Pytorch - 分布式通信原语(附源码)

极市导读
本文用通过pytorch中的分布式原语库来介绍每个通信原语的行为表现,主要对point-2-point communication 和collective communication两种通信方式进行介绍,并附有相关代码。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
前言
由于工作需要,最近在补充分布式训练方面的知识。经过一番理论学习后仍觉得意犹未尽,很多知识点无法准确get到(例如:分布式原语scatter、all reduce等代码层面应该是什么样的,ring all reduce 算法在梯度同步时是怎么使用的,parameter server参数是如何部分更新的)。
著名物理学家,诺贝尔奖得主Richard Feynman办公室的黑板上写了:"What I cannot create, I do not understand."。在程序员界也经常有"show me the code"的口号。因此,我打算写一系列的分布式训练的文章,将以往抽象的分布式训练的概念以代码的形式展现出来,并保证每个代码可执行、可验证、可复现,并贡献出来源码让大家相互交流。
经过调研发现pytorch对于分布式训练做好很好的抽象且接口完善,因此本系列文章将以pytorch为主要框架进行,文章中的例子很多都来自pytorch的文档,并在此基础上进行了调试和扩充。
最后,由于分布式训练的理论介绍网络上已经很多了,理论部分的介绍不会是本系列文章的重点,我会将重点放在代码层面的介绍上面。
1 基本介绍
近些年随着深度学习的火爆,模型的参数规模也飞速增长,OpenAI数据显示:
-
2012年以前,模型计算耗时每2年增长一倍,和摩尔定律保持一致; -
2012年后,模型计算耗时每3.4个月翻一倍,远超硬件发展速度;
近一年来,百亿、千亿级的参数模型陆续面世,谷歌、英伟达、阿里、智源研究院更是发布了万亿参数模型。因此,大模型已经成为了未来深度学习的趋势。提到大模型,就不得不提分布式训练,由于模型参数和训练数据的不断增多,只有通过分布式训练才能完成大模型的训练任务。
分布式训练可以分为数据并行、模型并行,流水线并行和混合并行。分布式算法又有典型的parameter server和ring all-reduce。无论是哪一种分布式技术一个核心的关键就是如何进行communication,这是实现分布式训练的基础,因此要想掌握分布式训练或当前流行的大模型训练务必对worker间的通信方式有所了解。
互联网上已经有很多关于分布式训练的通信方面的文章,但是均没有代码层面的例子。我是属于比较愚钝类型的,只有通过自己手动实现一下方能对一些抽象的概念有较深的理解。
Pytorch的分布式训练的通信是依赖torch.distributed模块来实现的,torch.distributed提供了point-2-point communication 和collective communication两种通信方式。
-
point-2-point communication提供了send和recv语义,用于任务间的通信 -
collective communication主要提供了scatter/broadcast/gather/reduce/all_reduce/all_gather 语义,不同的backend在提供的通信语义上具有一定的差异性。
| Device | CPU | GPU | CPU | GPU | CPU | GPU |
| send | ✓ | ✘ | ✓ | ? | ✘ | ✘ |
| recv | ✓ | ✘ | ✓ | ? | ✘ | ✘ |
| broadcast | ✓ | ✓ | ✓ | ? | ✘ | ✓ |
| all_reduce | ✓ | ✓ | ✓ | ? | ✘ | ✓ |
| reduce | ✓ | ✘ | ✓ | ? | ✘ | ✓ |
| all_gather | ✓ | ✘ | ✓ | ? | ✘ | ✓ |
| gather | ✓ | ✘ | ✓ | ? | ✘ | ✘ |
| scatter | ✓ | ✘ | ✓ | ? | ✘ | ✘ |
| reduce_scatter | ✘ | ✘ | ✘ | ✘ | ✘ | ✓ |
| all_to_all | ✘ | ✘ | ✓ | ? | ✘ | ✓ |
| barrier | ✓ | ✘ | ✓ | ? | ✘ | ✓ |
2 P2P communication
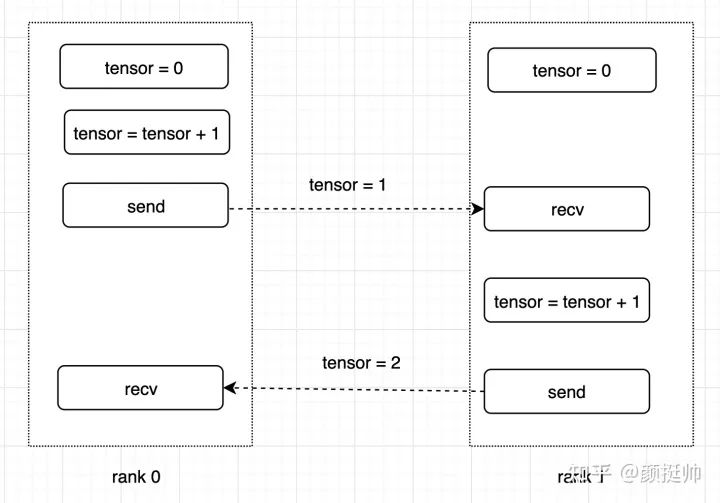
下面通过torch.distributed的send/recv接口实现一个简易的ping-pong 程序。程序功能如下:
-
tensor 初始值为0 -
process 0 (或叫rank 0):对tensor加1,然后发送给process 1(或叫rank1); -
process 1:接收到tensor后,对tensor 加2,然后在发送给process 0; -
process 0:接收process1发送的tensor;
2.1 初始化
pytorch中在分布式通信原语使用之前,需要对分布式模块进行初始化。pytorch的分布式模块通过torch.distributed.init_process_group来完成
-
通过环境变量
MASTER_ADDR和MASTER_PORT设置rank0的IP和PORT信息,rank0的作用相当于是协调节点,需要其他所有节点知道其访问地址; -
本例中后端选择的是gloo,通过设置
NCCL_DEBUG环境变量为INFO,输出NCCL的调试信息; -
init_process_group:执行网络通信模块的初始化工作 -
backend:设置后端网络通信的实现库,可选的为gloo、nccl和mpi;本例选择gloo作为backend(注:nccl不支持p2p通信,mpi需要重新编译pytorch源码才能使用); -
rank:为当前rank的index,用于标记当前是第几个rank,取值为0到work_size - 1之间的值; -
world_size: 有多少个进程参与到分布式训练中;
def init_process(rank_id, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank_id, world_size=size)
fn(rank_id, size)
2.2 通信逻辑
下面的代码展示了rank0和rank1进行ping-pong通信的实现:
-
通过rank_id来区分当前应该执行哪一个rank的业务逻辑;
-
pytorch 中通过
torch.distributed.send(tensor, dst, group=None, tag=0)和torch.distributed.isend(tensor, dst, group=None, tag=0)来实现tensor的发送,其中send是同步函数,isend是异步函数; -
tensor:要发送的数据 -
dst:目标rank,填写目标rank id即可 -
pytorch中通过
torch.distributed.recv(tensor, src=None, group=None, tag=0)和torch.distributed.irecv(tensor, src=None, group=None, tag=0)来实现tensor的接收,其中recv是同步函数,irecv是异步函数; -
tensor:接收的数据 -
src:接收数据来源的rank id
def run(rank_id, size):
tensor = torch.zeros(1)
if rank_id == 0:
tensor += 1
# Send the tensor to process 1
dist.send(tensor=tensor, dst=1)
print('after send, Rank ', rank_id, ' has data ', tensor[0])
dist.recv(tensor=tensor, src=1)
print('after recv, Rank ', rank_id, ' has data ', tensor[0])
else:
# Receive tensor from process 0
dist.recv(tensor=tensor, src=0)
print('after recv, Rank ', rank_id, ' has data ', tensor[0])
tensor += 1
dist.send(tensor=tensor, dst=0)
print('after send, Rank ', rank_id, ' has data ', tensor[0])
2.3 任务启动
通过下面的代码来启动两个process进行ping-pong通信:
-
这里使用 torch.multiprocessing来启动多进程,torch.multiprocessing是python库中multiprocessing的封装,并且兼容了所有的接口 -
multiprocessing.set_start_method : 用于指定创建child process的方式,可选的值为 fork、spawn和forkserver。使用spawn,child process仅会继承parent process的必要resource,file descriptor和handle均不会继承。 -
multiprocessing.Process(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None):用来启动child process
if __name__ == "__main__":
size = 2
processes = []
mp.set_start_method("spawn")
for rank in range(size):
p = mp.Process(target=init_process, args=(rank, size, run))
p.start()
processes.append(p)
for p in processes:
p.join()
2.4 测试
完整代码如下:
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def run(rank_id, size):
tensor = torch.zeros(1)
if rank_id == 0:
tensor += 1
# Send the tensor to process 1
dist.send(tensor=tensor, dst=1)
print('after send, Rank ', rank_id, ' has data ', tensor[0])
dist.recv(tensor=tensor, src=1)
print('after recv, Rank ', rank_id, ' has data ', tensor[0])
else:
# Receive tensor from process 0
dist.recv(tensor=tensor, src=0)
print('after recv, Rank ', rank_id, ' has data ', tensor[0])
tensor += 1
dist.send(tensor=tensor, dst=0)
print('after send, Rank ', rank_id, ' has data ', tensor[0])
def init_process(rank_id, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank_id, world_size=size)
fn(rank_id, size)
执行效果如下:
root@g48r13:/workspace/communication# python sync_p2p.py
after send, Rank 0 has data tensor(1.)
after recv Rank 1 has data tensor(1.)
after send Rank 1 has data tensor(2.)
after recv, Rank 0 has data tensor(2.)3 collective communication
3.1 broadcast
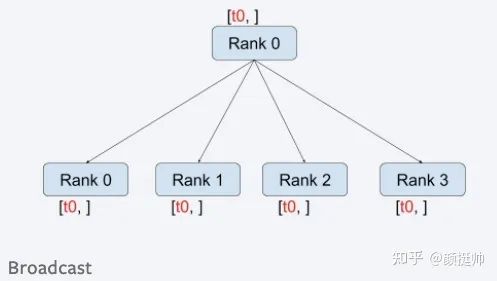
broadcast的计算方式如上图所示。
在pytorch中通过torch.distributed.broadcast(tensor, src, group=None, async_op=False) 来broadcast通信。
-
参数tensor在src rank是input tensor,在其他rank是output tensor; -
参数src设置哪个rank进行broadcast,默认为rank 0;
使用方式如下面代码所示:
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def run(rank_id, size):
tensor = torch.arange(2, dtype=torch.int64) + 1 + 2 * rank_id
print('before broadcast',' Rank ', rank_id, ' has data ', tensor)
dist.broadcast(tensor, src = 0)
print('after broadcast',' Rank ', rank_id, ' has data ', tensor)
def init_process(rank_id, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank_id, world_size=size)
fn(rank_id, size)
if __name__ == "__main__":
size = 4
processes = []
mp.set_start_method("spawn")
for rank in range(size):
p = mp.Process(target=init_process, args=(rank, size, run))
p.start()
processes.append(p)
for p in processes:
p.join()
输出内容为:
-
一共有4个rank参与了broadcast计算,计算之前:rank0 为[1, 2],rank1 为[3, 4], rank2为[5, 6], rank3为[7, 8] -
broadcast计算之后,所有rank的结果均rank0的tensor即[1, 2](因为在调用torch.distributed.broadcast时src设置为0,表示rank0进行broadcast)
before broadcast Rank 1 has data tensor([3, 4])
before broadcast Rank 0 has data tensor([1, 2])
before broadcast Rank 2 has data tensor([5, 6])
before broadcast Rank 3 has data tensor([7, 8])
after broadcast Rank 1 has data tensor([1, 2])
after broadcast Rank 0 has data tensor([1, 2])
after broadcast Rank 2 has data tensor([1, 2])
after broadcast Rank 3 has data tensor([1, 2])3.2 scatter
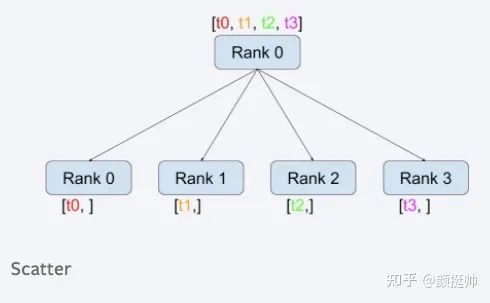
scatter的计算方式如上图所示。
在pytorch中通过torch.distributed.scatter(tensor, scatter_list=None, src=0, group=None, async_op=False) 来实现scatter通信。
-
参数tensor为除 src rank外,其他rank获取output tensor的参数 -
scatter_list为进行scatter计算tensor list -
参数src设置哪个rank进行scatter,默认为rank 0;
使用方式如下面代码所示:
-
这里需要注意的是,仅有src rank才能设置scatter_list( 本例中为rank 0),否则会报错
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def run(rank_id, size):
tensor = torch.arange(2, dtype=torch.int64) + 1 + 2 * rank_id
print('before scatter',' Rank ', rank_id, ' has data ', tensor)
if rank_id == 0:
scatter_list = [torch.tensor([0,0]), torch.tensor([1,1]), torch.tensor([2,2]), torch.tensor([3,3])]
print('scater list:', scatter_list)
dist.scatter(tensor, src = 0, scatter_list=scatter_list)
else:
dist.scatter(tensor, src = 0)
print('after scatter',' Rank ', rank_id, ' has data ', tensor)
def init_process(rank_id, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank_id, world_size=size)
fn(rank_id, size)
if __name__ == "__main__":
size = 4
processes = []
mp.set_start_method("spawn")
for rank in range(size):
p = mp.Process(target=init_process, args=(rank, size, run))
p.start()
processes.append(p)
for p in processes:
p.join()
输出内容为:
-
一共有4个rank参与了scatter计算,计算之前:rank0 为[1, 2],rank1 为[3, 4], rank2为[5, 6], rank3为[7, 8],scatter list为[0,0], [1,1], [2,2], [3,3]; -
scatter计算之后,rank按顺序被分配scatter list的每一个tensor, rank0为[0,0], rank1为 [1, 1] , rank2为 [2, 2], rank3[3, 3];
root@g48r13:/workspace/communication# python scatter.py
before scatter Rank 1 has data tensor([3, 4])
before scatter Rank 0 has data tensor([1, 2])
before scatter Rank 2 has data tensor([5, 6])
scater list: [tensor([0, 0]), tensor([1, 1]), tensor([2, 2]), tensor([3, 3])]
before scatter Rank 3 has data tensor([7, 8])
after scatter Rank 1 has data tensor([1, 1])
after scatter Rank 0 has data tensor([0, 0])
after scatter Rank 3 has data tensor([3, 3])
after scatter Rank 2 has data tensor([2, 2])3.3 gather
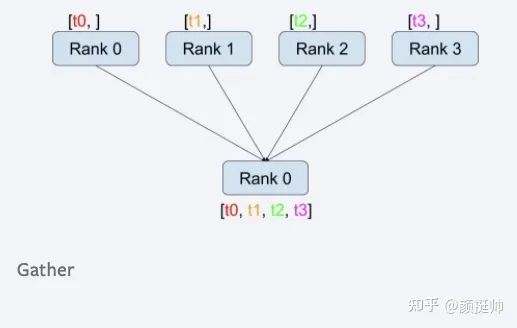
gather计算方式如上图所示。在pytorch中通过torch.distributed.gather(tensor, gather_list=None, dst=0, group=None, async_op=False) 来实现gather的通信;
-
参数tensor是所有rank的input tensor -
gather_list是dst rank的output 结果 -
dst为目标dst
使用方式如下:
-
这里需要注意的是在rank 0(也就是dst rank)中要指定gather_list,并且要在gather_list构建好的tensor,否是会报错
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def run(rank_id, size):
tensor = torch.arange(2, dtype=torch.int64) + 1 + 2 * rank_id
print('before gather',' Rank ', rank_id, ' has data ', tensor)
if rank_id == 0:
gather_list = [torch.zeros(2, dtype=torch.int64) for _ in range(4)]
dist.gather(tensor, dst = 0, gather_list=gather_list)
print('after gather',' Rank ', rank_id, ' has data ', tensor)
print('gather_list:', gather_list)
else:
dist.gather(tensor, dst = 0)
print('after gather',' Rank ', rank_id, ' has data ', tensor)
def init_process(rank_id, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank_id, world_size=size)
fn(rank_id, size)
if __name__ == "__main__":
size = 4
processes = []
mp.set_start_method("spawn")
for rank in range(size):
p = mp.Process(target=init_process, args=(rank, size, run))
p.start()
processes.append(p)
for p in processes:
p.join()
输出内容如下:
-
一共有4个rank参与了gather计算,计算之前:rank0 为[1, 2],rank1 为[3, 4], rank2为[5, 6], rank3为[7, 8] -
gather计算之后,gather_list的值为[tensor([1, 2]), tensor([3, 4]), tensor([5, 6]), tensor([7, 8])]
root@g48r13:/workspace/communication# python gather.py
before gather Rank 0 has data tensor([1, 2])
before gather Rank 3 has data tensor([7, 8])
after gather Rank 3 has data tensor([7, 8])
before gather Rank 1 has data tensor([3, 4])
before gather Rank 2 has data tensor([5, 6])
after gather Rank 1 has data tensor([3, 4])
after gather Rank 2 has data tensor([5, 6])
after gather Rank 0 has data tensor([1, 2])
gather_list: [tensor([1, 2]), tensor([3, 4]), tensor([5, 6]), tensor([7, 8])]3.4 reduce
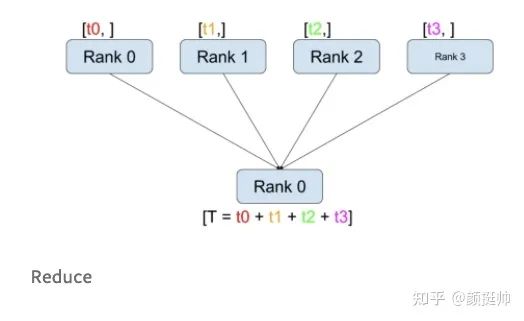
reduce的计算方式如上图所示。在pytorch中通过torch.distributed.reduce(tensor, dst, op=<ReduceOp.SUM: 0>, group=None, async_op=False)来实现reduce通信;
-
参数tensor是需要进行reduce计算的数据,对于dst rank来说,tensor为最终reduce的结果 -
参数dist设置目标rank的ID -
参数op为reduce的计算方式,pytorch中支持的计算方式有 SUM, PRODUCT, MIN, MAX, BAND, BOR, and BXOR
使用方式如下:
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def run(rank_id, size):
tensor = torch.arange(2, dtype=torch.int64) + 1 + 2 * rank_id
print('before reudce',' Rank ', rank_id, ' has data ', tensor)
dist.reduce(tensor, dst = 3, op=dist.ReduceOp.SUM,)
print('after reudce',' Rank ', rank_id, ' has data ', tensor)
def init_process(rank_id, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank_id, world_size=size)
fn(rank_id, size)
if __name__ == "__main__":
size = 4
processes = []
mp.set_start_method("spawn")
for rank in range(size):
p = mp.Process(target=init_process, args=(rank, size, run))
p.start()
processes.append(p)
for p in processes:
p.join()
执行结果如下:
-
一共有4个rank参与了gather计算,计算之前:rank0 为[1, 2],rank1 为[3, 4], rank2为[5, 6], rank3为[7, 8];dst rank设置为3 -
可见rank 3为reduce sum计算的最终结果; -
需要注意这里有个副作用,就是rank 0、rank 1和rank 2的tensor也会被修改
root@g48r13:/workspace/communication# python reduce.py
before reudce Rank 3 has data tensor([7, 8])
before reudce Rank 0 has data tensor([1, 2])
before reudce Rank 2 has data tensor([5, 6])
before reudce Rank 1 has data tensor([3, 4])
after reudce Rank 1 has data tensor([15, 18])
after reudce Rank 0 has data tensor([16, 20])
after reudce Rank 3 has data tensor([16, 20]) # reduce 的最终结果
after reudce Rank 2 has data tensor([12, 14])3.5 all-gather
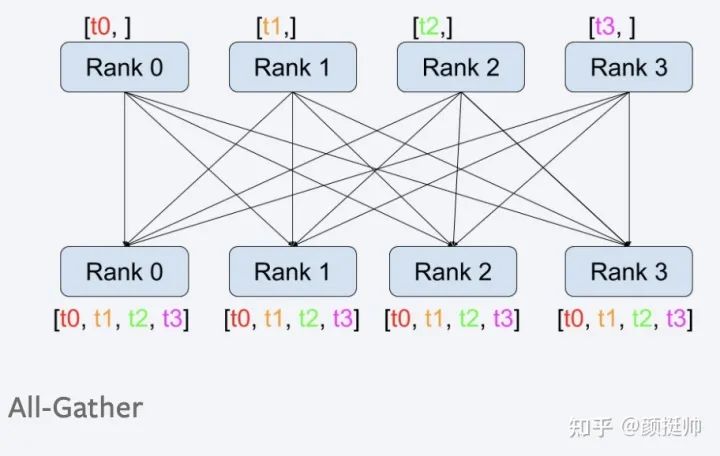
all-gather计算方式如上图所示。在pytorch中通过torch.distributed.all_gather(tensor_list, tensor, group=None, async_op=False)来实现。
-
参数tensor_list,rank从该参数中获取all-gather的结果 -
参数tensor,每个rank参与all-gather计算输入数据
使用方式如下:
-
同gather的使用方式基本一样,区别是all_gather中每个rank都要指定gather_list,并且要在gather_list构建好的tensor,否是会报错;
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def run(rank_id, size):
tensor = torch.arange(2, dtype=torch.int64) + 1 + 2 * rank_id
print('before gather',' Rank ', rank_id, ' has data ', tensor)
gather_list = [torch.zeros(2, dtype=torch.int64) for _ in range(4)]
dist.all_gather(gather_list, tensor)
print('after gather',' Rank ', rank_id, ' has data ', tensor)
print('after gather',' Rank ', rank_id, ' has gather list ', gather_list)
def init_process(rank_id, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank_id, world_size=size)
fn(rank_id, size)
if __name__ == "__main__":
size = 4
processes = []
mp.set_start_method("spawn")
for rank in range(size):
p = mp.Process(target=init_process, args=(rank, size, run))
p.start()
processes.append(p)
for p in processes:
p.join()
执行结果如下:
-
一共有4个rank参与了gather计算,计算之前:rank0 为[1, 2],rank1 为[3, 4], rank2为[5, 6], rank3为[7, 8]; -
执行完gather_list后,每个rank均可以拿到最终gather_list的结果
root@g48r13:/workspace/communication# python all_gather.py
before gather Rank 0 has data tensor([1, 2])
before gather Rank 2 has data tensor([5, 6])
before gather Rank 3 has data tensor([7, 8])
before gather Rank 1 has data tensor([3, 4])
after gather Rank 1 has data tensor([3, 4])
after gather Rank 0 has data tensor([1, 2])
after gather Rank 3 has data tensor([7, 8])
after gather Rank 2 has data tensor([5, 6])
after gather Rank 1 has gather list [tensor([1, 2]), tensor([3, 4]), tensor([5, 6]), tensor([7, 8])]
after gather Rank 0 has gather list [tensor([1, 2]), tensor([3, 4]), tensor([5, 6]), tensor([7, 8])]
after gather Rank 3 has gather list [tensor([1, 2]), tensor([3, 4]), tensor([5, 6]), tensor([7, 8])]
after gather Rank 2 has gather list [tensor([1, 2]), tensor([3, 4]), tensor([5, 6]), tensor([7, 8])]3.6 all-reduce
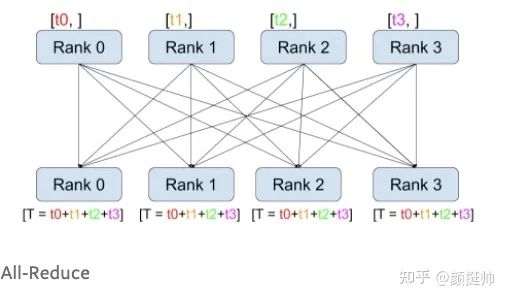
all-reduce计算方式如上图所示。在pytorch中通过torch.distributed.all_reduce(tensor, op=<ReduceOp.SUM: 0>, group=None, async_op=False) 来实现all-reduce的调用;
使用方式如下面代码所示
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
def run(rank_id, size):
tensor = torch.arange(2, dtype=torch.int64) + 1 + 2 * rank_id
print('before reudce',' Rank ', rank_id, ' has data ', tensor)
dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
print('after reudce',' Rank ', rank_id, ' has data ', tensor)
def init_process(rank_id, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank_id, world_size=size)
fn(rank_id, size)
if __name__ == "__main__":
size = 4
processes = []
mp.set_start_method("spawn")
for rank in range(size):
p = mp.Process(target=init_process, args=(rank, size, run))
p.start()
processes.append(p)
for p in processes:
p.join()
输出内内容为:
-
一共有4个rank参与了all-reduce计算,计算之前:rank0 为[1, 2],rank1 为[3, 4], rank2为[5, 6], rank3为[7, 8] -
all-reduce计算之后,所有rank的结果均相同,为rank0-rank3的tensor计算sum的结果[1+3 + 5 + 7, 2 + 4 + 6 + 8]=[16, 20]
root@g48r13:/workspace/communication# python all_reduce.py
before reudce Rank 3 has data tensor([7, 8])
before reudce Rank 2 has data tensor([5, 6])
before reudce Rank 0 has data tensor([1, 2])
before reudce Rank 1 has data tensor([3, 4])
after reudce Rank 0 has data tensor([16, 20])
after reudce Rank 3 has data tensor([16, 20])
after reudce Rank 2 has data tensor([16, 20])
after reudce Rank 1 has data tensor([16, 20])参考
https://zhuanlan.zhihu.com/p/482557067
https://link.zhihu.com/?target=https%3A//pytorch.org/tutorials/intermediate/dist_tuto.html%23communication-backends
公众号后台回复“项目实践”获取50+CV项目实践机会~

“
点击阅读原文进入CV社区
收获更多技术干货


