人工智能再下一城,在多人扑克中大胜人类

图片来自erpinnews.com
撰文 | 李家劲
责编 | 叶水送
● ● ●
过去二十年来,有许多人工智能被设计出来玩各种类型的扑克牌游戏,但所有这些人工智能都只能玩一对一的游戏,如 Libratus 就是二人德州扑克的高手。由此多人扑克游戏,毫无悬念地成为了下一个里程碑式的目标。

最近,美国卡内基梅隆大学 Noam Brown 和 Tuomas Sandholm 设计出了新的智能系统 Pluribus,它能在六人无限注德州扑克中击败人类专业选手,相关研究发表在7月12日的 Science 杂志上。
目前,很多超越人类的人工智能都是关于两人零和游戏,如围棋,游戏中只能有一方可以获胜,用博弈论的术语来讲,这些人工智能所做的都是在找到一个接近纳什均衡的策略。所谓纳什均衡策略就是指一系列能够使自己预期收益最大化的策略,无论对手做什么行动,至少自己不会输,另一个博弈者也会采取同样的策略。

纳什均衡由诺奖得主约翰·纳什1951年提出,图源 l.yimg.com
纳什均衡已经被证明存在于所有有限次博弈中以及大部分无限次博弈中。只不过,纳什均衡策略并不是随随便便就能找到。第一,纳什均衡策略可通过不断观察和利用对手的弱点来获得,就好比见到一直出剪刀的对手,人工智能就一直出石头。但对手也可根据你的策略来做调整,而且这种方法需要很多训练样本;第二,目前还没有足够快的算法可以找到纳什平衡;第三,在多人游戏中,就算每个玩家都独自找到了纳什均衡策略,这个总的策略集合也不一定是纳什均衡策略。
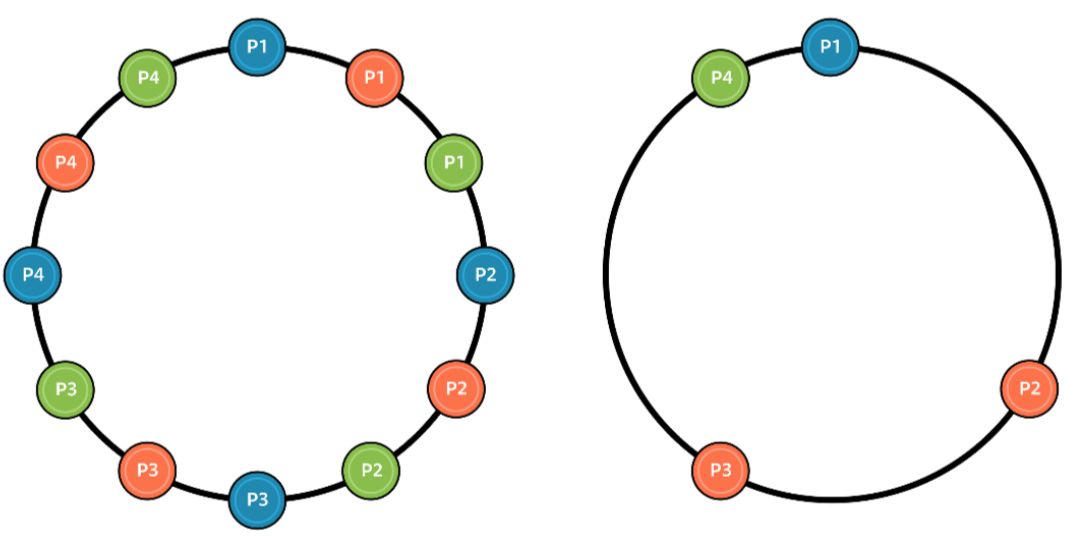
上图为四人柠檬水果摊游戏。玩家需要在圆环中找到一个位置,使自己与其他所有人的距离总和最远(左)。纳什均衡策略是每个人都均匀分布在圆环上。但如果每个人都有自己的纳什均衡策略,那么最终可能不会有纳什均衡出现(右)。而如果是两人游戏就不会有这样的问题。
但 Pluribus 系统并不打算找到这个博弈论意义上的最优策略,而是采用一种能够经常打败人类选手的策略。首先,Pluribus 通过自我博弈计算出自己的策略。换句话说,Pluribus 不断跟自己的分身玩德州扑克,期间没有任何人类或其他人工智能的参与。最初,Pluribus 作为新手,行动完全随机,但它会不断改进自己的策略,逐渐提高自己的水平。自我训练得出的策略被称为“蓝图”。然后,Pluribus 就和真实玩家对战,积累实战经验,期间不断改进自己的策略。
这其中涉及到哪些技术细节呢?在德州扑克中,由于每一回合可以采取的行动实在太多,为了减少问题的复杂度,研究者采用了行动抽象(Action abstraction)和信息抽象(Information abstraction)的简化技术。所谓成败在于细节,Pluribus 因此只会将信息抽象用于对未来几个回合的预想中,而不会用在当前回合的决策上。
为了计算出“蓝图”策略,Pluribus 采用了蒙特卡洛虚拟遗憾最小化算法(MCCFR)。MCCFR 会随机考虑一部分行动,而不是所有可选行动,来选择应该采取的决定。在MCCFR的每一次迭代中,人工智能会根据在场玩家的策略模拟一盘游戏,然后找出自己在模拟游戏中的最优策略。每一回合,人工智能都会被加入一个虚拟遗憾值,使它会后悔上次没有用其他更好的策略,那么下一轮人工智能就会有倾向选择上次后悔没选的策略。就这样,Pluribus每局都在学习如何击败以前的自己,从而不断提高自己的水平。
“蓝图”策略只是一个粗略的策略。基于“蓝图”,Pluribus 在跟真正对手博弈的时候,用实时搜索(real-time search)技术寻找更好的策略。不同于围棋等完全信息博弈(perfect-information games),六人德州扑克是不完全信息博弈(imperfect-information games)。人工智能对其他玩家的特征、策略和对应收益都没有完整的了解。所以,研究者独创了一种新的方法,他们假设每个玩家会有自己的4种策略,包括“蓝图”策略和它的三个变种,并且会在游戏中选择其中一种。由于对手会变换策略,Pluribus 就会计算出比较平衡的策略,而不会偏向于只采取某些决定。另外,为了防止被对手看穿自己的策略,Pluribus 会先计算如果手上的牌跟现在不一样时,会采取什么行动。Pluribus 得出一个可以平衡各种情况的策略后才开始该回合的行动。
训练完成后,就到测试阶段了。实际运行中,Pluribus 平均每回合只需要20秒思考时间,足足比专业选手快一倍。如此快的速度,那实力如何呢?研究者设计了两个比赛,分别是5H+1AI(H代表人类),以及1H+5AI,并且邀请世界各地的高手参加。结果发现,在5H+1AI中,Pluribus 平均每局能赢 48mbb(milli big blinds),在六人德州扑克中是极好的成绩;在1H+5AI中,Pluribus 以平均每局32mbb 的成绩击败人类。
Pluribus 击败人类,说明人类的经验性策略并不是最优,或许人类可以从中学习到新的技巧。另外,从人工智能的研究来讲,Pluribus 的成功表明即使理论上没法保证人工智能在多人游戏上的表现,我们也可以通过精巧的算法设计来训练出超越人类的人工智能。

制版编辑 | 皮皮鱼
更多精彩文章:




这个夏天,来点古典音乐吧。