2015-2019年摘要模型(Summarization Model)发展综述(二)
作者:张文涛
本文为授权转载,原文链接,点击阅读原文直达:
https://zhuanlan.zhihu.com/p/138282654

一、2015-2019年摘要模型发展综述(一)
二、2015-2019年摘要模型发展综述(二)
三、2015-2019年抽取式摘要模型(Extractive Summarization Model)论文详述
四、2015-2019年生成式摘要模型(Abstractive Summarization Model)论文详述
一、2015-2019年摘要模型发展综述(二)
目录
3、生成式摘要模型的发展过程
3.1、RNN-based Summarization model的发展过程
3.1.1、模型的基础结构
3.1.2、引入copy mechanism
3.1.3、防止重复生成的机制
3.1.4、还有哪些attended information
3.1.5、超长文档的压缩
3.1.6、提高抽象度的尝试
3.1.7、loss function的变化过程
3.1.8、multi-task learning framework训练的摘要模型
3.1.9、可控生成的摘要模型
3.1.10、graph-based summarization mdel
3.1.11、自监督摘要模型
3.2、Transformer-based Summarization model的发展过程
3.2.1、model structure的变化过程
3.2.2、合适摘要生成任务的pre-training task
3.2.3、graph-based summarization mdel
4、结语
3、生成式摘要模型的发展过程
根据pre-trained model出现的时间,可以大致将生成式摘要模型的发展过程分为两个阶段:(1)2015-2018年,RNN-based Summarization model的发展阶段(2)2019-2020年,Transformer-based Summarization model的发展阶段。
当预训练模型出现后,摘要模型虽然在建模思想上延续RNN-based model阶段的思想,但是在模型结构和训练方式上出现了较大的改变,尤其是在encoder和decoder的预训练方式等方面。为此,本文将分两个阶段介绍摘要模型的发展过程。
3.1、RNN-based Summarization model的发展过程
3.1.1、模型的基础结构
生成式摘要模型的基础结构也包含sentence encoder、document encoder和decoder等结构。与抽取式摘要模型一样,sentence encoder大多都是CNN-based或RNN-based结构,且没有定论表明哪种结构更好,两种结构都频繁出现在许多生成式摘要模型中;document encoder基本都是RNN-based结构;由于生成式模型的目标是生成文本序列,所有decoder基本都是RNN-based decoder。这些encoder和decoder的结构与抽取式摘要模型中介绍的encoder和decoder基本类似,故此处不再赘述,而是介绍生成式模型在组合这些结构的方式上的不同。
生成式摘要模型的基础结构主要有三种类型:
第一种基础结构
第一种结构是sentence encoder + decoder,即模型的decoder直接利用文档词级别的上下文信息生成摘要,而非利用文档句级别的上下文信息;这种结构在预训练生成式摘要模型中逐渐成为标准结构;
如:[20]提出的基于窗口的摘要模型,模型结构如下图,将摘要生成任务视为LM task:
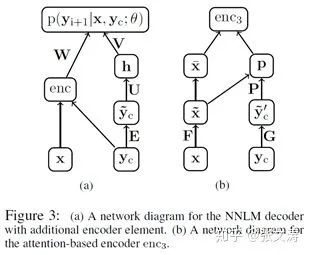
上图右边部分是encoder,输入有两个部分:Fx是文档的词向量矩阵, 
上图左边部分是LM(decoder),以基于文档和未基于文档的上下文表示向量为输入(enc和 
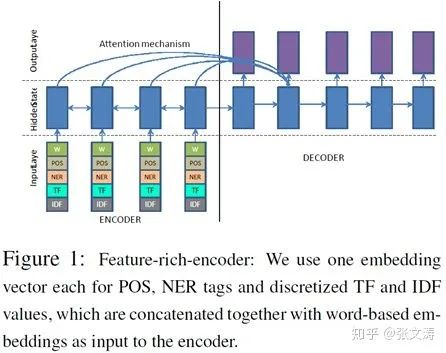
再如:[21]提出的feature rich encoder的摘要模型,模型结构如下图,encoder的输入是每个词的embedding及统计特征拼接得到词向量,decoder在解码时直接attend每个词的隐向量,自适应地选择对当前解码有用的信息:
第二种基础结构
第二种结构是sentence encoder + document encoder + decoder,即模型的decoder或仅利用文档句级别的上下文信息,或同时利用文档词级别和句级别的上下文信息,以期decoder可以获得更高层次的语义信息;然而,当sentence encoder足够有效时,增加document encoder似乎在语义提取上更显冗余,甚至引入噪声;
如:[21]提出的hierarchical document structure的摘要模型,模型结构如下图,sentence encoder和document encoder是bi-GRU,其中document encoder的输入是每个句子最后一个词对应的sentence encoder的hidden state;decoder在解码时,不仅attend每个词的隐向量,还attend每个句子的隐向量。
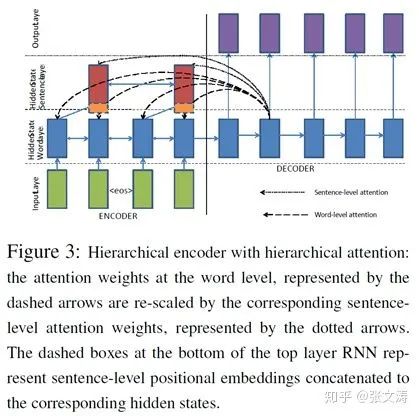
每t步解码时,首先分别计算word level attention distribution和sentence level attention distribution,前者的输入是decoder的隐向量和word level encoder输出的隐向量,后者的输入是decoder的隐向量和sentence level encoder输出的隐向量;然后,按照下式对在文档词上的attention distribution进行调整:
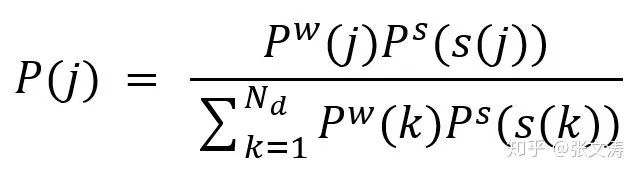
其中, 

再如:[22]提出的层次化的摘要模型,结构如下图,图中的word encoder是本文章中一直说的sentence encoder,图中的sentence encoder是本文章中一直说的document encoder;word encoder单独编码每个句子,并将last hidden state作为句向量,经sentence encoder编码后得到上下文句向量;decoder也有两个层次,sentence decoder解码摘要每个句子的主题,word decoder则根据该主题解码每个句子的词,并将last hidden state作为sentence decoder解码下一个句子主题的输入,从而生成摘要。encoder和decoder都是uni-LSTM。
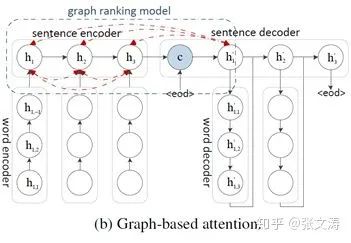
上图展示了一种改进的attention机制,[22]认为,传统的attention distribution仅考虑encoder和decoder的向量间的关系,没有考虑encoder的向量间的关系,实际上这部分相关关系也应在解码时充分考虑;
为此,[22]提出graph attention,图中的顶点是文档中的句子,边是句子间的相似关系,由bilinear similarity计算得到;通过定义一种图上的PageRank算法,按照下式计算第t步解码时每个句子的重要性得分,进而计算decoder的第t步状态与encoder间的上下文表示向量:
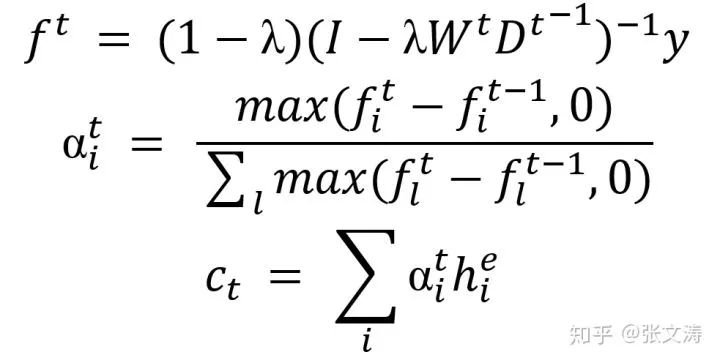
其中, 

第三种基础结构
第三种结构是sentence encoder + (document encoder) + extractor + abstractor,其中extractor是抽取式摘要模型的decoder,abstractor是生成式摘要模型的decoder,通常是seq2seq model;这种两段式的摘要模型的思路是,先通过extractor将文档的重要信息抽取出来,再由abstractor将其改写为更抽象、更流利的摘要;这种结构在预训练生成式摘要模型的结构中也较为常见,算得上是标准结构;
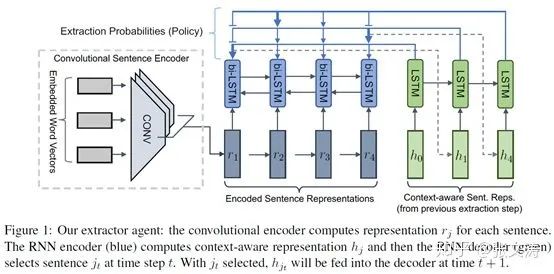
如:[23]提出两段式的摘要模型,结构如下图,由CNN-based sentence encoder (灰色部分)+ LSTM-based document encoder(蓝色部分)对文档进行编码;通过LSTM-based extractor(绿色部分)从中选择最重要的k个句子,decoder将任务视为global selection;再通过abstractor(未在图中)对其进行rewrite,生成最终的摘要。
需要注意的是,extractor在第t步解码时,需要按下式计算两次attention distribution,第一次是计算作为聚合权重的attention,第二次是计算作为选择概率分布的attention:
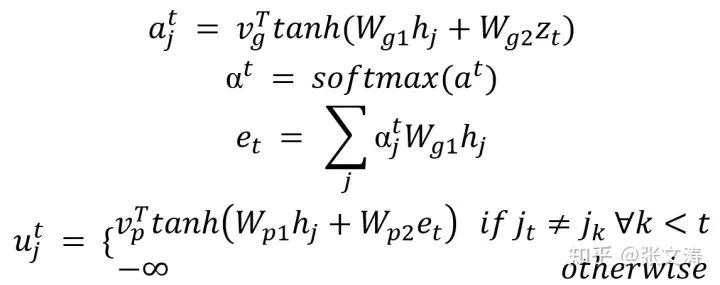
其中, 


[23]在训练模型时分为两步,首先分别训练encoder + extractor和abstractor,然后将两者联合训练,此时abstractor的参数固定,仅更新encoder和extractor;经试验发现,这种两段式的模型,无论在效果还是效率上都优于前两种结构的模型。
基础结构的改进方向
2019年之前的生成式摘要模型大多都是在上述三种基础结构之上进行调整,主要的调整集中在:(1)decoder在解码时,除了attend来自encoder的信息,还应该attend其他更有效的信息,如:文档的主题、实体信息、摘要模板等(2)除了上述通用结构,生成式摘要模型还有一些特有的结构,如:Pointer、Switch、temporal attention等,这些结构被提出来用于解决一些生成式模型独有的问题,如:OOV、重复生成等问题。这些改进的细节,将在下文中逐步介绍。
3.1.2、引入copy mechanism
为什么需要引入copy mechanism
生成式摘要模型在decode时,有时候会遇到OOV问题,即某个适合描述文档信息的词没有包含在decoder的vocabulary中,此时往往会输出<UNK>或其他替代词,这类不在vocabulary中的词被称为OOV;OOV往往是文档中描述某个实体或事件的词,具有重要的语义信息。
为了解决OOV问题,同时不增加decoder的vocabulary的规模,模型希望引入一种机制:当decoder在解码过程中碰到 OOV时,从文档中复制该词作为解码结果,否则从decoder的vocabulary中生成某个词作为解码结果。这个机制就是copy mechanism。
为了解释copy mechanism,这里先介绍与之相关的一些概念:
(1)Generator,即前文所说的decoder,具有自己的vocabulary,其通常包含常见词和领域的特征词;Generator在每步decode时,从vocabulary中选择一个词作为结果
(2)Pointer,是对文档包含的词的选择器,其vocabulary就是文档中所有的词;每步decode时,计算在文档词上的概率分布,选择概率最高的词作为结果
(3)Switch,是解码结果的选择器,每步解码时决定选择Generator的结果还是Pointer的结果作为最终结果,通常是一个二分类器;Switch的选择性有hard limitation和soft limitation两种:hard limitation指,根据Switch的概率在Generator和Pointer间进行选择,选择其中一种结构的结果作为最终结果;soft limitation指,将Switch的概率作为权重,将Generator和Pointer的结果进行加权合并为最终的概率分布,选择概率最高的词作为最终结果。后续的论文中,soft Switch基本成为标准的Switch机制。
copy mechanism的真相
2016年,[21]首次提出了Switching Generator-Pointer,模型结构如下图;模型采用hard Swtich,选择Generator时decoder图示G,选择Pointer时decoder图示P;
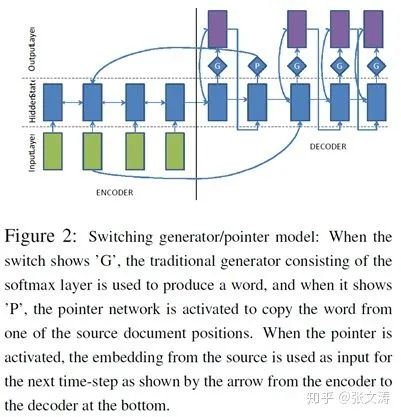
模型按照standard seq2seq的方式计算Generator,此处不再赘述;
模型按照下式计算Pointer,其中 


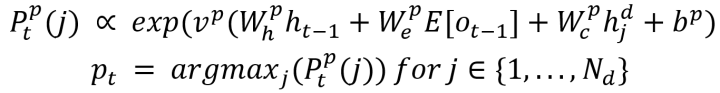
模型按照下式计算Switch,其中各项参数的意义与上式相同,当 
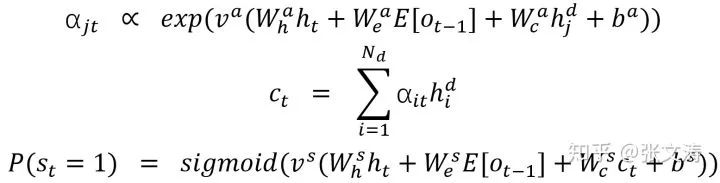
可见,[21]在计算Generator、Pointer和Switch时,分别计算在文档词上的attention分布,并没有机制显式强迫三个分布相互协调,满足同一种重要信息抽取的倾向,因此在训练模型时容易学习到包含矛盾的参数。
2017年,[24]改进了Pointer和Switch的计算方式,提出了标准的copy mechanism,成为目前摘要模型主流的组成结构;模型结构如下图:
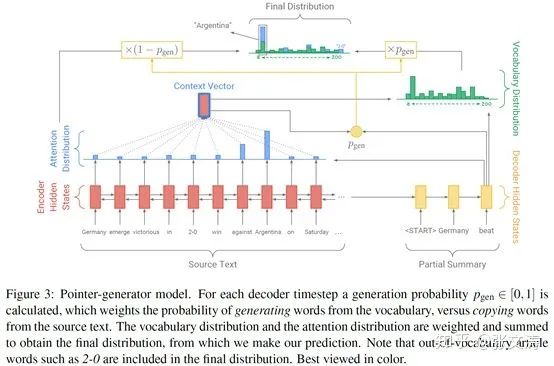
模型的sentence encoder(红色部分)是bi-LSTM,decoder(黄色部分)是uni-LSTM,在第t步解码时,首先按照下式计算context vector:
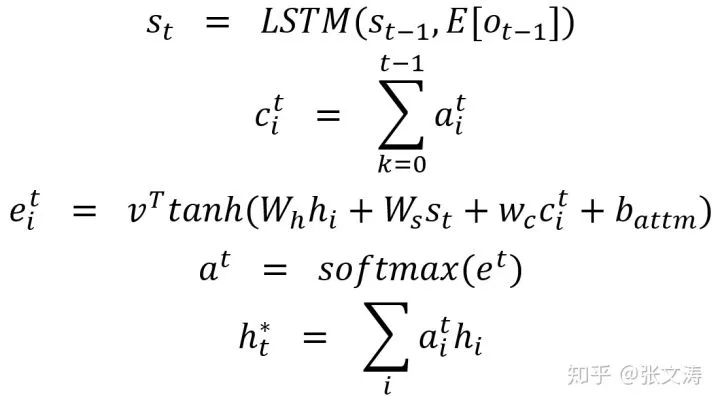
其中, 



求得context vector后,[24]按照下述方式计算Pointer、Generator和Swtich:
(1)计算Pointer:模型将 
(2)计算Generator:模型按照下式计算Generator解码的概率分布:
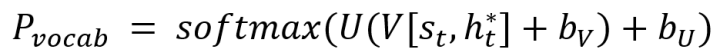
(3)计算Switch:模型按照下式计算Switch的概率分布, 
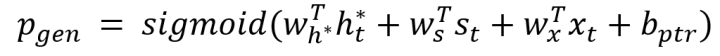
得到三种结构的概率分布后,[24]使用soft Switch按下式计算最终的解码结果;当w是OOV时, 

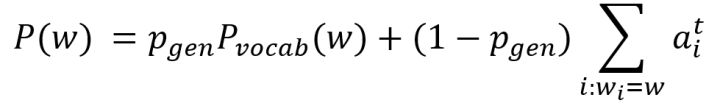
可见,[24]在计算Pointer、Generator和Switch时,使用相同的attention distribution,这种简化引入的参数更少,并显式提出了attention分布的协同性,不仅提高了模型的表现,也加速了模型的收敛,[24]通过试验对比,[24]的训练速度相比[21]要快2/3。
copy mechanism并非总是有利的
copy mechanism作为一种相对独立的结构,可以增加在任何一种生成式摘要模型中,总是可以有效解决OOV的问题,提高模型的表现。但是copy mechanism并非总是只带来有利的结果,有时候引入copy mechanism的模型总是会遇到copy too much的问题。
[24]通过实验衡量模型的抽象能力,即有多少内容是生成的,有多少内容是复制的。下图显示,相比reference summaries,[24]的copy rate非常高,高达35%的句子是从原文档中抽取的:
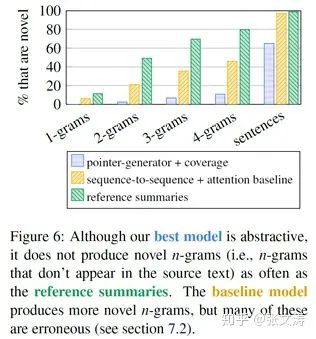
另外,从 
这种差距主要是因为teacher-forcing训练方式导致的,即模型在训练时,decoder每步总是接受正确的输入,但在预测时,decoder每步接受的上一步的输出,并不总是正确的输入,由此导致模型更加依赖Pointer的结果;这是一种exposure bias;
为了解决这种exposure bias,[25]提出一种训练方式,即在训练过程中,decoder每步的输入有25%的概率被替换为第t-1步的输出,而非gold-truth inputs。
3.1.3、防止重复生成的机制
temporal attention
2016年,[21]在论文中针对生成式摘要模型常见的诸多问题提出了改进方法。其中,关于摘要模型在解码阶段总是重复生成相同内容的问题,[21]认为这是因为decoder在解码的过程中,随着解码序列增长,忘记之前已经生成的内容,进而对同一个重要信息反复地解码,生成重复的摘要内容。
为此,[21]提出在计算decoder对encoder的attention distribution时,使用temporal attention按下式对attention distribution进行调整;在第t步解码时,首先计算该步original attention distribution,然后将前t-1步的attention distribution之和作为规范数,使用该规范数对original attention distribution进行规范,得到temporal attention distribution:
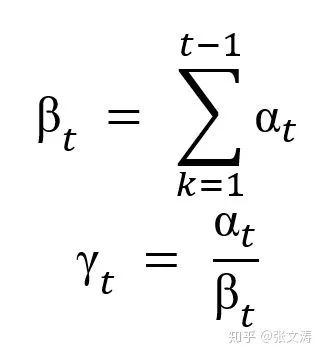
temporal attention distribution的意义在于,对于attention distribution中的每个词的score,当decoder在之前解码时对该词赋予过较高的attention score,即说明decoder曾对该词的信息进行过解码,从而强制性降低未来解码时decoder对该词赋予的score;反之,则提高未来解码时decoder对该词赋予的score,提醒decoder注意到尚未被解码的词的信息。
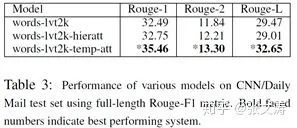
[21]在CNNDM的实验显示,temporal attention(temp)大幅提高了模型的表现,数据见下图,words-lvt2k-temp-att即为使用temporal attention的模型:
2018年,[25]提出,虽然[21]在计算decoder和encoder间的attention distribution时引入temporal attention,可以缓解模型重复生成的问题,但是decoder也可能会因为自身的状态而遗忘之前的输出内容,进而导致重复生成的问题。
为此[25]提出,引入decoder间的intra-temporal attention,使decoder在第t步解码时不仅可以看到encoder的信息,还可以看到前t-1步的解码信息,公式如下:
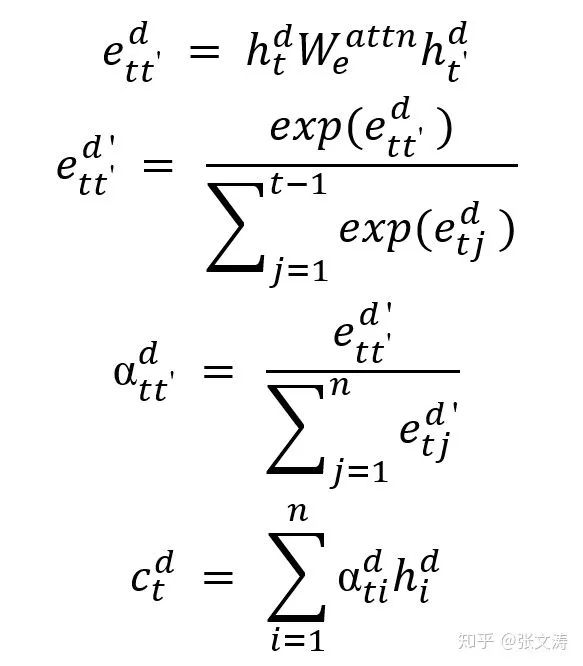
从上式可见,intra-temporal attention本质上就是temporal attention在decoder的隐向量间的应用,通过上式求得decoder的上下文向量 

惩罚重复生成的损失函数
2017年,[24]提出使用惩罚重复生成的损失函数解决重复生成问题;解码的过程中,计算decoder与encoder的attention distribution时,首先按下式引入coverage vector:
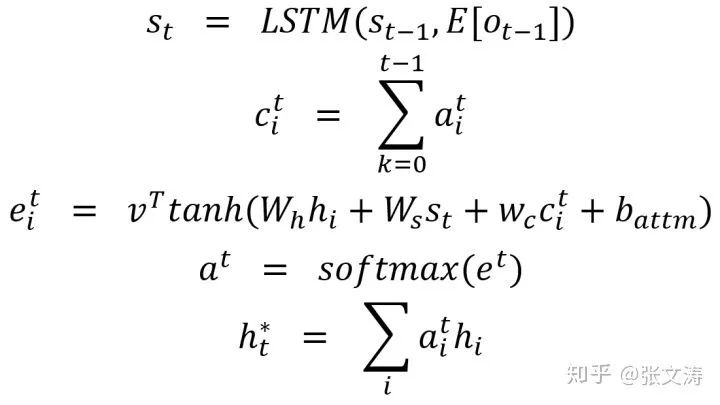
上式中,
但是论文发现,仅凭此项无法使得模型快速学到避免重复的能力,为此在损失函数中增加了对重复内容的惩罚项,公式如下:
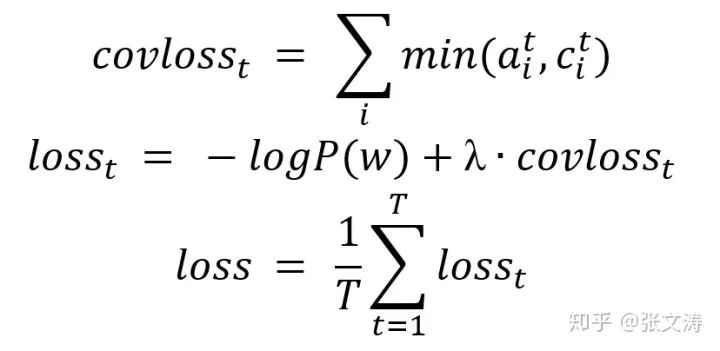
其中, 
[24]尝试了不同的training schema,发现two-stage training的效果最好,即先用无covloss的损失函数训练模型230000 steps至收敛,然后用有covloss的损失函数训练模型3000 steps至收敛;[24]尝试全程使用无covloss的损失函数的训练方式、和全程使用有covloss的损失函数的训练方式,发现前者无法改善模型的重复问题,后者使模型受covloss的影响过大,甚至无法完成主损失函数的训练。
[24]在CNNDM上进行ablation考察covloss的效果,实验数据如下,可见covloss确实缓解了模型重复生成的问题,根据论文中的数据,其效果显著好于[21]提出的temporal attention:
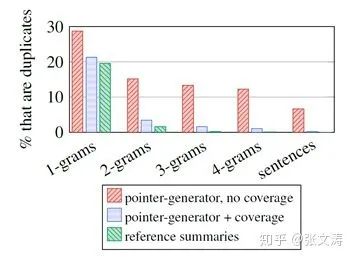
使用词频信息控制重复生成
2017年,[26]提出使用word frequency estimation model解决重复生成的问题;模型估计摘要中每个词出现的频率上限,进而限制decoder在解码时预测某个词的次数不会超过估计的频率,从而解决重复生成的问题。
[26]定义词频估计a,公式如下:
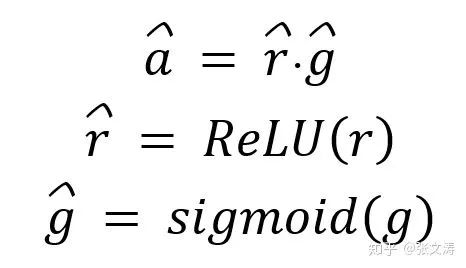
其中, 



上图中,v(1, M)代表维度为M的、元素都为1的向量;对于r,[26]将所有输入特征相加用于估计词的frequency;对于g,[26]使用输入特征在两个方向上的最突出的表现进行voting来估计词的occurrence,例如:某个输入的特征是目标词出现或不出现的强烈信号,此时g的取值是该输入的特征,是一个绝对值较大的正数或负数,而非所有输入特征的聚合值,这种思想来自于Goodfellow提出的max-pooling layers。
在训练过程中,需要增加如下损失函数,与主损失函数共同训练:
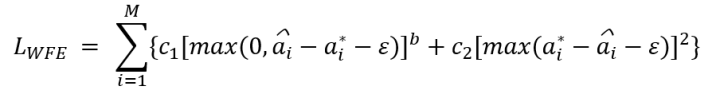
其中, 



在预测过程中,使用beam search解码;解码的每j步,按下式使用估计的词频对计算每个候选项的分数进行调整:
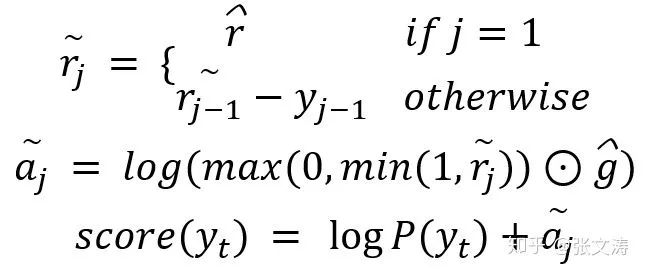



一种更简单的方式
上文提到的几种方式都是对模型的结构或训练方式作出合适的调整,这些方式总是对模型的结构或训练过程具有一定的要求,因而在使用灵活性上受到限制。
事实上,还有一种被广泛使用的方式,称为repetitive trigram avoidance,即在decoder使用beam search解码时,将生成重复的trigram的候选序列的概率调整为0,从而阻止其继续生成。这种方式作为一种后处理方式,对模型的结构和训练过程没有任何要求,因而在使用上具有相当大的灵活性。需注意,是否使用trigram,还是使用更合适的N-gram,都是可以自由地在验证集上进行调整的。
然而,repetitive trigram avoidance仅能解决短语级别的重复生成,面对句子级别的重复生成时显得无能为力;为此,[23]提出一种解决句子级别重复生成的方式:
Beam search时,假设width=k,每次解码保留全部k个句子,当解码完成时,假设此时beam length=n,即进行了n次解码;对所有句子进行 
需注意,[23]在解码时并没有时候repetitive trigram avoidance,这是因为[23]的Abstractor的输入不是原文档,而是Extractor从原文档中选择的句子,这个过程本身就有效降低了输入信息的冗余度。
防止摘要模型重复生成的机制远不止上文提到的几种方式,例如:[22]、[27]、[33]、[36]也都提出了不同的方式缓解模型重复生成的问题。纵观各种方式,[21]的temporal attention、[24]的coverage vecotr + covloss、后处理的repetitive trigram avoidance是最常用的三种方式,也有许多模型联合使用这三种方式。但总的来说,repetitive trigram avoidance使用起来更加简单,且效果容易控制。
3.1.4、还有哪些attended information
生成式摘要模型的decoder在解码时,除了attend模型的encoder编码的文档信息,有时候还会attend其他有用的信息,以便更好地生成摘要。
attend topic information
[30]提出一种topic-aware的摘要模型,decoder在解码时不仅知悉文档词的语义信息,还知悉每个词的topic信息,从而围绕同一个topic进行解码;模型结构如下图:
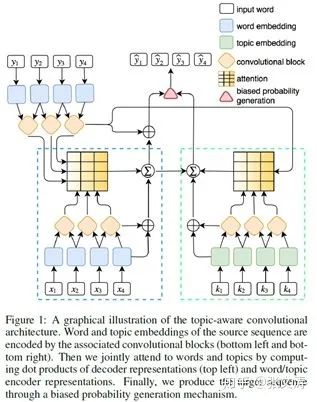
模型由两个对称的结构组成,蓝色框内的是context model,用于编码文档词的语义信息,绿色框内的是topic model,用于编码文档词的topic信息;上方左边是decoder,每步解码时,分别与context model和topic model计算attention distribution、计算上下文向量,然后计算在word vocabulary和topic word vocabulary上的概率分布;上方中间是final classifier,根据decoder与两个model的解码结果,计算最终在word vocabulary上的概率分布;
需注意,[30]使用LDA计算每个词的topic vector,并保留topic vecotr的最大值最大的前N个词作为topic words;topic model的输入是文档词,但当某个文档词是topic words时,该词的embeddings替换为topic vector,否则仍为glove embeddings。
attend template information
[31]提出基于template的生成式摘要模型,即给定一篇待压缩的文档,通过IR手段从语料库中寻找与该文档最相似、且已经被压缩的其他文档,将其他文档的摘要当做template,指导模型为待压缩文档生成合适的摘要。本节介绍给定template后,摘要模型如何利用该template进行压缩。
模型的结构如下图左边,底层输入是待压缩文档,顶层输入是template summaries:
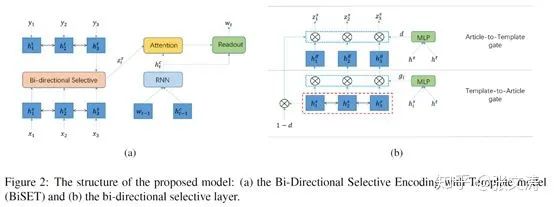
首先,模型对文档和template分别使用不同的2-layer bi-LSTM进行编码,输入为词向量,得到每个token的隐向量;
然后,模型计算T2A gate(上图右边下层部分),使用template对文档的信息进行筛选,得到template-aware隐向量,公式如下:
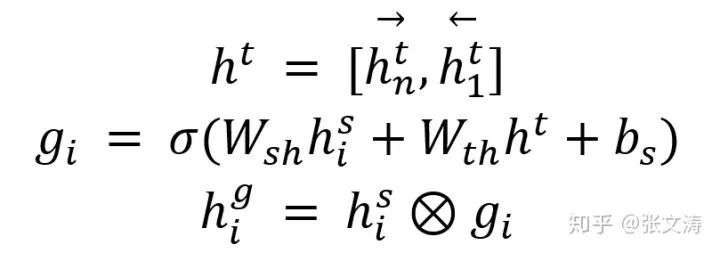
其中, 

最后,模型计算A2T gate(上图右边上层部分),用于控制template-aware representation在final representation中的比例,当template质量较低,对应的representation不可靠时,允许模型降低其在final表征中的比例;公式如下:
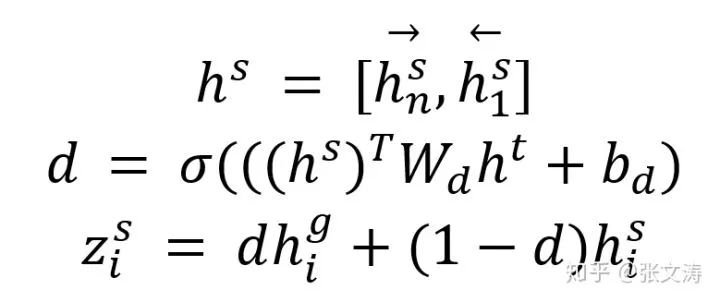
其中,
模型通过上述步骤得到原文档中每个token的template-aware representation,这些表征用于decoder生成摘要;decoder是1-layer uni-LSTM,解码方式不再赘述。
attend knowledge information
[32]提出一个knowledge-based context-aware摘要模型,模型的decoder在解码时,不仅知晓文档的语义信息,还知晓文档中包含的相关知识,这种知识通过(1)对文档中concept的识别(2)识别的concept代表的domain knowledge,如:常识、专业知识等,这两方面来提现,进而提高解码内容的质量,使其更符合要求的领域知识。
下图是对这种思想的解释,知晓group的知识的decoder在解码时,可以将运动员和官员统一称为团体;而不知晓group的知识的decoder在解码时,仅复制运动员作为摘要,丢失了官员的信息:
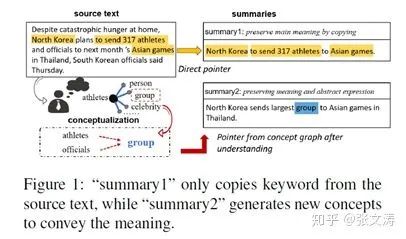
模型的结构下图,上层Encoder-Decoder是[24]提出的Pointer-Generator Network(除了Pointer),[32]在此基础上将Pointer改进为Conceptual Pointer,结构如下层部分;在解码时,上层和下层部分各自生成一种概率分布,分别代表基于语义和知识的解码结果,模型将两种分布加权合并作为最终的概率分布:
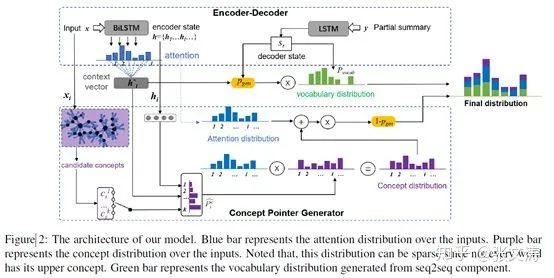
此处介绍模型提出的knowledge encoder的结构和计算过程:
首先,模型通过Microsoft Concept Graph识别原文档中的concepts;MCG是一个“isA”的分类知识库,库中的概念都通过“isA”指向一个或多个实体,且每条“isA”都有一个概率,是此概念代表该实体的概率,假设 
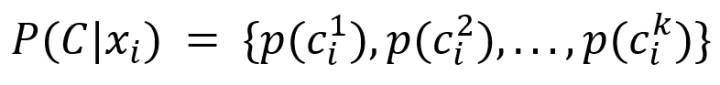
其中,

然后,为了识别在当前上下文的条件下,
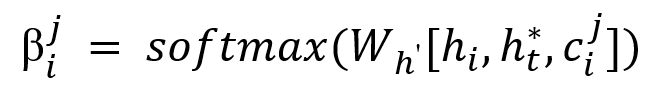
其中, 
由此,得到
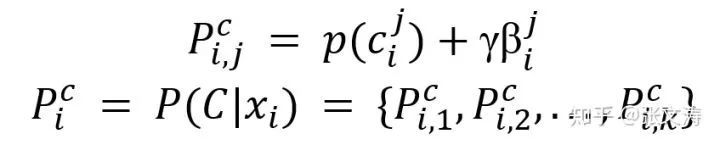
最后,使用greedy strategy,按下式对齐概念
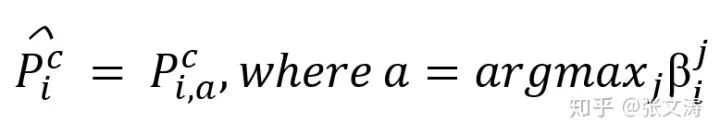
由此,按下式计算Conceptual Pointer的解码结果:
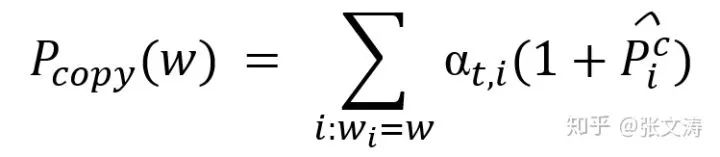
之后,按照[24]的方式计算Switch、Generator和最终的解码结果。
需注意,在解码时,模型decoder的词汇表除了包含Generator的词汇表和原文档中的词,还包含所有识别出的概念对应的所有候选实体;该策略使得模型可以更加充分地探索探索概念空间。
还有许多其他attended information
除了上文提到的各种attended information,事实上还有许多其他可供attend的有用信息,这些信息并没有成为生成式摘要模型的标准结构,但是在某些方面总是可以提高摘要模型生成内容的效果,尤其是如何将知识、实体和关系等信息加入摘要模型中以指导模型生成具备常识的、与文档逻辑一致的摘要,是最近比较热门的问题。
从attended information的形式来讲,除了textual information外,graph information也逐渐成为更受关注的信息形式,通常来说,模型会使用GNN编码这类信息,并将其与传统摘要模型的结构相结合,对两部分进行共同训练。
3.1.5、超长文档的压缩
常规的生成式摘要模型在处理超长文档时总是力不从心,与文档中极其繁多且复杂的信息相对比,模型的encoder往往过于简单,无法有效处理如此复杂的信息,从中寻找到有效的特征,模型的decoder在解码时,也因为需要attend过多的信息而容易引入噪声,降低解码结果的质量;即使将encoder和decoder的结构换为Transformer-based model,也无法有效解决处理超长文档时面临的问题。
解决这个问题的思路通常有两种:(1)分段压缩,将超长文档切分为多个片段,每个片段分别进行压缩,并在压缩时引入其他片段的信息,以提高压缩效果(2)二段式压缩,先从超长文档中挑选出重要的信息,再对这些重要信息进行压缩,减少decoder在解码时需要处理的噪声信息量,提高压缩效果。下文将分别介绍这两种思路的代表性模型。
分段压缩
[33]提出针对超长文档的分段压缩模型,称为Deep Communicating Agents,结构如下图:
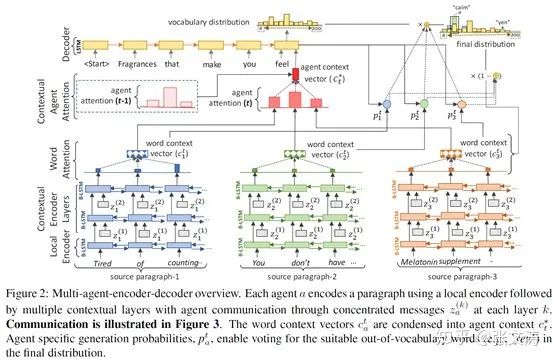
[33]将长文档划分为M个片段,每个片段由一个agent进行编码,这些agent具有相同的结构和参数(上图中蓝色、绿色和橘红色部分);
每个agent都包含两个encoder:(1)Local Encoder,1-layer bLSTM,编码每个片段的语义信息(2)Contextual Encoder,2-layer bLSTM,结构如下图,每层的输入输出本片段的信息,还有其他M-1个片段的信息,由此实现不同片段的上下文信息的交换:
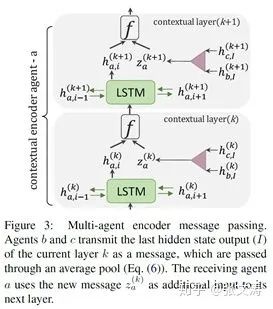
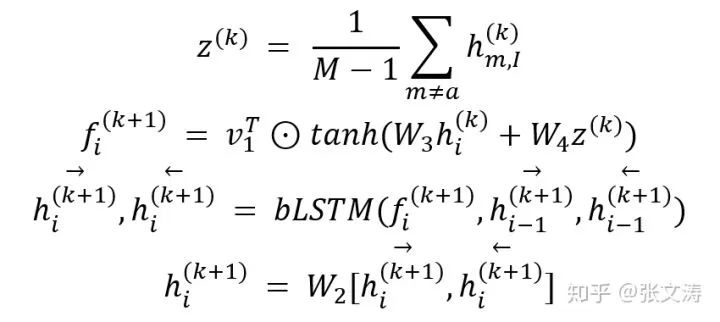
其中, 

所有agent都共享同一个Generator(上图中黄色部分),但每个agent都有各自的Pointer和Switch,所有Pointer和Switch具有相同的结构和参数;
解码时,Generator的第t步隐向量按下述方式解码,计算attention distribution、Pointer和Switch的公式与[24]相同:
(1)Generator的隐向量分别与每个agent的输出隐向量计算words attention distribution,该处的words指每个agent自己包含的words,作为每个agent各自的Pointer的解码结果;
(2)分别以每个agent的words attention distribution为权重,对agent的输出隐向量进行元素级加和,计算每个agent各自的表示向量;
(3)Generator的隐向量与(2)中得到的agent embeddings计算agent attention distribution;
(4)以(3)中的agent attention distribution为权重,对agent embeddings进行元素级加和,计算文档表示向量;
(5)Generator将隐向量、(4)中得到的文档表示向量拼接,通过MLP + classifier解码,得到在vocabulary上的概率分布,作为Generator的结果;为了使当前解码和前一步解码保持一定的主题紧凑性,防止解码所需的文档表征的主题性变化太大,Generator同时引入了前一步和当前步计算得到的文档表示向量;
(6)Generator的隐向量分别与每个agent计算各自的Switch,每个agent使用各自的soft Switch合并各自的Pointer和共享的Generator的结果,得到每个agent的解码结果;
(7)以(3)中得到的agent attention distribution为权重,对(6)中得到的每个agent的解码结果进行元素级加和,得到模型的最终结果。
[33]试验显示,在CNNDM上,DCA的ROUGE-1/2 F1高于[25],但ROUGE-L F1低于[25],这是因为DCA生成的摘要更加抽象导致的;在人工评价方面,DCA在可读性和信息性上都打到了最优。
二段式压缩
[29]提出二段式压缩模型,先从原文档中选择重要的内容,再基于选择的内容生成摘要;这种思想与[23]类似,但不同的是[23]的Extractor是sentence-level selector,而[29]的Content Selector是word-level selector;模型的工作原理如下图:
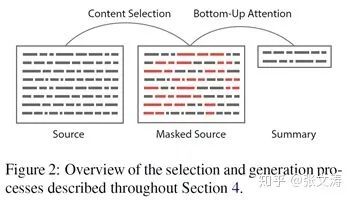
更进一步,Context Selector通过对文档进行word-level mask(选择一部分词等价于对另一部分词进行mask),还可以阻止模型在生成摘要时大量复制文档中的句子;摘要模型在生成摘要时,之所以常常大量复制文档的句子,是因为模型的Decoder本质上是一个LM,而Pointer Attention distribution是Decoder与Encoder的Attention distribution,但也可以视为Decoder与Vocabulary的Attention distribution;而文档的句子本身就是符合主题的自然语言,这就使得Pointer的结果最容易满足Decoder LM的生成需要,进而引起大量复制的问题。
为了训练Content Selector,需要在文档中标记哪些token需要被抽取;由于现有语料库都没有这种标记,故[29]采用如下规则标记token:只要token满足下述规则,其label=1,否则label=0:(1)该token是摘要和原文档的句子间最长重叠子序列的一部分(2)该最长重叠子序列在原文档中第一次出现。
模型由两部分组成:(1)Context Selector,1-layer bLSTM + sigmoid classifier,沿文档逐词进行序列标注(2)Abstractor,即Pointer-Generator Network;
为了更好地探索模型的结构,[29]提出了4种集成Selector和Abstractor的方式:
(1)Bottom-Up Copy Attention:[29]发现Abstractor的encoder在full text上训练可以得到更好的训练,为此仅将Context Selector用于Attention Masking;具体来讲,在模型训练过程中,使用相同的full text语料分别训练Abstractor和Selector;在预测时,则按照下述步骤进行:
(a)使用Selector对原文档进行标注,为每个token都预测一个提取概率 
(b)对Abstractor Pointer的attention distribution进行调整,提出一个阈值 
(c)Abstractor Generator使用full attention distribution生成新的token,Switch同理;
通过这种方式,调整Abstractor Pointer的解码结果,得到生成的摘要。
(2)Mask Only:[29]为考察新的数据标注集的效果,提出这种方式;在训练过程中,按照dataset的方式对齐原文档和reference summaries,被对齐的token被视为模型应在此处选择Pointer且Pointer应选择该token的gold-truth,使用这种gold-truth训练Abstractor;在预测时,不再使用Selector;
(3)Multi-Task:[29]将Abstractor和Selector视为不同任务,使用multi-task framework进行训练,此时Selector与Abstractor共享encoder,Selector的结构改为encoder + sigmoid classifier;在预测时,按(1)的方法进行;
(4)Diff Mask:[29]尝试训练一个end-to-end model;同时训练Selector和Abstractor,目标函数为两个模型的目标函数之和,但此处不再使用Selector的预测结果对Abstractor Pointer的attention distribution进行hard mask,而是采用soft mask,即对Pointer的attention乘以对应的提取概率 ,所得的结果进行normalization后作为新的copy attention distribution;在预测时,也用这种soft mask的方式调整Abstractor。
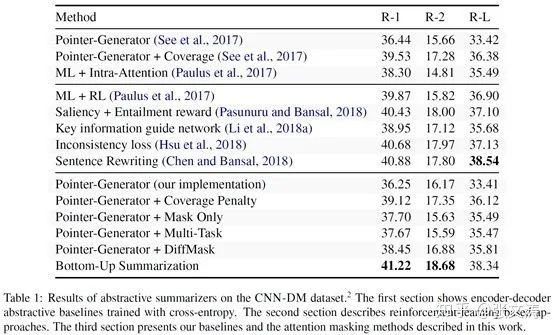
[29]通过实验对比上述4种结构的模型,数据如下,发现Bottom-Up Copy Attention结构的模型表现最好,且在ROUGE-1/2上达到了当时的SOTA:
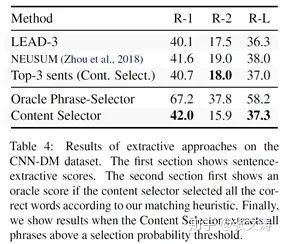
单独考察Content Selector的表现,可以发现,Selector已经是足够好的抽取式摘要模型,其在ROUGE-1上的表现说明Selector抓住了原文档的重要信息,但ROUGE-2的表现说明Selector的结果在流利度上较差,数据如下图:
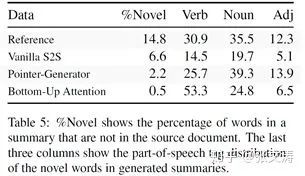
考察Abstractor的抽象能力,可以发现,Abstractor在unigram novelty上最低,说明其抽象程度并没有得到提高,这也说明Abstractor似乎只起到了生成更流利的摘要的作用,而非生成更抽象的摘要的作用,数据如下图:
3.1.6、提高抽象度的尝试
正如[24]和[33]中提到的,生成式摘要模型生成的摘要的抽象度往往都较低,模型的decoder似乎只学会生成更流利的摘要,而非更抽象的摘要。这种情况几乎在所有生成式摘要模型中都可以看到。为了提高生成式摘要模型的抽象能力,一些论文做出了尝试。
更加抽象的数据集
如:[34]认为,CNNDM、DUC、Gigaword等传统数据集有extractive bias,即这些数据集的摘要本身就有较高的比例来自原文档,使得样本更有利于训练Extractive Summarization model,不利于提高模型的抽象能力;
[34]对比了各常用摘要数据集的抽象程度,数据如下图,可见由于传统数据集有extractive bias,lead model和Extractive Summarization model等天然具有更好的表现:
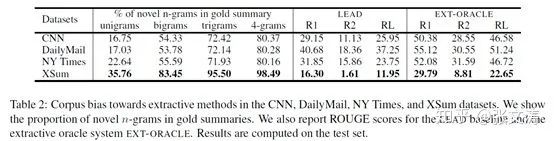
为此,论文提出新的数据集XSum,每个样本由一篇BBC的报道和一句话摘要构成,这些摘要由编辑人工编写,抽象度较传统数据集更高。
类似的还有[35]提出的NEWSROOM数据集,相比XSum仅有新闻稿这一种类型的文档,其中的文档具有相当丰富的主题,如:体育、经济、教育等。
更加抽象的解码器
再如:[36]从模型结构的角度进行改进,提出将一个在更丰富的语料上训练的LM整合进生成式摘要模型中,从而使得模型decoder在解码时可以借助LM更丰富的表达能力,生成更加抽象的摘要。
[36]在[24]的基础上,将原Generator调整为Contextual Model(绿色部分),同时将pre-trained LM(蓝色部分)整合为新Generator的一部分,模型结构如下图:
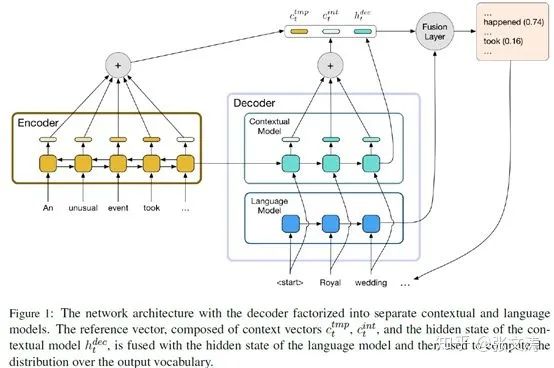
pre-trained LM是3-layer AWD-LSTM LM,按下式整合至Generator并解码(上图中的Fusion Layer):
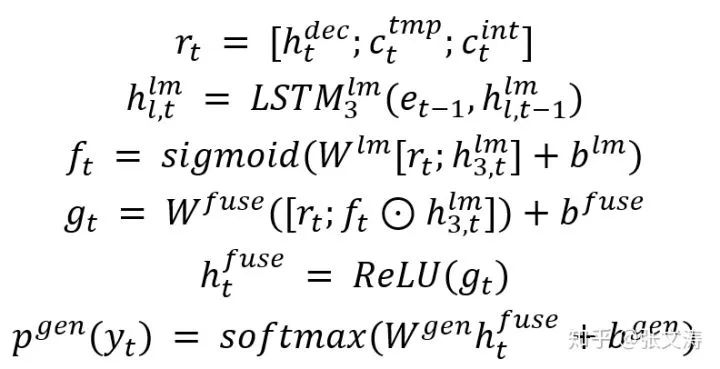
其中, 



实际上,Contextual Model的作用是整合已经decoder已经解码的信息,模型利用encoder编码的信息和decoder解码的信息对LM的解码信息进行校正,使模型的最终解码结果既可以与文档信息保持一致,还可以利用LM的抽象能力;
在训练过程中,[36]为了鼓励模型在生成摘要时,降低copy的概率,提高摘要的抽象度,定义novelty reward,公式如下:
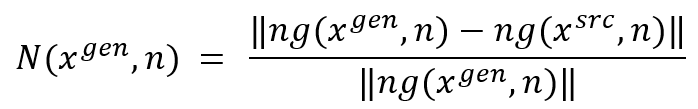
其中,ng(x,n)为文档x中的unique n-gram集合, 

为了防止模型受上式约束,偏向于生成较短的摘要,对上式进行如下调整:
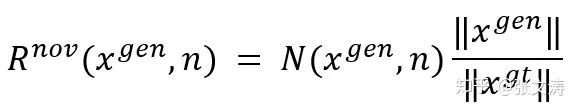
其中, 
由此,[36]定义了novelty reward,在训练时与ROUGE-based reward加权相加后作为total reward,用于RL Loss的训练。
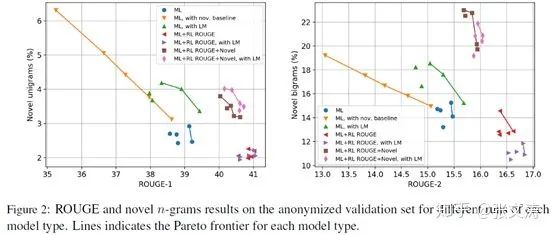
[36]的试验显示,生成式摘要模型在ROUGE score和novelty之间有着trade-off,同时提高两者较为困难;在所有模型中,[36]具有最好的trade-off曲线(菱形粉红曲线),见下图:
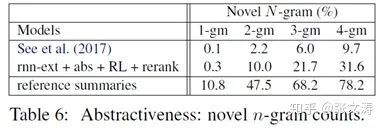
值得一提的是,采用3.1.1中第三种结构的模型,似乎在提高生成摘要抽象程度上具有自己的优势,如:[23]使用这种结构生成摘要,在试验中显示,相比[24]生成的摘要具有更高的抽象度,数据如下图:
[23]认为,这是因为模型的Abstractor是基于离散的sentence,而非连续的sentences进行训练的,其在生成摘要时需要学习如何丢弃文档中的词,采用类似人类的方式生成摘要,由此生成的摘要更具有抽象性。
3.1.7、loss function的变化过程
与抽取式摘要模型的loss function的变化过程一样,生成式摘要模型的loss function的变化过程也是,从2018年之前以MLE Loss为主变为2018年之后以MLE Loss + RL Loss为主,并且RL Loss也是以ROUGE score-based Loss为标准Loss,故生成式摘要模型的loss function的变化过程不再赘述;
但是,生成式摘要模型往往会遇到抽取式摘要模型不需要处理的问题,如:重复生成、摘要长度偏好、抽象程度较低等问题,由此产生了一系列对loss function的改进以处理这些问题;本节主要对这些改进方式进行介绍,这些改进往往以附加loss的形式存在,与模型的主loss共同进行训练。
[24]提出了covloss,和coverage vector共同解决模型重复生成的问题,在3.1.3中进行了详细介绍,此处不再赘述;
[36]为了提高摘要的抽象度,提出了novelty reward,在3.1.6中进行了介绍,不再赘述。
basic self-critic training
[25]首次提出使用RL Loss训练生成式摘要模型,以ROUGE-L F1 score作为reward,采用self-critic training进行训练,即:每个样本训练时,生成两个摘要:(1)根据decoder每步输出的概率,逐步采样得到的摘要 

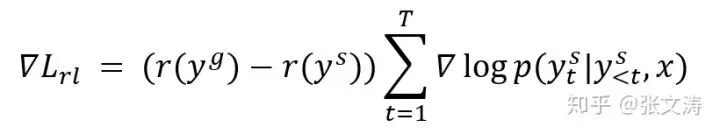
其中,r(·)是reward function,即ROUGE-L F1 score;该梯度反映的思想是,对于那些比采用贪婪策略得到的摘要的质量更好的摘要,最大化其生成的概率,反之则最小化生成的概率,从而强迫模型寻找全局最优的解,该解至少优于局部最优解(贪婪策略)。
self-critic training已经成为生成式摘要模型训练过程中使用RL Loss训练模型的标准方法,对该训练方法的改进更多地集中在引入更多样化的reward,从不同方面提高生成摘要的质量,但目前除了ROUGE-based reward,暂没有其他公认的更加好用的reward。
改进self-critic training中的均值的估计方式
[23]对self-critic training提出了改进,[23]的模型结构在3.1.1中第三种结构章节进行介绍,此处不再赘述;与[25]定义的RL Loss梯度类似,[23]定义梯度如下:
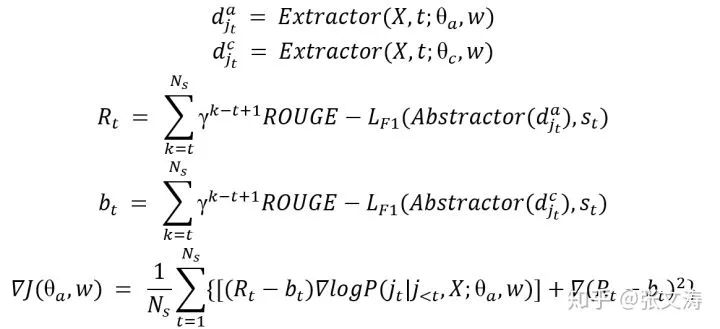
其中, 






特别的,为了让Extractor学习何时停止,论文随机初始化代表stop的待学习向量,decoder在每步解码时,同时attend该stop的表示向量和encoder,当Extractor选择该向量即视为停止继续输出;为此,论文定义两个特殊的reward:
(1)Extractor选择stop时的奖励,定义如下:
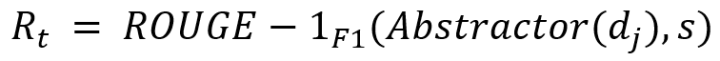
其中, 
(2)多余选择的奖励,即当选择的句子数量超过reference summary时,对于多出来的解码步, 
multi-rewards self-critic training
[37]在self-critic RL training的训练方式上,提出三种不同的reward,用于评价生成摘要的不同方面的质量,从而强迫模型从不同角度提升解码结果的质量:
(1)ROUGE rewards,即[25]提出的基于ROUGE-L F1的reward;
(2)Saliency rewards:ROUGE-L对每个token给予相同的权重,而Saliency rewards对ROUGE-L的公式进行调整,使其考虑每个token的重要性;顾名思义,该reward评价摘要的信息性和流利度;
首先,[37]在SQuAD corpus上训练一个saliency classifier,这是一个bi-LSTM + sigmoid classifier的简单分类器;Saliency classifier可以对输入的每个token预测一个重要性的概率,此概率被视为每个token的权重;
然后使用saliency classifier对reference summaries和candidate summaries进行重要性预测,对每个token都给予一个重要性概率,作为该token的权重;
最后,按照下式对ROUGE-L F1的公式进行调整,假设reference summaries R有u个句子共计m个token, 

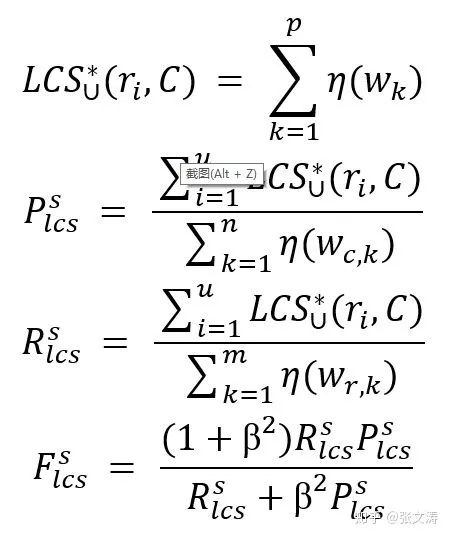
其中, 

(3)Entailment rewards,该reward评价摘要在内容逻辑性上是否与文档一致,尤其是当文档中涉及较多的实体和关系时,摘要中能否正确反映原实体和关系是关键问题:
首先,[37]在SNLI上训练一个entailment classifier;
然后使用entailment classifier对整个reference summaries和每一个candidate summaries中的句子组成的input pair进行分类,基于每个句子一个entailment score;然后计算这些句子的mean score作为candidate summaries的entailment score;
最后,对该score进行length-normalization,以防止模型偏向于生成短摘要;公式如下:
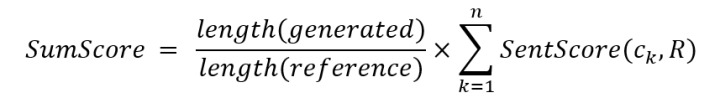
[37]提出,如果加权相加三种RL objective,需要寻找每个objective的权重值,这是复杂的工作,且模型对于权重很敏感;为此,论文提出一种更简单但是robust的方法,模仿multi-task框架,将每个RL objective视为一种task,在训练的时候轮流使用每种RL objective对模型训练若干mini-batches。
解决分布偏移的loss
[32]提出,模型在训练和测试时,可能遇到测试集和训练集的tokens分布不一致的情况,为此,论文提出一种RL objective:Distant Supervision,使模型可以根据训练集和测试集的分布情况适应性地调整模型训练时的训练重心,更关注哪些难以学习的样本(分布不一致的样本),从而降低这种不一致对模型训练结果的影响;
首先,对于每一个样本的reference summary,计算summary的表征;从测试集中挑选个文档,分别计算每个文档的表征;计算表征的方式是,将文档或摘要中的全部词向量进行元素级相加,得到加和向量,然后使用softmax将加和向量转换为一个概率分布;
然后按下式计算两者间的KL diversity:
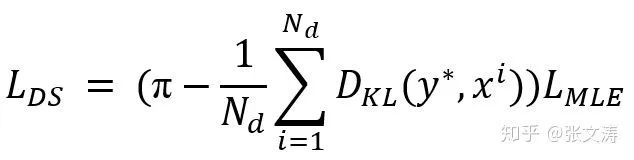
可见,DS loss的目标在于,对和测试集分布不一致的训练样本,将其作为重要样本进行训练,要求模型对其解码的loss低于其他分布一致的训练样本。
[32]通过实验对比ROUGE Loss和DS Loss的效果,实验发现,在测试集与训练集分布一致时,RL loss的效果更好;反之,则DS loss的效果更好。
3.1.8、multi-task learning framework训练的摘要模型
[38]提出使用multi-task learning framework训练摘要模型;摘要生成任务需要模型可以分辨文档中的重要信息,并对其进行有逻辑的总结,为此论文提出两个auxiliary task:
(1)Question generation:根据文档生成问题的任务,该任务需要模型有能力识别文档中的重要信息,并对此信息进行提问;使用该任务作为辅助任务,帮助摘要模型更好地掌握分辨重要信息的能力;
(2)Entailment generation:根据文档生成逻辑上一致的假设的任务,该任务需要模型生成的内容与文档在逻辑上一致,要求模型学习有逻辑地生成的能力;使用该任务作为辅助任务,帮助摘要模型在生成文档的摘要时,学会如何减少无关甚至相反内容的生成。
[38]在[24]的基础上,提出multi-task learning model,结构如下图;encoder是2-layer bi-LSTM,decoder是2-layer uni-LSTM,Pointer和Coverage Strategy与[24]相同:
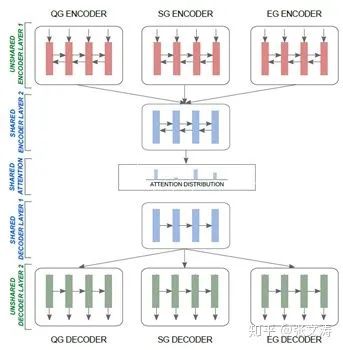
主任务(summarization task)和两种辅助任务(Question Generation task、Entailment Generation task)采用相同的模型结构;三种任务的embeddings layer、encoder的第一层和decoder的第二层的结构不共享,encoder的第二层、attention distribution和decoder的第一层的结构共享;
需注意,模型采用的共享方式不是hard sharing,即共享的结构使用同一套参数;而是采用soft sharing,即共享的结构实际上有各自的参数,模型鼓励这些参数在参数空间的分布上趋同,使用L2 loss惩罚共享参数间的不同分布;soft sharing使模型具有更大的任务灵活性。具体来讲,对损失函数进行如下调整:
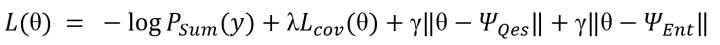
其中,第一项是主任务的CE Loss,第二项是covloss,第三项和第四项是soft sharing loss,鼓励共享结构的参数分布趋同。
在训练时,[38]先分别在各自的语料上训练三个模型,直至三个模型达到90%的收敛度;然后使用上述的L(θ)按下述方法进行multi-task learning:先训练a个batch的SG任务,再训练b个batch的QG任务,再训练c个batch的EG任务,循环往复直至三个model都收敛。
[38]实验显示,multi-task model在三个任务的测试集上的表现都好于原SOTA model,且相比[24],multi-task model生成摘要的抽象度更高;
[38]进行ablation考察两种辅助任务对主任务效果提升的贡献度:
(1)[38]使用SOTA entailment classifier对candidate summaries进行分类,发现相比[24]生成的摘要,multi-task model生成的摘要更多地被classifier分类为entailment,见下图,这明EG task确实提高了candidate summaries的逻辑一致性:
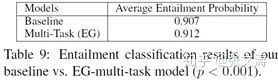
(2)[38]使用SOTA answer-span prediction classifier对reference summaries和[24]、[38]的candidate summaries进行标注,识别其中的keyword,即句中的重要信息,对比哪种candidate summaries包含更多的重要信息;结果显示,[38]生成的摘要包含更多的重要信息,见下图:
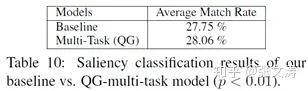
并非所有multi-task learning都会提高摘要生成任务的效果,多任务的选择往往也非常重要,一般来说,辅助任务需要和主任务在任务形式及语义偏好的逻辑上具有相似性,即提升辅助任务的语义偏好也可以提升主任务,才能提升主任务的表现,否则反而会降低主任务的表现。
3.1.9、可控生成的摘要模型
摘要生成任务的一个核心问题是,如何进行摘要的可控生成,包括控制摘要的长度、风格,有时候还希望给定一些先验条件,控制模型同时基于文档和先验条件生成合适的摘要。
有一些论文对可控生成进行了尝试,主要的方式是向模型提供输入时,除了提供文档外,还提供额外的控制信息;控制信息的形式多种多样,包括标识、文本、图等,目前最热门的是以图表示的控制信息,将在graph-based model中介绍;虽然可控生成的模型研究很多,但目前暂没有非常好的可控生成模型。
[39]提出对生成摘要的内容进行控制的变量,主要有以下4个方面:
(1)长度控制,[39]将reference summaries的长度分成10类,每类代表一个长度范围并使用一个marker token表示;在训练和预测时,将该token放在原文档前作为输入的一部分,以控制模型生成的摘要长度;
(2)实体控制,[39]使用anonymized corpus(将文本中的实体替换为实体标识),在训练和预测时,将一个或多个偏好的entity marker tokens放在原文档前作为输入的一部分,训练model生成reference summaries中提及这些实体的部分;训练时选择的实体应出现在gold-truth中,测试时选择的实体应出现在document中;如果将原文档中所有实体的marker token都作为输入,则相当于进行full text summarization;
(3)来源控制,[39]认为来自不同来源的文章对应的摘要的风格不同,在训练和预测时,将来源的marker token放在原文当前作为输入的一部分,控制模型根据文档的来源生成不同风格的摘要;
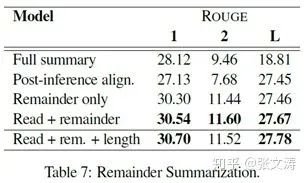
(4)剩余摘要,[39]认为,有时候读者已经阅读了文档的一部分,此时需要对尚未阅读的部分进行总结生成摘要,提高阅读的效率;对文档剩余部分提炼摘要比对文档全文提炼摘要更加困难,因为剩余部分的长度变化范围很大,且包含的剩余信息量的不确定更高;为此论文提出4种方案进行对比:(a)full summary baseline,即训练时始终在(全文档,全摘要)的样本上训练,测试时直接以剩余文档为输入(b)post-inference alignment,在(a)生成的文档基础上,将生成的摘要中对齐至剩余文档的句子作为最终摘要(c)remainder only,训练时在(剩余文档,剩余摘要)的样本上进行训练(d)read and remainder,训练时在(全文档,剩余摘要)的样本上进行训练,但通过特殊的分隔符将全文档中已读部分和剩余部分区分开。
[39]对比前三种控制策略对摘要模型的提升效果,发现长度控制提升的效果最好,其次依次是实体控制和来源控制,数据见下图:
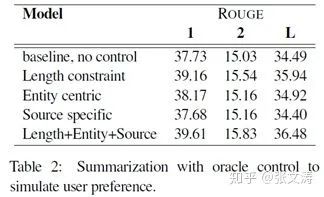
通过引入控制变量,使得摘要模型不需要花费精力在预测这些难以预测的变量上,尤其是摘要的长度,腾出更大的精力在内容生成上,因而提高了摘要的质量。
[39]对比(4)中不同方式训练的剩余文档摘要模型的效果,数据如下;使用(c)方式训练的模型大幅提高剩余文档摘要任务的表现,当引入长度控制后,效果进一步提高,原因部分是因为剩余文档的摘要长度更加难以预测,当显示指定长度后,即释放模型更多的精力用于生成质量更高的内容。:
3.1.10、graph-based summarization mdel
基于语义树的摘要模型
文档的句法结构和语义信息往往都以树的形式表现,如果对文档进行成分句法分析,可以得到反映文档语义信息的一棵语法树;为了让生成式摘要模型可以更好地学习到文档的语义信息,通常需要寻找合适的方式使模型可以处理语法树形式的输入。
[40]提出基于Abstract Meaning Representation(AMR) Graph的摘要模型;
AMR是一种语义分析的方法,从句子中抽取表征抽象语义的AMR Grhph;图中每个节点都是一个concept,concepts有不同的种类,例如:英文单词“dog”、PropBank事件谓语“run-02”、特殊关键词“person”等,每个关键词最终都对应着句子中的某些本文片段;图中的每条边都是一个relation,代表concepts间的关系,例如:ProbBank核心语义角色“ARG0”、具体语义关系“location”等;实际的AMR Graph见下图:
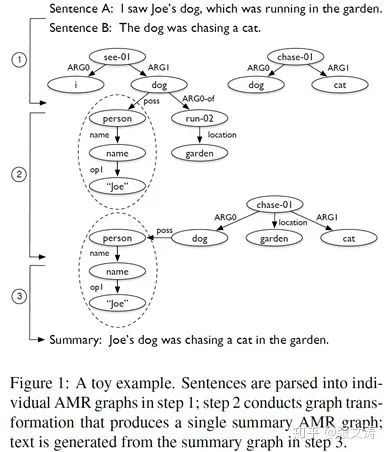
[40]生成摘要的过程如上图:(1)从文档的句子中抽取每个句子的AMR Graph(2)将这些单独的AMR Graph合并为一个AMR Graph,并满足某些用于生成摘要的条件(3)根据某种算法,从AMR Graph中提取出一个合适的subgraph,在模型训练过程中,该subgraph即为reference summaries的AMR Graph(4)将该subgraph翻译为自然语言,得到的结果即为文档的摘要;
[40]的核心阶段是第(3)步寻找Subgraph的模型,该模型的训练过程分为两步:Subgraph Prediction和Parameter Estimation;[40]使用EM训练模型,首先固定节点参数 

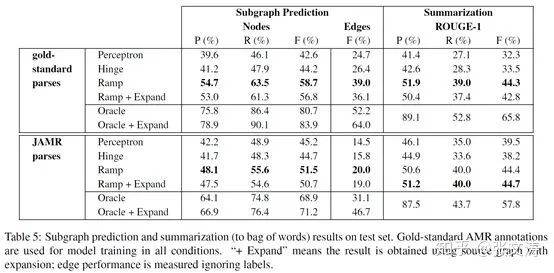
寻找到最优的Subgraph后,通过规则将AMR Graph转为自然语言的摘要;[40]此处给出的方法是,将每个节点对应的文本片段作为摘要的内容收集起来;可见,[40]实际上并没有进行人类语言式的修正,因此得到的摘要不是严格意义上的自然语言的摘要,只能使用ROUGE-1进行unigram的评价,数据如下图:
基于事实三元组的摘要模型
文档中通常会包含一些事实,从知识图谱的角度考虑,这些事实往往可以用三元组来表示;给定一段文本,如果使用Stanford OpenIE从中抽取三元组(subject,relation,object),就可以得到一系列三元组,例如:

每个三元组就相当于一个小的图结构,反映了一个基础事实;许多三元组如果相互连接起来,就会形成一个事实的图结构,根据事实的不同,可以被看做不同domain的知识图谱;
为了使生成式摘要模型生成的摘要所包含的事实,在逻辑上与文档包含的事实相一致,通常需要寻找合适的方式,使摘要模型可以处理这些事实三元组;本节介绍一个处理方式不太graph style的生成式摘要模型,更加graph style的摘要模型可以在Transformer-based model的介绍中看到。
[41]提出Fact Aware Summarization model,模型的结构如下图:
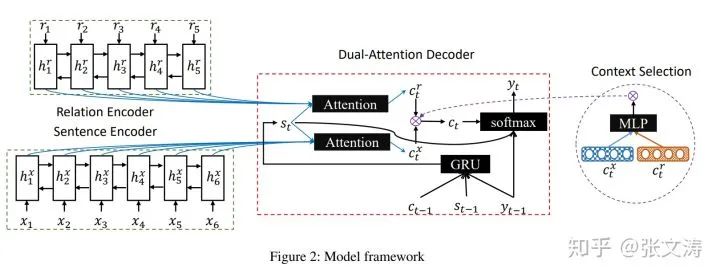
模型有两个encoder:(1)relation encoder,bi-GRU,编码事实三元组,输入是将识别出来的所有事实三元组通过分隔符拼接后形成的文本序列(2)sentence encoder,bi-GRU,编码文档句子的语义信息;两个encoder共享word embeddings;
decoder是GRU,在每步解码时,隐向量分别attend两个encoder得到两个上下文表示向量,按下式进行解码:
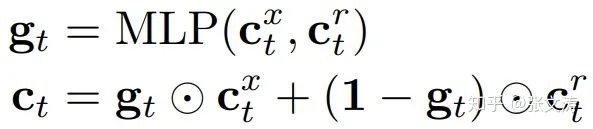
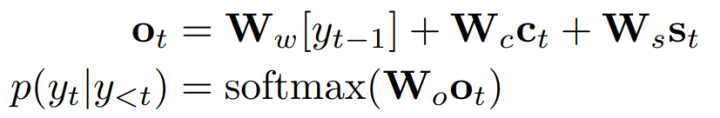
其中, 

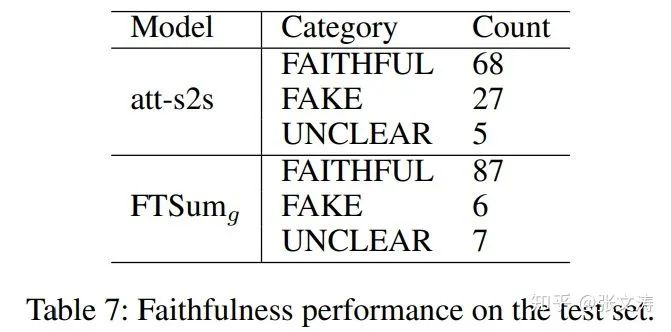
[41]的实验显示,相比att-s2s model,[41]生成的摘要包含了更多正确的事实三元组,数据如下图;att-s2s总是将靠近predicate(relation)的词当做是subject或object,但这并不总是正确的,而[41]可以根据事实的描述生成合适的三元组,不受距离的限制:
然而,[41]同时注意到,当文档中存在多个较长的事实描述时,模型总是只利用第一个事实描述的信息解码,忽略后续的事实描述,这损害了模型的信息性;为此,[41]认为也许可以通过引入copy mechanism解决该问题。
[41]这种将三元组拼接作为长文本的处理方式并非是最优的图结构输入的处理方式,因此生成的摘要的ROUGE scores相比于2018年许多成熟的摘要模型来说,并不令人满意;为此,许多论文提出了改进的处理方式,例如:使用GNN或transX等算法处理图包含的信息,更多的细节留待后面介绍。
3.1.11、自监督摘要模型
最后,还有一种神奇的生成式摘要模型,即自监督摘要模型。
当我们仅有文档数据,但是没有对应的人工编写的摘要时,如何才能基于这种数据训练生成式摘要模型?自监督摘要模型被提出来用于解决这个问题,由于训练文档没有对应的人工摘要,因此在训练时,模型的优化目标并非是最大化生成摘要的概率,也不能使用MLE/CE Loss和RL Loss;但在测试集上进行评价时,通常会给测试集提供人工摘要,使用ROUGE scores评价生成的摘要的质量。
[42]提出一个unsupervised abstractive summarization model(UAS),结构如下图:
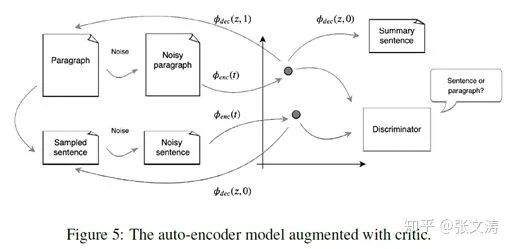
encoder和decoder的结构
UAS是一个encoder-decoder model;encoder是一个denoising encoder,将document或sentence编码成分布在同一向量空间的隐向量;encoder的输入是加入噪声的输入,论文提出两种加噪的方式:
(1)randomly masking tokens:(a)按照15%的概率选择被mask的句子(b)被选择的句子中,每个token按照85%的概率被替换<MASK>;
(2)Permuting order of sentences:论文发现,即使按照(1)加入噪声,模型在生成document的第一个句子时准确率很高,生成第二至五个句子时准确率过低,说明模型仅对第一个句子有很好的记忆;为了迫使模型记住更多的句子,及句间的共现关系,论文按照50%的概率重新排列document中的句子顺序,要求模型按原来的顺序重建paragraph;
[42]提出两种encoder结构:(1)1-layer bi-GRU(RNN),将两个方向的last hidden state拼接并线性变换,作为输出的隐向量(2)2-layer Transformer encoder(TRN),将顶层输出的第一个位置的向量进行线性变换,作为输出的隐向量;
decoder根据隐向量重建document或sentence,当参数β=0时,decoder将隐向量重建为sentence,当参数β=1时,decoder将隐向量重建为document;如果encoder将document编码为隐向量,decoder在β=0时将该隐向量重建为sentence,相当于为paragraph生成了single sentence summarization;
[42]提出两种decoder结构:(1)1-layer uni-GRU(RNN)(2)2-layer Transformer decoder without encoder-decoder attention(TRN);两种decoder的输入都是前一步的输出词向量和encoder输出的隐向量拼接得到的输入向量,其中,第一个位置的输入是值全为β的β向量,通知decoder接下来的工作内容;
UAS的encoder和decoder间没有使用attention相关联,而是将encoder的输出作为decoder的输入,从而强迫模型将所有信息都编码于隐向量中;
[42]对比了RNN-RNN、RNN-TRN、TRN-RNN、TRN-TRN四种结构的UAS,实验数据显示TRN-RNN的UAS的效果最好。
引入critic解决分布空间的差异
[40]发现,如果仅采用上述结构训练模型,得到的模型以document的隐向量作为输入时,即使β=0,模型也会重建document而非sentence;这是因为encoder将document和sentence编码至同一分布空间的不同部分,decoder可以识别这种不同以至于忽略β的指导;
为此,[42]提出adversarial discriminator/critic D,被训练区分隐向量是来自document还是sentence;Critic的结构是MLP + sigmoid classifier,输入是隐向量,输出是分类概率;
加入critic后,encoder将被鼓励生成可以迷惑critic的隐向量,从而使encoder将document和sentence编码至同一分布空间的同一部分;
但需注意的是,[42]发现并非所有encoder结构的UAS都需要critic,对比不同结构的encoder的编码分布,结果如下图:
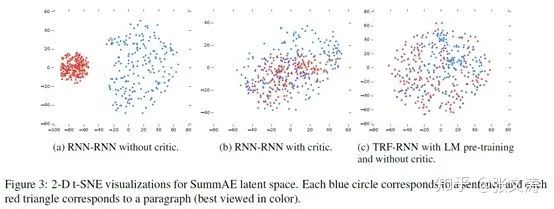
上图左边和中间的部分,说明了critic对RNN encoder的作用;上图右边部分,说明对于TRF encoder,LM pre-training具有和critic相同的效果,且单独的LM pre-training比LM pre-training + critic的效果更好,因而这种结构的UAS不需要critic;
高效的pre-training task
[42]提出三种用于abstractive summarization model的pre-training task:
(1)encoder pre-training,Corrupted Paragraph Prediction(CPP):[42]按照50%的概率随机调换paragraph中相邻的两个句子的顺序,将encoder的输出送入sigmoid classifier判断是否发生了调换;该任务要求encoder学习句间的关系;
(2)encoder pre-training,Next Sentence or Same Paragraph:[42]从document中挑选两个不同的句子,50%的概率这两个句子相邻,50%的概率这两个句子不相邻;两个句子分别使用encoder编码成隐向量,两个隐向量的点积通过sigmoid classifier判断是否相邻;该任务要求encoder将句间的关系编码进隐向量,相比Bert的NSP任务,NSSP更加困难,因为两个句子出自同一个document,具有相同的style和topic;
(3)decoder pre-training,AE LM:[42]将decoder视为LM,设置encoder的输出向量z为零向量,使用标准的自回归语言模型目标训练decoder;
[42]进行了ablation考察预训练任务对模型的提升效果,发现三种预训练和两种加噪方式都可以不同程度的提高模型的效果,且使模型生成更加流利的摘要。
为摘要生成任务构造合适的预训练任务,是目前摘要模型发展的趋势,虽然[42]在提出预训练任务时采用的是RNN-based结构的模型,但这些预训练任务的思想都可以用于Transformer-based model的预训练中;事实上,已经有很多Transformer-based model的论文提出了许多不同的预训练任务。
训练方式
UAS的训练过程分为两个阶段:pre-training和finetuning;pre-training时,不对输入的文档加噪,也不加入critic;
finetuning时,对输入的文档加噪,且同时训练encoder-decoder和critic,两者具有不同的损失函数:
(1)critic的损失函数公式如下,其中t是输入, 
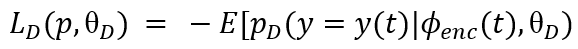
(2)encoder-decoder的损失函数公式如下,其中p是document, 





[42]按照下述方式,轮流训练encoder-decoder和critic,即首先使用 


通过上述方式,[42]得到自监督的生成式摘要模型,在[40]提出的新数据集ROCSumm上取得了SOTA;虽然[42]没有在DUC2004或CNNDM这类流行的监督语料库上进行测试,但是这种思想基本贯穿了所有自监督摘要模型的结构和训练方式。
3.2、Transformer-based Summarization model的发展过程
3.2.1、model structure的变化过程
2018-2019年,大量的预训练模型出现,也推动了生成式摘要模型结构的发展变化,这种变化受到预训练模型结构发展的深刻影响;
2018年至2019年早期,预训练模型的结构大多都是单encoder结构,如:BERT、GPT-2、ERNIE、XLNet等,这些模型的预训练任务也都是以NLU任务为主,如:解码字符级别的n-gram、句子分类、实体分类等,使得这些预训练模型更加适合NLU任务;此时,生成式摘要模型大都使用预训练模型初始化encoder,再和随机初始化的decoder共同finetuning。由于decoder缺乏预训练,这种方式使得生成式摘要模型长期处于次优结构的窘境;一些模型被出来以解决这种问题;
2019年中后期至2020年,一些seq2seq结构的预训练模型出现,如:MASS、T5等,这些模型的预训练任务也大都采用NLG的形式,使得这些预训练模型更加适合NLG任务;此时,生成式模型开始采用seq2seq结构的预训练模型,并提出了适合摘要生成任务的预训练任务,从encoder、attention到decoder全部都经预训练模型初始化,从而大幅提升了生成式摘要模型的表现,一度超过了抽取式摘要模型的表现。
预训练初始化encoder + 随机初始化decoder的基础模型结构
[17]提出基于BRET的抽取式摘要模型,及以抽取式摘要模型为encoder的生成式摘要模型,本节主要介绍生成式摘要模型的结构;
模型的结构非常简单,是BERT(encoder) + 6-layer Transformer decoder;encoder的结构及输入的形式在2.2.1三种主要的结构中进行了介绍,此处不再赘述;
训练过程分为两个阶段:(1)单独训练encoder,encoder使用BERT进行初始化,然后在抽取式摘要生成任务上进行finetuning(2)随机初始化decoder,和encoder一起,在生成式摘要生成任务上进行finetuning;此时,encoder已经进行过预训练,而decoder没有进行过预训练,为了解决这种差异,[17]使用seperate finetuning,即在同一个训练过程中,使用不同的lr和warmup参数优化encoder和decoder,encoder的lr要更小一些,避免出现在训练过程中遗忘已经学习到的信息。
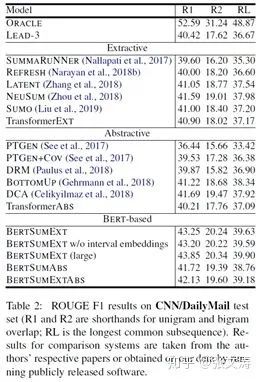
[17]使用这种方式使得生成式摘要模型可以利用抽取式摘要模型的知识,更加有效地提取文档的有效信息;虽然[17]没有使用copy mechanism,但是通过BPE tokenization有效缓解OOV的问题;实验显示,[17]在CNNDM上达到了当时的SOTA,数据如下,可见提高encoder的信息编码能力可以有效提升摘要模型的表现:
有什么改进方法呢?
虽然上述简单的模型结构就可以利用预训练的encoder获得良好的表现,但是由于decoder和attention distribution没有经过预训练初始化,无法通过在更大的训练集上预训练来学习到更加丰富的语义知识,从而限制模型的表现进一步提高;
一个最自然的想法是使用pre-trained LM初始化decoder,事实上很多模型也是这样做的,通过在更丰富的语料上对decoder进行预训练,提高decoder的表达能力,这种方式也确实进一步提高了模型的表现,成为早期生成式预训练摘要模型的标准训练方法;
但是,即使对encoder和decoder分别使用预训练模型进行初始化,对于RNN-based model来说,decoder-encoder attention无法充分的预训练,对于Transformer-based model来说,encoder-decoder multi-head attention无法进行充分的预训练,从而限制了decoder对encoder编码的信息的筛选能力;一些模型对这个问题提出了改进方法;
如:[43]提出,利用BERT可以提高生成式摘要模型的表现,但是decoder的解码方式是从左至右解码,每个token仅能attend左边的上下文,而BERT在预训练时,每个token可以attend两边的上下文;因此,直接使用BERT作为decoder会限制其在解码时的效果。
为此,[43]提出two-stage decoder,首先使用auto-regressive decoder生成draft summaries,然后使用BERT-based decoder对draft summaries进行rewrite,生成refined summaries;模型结构如下图:
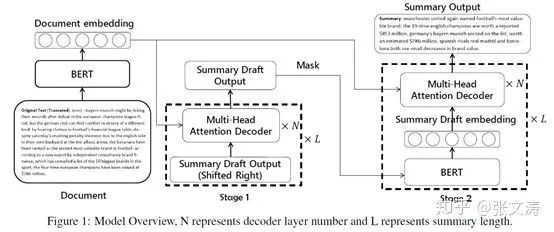
Encoder是BERT,输入是原文档tokens的表示向量,输出是tokens的上下文向量;
Decoder由两部分组成:Draft decoder和Refine decoder:
Draft decoder是12-layer 12-head Transformer decoder,第一层decoder的第t步的输入是第t-1步预测的词向量,draft decoder与encoder共享BERT的embeddings matrix,且第1步的输入是[PAD]向量;encoder-decoder multi-head attention利用encoder编码的上下文向量计算attention distribution;
Draft decoder引入了copy mechanism,使用下式计算Pointer distribution:
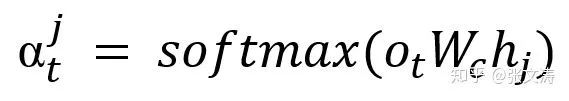
其中, 
同时,利用下式计算Switch:
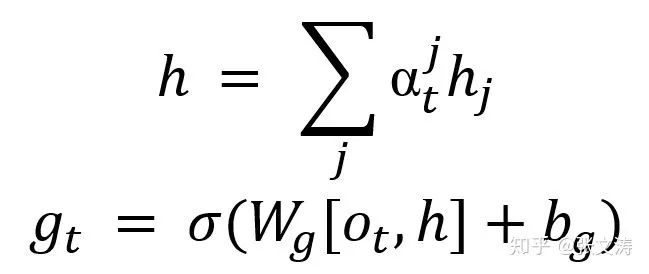
Draft decoder使用soft Switch得到最终的解码的概率分布:
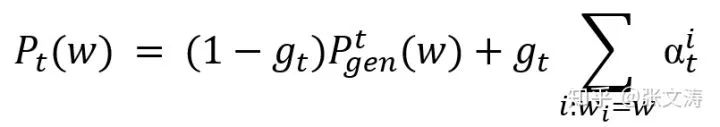
Draft decoder通过上述方式生成draft summary,[43]认为该summary的质量受decoder的能力限制,质量不尽如人意,需要经过Refine decoder对其进行修正。
Refine decoder是BERT + 12layer 12-head Transformer decoder,不与encoder共享embeddings matrix,但与Draft decoder共享Transformer decoder的参数;
Refine decoder的输入是masked draft summary,其第t步解码方式如下:
(1)将draft summary中第t个token进行mask,得到masked draft summary;
(2)将masked draft summary经BERT编码得到上下文向量,此时每个token都包含两边的上下文信息,而非仅包含左边的上下文信息;
(3)将(2)的上下文向量作为Transformer decoder的输入,encoder编码的上下文信息作为encoder-decoder multi-head attention的输入,预测第t个token的概率分布;在训练时,target token是masked token,在预测时,选择概率最大的token作为target token;需注意,Transformer decoder的输入总是全部的masked draft summary;
Refine decoder通过上述方式,根据draft summary的长度迭代进行解码,生成相同长度的refine summary;该解码过程与BERT的MLM任务类似,可以充分利用BERT使用两边的上下文进行解码的能力,生成信息更充分、更加流利的摘要。
[43]并非使用one-stage end-to-end的训练方式,而是复用encoder,使用teacher-forcing同时训练draft decoder和refine decoder;两个decoder使用相同的encoder信息,输入都是gold summary,损失函数都是MLE loss,目标是拟合gold summary;同时,[43]使用self-critic RL training训练draft decoder,以ROUGE-L F1为reward。
预测时,draft decoder使用beam search解码,选择最好的draft summary;在beam search时,采用repetitive trigram avoidance避免生成重复的内容;refine decoder采用greedy strategy解码。
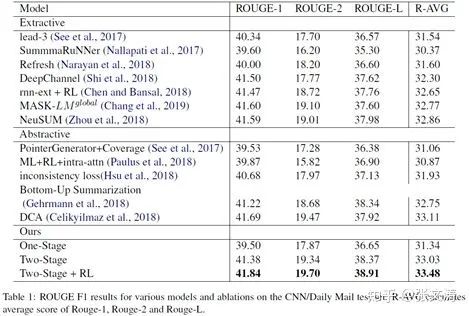
[43]在CNNDM上进行了ablation,数据如下图,two-stage model达到了当时的SOTA:
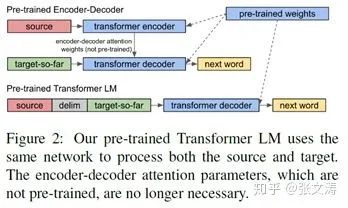
再如:[44]提出,在文本生成任务,如生成式摘要生成任务中,如果使用encoder-decoder model,通常只能使用pre-trained model初始化encoder和decoder的参数,attention parameters只能采用随机初始化,这限制了pre-trained model的作用;为此,[44]提出一种decoder-only的generation model,保证所有参数都可以使用pre-trained LM进行初始化,最大程度利用预训练的效果提高下游任务的表现;
[44]的baseline是GPT,模型的结构如下图;上边部分是encoder-decoder model的初始化方式,可见两个Transformer间的attention parameters无法使用预训练模型初始化;下边部分是decoder-only model的初始化方式,由于没有attention parameters,所以全部参数都可以经预训练模型初始化:
[44]的输入是由文档和摘要通过<delim>拼接得到的,与standard GPT使用的casual-masking不同,[44]使用的masking由两部分组成,在source部分是non-masking(BERT型),在target部分是casual-masking(GPT型),即每个source token只能看到左右两边的source的tokens,而每个target tokens只能看到所有source tokens和左边的target tokens,这相当于T5和uniLM中的prefix masking;
通过这种方式,将encoder和decoder整合至一个单独的Transformer-based LM中,使得所有参数都可以被pre-trained LM初始化;[44]没有使用诸如RL Loss,copy mechanism等增强方法。
pre-training时,pre-training task是GPT的LM task,而非BERT的MLM;finetuning时,使用MLE/CE Loss,且只计算target部分的loss。
[44]的实验显示,pre-training可以提高模型的表现,而保证所有参数都可以经pre-trained model初始化的模型可以进一步提高模型的表现;而且,pre-trained decoder only的表现比pre-trained encoder only差,可能是因为模型在生成摘要时更加依赖充分训练的encoder,如果encoder疏于训练,deocder无法获得有关source的有效信息;
然而,虽然[44]可以提高摘要模型的表现,但是这种结构的模型在预测时存在很大的不效率,在每步解码时,都需要编码所有source和已生成的target,严重降低了预测的效率,因此这种结构的摘要模型更多提供的是一种思想,在接下来的诸多摘要模型中出现的并不多。
预训练seq2seq的模型结构
随着MASS和T5的问世,seq2seq结构的生成式摘要模型也逐渐成熟起来,在更大更丰富的语料上进行训练的摘要模型,表现一度超过了抽取式模型,成为CNNDM等语料上的SOTA。
[45]提出的baseline是standard Transformer,模型结构如下图,使用正弦余弦绝对位置编码;[45]训练了两个不同参数大小的模型,PEGASUS-base和PEGASUS-large,前者使用Transformer-base,后者使用Transformer-large;[45]还提出了没有pre-training的PEGASUS-base,即Transformer-base,作为对比:
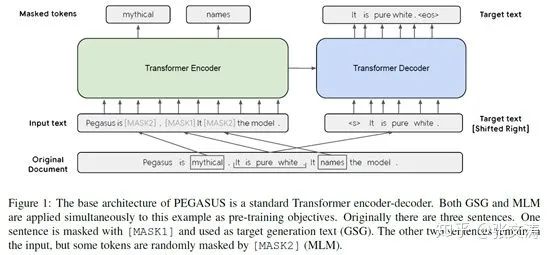
[45]提出,如果pre-training task在形式上与finetuning task类似,则有利于提升finetuning task的表现;为此,[45]提出一个专用于abstractive summarization task的pre-training task,即gap sentences generation(GSG),相关细节将在3.2.2中介绍。
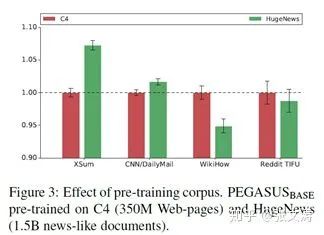
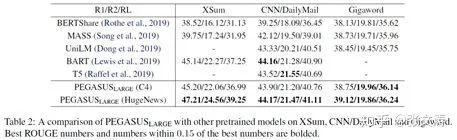
[45]提出,如果pre-training corpus与finetuning corpus的type相似,则有利于提升finetuning task的表现;为此,[45]提出两个pre-training corpus,C4和HugeNews;前者是[T5][Raffle et al.]提出的,大小750GB,且绝大部分文章不是news-type的;后者是论文收集的news-type articles corpus,大小3.8TB,其中包含CNNDM、NYT等corpus;
同样地,finetuning corpus共有12个,其中6个corpus是news-type的。
[45]首先分别在两个pre-trained corpus上进行pre-training,然后分别在不同的finetuning corpus上进行finetuning,对比corpus type对下游任务的影响;
实验显示,在C4上预训练的模型在non-news-type的finetuning corpus(wikihow/reddit)上的表现更好,在HugeNews上预训练的模型在news-type的finetuning corpus(XSum/ CNNDM)上的表现更好,说明pre-training corpus type对下游任务的影响很大,in-domain training可以提高下游任务的表现:
训练时,目标函数是MLE loss,使用Adafactor optimizer,square root learning rate decay,在beam search时使用length penalty;
预测时,[45]没有使用任何防止重复生成的机制,但[45]发现生成的摘要中重复生成的比例非常小;这似乎说明,模型重复生成是因为encoder和decoder没有像pre-trained model一样经过充分的预训练,没有在全词汇表上建立良好的语言模型,因而只能围绕少数几个学习较好的点重复生成内容;
[45]对比BPE和SentencePiece Unigram在不同词汇表规模下的影响,如下图:
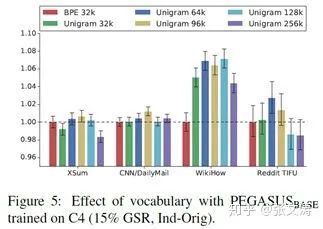
在news-type corpus上,两种tokenizers的效果差不多,但是在non-news-type corpus上,SentencePiece Unigram的表现要好得多;
[45]发现,在CNNDM、BIGPATENT等corpus中,测试集文档的长度经常会超过训练集文档的最长长度,但是PEGASUS可以在最长1024个tokens的长度的测试集上泛化得很好;[45]认为,该现象证明了正弦余弦位置向量在长输入上具有较好的泛化能力,使得模型可以处理超出训练长度的输入文档;
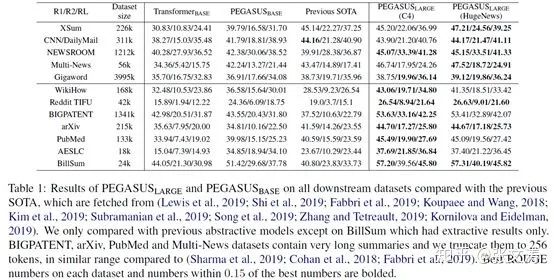
[45]在finetuning corpus上的表现如下图,可以发现:(1)在C4上训练的PEGASUS在non-news corpus上达到了SOTA,在HugeNews上训练的PEGASUS在news corpus上达到了SOTA(2)从Transformer-base到PEGASUS-large的提升,在规模越小的数据集上越大,说明pre-training对小数据集具有重要的作用;
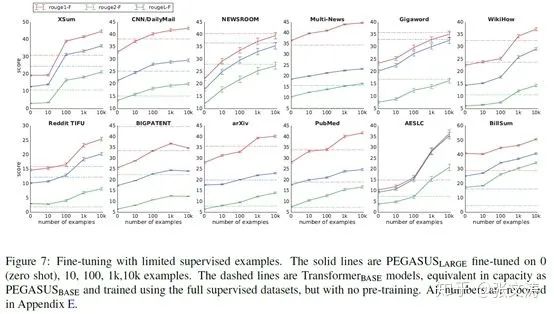
[45]测试模型在low-source corpus上的zero-shot预测的效果,发现往往只需要几百至几千的样本上finetuning,就可以达到Transformer-base在全数据集上训练达到的结果:
一些对模型结构的探讨
[46]的目的是考察multi-head attentions是否会在abstractive summarization task中形成某些特化的关注,即重点关注某些特殊的部分;
经过三个实验,论文得出如下结论:
(1)encoder和decoder中,确实会有一些head形成某种特化关注,关注输入中的某些特殊片段,例如:相邻的tokens、名词、动词、标点符号、POS等;
(2)更具体地说,在decoder中某些head会特化关注某些POS或entities;而在encoder中没有发现这种特化,encoder中某些head会特化关注相邻的tokens,这种特化更多地在encoder中出现,更少地在decoder中出现;
(3)然而,这些特化并非是强烈的,而是有限的特化;这些特化的head有时也会关注很多非特化的文本片段;
(4)相同的模型结构在不同的参数下会有不同的特化,这种特化可能无法反映在两个模型的ROUGE scores上(scores类似),但解释了某些模型更加擅长处理某种特化文本出现较多的articles;
(5)对于特化关注entities的model,由于并非所有articles中都会出现entities,所以在处理不包含entities的articles时,这类model的效果就会被减弱;此时,这些特化的head会关注一些形式上类似entities的tokens。
3.2.2、合适摘要生成任务的pre-training task
[45]提出,如果pre-training task在形式上与finetuning task类似,则有利于提升finetuning task的表现;为此,论文提出一个专用于abstractive summarization task的pre-training task,即gap sentences generation(GSG):
首先,计算文档中每个句子与剩余句子的ROUGE-1 F1,从而为每个句子计算一个重要性得分;从文档中挑选45%的重要性得分最高的句子,其中80%的句子用[MSAK]代替,剩余20%的句子保持不变,以鼓励模型偏向于从文档中复制句子作为摘要;上述挑选句子的方法被称为Ind-Ori,[45]还提出了其他几种方法作为对比,但经试验证明Ind-Ori的效果最好;
然后,将masked document作为输入,通过一个Transformer encoder-decoder按顺序生成masked sentences,句间用[SEP]分隔;模型利用masked sentences的上下文信息,生成重要性较高的masked sentences,这种任务形式与summarization task非常类似:
GSG的形式与T5的预训练任务非常相似,差别在于,T5的预训练任务是character level的,随机选择连续的3个character上进行mask,模型学习根据上下文预测masked characters;而GSG是sentence level的,每次mask整个句子,模型学习根据其他句子预测masked sentence,从而不仅学习到短语级别的语义信息,还学习到句子级别的语义信息和句子间的共现信息。
[45]还提到MLM task可以与GSG task一起用于pre-training,但实验发现,MLM task对下游任务没有提升,因为在预训练阶段仅使用GSG。
3.2.3、graph-based summarization mdel
GNN-based method
在本节,让我们继续事实三元组的话题(前文见3.2.10)。随着GNN的发展,生成式摘要模型开始使用GNN处理graph inputs,希望可以使模型从图结构中学习到更丰富的语义关系和领域知识,生成事实逻辑一致的摘要,提高摘要的质量。
[47]使用Stanford OpenIE从文档中抽取出事实三元组后,使用Levi transformation将这些三元组构建为文档的知识图谱;具体来讲,对于每个三元组(subject,relation,object),将subject、relation和object作为vertex,并将subject->relation和relation->object作为edge;对每个三元组都进行这种transformation,即可以得到知识图谱G=(V,E)。
为了将文档的知识图谱整合至摘要模型中,[47]提出带有GNN结构的生成式摘要模型,使用GNN从知识图谱中提取语义信息和结构信息,结构如下图:
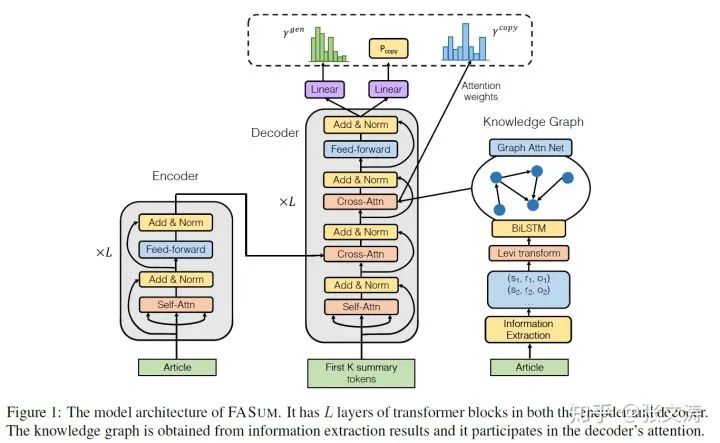
模型由三部分组成:Text Encoder、Graph Encoder和Decoder:
上图左边部分是Text Encoder,是standard 10-layer 8-head Transformer encoder;
上图右边部分是Graph Encoder,文档经OpenIE和Levi transformation后得到知识图谱,图中的每个vertex都对应文档中的一个metion t(v),如:vertex(cat)->metion(a cat);然后Graph Encoder按下述方式编码图的信息:
(1)t(v)是文档中的一个文本片段,使用一个bi-LSTM对其进行编码,使用last hidden state作为该metion对应的vertex的初始node embeddings;
(2)使用2-layer GAN编码图的结构信息,每层的GAN公式如下;其中,neighbor(i)是vertex i的所有相邻vertex, 
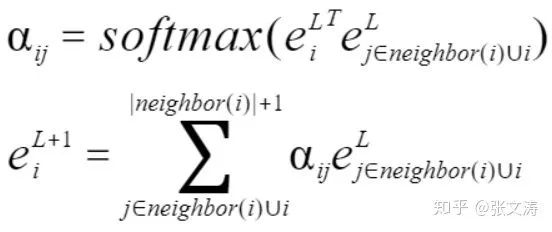
由此,Graph Encoder得到文档的知识图谱中每个vertex的node embeddings。
上图中间部分是Decoder,10-layer 8-head Transformer decoder,与standard Transformer deocder相比,不同的地方在增加了graph-decoder multi-head attention;解码时,decoder按下式attend全部node embeddings:
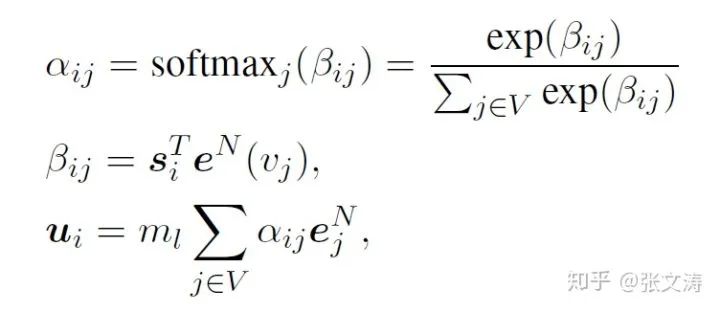
其中, 

经过三次multi-head attention transformation,decoder得到同时编码了Text Encoder和Graph Encoder信息的隐向量,继而使用该隐向量解码在vocabulary上的概率分布。
需要注意的是,Decoder引入了copy mechanism;Decoder使用graph-decoder attention 
Decoder按照下式计算Switch,并使用soft Switch计算最终的解码结果,其中 

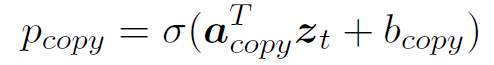
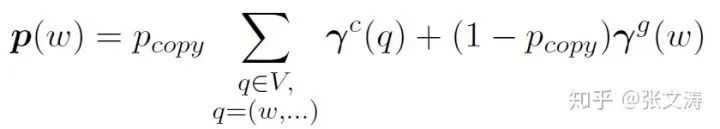
训练时,使用MLE/CE Loss作为目标函数。
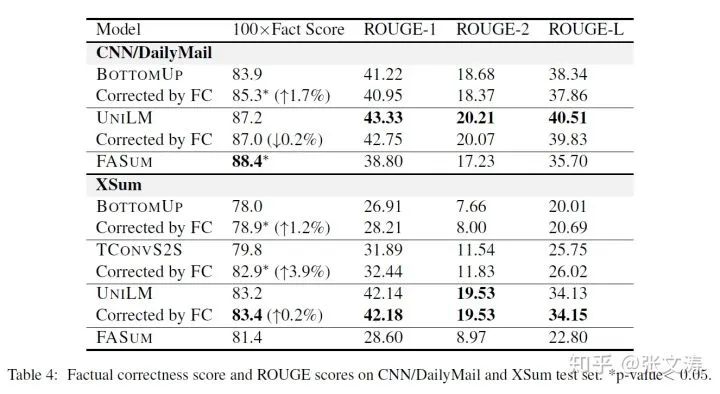
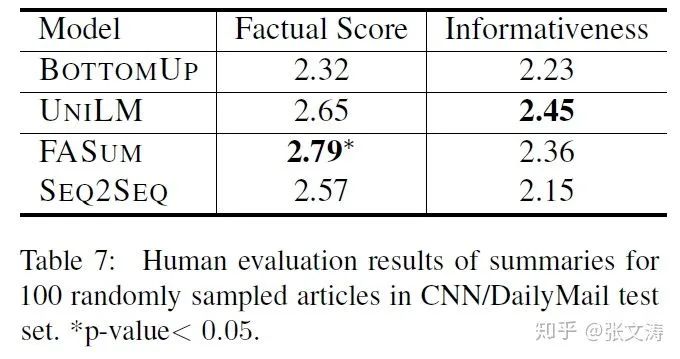
[47]在CNNDM/XSum上进行了实验,数据如下图,可以发现,虽然模型在ROUGE scores上的表现不佳,但是在事实正确率上达到了最佳;对其他摘要模型中增加Graph Encoder后,事实正确率基本都得到了提升, 在CNNM上ROUGE scores出现小幅下降,但在XSum上出现小幅上升,这似乎说明ROUGE scores并不总是反映事实正确率:
[47]进行了人工评估,数据如下,[47]在事实正确率上达到了最佳,在信息性上第二,经过大量语料预训练的UNILM则在信息性上达到了最佳:
transX-based method
前文提到的graph-based model,都是对原文中的事实进行抽取,并将其整合至摘要模型。但是摘要生成的事实性错误,除了指与原文中事实相违背的内容,还有与人们的常识相违背的内容,为此,需要将常识性知识图谱也整合至摘要模型。
但是,这类知识图谱通常规模都很大,每次解码时都使用GNN编码整个知识图谱会大幅降低模型的预测效率;为此,使用transX预先为知识图谱中的vertex和edge训练embeddings,再将其通过合理的方式整合至知识图谱中成为现实的选择。
[48]从Wikidata中进行数据采样,构造了一个较小规模的常识性知识图谱,并使用transE为图中的vertex和edge都训练一个embeddings,摘要模型中只使用node embeddings;
[48]提出的baseline是Transformer-XL,相比vanilla Transformer,这种结构可以处理序列更长的输入,保持分段输入间的语义关系,模型结构如下图:
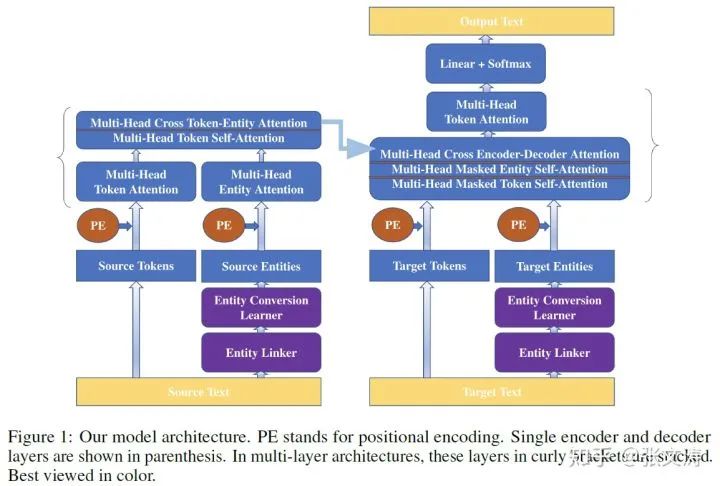
模型的结构非常简单,Entity Linker是一个实体链接模型,从文档中寻找实体并将其与知识图谱中的实体相关联;Entity Conversion Learner是MLP,激活函数是ReLU,其目的是将实体的node embeddings转换至token embeddings的分布空间;PE是位置编码。
encoder和decoder中,分别按照上图中的attention描述进行attention计算,同一蓝色方框内的不同attention并行计算,并将结果进行线性变换放大至token size的维度后,拼接作为输出矩阵。
[48]在CNNDM上进行了实验,数据如下图,虽然从ROUGE scores的角度来讲,模型的表现可以说较差,远逊于当时的SOTA,但是模型的思路可以作为一种整合知识图谱的思路继续进行研究:

4、结语
本文章对2015年-2019年的摘要模型的发展变化进行了详细的分析和介绍,从任务定义方面,区分为抽取式摘要模型和生成式摘要模型,从时间发展方面,区分为RNN-based模型和Transformer-based模型,对模型的结构、训练方式、输入信息的发展和变化进行了讲解。
本文章没有按照论文的方式进行介绍,而是将诸多论文揉碎,按照论文提及的摘要模型的每个结构的方式进行介绍,此举是希望大家可以将摘要模型拆分成诸多结构,对每个结构的优化过程和原因都有所了解,从而在实际应用中可以自由地组合拆分这些结构。
本文章虽然目前仅对2015年-2019年的摘要模型进行了介绍,但未来将定时更新摘要模型的最新进展,希望大家都可以关注本文章,时常回来查看更新。
参考文献
[20][2015][Rush et al.][A Neural Attention Model for Abstractive Sentence Summarization][ABS]
[21][2016][Nallapati et al.][Abstractive Text Summarization Using Sequence-to-Sequence RNNs and Beyond][Beyond]
[22][2017][Jiwei Tian][Abstractive Document Summarization with a Graph-Based Attentional Neural Model][GraphAtt]
[23][2018][Chen et al.][Fast Abstractive Summarization with Reinforce-Selected Sentence Rewriting][FastSum]
[24][2017][See et al.][Get To The Point: Summarization with Pointer-Generator Networks][PGNet]
[25][2018][Paulus][A Deep Reinforced Model for Abstractive Summarization][DeepRL]
[26][2017][Suzuki et al.][Cutting-off Redundant Repeating Generations for Neural Abstractive Summarization][WFE]
[27][2018][Nema et al.][Diversity driven Attention Model for Query-based Abstractive Summarization][SD2]
[28][2018][Celikyilmaz et al.][Deep Communicating Agents for Abstractive Summarization][DCA]
[29][2018][Gehrman et al.][Bottom-Up Abstractive Summarization][BottomUp]
[30][2018][Wang et al.][A Reinforced Topic-Aware Convolutional Sequence-to-Sequence Model for Abstractive Text Summarization][RTACS2S]
[31][2019][Wang et al.][BiSET: Bi-directional Selective Encoding with Template for Abstractive Summarization][BiSET]
[32][2019][Wang et al.][Concept Pointer Network for Abstractive Summarization][ConceptPointer]
[33][2018][Celikyilmaz et al.][Deep Communicating Agents for Abstractive Summarization][DCA]
[34][2018][Narayan et al.][Don’t Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization][Extreme]
[35][2018][Grusky et al.][Newsroom: A Dataset of 1.3 Million Summaries with Diverse Extractive Strategies]
[36][2018][Kryscinski et al.][Improving Abstraction in Text Summarization][LMSum]
[37][2018][Pasunuru et al.][Multi-Reward Reinforced Summarization with Saliency and Entailment][MRR]
[38][2018][Guo et al.][Soft Layer-Specific Multi-Task Summarization with Entailment and Question Generation][MTLSum]
[39][2018][Fan et al.][Controllable Abstractive Summarization][CASum]
[40][2018][Liu et al.][Toward Abstractive Summarization Using Semantic Representations][AMRSum]
[41][2018][Cao et al.][Faithful to the original: Fact aware neural abstractive summarization][FTSum]
[42][2019][Liu et al.][SummAE: Zero-Shot Abstractive Text Summarization using Length-Agnostic Auto-Encoders][SummAE]
[43][2019][Zhang et al.][Pretraining-Based Natural Language Generation for Text Summarization][DraftSum]
[44][2019][Khandelwal][Sample Efficient Text Summarization Using a Single Pre-Trained Transfor-mer][TransLMSum]
[45][2019][Zhang et al.][PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Sum-marization][PEGASUS]
[46][2019][Baan et al.][ Do Transformer Attention Heads Provide Transparency in Abstractive Sum-marization]
[47][2020][Zhu et al.][Boosting Factual Correctness of Abstractive Summarization with Knowledge Graph][FASum]
[48][2019][Gunel et al.][Mind The Facts: Knowledge-Boosted Coherent Abstractive Text Summarization][KGSum]
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,点个在看吧👇



