迁移学习:如何将预训练CNN当成特征提取器

本文为 AI 研习社编译的技术博客,原标题 :
Transfer Leaning: How a Pre-Trained CNN could be used as a Feature Extractor
作者 | Rakesh Thoppaen
翻译 | Disillusion
校对 | 酱番梨 整理 | 菠萝妹
原文链接:
https://medium.com/@Rakesh.thoppaen/transfer-leaning-3f5f89a40011
注:本文的相关链接请点击文末【阅读原文】进行访问
迁移学习:如何将预训练CNN当成特征提取器
目标:学习如何使用预训练网络对完全不同的数据集进行分类

迁移学习涉及到使用一个特定数据集上训练的模型
然后将其应用到另一个数据集上
使用预训练好的模型作为“捷径”,从其没有训练过的数据中学习模式的能力。
深度学习的魅力在于预训练好的模型能够对完全不同的数据集进行分类。这种能力内用了这些深度神经网络结构(在ImageNet数据集上进行过训练)的预训练权重并把其应用在我们自己的数据集上。
在产业中能用到的预训练模型如下:
Xception
VGG16
VGG19
ResNet50
InceptionV3
InceptionResNetV2
MobileNet
//这些预训练模型是keras的一部分。
一些流行的现有深度学习框架包括:Tensorflow, Theano, Caffe, Pytorch, CNTK, MXNet, Torch, deeplearning4j, Caffe2 。
Keras
Keras 是一种高层API,Keras由Python编写而成并能够在TensorFlow、Theano以及CNTK上运行。Keras提供了一种简单及模块化的API去创建和训练神经网络,省去了大部分复杂的细节。这让你入门深度学习变得非常简单。
Keras用到了一些以Theano、TensorFlow为后端的深度学习函数库。同时,这些函数库通过一些更低层次的函数库与硬件进行沟通。例如,如果你在CPU上运行程序,Tensorflow或者Theano应用BLAS函数库。另一方面,当你在GPU上运行程序时,它们则会应用CUDA和cuDNN函数库。
如果你正在建立一个新系统,你可能会想看一下这篇文章。
Keras提供了一种让训练和评估模型变得极其简单的工作流程。详见下图:
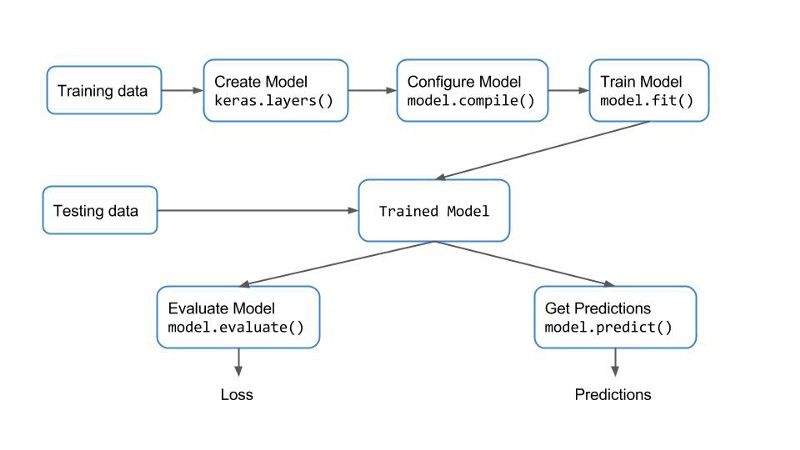
Keras Workflow
通过特征提取进行迁移学习案例:花的分类
步骤0:排列数据——训练/测试和配置文件
我们将使用来自牛津大学的FLOWERS17数据集,从这里下载数据集。你可以选择任何数据并使用以下代码执行分类。将标注好的训练数据和测试数据放在dataset文件夹中。
保存下列json代码并命名为conf.json在上图的conf文件夹中。
对“model”, “feature_path”, “label_path”, ”results” 依据你将要选择的网络进行修改。在下述案例种,我使用了mobilenet预训练网络。
“num_classes”表示你数据集中类的数量。
{
"model" : "mobilenet",
"weights" : "imagenet",
"include_top" : false,
"train_path" : "dataset/train",
"test_path" : "dataset/test",
"features_path" : "output/flowers_17/mobilenet/features.h5",
"labels_path" : "output/flowers_17/mobilenet/labels.h5",
"results" : "output/flowers_17/mobilenet/results.txt",
"classifier_path" : "output/flowers_17/mobilenet/classifier.pickle",
"model_path" : "output/flowers_17/mobilenet/model","test_size" : 0.10,
"seed" : 9,
"num_classes" : 17
}类似的,如果你想用只有4个类的inceptionV3而不是mobilenet,使用以下json代码。
{
“model” : “inceptionv3”,
“weights” : “imagenet”,
“include_top” : false,
“train_path” : “dataset/train”,
“test_path” : “dataset/test”,
“features_path” : “output/flowers_17/inceptionv3/features.h5”,
“labels_path” : “output/flowers_17/inceptionv3/labels.h5”,
“results” : “output/flowers_17/inceptionv3/results.txt”,
“classifier_path” : “output/flowers_17/inceptionv3/classifier.pickle”,
“model_path” : “output/flowers_17/inceptionv3/model”,“test_size” : 0.10,
“seed” : 9,
“num_classes” : 4
}步骤1:特征提取
# filter warnings
import warnings
warnings.simplefilter(action="ignore", category=FutureWarning)
# keras imports
from keras.applications.vgg16 import VGG16, preprocess_input
from keras.applications.vgg19 import VGG19, preprocess_input
from keras.applications.xception import Xception, preprocess_input
from keras.applications.resnet50 import ResNet50, preprocess_input
from keras.applications.inception_resnet_v2 import InceptionResNetV2, preprocess_input
from keras.applications.mobilenet import MobileNet, preprocess_input
from keras.applications.inception_v3 import InceptionV3, preprocess_input
from keras.preprocessing import image
from keras.models import Model
from keras.models import model_from_json
from keras.layers import Input# other imports
from sklearn.preprocessing import LabelEncoder
import numpy as np
import glob
import cv2
import h5py
import os
import json
import datetime
import time
# load the user configs
with open('conf/conf.json') as f:
config = json.load(f)
# config variables
model_name = config["model"]
weights = config["weights"]
include_top = config["include_top"]
train_path = config["train_path"]
features_path = config["features_path"]
labels_path = config["labels_path"]
test_size = config["test_size"]
results = config["results"]
model_path = config["model_path"]
# start time
print ("[STATUS] start time - {}".format(datetime.datetime.now().strftime("%Y-%m-%d %H:%M")))
start = time.time()# create the pretrained models
# check for pretrained weight usage or not
# check for top layers to be included or not
if model_name == "vgg16":
base_model = VGG16(weights=weights)
model = Model(input=base_model.input, output=base_model.get_layer('fc1').output)
image_size = (224, 224)
elif model_name == "vgg19":
base_model = VGG19(weights=weights)
model = Model(input=base_model.input, output=base_model.get_layer('fc1').output)
image_size = (224, 224)
elif model_name == "resnet50":
base_model = ResNet50(weights=weights)
model = Model(input=base_model.input, output=base_model.get_layer('flatten').output)
image_size = (224, 224)
elif model_name == "inceptionv3":
base_model = InceptionV3(include_top=include_top, weights=weights, input_tensor=Input(shape=(299,299,3)))
model = Model(input=base_model.input, output=base_model.get_layer('custom').output)
image_size = (299, 299)
elif model_name == "inceptionresnetv2":
base_model = InceptionResNetV2(include_top=include_top, weights=weights, input_tensor=Input(shape=(299,299,3)))
model = Model(input=base_model.input, output=base_model.get_layer('custom').output)
image_size = (299, 299)
elif model_name == "mobilenet":
base_model = MobileNet(include_top=include_top, weights=weights, input_tensor=Input(shape=(224,224,3)), input_shape=(224,224,3))
model = Model(input=base_model.input, output=base_model.get_layer('custom').output)
image_size = (224, 224)
elif model_name == "xception":
base_model = Xception(weights=weights)
model = Model(input=base_model.input, output=base_model.get_layer('avg_pool').output)
image_size = (299, 299)
else:
base_model = Noneprint ("[INFO] successfully loaded base model and model...")
# path to training dataset
train_labels = os.listdir(train_path)
# encode the labels
print ("[INFO] encoding labels...")
le = LabelEncoder()
le.fit([tl for tl in train_labels])
# variables to hold features and labels
features = []
labels = []
# loop over all the labels in the folder
count = 1
for i, label in enumerate(train_labels):
cur_path = train_path + "/" + label
count = 1
for image_path in glob.glob(cur_path + "/*.jpg"):
img = image.load_img(image_path, target_size=image_size)
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
feature = model.predict(x)
flat = feature.flatten()
features.append(flat)
labels.append(label)
print ("[INFO] processed - " + str(count))
count += 1
print ("[INFO] completed label - " + label)
# encode the labels using LabelEncoder
le = LabelEncoder()
le_labels = le.fit_transform(labels)
# get the shape of training labels
print ("[STATUS] training labels: {}".format(le_labels))
print ("[STATUS] training labels shape: {}".format(le_labels.shape))
# save features and labels
h5f_data = h5py.File(features_path, 'w')
h5f_data.create_dataset('dataset_1', data=np.array(features))
h5f_label = h5py.File(labels_path, 'w')
h5f_label.create_dataset('dataset_1', data=np.array(le_labels))
h5f_data.close()
h5f_label.close()
# save model and weights
model_json = model.to_json()
with open(model_path + str(test_size) + ".json", "w") as json_file:
json_file.write(model_json)
# save weights
model.save_weights(model_path + str(test_size) + ".h5")
print("[STATUS] saved model and weights to disk..")
print ("[STATUS] features and labels saved..")
# end time
end = time.time()
print ("[STATUS] end time - {}".format(datetime.datetime.now().strftime("%Y-%m-%d %H:%M")))步骤2:训练
# organize imports
from __future__ import print_function
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
import numpy as np
import h5py
import os
import json
import pickle
import seaborn as sns
import matplotlib.pyplot as plt
# load the user configs
with open('conf/conf.json') as f:
config = json.load(f)
# config variables
test_size = config["test_size"]
seed = config["seed"]
features_path = config["features_path"]
labels_path = config["labels_path"]
results = config["results"]
classifier_path = config["classifier_path"]
train_path = config["train_path"]
num_classes = config["num_classes"]
classifier_path = config["classifier_path"]
# import features and labels
h5f_data = h5py.File(features_path, 'r')
h5f_label = h5py.File(labels_path, 'r')
features_string = h5f_data['dataset_1']
labels_string = h5f_label['dataset_1']
features = np.array(features_string)
labels = np.array(labels_string)
h5f_data.close()
h5f_label.close()
# verify the shape of features and labels
print ("[INFO] features shape: {}".format(features.shape))
print ("[INFO] labels shape: {}".format(labels.shape))
print ("[INFO] training started...")
# split the training and testing data
(trainData, testData, trainLabels, testLabels) = train_test_split(np.array(features),
np.array(labels),
test_size=test_size,
random_state=seed)print ("[INFO] splitted train and test data...")
print ("[INFO] train data : {}".format(trainData.shape))
print ("[INFO] test data : {}".format(testData.shape))
print ("[INFO] train labels: {}".format(trainLabels.shape))
print ("[INFO] test labels : {}".format(testLabels.shape))
# use logistic regression as the model
print ("[INFO] creating model...")
model = LogisticRegression(random_state=seed)
model.fit(trainData, trainLabels)
# use rank-1 and rank-5 predictions
print ("[INFO] evaluating model...")
f = open(results, "w")
rank_1 = 0
rank_5 = 0
# loop over test data
for (label, features) in zip(testLabels, testData):
# predict the probability of each class label and
# take the top-5 class labels
predictions = model.predict_proba(np.atleast_2d(features))[0]
predictions = np.argsort(predictions)[::-1][:5]
# rank-1 prediction increment
if label == predictions[0]:
rank_1 += 1
# rank-5 prediction increment
if label in predictions:
rank_5 += 1
# convert accuracies to percentages
rank_1 = (rank_1 / float(len(testLabels))) * 100
rank_5 = (rank_5 / float(len(testLabels))) * 100
# write the accuracies to file
f.write("Rank-1: {:.2f}%\n".format(rank_1))
f.write("Rank-5: {:.2f}%\n\n".format(rank_5))
# evaluate the model of test data
preds = model.predict(testData)
# write the classification report to file
f.write("{}\n".format(classification_report(testLabels, preds)))
f.close()
# dump classifier to file
print ("[INFO] saving model...")
pickle.dump(model, open(classifier_path, 'wb'))
# display the confusion matrix
print ("[INFO] confusion matrix")
# get the list of training lables
labels = sorted(list(os.listdir(train_path)))
# plot the confusion matrix
cm = confusion_matrix(testLabels, preds)
sns.heatmap(cm,
annot=True,
cmap="Set2")
plt.show()步骤3:测试
# test script to preform prediction on test images inside
# dataset/test/
# -- image_1.jpg
# -- image_2.jpg
# ...
# organize imports
from __future__ import print_function
# keras imports
from keras.applications.vgg16 import VGG16, preprocess_input
from keras.applications.vgg19 import VGG19, preprocess_input
from keras.applications.xception import Xception, preprocess_input
from keras.applications.resnet50 import ResNet50, preprocess_input
from keras.applications.inception_resnet_v2 import InceptionResNetV2, preprocess_input
from keras.applications.mobilenet import MobileNet, preprocess_input
from keras.applications.inception_v3 import InceptionV3, preprocess_input
from keras.preprocessing import image
from keras.models import Model
from keras.models import model_from_json
from keras.layers import Input# other imports
from sklearn.linear_model import LogisticRegression
import numpy as np
import os
import json
import pickle
import cv2
# load the user configs
with open('conf/conf.json') as f:
config = json.load(f)
# config variables
model_name = config["model"]
weights = config["weights"]
include_top = config["include_top"]
train_path = config["train_path"]
test_path = config["test_path"]
features_path = config["features_path"]
labels_path = config["labels_path"]
test_size = config["test_size"]
results = config["results"]
model_path = config["model_path"]
seed = config["seed"]
classifier_path = config["classifier_path"]
# load the trained logistic regression classifier
print ("[INFO] loading the classifier...")
classifier = pickle.load(open(classifier_path, 'rb'))
# pretrained models needed to perform feature extraction on test data too!
if model_name == "vgg16":
base_model = VGG16(weights=weights)
model = Model(input=base_model.input, output=base_model.get_layer('fc1').output)
image_size = (224, 224)
elif model_name == "vgg19":
base_model = VGG19(weights=weights)
model = Model(input=base_model.input, output=base_model.get_layer('fc1').output)
image_size = (224, 224)
elif model_name == "resnet50":
base_model = ResNet50(weights=weights)
model = Model(input=base_model.input, output=base_model.get_layer('flatten').output)
image_size = (224, 224)
elif model_name == "inceptionv3":
base_model = InceptionV3(include_top=include_top, weights=weights, input_tensor=Input(shape=(299,299,3)))
model = Model(input=base_model.input, output=base_model.get_layer('custom').output)
image_size = (299, 299)
elif model_name == "inceptionresnetv2":
base_model = InceptionResNetV2(include_top=include_top, weights=weights, input_tensor=Input(shape=(299,299,3)))
model = Model(input=base_model.input, output=base_model.get_layer('custom').output)
image_size = (299, 299)
elif model_name == "mobilenet":
base_model = MobileNet(include_top=include_top, weights=weights, input_tensor=Input(shape=(224,224,3)), input_shape=(224,224,3))
model = Model(input=base_model.input, output=base_model.get_layer('custom').output)
image_size = (224, 224)
elif model_name == "xception":
base_model = Xception(weights=weights)
model = Model(input=base_model.input, output=base_model.get_layer('avg_pool').output)
image_size = (299, 299)
else:
base_model = None# get all the train labels
train_labels = os.listdir(train_path)
# get all the test images paths
test_images = os.listdir(test_path)
# loop through each image in the test data
for image_path in test_images:
path = test_path + "/" + image_path
img = image.load_img(path, target_size=image_size)
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
feature = model.predict(x)
flat = feature.flatten()
flat = np.expand_dims(flat, axis=0)
preds = classifier.predict(flat)
prediction = train_labels[preds[0]]
# perform prediction on test image
print ("I think it is a " + train_labels[preds[0]])
img_color = cv2.imread(path, 1)
cv2.putText(img_color, "I think it is a " + prediction, (140,445), cv2.FONT_HERSHEY_SIMPLEX, 1, (0,0,255), 2)
cv2.imshow("test", img_color)# key tracker
key = cv2.waitKey(0) & 0xFF
if (key == ord('q')):
cv2.destroyAllWindows()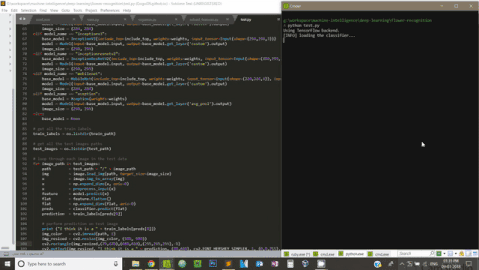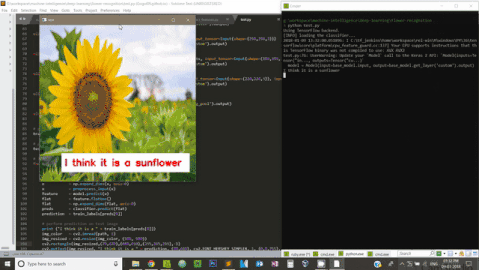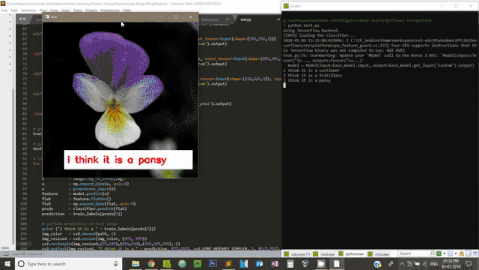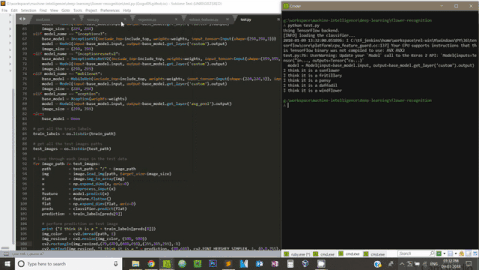
期望结果
如果在你的电脑上启用了GPU,你可以加速特征提取和训练进程。
想要继续查看该篇文章相关链接和参考文献?
长按链接点击打开或点击底部【阅读原文】:
http://ai.yanxishe.com/page/TextTranslation/1250
AI研习社每日更新精彩内容,观看更多精彩内容:
机器学习 2019:AI 发展趋势分析
使用 SKIL 和 YOLO 构建产品级目标检测系统
谷歌开源BERT不费吹灰之力轻松训练自然语言模型
使用 Tensorflow 完成简单的强化学习 Part 1:好奇心驱动的学习
等你来译:
如何用PyTorch训练图像分类器
掌握机器学习必须要了解的4个概念
给你的电脑做个简单的“人脸识别认证”
取得自然语言处理SOA结果的分层多任务学习模型(HMTL)
CMU 2018 秋季《深度学习导论》为官方开源最新版本,由卡耐基梅隆大学教授 Bhiksha Raj 授权 AI 研习社翻译。学员将在本课程中学习深度神经网络的基础知识,以及它们在众多 AI 任务中的应用。课程结束后,期望学生能对深度学习有足够的了解,并且能够在众多的实际任务中应用深度学习。

↗扫码即可免费学习↖
点击 阅读原文 查看本文更多内容↙


