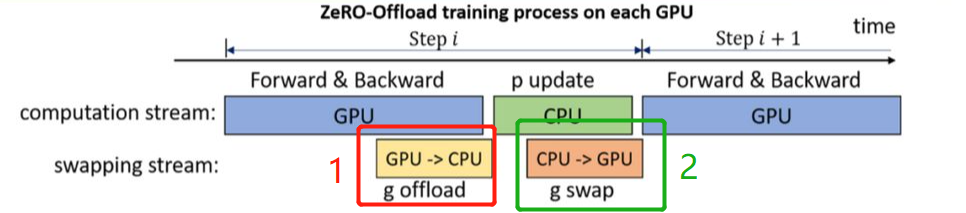
在前向传播的时候,模型参数并没有进行分割,每个GPU都单独保存着一份模型参数,每张卡喂入数据,计算各自的loss并反向传播更新梯度。
这里梯度是平均分配到每个GPU上的,对梯度进行reduce-scatter得到梯度平均值并卸载到CPU中。(上图红色框)
这里优化器状态都是在CPU中保存,更新完的梯度到达CPU中之后,每个数据并行线程直接在CPU中通过梯度和优化器对参数进行更新,并把参数加载到GPU中 (上图绿色框),通过all-gather返回到各个GPU中,从而完成了一次模型训练。
效果
Notice: Zero-Offload是专门为与 Adam 进行混合精度训练而设计的。特别是,当前版本使用了DeepCPUAdam,它是 Adam 的优化版本。使用这个优化器的主要原因是避免CPU计算成为整个过程的瓶颈。
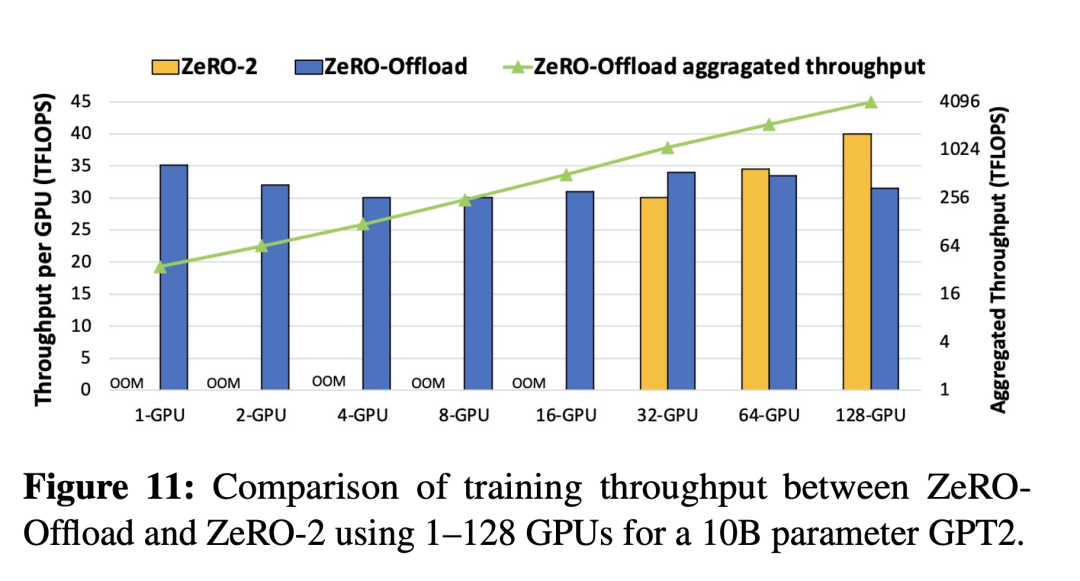
ZeRO-Offload在总吞吐量(绿色线)方面实现了近乎完美的线性加速。其次,从1到16块GPU,ZeRO-2会出现耗尽内存的情况(out of memory)但是ZeRO-Offload依然可以有效地训练模型,随着 GPU 数量的增加,每个 GPU 的吞吐量接近线性缩放。
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜广推与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
[1] ZeRO: https://arxiv.org/abs/1910.02054
[2] ZeRO-Offload: https://arxiv.org/pdf/2101.06840.pdf
[3] DeepCPUAdam: https://github.com/microsoft/DeepSpeed/tree/master/deepspeed/ops/adam
 后台回复关键词【入群】
后台回复关键词【入群】

