【论文复现】Top-K Off-Policy Correction for a REINFORCE RS论文复现
深度强化学习实验室
1. 前言
做推荐的同学应该多多少少听到过强化学习和推荐系统的结合可以擦出什么样的火花,二者的结合能给推荐领域带来怎么样的效果提升。从强化学习奖励最大化的思维方式来说,将强化学习用于推荐领域可谓是完美的契合了推荐的场景。但问题是如何将RL与推荐相结合一直是各大公司研究的热点。其中谷歌于2018年发表的论文《Top-K Off-Policy Correction for a REINFORCE Recommender System》在推荐领域引起了不小的反响。谷歌出品,必属精品。google发表的论文不管是在工业界还是学术界引起的反响不可小觑。由于笔者对强化学习和推荐相结合的领域一直有莫大的兴趣。在反复研读了这篇论文后,苦于论文的代码没有开源,于是一直致力于对论文的复现工作,经过长达10个多月的思考和翻阅资料后,终于在最近对论文的复现工作有了自己比较满意的成果,现将代码复现过程及心得与不足整理于此,希望能给广大做推荐的同学提供思路。鉴于笔者能力有限,其中有纰漏之处还请读者谅解并提出宝贵意见。
2. 代码及实现细节
注意:模型训练的数据来自于movie-len公开数据集,笔者尝试了该数据集的3类数据分别为ml-1M,ml-20m,ml-latest。先上几张各自的loss下降曲线:
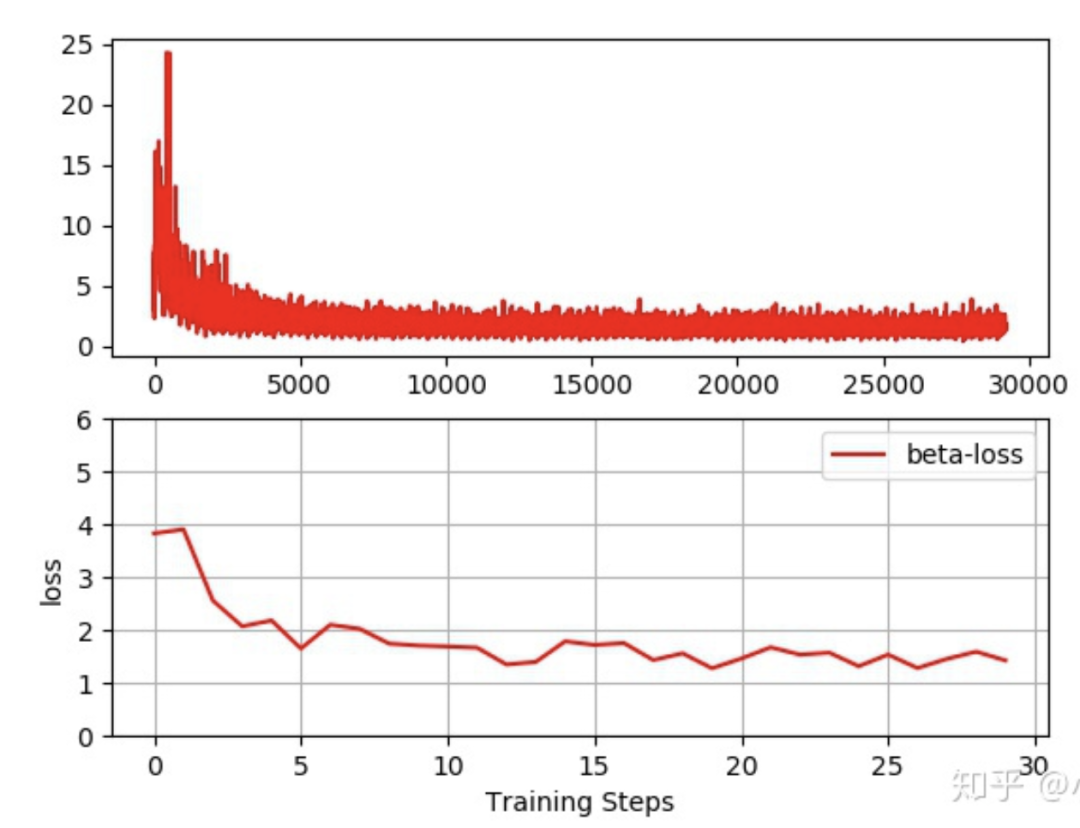
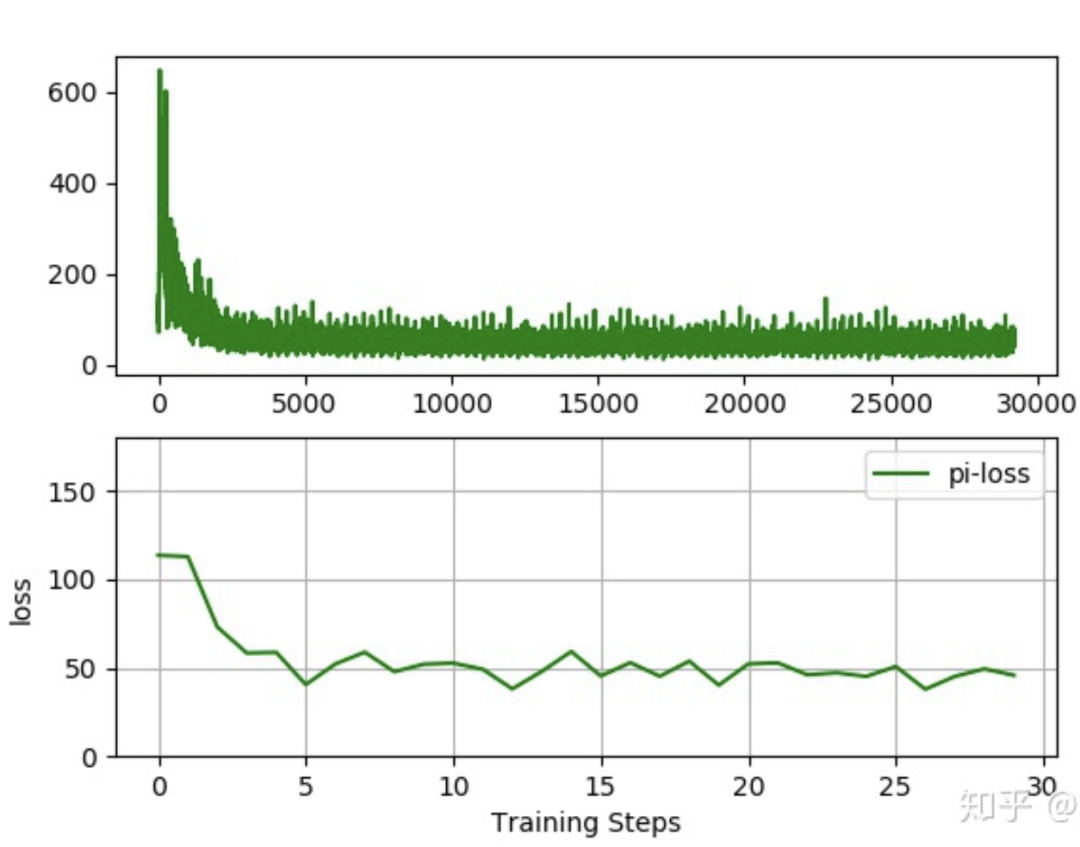
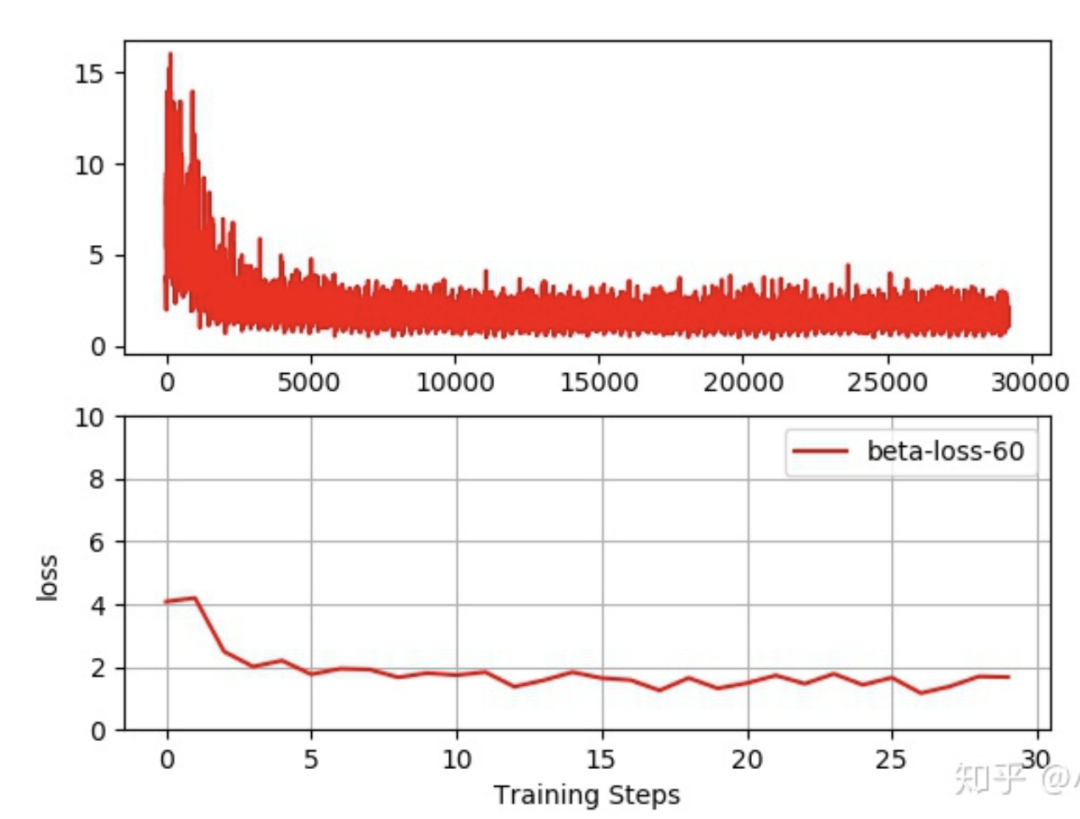
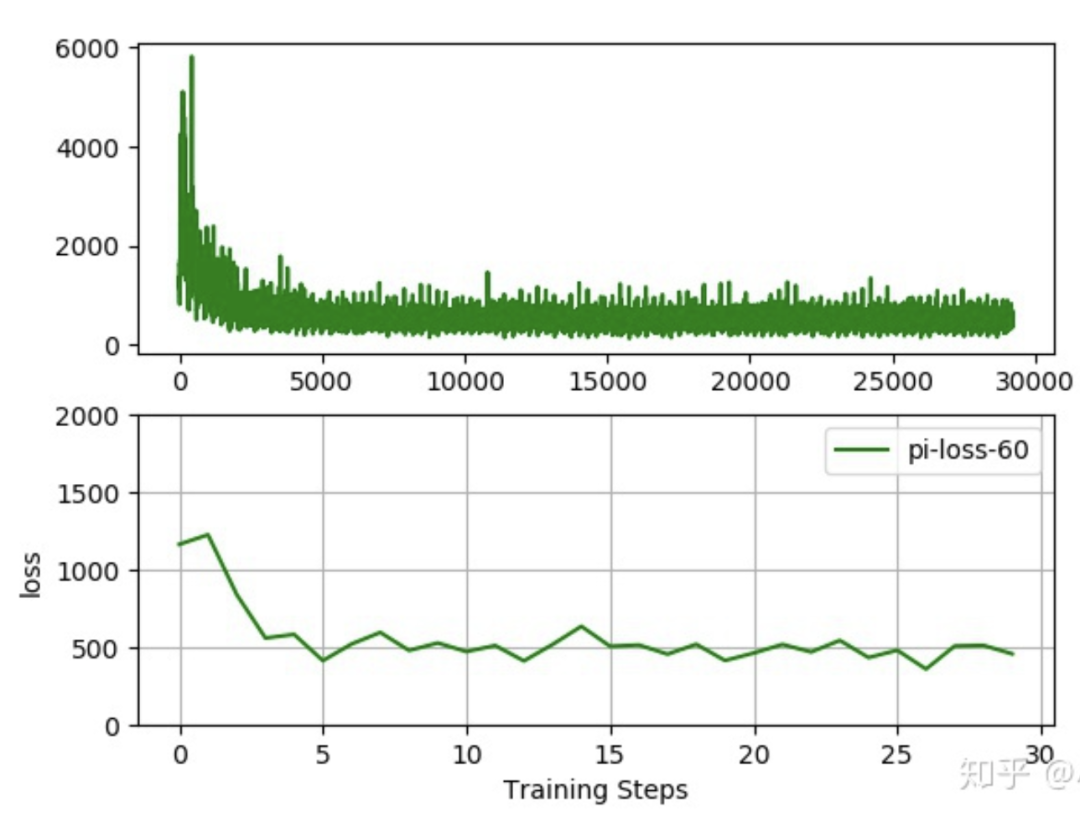
从loss曲线来看,loss下降的还是不错的。说明模型在朝着正确的方向更新。下面进入正题。
读过该论文的同学应该知道,该论文的思路是使用强化学习著名的reinforce 算法来做推荐,然而,reinforce算法有个短板,她是一个on-policy算法,然后推荐场景下拥有大量的行为日志,是一个off-policy的场景,如何将二者结合起来呢,作者借鉴了PPO算法的思路(PS:不好意思,我不知道是谁借鉴谁),使用重要性采样的思路,采用2个网络来建模,一个PI策略,一个beta,beta策略根据行为日志数据提供important sampling中概率计算的功能。按照论文中的模型架构,主网络PI用来做决策,未来用来提供action,beta策略用来计算行为日志中每个p(a|s)的概率。原论文中采用CFN网络来计算下一个state,这里,笔者使用GRU网络来替代CFN网络的功能。网络结构代码定义如下:
def _init_graph(self):
with tf.variable_scope('input'):
self.X = tf.placeholder(tf.int32,[None],name='input')
self.label = tf.placeholder(tf.int32,[None],name='label')
self.discounted_episode_rewards_norm = tf.placeholder(shape=[None],name='discounted_rewards',dtype=tf.float32)
self.state = tf.placeholder(tf.float32,[None,self.rnn_size],name='rnn_state')
cell = rnn.GRUCell(self.rnn_size)
with tf.variable_scope('emb'):
embedding = tf.get_variable('item_emb',[self.item_count,self.embedding_size])
inputs = tf.nn.embedding_lookup(embedding,self.X)
outputs,states_ = cell.__call__(inputs,self.state)# outputs为最后一层每一时刻的输出
print(outputs.shape,states_)
self.final_state = states_
# state = tf.reshape(outputs,[-1,self.rnn_size])#bs*step,rnn_size,state
state = outputs
with tf.variable_scope('main_policy'):
weights=tf.get_variable('item_emb_pi',[self.item_count,self.rnn_size])
bias = tf.get_variable('bias',[self.item_count])
self.pi_hat =tf.add(tf.matmul(state,tf.transpose(weights)),bias)
self.PI = tf.nn.softmax(self.pi_hat)# PI策略
self.alpha = cascade_model(self.PI,self.topK)
with tf.variable_scope('beta_policy'):
weights_beta=tf.get_variable('item_emb_beta',[self.item_count,self.rnn_size])
bias_beta = tf.get_variable('bias_beta',[self.item_count])
self.beta = tf.add(tf.matmul(state,tf.transpose(weights_beta)),bias_beta)
self.beta = tf.nn.softmax(self.beta)# β策略
label = tf.reshape(self.label,[-1,1])
with tf.variable_scope('loss'):
pi_log_prob, beta_log_prob, pi_probs = self.pi_beta_sample()
ce_loss_main =tf.nn.sampled_softmax_loss(
weights,bias,label,state,self.num_sampled,num_classes=self.item_count)
topk_correction =gradient_cascade(tf.exp(pi_log_prob),self.topK)# lambda 比值
off_policy_correction = tf.exp(pi_log_prob)/tf.exp(beta_log_prob)
off_policy_correction = self.weight_capping(off_policy_correction)
self.pi_loss = tf.reduce_mean(off_policy_correction*topk_correction*self.discounted_episode_rewards_norm*ce_loss_main)
# tf.summary.scalar('pi_loss',self.pi_loss)
self.beta_loss = tf.reduce_mean(tf.nn.sampled_softmax_loss(
weights_beta,bias_beta,label,state,self.num_sampled,num_classes=self.item_count))
# tf.summary.scalar('beta_loss',self.beta_loss)
with tf.variable_scope('optimizer'):
# beta_vars = [var for var in tf.trainable_variables() if 'item_emb_beta' in var.name or 'bias_beta' in var.name]
beta_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES,scope='beta_policy')
self.train_op_pi = tf.train.AdamOptimizer(0.01).minimize(self.pi_loss)
self.train_op_beta = tf.train.AdamOptimizer(0.01).minimize(self.beta_loss,var_list=beta_vars)
# 论文中根据概率选动作,根据动作计算概率的代码,主要是pi loss中用到的代码
def pi_beta_sample(self):
# 1. obtain probabilities
# note: detach is to block gradient
beta_probs =self.beta
pi_probs = self.PI
# 2. probabilities -> categorical distribution.
beta_categorical = tf.distributions.Categorical(beta_probs)
pi_categorical = tf.distributions.Categorical(pi_probs)
# 3. sample the actions
# See this issue: https://github.com/awarebayes/RecNN/issues/7
# usually it works like:
# pi_action = pi_categorical.sample(); beta_action = beta_categorical.sample();
# but changing the action_source to {pi: beta, beta: beta} can be configured to be:
# pi_action = beta_categorical.sample(); beta_action = beta_categorical.sample();
available_actions = {
"pi": pi_categorical.sample(),
"beta": beta_categorical.sample(),
}
pi_action = available_actions[self.action_source["pi"]]
beta_action = available_actions[self.action_source["beta"]]
# 4. calculate stuff we need
pi_log_prob = pi_categorical.log_prob(pi_action)
beta_log_prob = beta_categorical.log_prob(beta_action)
return pi_log_prob, beta_log_prob, pi_probs
论文中说,训练主网络pi采用reward>0的(s,a)对,而训练beta网络使用所有的(s,a),而由于使用的数据集的局限性,在实现论文的时候并没有使用这种思路来训练网络。
由于强化学习框架的要求,使用强化学习时,reward是一个必不可少的条件,如果将此算法运用到推荐领域,在用户的历史序列中的item对应的reward该如何定义,最常见的做法是,点击的item reward定为1,未点击的定为0。有精力的同学可以尝试下。
原文中使用CFN来建模state,这里笔者采用的session-based-rnn的思想建模state,不得不感叹一下,session-based-rnn中训练RNN模型的思路确实给力,估计以后训练RNN相关模型都采用这种思路来训练了吧
原论文中在训练的时候加入了label的信息。由于能力有限,实在不知道该如何实现这种思路,正常来说,输入数据是不应该含有标签的信息的。
注意:tf.nn.sampled_softmax_loss API 在训练的时候,其中参数numsampled似乎和batch_size参数有关,在此代码中,20-100倍之间效果差不了多少。比如batch_size=4096,那么num_sampled可以为120.num_sampled的不同会影响loss曲线的下降。
个人认为:本论文给topK推荐提供了一种思路,如果仅仅是考虑top1推荐的话,同样数据训练的前提下,效果似乎没有session-based-rnn好。比如同样适用20m数据集,与session-based-rnn效果对比如下:
| Recall@20 | MRR@20 | train time | |
|---|---|---|---|
| ession-based-rnn | 0.20232047783713317 | 0.07123638589710173 | 445m |
| TOCR | 0.19942149398322467 | 0.052183558844622564 | 970m |
com/awarebayes/RecNN
完
总结3: 《强化学习导论》代码/习题答案大全
总结6: 万字总结 || 强化学习之路
完
第85篇:279页总结"基于模型的强化学习方法"
第84篇:阿里强化学习领域研究助理/实习生招聘
第83篇:180篇NIPS2020顶会强化学习论文
第81篇:《综述》多智能体强化学习算法理论研究
第80篇:强化学习《奖励函数设计》详细解读
第79篇: 诺亚方舟开源高性能强化学习库“刑天”
第77篇:深度强化学习工程师/研究员面试指南
第75篇:Distributional Soft Actor-Critic算法
第74篇:【中文公益公开课】RLChina2020
第73篇:Tensorflow2.0实现29种深度强化学习算法
第72篇:【万字长文】解决强化学习"稀疏奖励"
第71篇:【公开课】高级强化学习专题
第70篇:DeepMind发布"离线强化学习基准“
第66篇:分布式强化学习框架Acme,并行性加强
第65篇:DQN系列(3): 优先级经验回放(PER)
第64篇:UC Berkeley开源RAD来改进强化学习算法
第61篇:David Sliver 亲自讲解AlphaGo、Zero
第59篇:Agent57在所有经典Atari 游戏中吊打人类
第58篇:清华开源「天授」强化学习平台
第57篇:Google发布"强化学习"框架"SEED RL"
第53篇:TRPO/PPO提出者John Schulman谈科研
第52篇:《强化学习》可复现性和稳健性,如何解决?
第51篇:强化学习和最优控制的《十个关键点》
第50篇:微软全球深度强化学习开源项目开放申请
第49篇:DeepMind发布强化学习库 RLax
第48篇:AlphaStar过程详解笔记
第47篇:Exploration-Exploitation难题解决方法
第45篇:DQN系列(1): Double Q-learning
第44篇:科研界最全工具汇总
第42篇:深度强化学习入门到精通资料综述
第41篇:顶会征稿 || ICAPS2020: DeepRL
第40篇:实习生招聘 || 华为诺亚方舟实验室
第39篇:滴滴实习生|| 深度强化学习方向
第37篇:Call For Papers# IJCNN2020-DeepRL
第36篇:复现"深度强化学习"论文的经验之谈
第35篇:α-Rank算法之DeepMind及Huawei改进
第34篇:从Paper到Coding, DRL挑战34类游戏
第31篇:强化学习,路在何方?
第30篇:强化学习的三种范例
第29篇:框架ES-MAML:进化策略的元学习方法
第28篇:138页“策略优化”PPT--Pieter Abbeel
第27篇:迁移学习在强化学习中的应用及最新进展
第26篇:深入理解Hindsight Experience Replay
第25篇:10项【深度强化学习】赛事汇总
第24篇:DRL实验中到底需要多少个随机种子?
第23篇:142页"ICML会议"强化学习笔记
第22篇:通过深度强化学习实现通用量子控制
第21篇:《深度强化学习》面试题汇总
第20篇:《深度强化学习》招聘汇总(13家企业)
第19篇:解决反馈稀疏问题之HER原理与代码实现
第17篇:AI Paper | 几个实用工具推荐
第16篇:AI领域:如何做优秀研究并写高水平论文?
第14期论文: 2020-02-10(8篇)
第13期论文:2020-1-21(共7篇)
第12期论文:2020-1-10(Pieter Abbeel一篇,共6篇)
第11期论文:2019-12-19(3篇,一篇OpennAI)
第10期论文:2019-12-13(8篇)
第9期论文:2019-12-3(3篇)
第8期论文:2019-11-18(5篇)
第7期论文:2019-11-15(6篇)
第6期论文:2019-11-08(2篇)
第5期论文:2019-11-07(5篇,一篇DeepMind发表)
第4期论文:2019-11-05(4篇)
第3期论文:2019-11-04(6篇)
第2期论文:2019-11-03(3篇)
第1期论文:2019-11-02(5篇)




