如何在Python中用LSTM网络进行时间序列预测

Matt MacGillivray 拍摄,保留部分权利
翻译 | AI科技大本营(rgznai100)
长短记忆型递归神经网络拥有学习长观察值序列的潜力。它似乎是实现时间序列预测的完美方法,事实上,它可能就是。在此教程中,你将学习如何构建解决单步单变量时间序列预测问题的LSTM预测模型。
在学习完此教程后,您将学会:
如何为预测问题制定性能基准。
如何为单步时间序列预测问题设计性能强劲的测试工具。
如何准备数据以及创建并评测用于预测时间序列的LSTM 递归神经网络。
让我们开始吧。
Python中使用长短期记忆网络进行时间序列预测
教程概览
这是一个大课题,我们将深入讨论很多问题。请做好准备。
该教程分为 9 节;它们分别为:
洗发水销量数据集
测试设置
持续性模型预测
LSTM数据准备
LSTM 模型开发
LSTM预测
完成LSTM 样本
得出稳定的结果
教程延伸
Python 环境
本教程假设您已安装 Python SciPy 环境。您在学习本教程时可使用 Python 2 或 3。
您必须使用 TensorFlow 或 Theano 后端安装 Keras(2.0或更高版本)。
本教程还假设您已安装 scikit-learn、Pandas、 NumPy 和 Matplotlib。
如果您在安装环境时需要帮助,请查看这篇文章:
如何使用 Anaconda安装机器学习和深度学习所需的 Python 环境
http://machinelearningmastery.com/setup-python-environment-machine-learning-deep-learning-anaconda/
洗发水销量数据集
该数据集描述某洗发水在3年内的月度销量。
数据单位为销售量,共有36个观察值。原始数据集由Makridakis、Wheelwright 和 Hyndman(1998)提供。
您可通过此链接下载和进一步了解该数据集:https://datamarket.com/data/set/22r0/sales-of-shampoo-over-a-three-year-period。
将该数据集下载至您当前的工作目录,并保存为“shampoo-sales.csv”。注意您可能需要删除 DataMarket 添加的脚注信息。
下方例子加载并生成已加载数据集的视图。
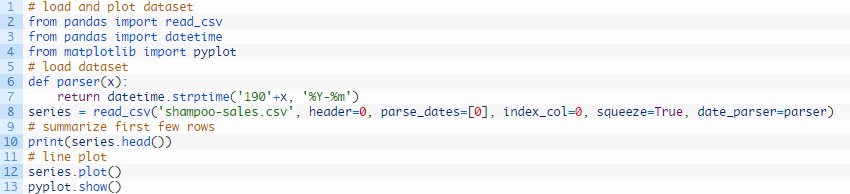
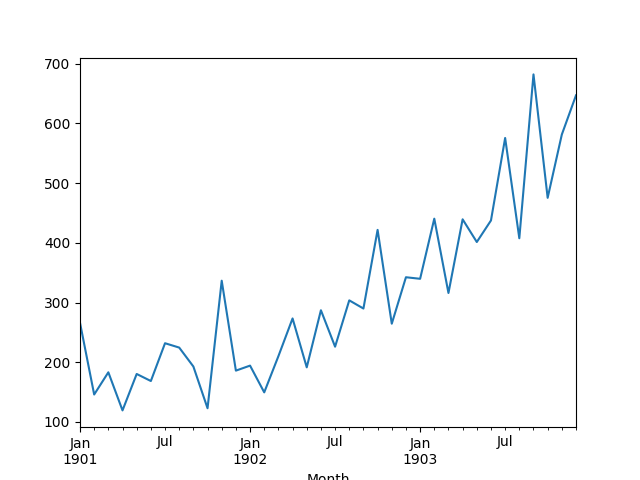
运行该示例,以 Pandas 序列的形式加载数据集,并打印出头5行。

然后生成显示增长持续性的序列线图。
试验测试设置
我们将把洗发水销量数据集分为两组:训练组和测试组。
前两年的销售数据将作为训练数据集,最后一年的数据将作为测试组。
例如:

使用训练数据集构建模型,然后对测试数据集进行预测。
我们将使用滚动预测的方式,也称为步进式模型验证。
以每次一个的形式运行测试数据集的每个时间步。使用模型对时间步作出预测,然后收集测试组生成的实际预期值,模型将利用这些预期值预测下一时间步。
例如:

这模拟了现实生活中的场景,新的洗发水销量观察值会在月底公布,然后被用于预测下月的销量。
最后,收集所有测试数据集的预测,计算误差值总结该模型的预测能力。采用均方根误差(RMSE)的原因是这种计算方式能够降低粗大误差对结果的影响,所得分数的单位和预测数据的单位相同,即洗发水月度销量。
例如:

持续性模型预测
对呈线性增长趋势的时间序列作出的准确的基线预测就是持续性化预测。
在持续性模型中,上一时间步(t-1)得到的观察值用于预测当前时间步(t)的观察值。
为了实现这一方法,我们可以从训练数据和步进验证积累的历史数据中收集上一次观察,然后用它来预测当前时间步。
例如:

我们将把所有预测累积在一个数组中,这样便可将它们与测试数据集进行直接比较。
洗发水销量数据集持续性预测模型的完整示例如下所示。
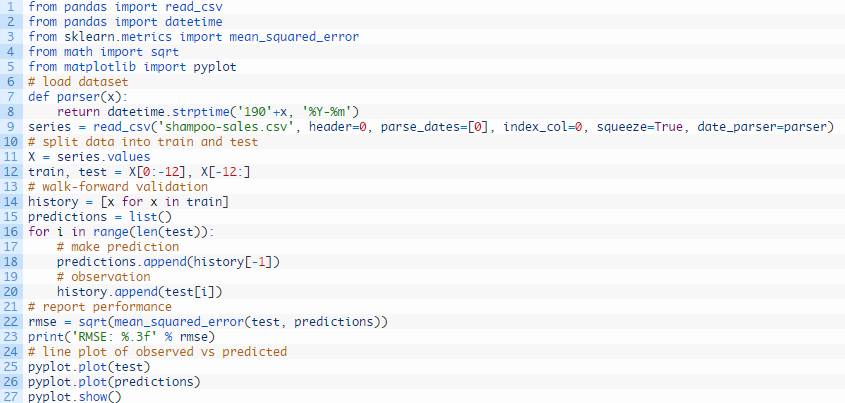
运行示例,约打印136个洗发水月度销量的均方根误差,对测试数据集进行预测。

同时生成测试数据集(蓝色)对比预测值(橙色)的线图,在背景中显示持续性模型预测。
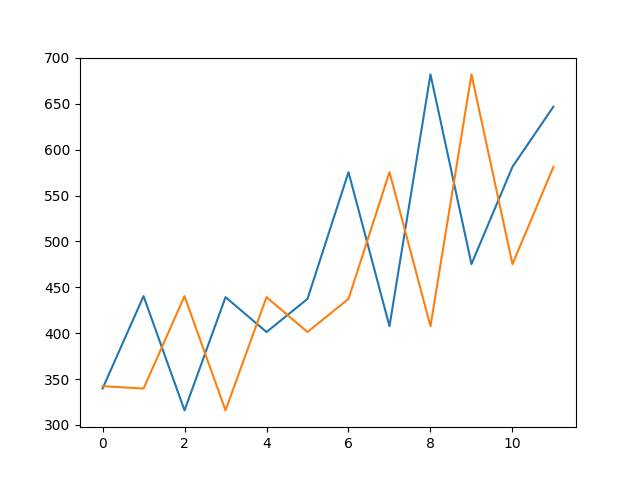
洗发水销量数据集观察值对比预测值的持续性预测
想要了解更多关于时间序列预测的持续性模型的内容,请查看这篇文章:
如何使用Python完成时间序列预测的基线预测
http://machinelearningmastery.com/persistence-time-series-forecasting-with-python/
现在我们制定了数据集的性能基线,接下来就可以开始构建数据的LSTM模型了。
LSTM数据准备
在将LSTM模型放入数据集前,我们必须转化数据。
本节分外三步:
将时间序列转化为监督学习问题。
转化时间序列数据使其呈静态。
转化观察值使其处于特定区间。
将时间序列转化为监督学习
Keras中的LSTM模型假设您的数据分为两部分:输入(X)和输出(y)。
对于时间序列问题,我们可以将上一时间步(t-1)的观测值作为输入,将当前时间步(t)的观测值作为输出。
为了实现这一转化,我们可以调用Pandas库中的shift()函数将某一序列中的所有数值向下错位特定的位数。我们需要向下错一位,这位上的数值将成为输入变量。该时间序列则将成为输入变量。
然后我们将这两个序列串在一起创建一个DataFrame进行监督学习。向下错位后的序列移到了顶部,没有任何数值。此位置将使用一个NaN(非数)值。我们将用0值代替这些NaN值,LSTM 模型将不得不学习“序列的开头”或“此处无数据”,因为此数据集中未观察到销量为零的月份。
下方的代码定义了一个完成此步的辅助函数,名称为 timeseries_to_supervised()。这个函数由原始时间序列数据的NumPy数组和一个滞后观察值或错位的序列数生成,并作为输入使用。

我们可以用载入的洗发水销量数据集测试该函数,并将它转化为监督学习问题。

运行该示例,打印新的监督学习问题的前5行。

想要了解更多关于将时间序列问题转化为监督学习问题的内容,请查看这篇文章:
时间序列预测问题转为监督学习问题
http://machinelearningmastery.com/time-series-forecasting-supervised-learning/
将时间序列转化为静态
洗发水销量数据集不是静止的。
这意味着数据中的某个结构与时间有关。更确切地说,数据中存在增加的趋势。
静态数据更容易建模,并且很可能得出更加准确的预测。
可以从观察中移除该趋势,然后再添加至预测中,将预测恢复至原始区间并计算出相当的误差值。
移除趋势的标准方法是差分数据。也就是从当前观察值(t)中减去从上一时间步(t-1)得到的观察值。这样我们就移除了该趋势,得到一个差分序列,或者一个时间步及其下一时间步得出的观察值发生改变。
我们可以通过调用pandas库中的diff() function函数自动完成此步。另外,我们还可以获得更好的控制,用我们自己编写的函数完成此步,在该例中我们将采用这种方法,因为它具有灵活性。
下方是一个名称为difference()的函数,用来计算差分序列。注意,由于不存在用于计算差分值的先前观察值,因此须略过该序列中的第一个观察值。

为了使差分序列的预测恢复至原始的区间内,我们还需要逆转这个流程。
下方的这个名为inverse_difference()的函数用来逆转这个操作。

我们可以通过差分整个序列来测试这些函数,然后再将它恢复至原始区间内,具体代码如下所示:

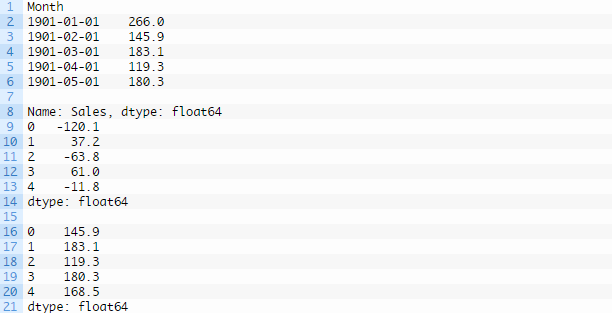
运行示例,打印载入数据的前5行,然后再打印差分序列的前5行,最后再打印序列逆转差分操作后的前5行。
注意,原始数据集中的第一个观察值已从逆转差分操作后的数据中移除。另外最后一个数据集按照预期与第一个数据集相对应。
想要了解更多关于时间序列静态化和差分的内容,请查看以下文章:
如何用Python检查时间序列数据是否呈静态
http://machinelearningmastery.com/time-series-data-stationary-python/
如何用Python差分时间序列数据集
http://machinelearningmastery.com/difference-time-series-dataset-python/
转化时间序列使其处于特定区间
和其他神经网络一样,LSTM要求数据须处在该网络使用的激活函数的区间内。
LSTM的默认激活函数为双曲正切函数(tanh),这种函数的输出值处在-1和1之间,这也是时间序列函数的区间。
为了保证该试验的公平,缩放系数(最小和最大)值必须根据训练数据集计算,并且用来缩放测试数据集和任何预测。这是为了避免该实验的公平性受到测试数据集信息影响,而可能使模型在预测时处于劣势。
我们可以使用MinMaxScaler class转化数据集使其处在 [-1, 1] 区间内。和其他scikit-learn转换模块一样,它需要提供行列矩阵形式的数据。因此,我们必须在转换数据集之前变换NumPy数组。
例如:

同样,我们必须将逆转对预测的缩放,将数值恢复至原始的区间内,这样就可以解释结果并且算出相当的误差值。
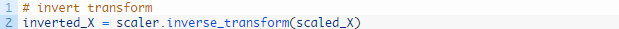
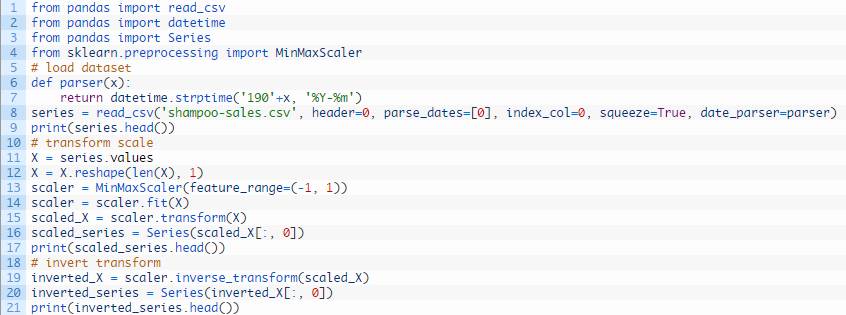
全部综合起来,下例所示的代码可转化洗发水销量数据所处的区间。
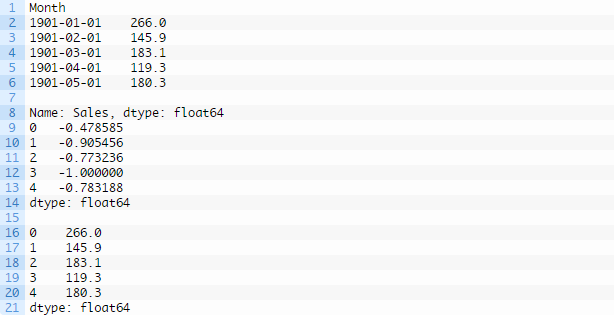
运行示例,打印载入数据的前5行,再打印经缩放数据的前5行,然后打印逆转缩放后数据的前5行,匹配原始数据。
现在我们学会了如何为LSTM网络准备数据,我们就可以构建模型了。
LSTM 模型开发
长短期记忆网络(LSTM)是一种递归神经网络(RNN)。
这类网络的的优点是它能学习并记住较长序列,并不依赖预先指定的窗口滞后观察值作为输入。
在Keras中,这被称为stateful,在定义LSTM网络层时将“stateful”语句设定为“True”。
在默认下,Keras中的LSTM 网络层在一批数据之间维持状态。一批数据是训练数据集中的固定行数,该数据集定义在更新网络权值之前运行多少模式。
各批数据之间的LSTM层的状态在默认下是清空的,因此我们必须使LSTM有状态。通过调用reset_states()函数,我们可以精确掌控LSTM层的状态何时被清空。
LSTM层要求输入值须位于有维度的矩阵中;【例子、时间步、特征】。
例子:是指定义域中的独立观察值,通常是几列数据。
时间步:是指特定观察值的给定变量的单独时间步。
特征:是指的观察时得到的单独指标。
我们在该网络的洗发水销量数据集的构造上有些灵活性。我们将简化构造,并且将问题限制在原始序列的每个时间步,仅保留一个单独的样本、一个时间步和一个特征。
鉴于训练数据集的形式定义为X输入和y输出,必须将其转化为样本/时间步/特征的形式,例如:

LSTM层必须使用 “batch_input_shape” 语句作为元组定义输入数据的形态,该语句详细规定读取没批数据的预期观察值数,时间步数和特征数。
batch大小通常要比样本总数小很多。它和epoch的数目共同决定网络学习数据的速度(权值更新的频率)。
最后一个定义LSTM层的输入参数是神经元的数目,也称为记忆单元或模块的数目。这是一个相当简单的问题,在1至5之间选取数字应该就足够了。
下列的这行语句生成一个简单的LSTM层,并且通过“batch_input_shape”语句规定输入层的预期参数。
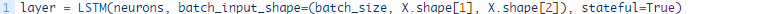
该网络需要在带线性激活函数的输出层上插入一个简单的神经元,以预测下一时间步的洗发水销量。
一旦明确规定好网络后,必须使用后端数学库将该网络编译成高效的符号表示,例如TensorFlow 或 Theano。
在编译网络时,我们必须规定一个损失函数和优化算法。我们将使用“mean_squared_error”作为损失函数,因为它与我们要计算的平方根误差十分接近,使用高效的ADAM优化算法。
使用连续的KerasAPI 定义该网络,下方的语句创建并编译该网络。

在编译后,该网络能够拟合训练数据。因为该网络有状态,我们必须在内部状态重启时实施控制。因此,我们必须一次一个epoch地手动管理训练流程,直至完成预期的epoch数。
在默认下,epoch内的样本在输入网络之前已经混合。同样,这对LSTM而言很不理想,因为我们希望该网络通过学习观察值序列形成状态。我们无法通过设置“shuffle”为“False”来禁止样本的混合。
而且在默认下,该网络在每个epoch结束时报告大量关于学习进展和模型技能的调试信息。我们可以将“verbose”语句设置为“0”级别以禁止该报告。
然后我们可以在每个训练epoch结束时重置内部状态,准备进行下一次训练迭代。
下方的循环语句可手动调整网络,使其与训练数据拟合。

综合起来,我们可以定义一个名为fit_lstm()的函数,它用于训练和返回LSTM模型。作为语句,它将训练数据集转化为监督学习的形式,一个批量大小,一些epoch和一些神经元。
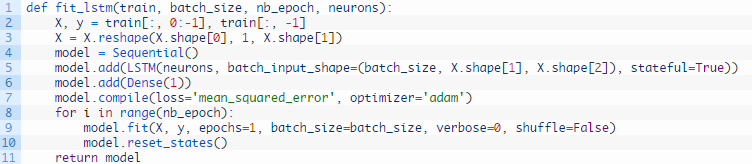
批量大小必须设置为1.这是因为它必须是训练和测试数据集大小的一个因子。
模型的predict() 函数也受到批量大小的限制;批量大小必须设置为1,因为我们希望对测试数据进行单步预测。
我们将不会在此教程中调整网络参数;相反,我们将使用以下结构进行,该结构经过少量测试并且带有误差。
批量大小:1
Epoch:3000
神经元: 4
作为本教程的延伸,你可能喜欢探索不同的模型参数并尝试改善性能。
更新:不妨试设置为1500 epoch和1 神经元,性能可能会更好!
下面,我们将探讨如何使用合格的LSTM模型作单步预测。
LSTM 预测
一旦LSTM模型与训练数据相拟合,这个模型就可用来作预测。
同样,我们有些灵活性。我们可以决定将模型一次性拟合所有训练数据,让一次一个地预测测试数据中的每个新时间步(我们将这种方法称为固定方法)。或者我们可以重新拟合模型或者在测试数据的每个时间步内更新模型,因为我们已知测试数据中的新观察值(我们将这种方法称为动态方法)。
在本教程中,我们为了方便采用固定方法,但是我们估计动态方法会得到更好的模型技能。
为了作出预测,我们能调用模型上的predict() 函数。这要求将一个三维NumPy数组作为语句。在这种情况下,它将是一个单值数组,前一时间步的观察值。
predict() 函数返回一列预测,提供的每个输入行对于一个预测。因为我们提供的是一个单一输入,输出将是单值的二维NumPy数组。
我们可以在下列这个名为forecast()的函数中发现这种行为。给定一个合适的模型,拟合模型(例1)时的一批数据和一行测试数据,该函数将从测试数据行中分离出输入数据,对其进行改造,然后以单一浮点值的形式返回预测。

在训练期间,每个epoch结束后都对内部状态进行重置。在进行预测时,我们将不会在预测中间重置内部状态。事实上,诶吗希望模型形成状态,因为我们预测测试数据集的每个时间步。
这引发了这样一个问题,在对测试数据集进行预测之前,对网络而言怎样才算作好的初始状态。
在本教程中,我们将通过对训练数据集的所有样本进行预测来确定初始状态。理论上,应设置好初始状态来预测下一步。
我们现在已经完成所有步骤,可以为洗发水销量数据集拟合LSTM网络模型并评测它的性能。
下一部分,我们将把所有这些步骤结合起来。
完成LSTM样本
本节,我们将为洗发水销量数据集拟合一个LSTM模型并评测它的性能。
这将涉及结合前几节中的所有内容,内容很多,所有让我们回顾一下:
1. 从CSV文件中载入数据集。
2. 转化数据集使其拟合LSTM模型,包括:
将数据转化为监督学习问题。
将数据转化为静态。
转化数据使其处于-1至1的区间内。
3. 将有状态的LSTM网络模型与训练数据进行拟合。
4. 根据测试数据评测静态的LSTM模型。
5. 报告预测的性能。
一些关于样本的注意事项:
为了简便起见,缩放和逆转缩放行为已被移至函数scale()和invert_scale()中。
为了确保测试数据的最小/最大值不影响模型,使用根据训练数据拟合的缩放器对测试数据进行缩放。
为了方便起见,数据转化的顺序调整为现将数据转化为静态,再转化为监督学习问题,再进行缩放。
为了方便起见,在将数据集分为训练组和测试组之前对整个数据集进行差分。我们可以在步进验证期间轻松收集观察值并在之后步骤中对它们进行差分。为了获得更好的可读性,我决定不采用这种做法。
完整的例子如下所示:

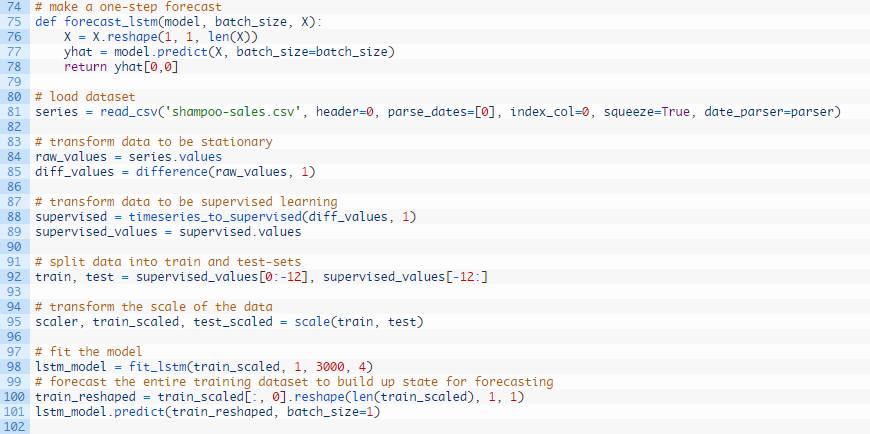
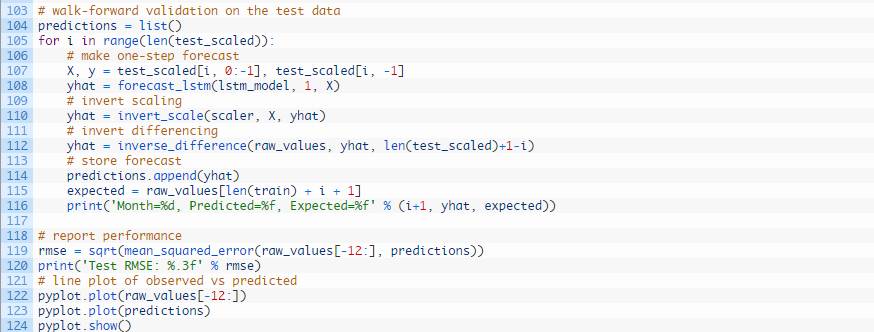
运行示例,打印测试数据集12个月份中每一月份的预期和预测销量。
示例还打印了所有预测值得均方根误差。该模型显示洗发水月度销量的均方根误差为71.721,好于持续性模型得出的对应结果136.761。
在构建LSTM模型中使用了随机数字,因此,你在运行该模型时可能得到不同的结果。我们在下一节中将对此进行进一步讨论。
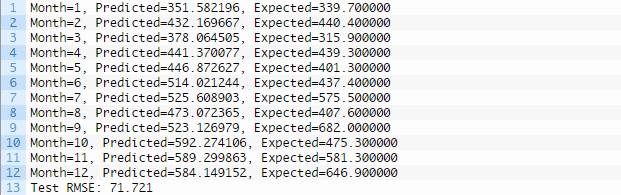
同时生成了测试数据(蓝色)对比预测数据(橙色)的线图,为模型技能提供了背景。
LSTM预测对比预期值的线图
作为后注,你可以通过一个简单的试验帮助建立对测试工具和所有转化和逆向转化的信任。
标注出在步进验证中拟合LSTM模型的线条:

用下列语句代替它:

这会构建出一个拥有完美预测技能的模型(例如预测出的预期结果和模型输出一致)。
结果应如下所示,显示LSTM模型是否能够完美预测序列,逆向转换和错误计算能正确显示。
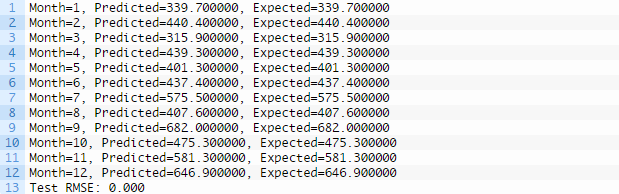
得出稳定的结果
神经网络的一个难题是初始条件不同,它们给出结果就不同。
一种解决办法是修改Keras使用的随机数种子值以确保结果可复制。另一种办法是使用不同的实验设置控制随机初始条件。
想要了解更多关于机器学习随机性的内容,请查看这篇文章:
概括机器学习中的随机性
http://machinelearningmastery.com/randomness-in-machine-learning/
我们可以多次重复上节中的实验,然后取均方根误差的平均值作为评估该结构预测未知数据的平均水平的一个指标。
这通常被称为多次重复或多次重启。
我们可以将模型拟合和步进验证包含在固定重复次数的循环语句中。运行每次迭代得到的均方根误差都能记录下来。然后我们可以总结均方根误差的分布。
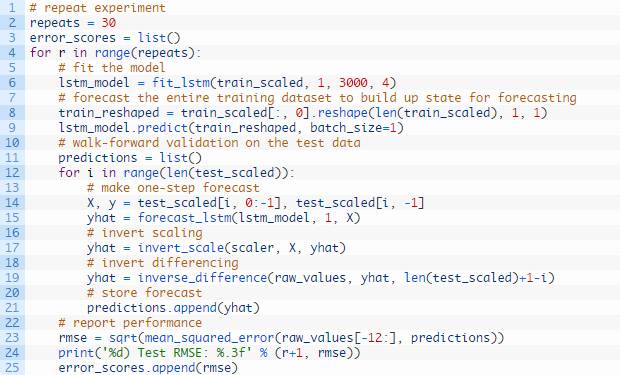
数据准备步骤仍和之前一样。
我们将使用30次重复,因为这足以提供一个良好的均方根误差分值分布。
完整的例子如下所示:
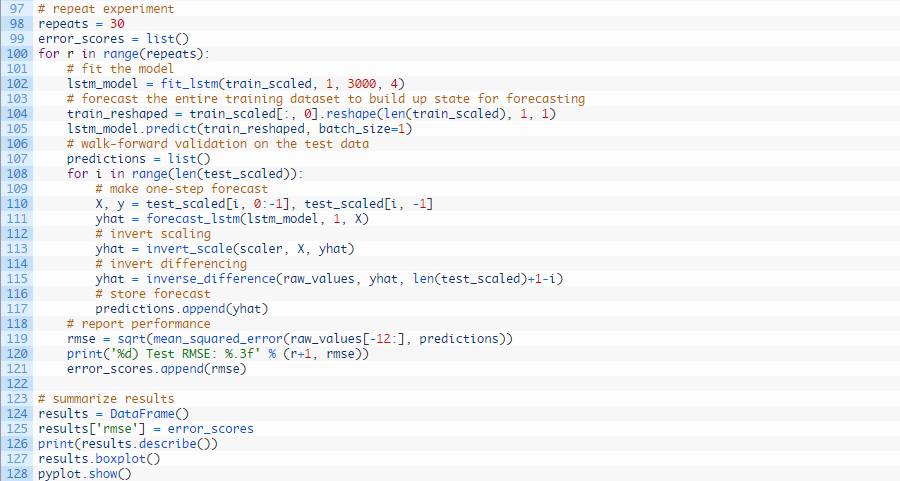
运行示例,打印每次重复的均方根误差分值。运行到最后将给出收集的均方根误差分值的总结统计数据。
我们能看到,洗发水阅读销量的均值和标准层均方根误差分值分别为138.491905和46.313783。
这是一个非常有用的结果,因为他表明,上文报告的结果可能是统计意义上的偶然时间。该实验表明,此模型的平均性能可能大概和持续性模型一样,都为136.761甚至还与后者相差少许。
这至少表明进一步的模型调试是必须的。
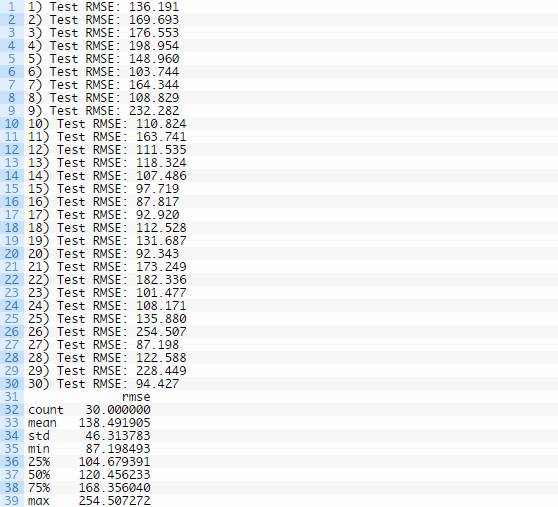
下方所示的分布生成了块状图和须状图。这得出了数据的中值以及范围和异常结果。
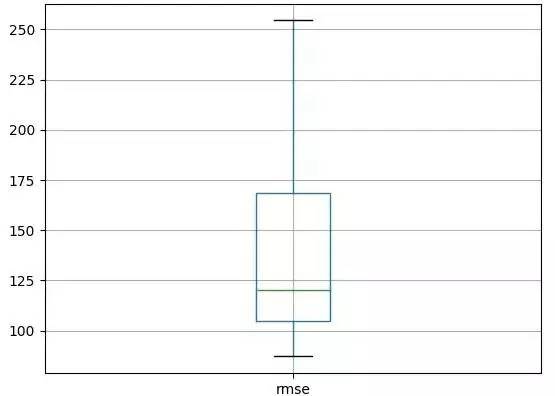
LSTM重复实验块状图和须状图
这是一个可用来比较LSTM模型结构或者构建另一结构的实验设置。
教程扩展
我们可考虑的教程扩展有很多。
多步预测。该实验设置可以在修改后预测下n个时间步,而不仅仅是下一时间步。而且还能实现更大的批量和更快的训练。注意,由于模型未更新,尽管已知新的观察值并且这些值都用作输入变量,我们在本教程中执行的仅仅是一类12单步预测。
调试LSTM模型。该模型未经调试;相反,模型结果结构只经过一些简单的测试并且存在误差。我认为,仅仅通过调试神经元数和训练epoch就能获得更好的结果,我还认为在测试中通过回调函数来提前终止运行可能有用。
初始状态实验。通过预测所有训练数据在进行预测之前初建系统是否有用还不得而知。理论上似乎是一种好办法,但是需要进行验证。而且,其他在预测前初建模型的方法也可能有用。
更新模型。可以在步进验证的每个时间步中更新模型。需要进行实验来确定从新开始重拟合该模型或者通过另外几个训练epoch(包括新样本)更新权值是否能获得更好的结果。
输入时间步。LSTM 输入支持单样本采用多个时间步。需要进行实验来确认将滞后观察作为时间步是否能获得更好结果。
输入滞后特征。滞后观察可作为输入特征。需要实验确定包括滞后观察是否能像AR(k)线性模型那样带来任何好处。
输入误差序列。和MA(k)一样,误差序列经过构建(预测持续性模型的误差)可作为附加的输入特征。需要进行实验以观察这是否能带来任何好处。
学习非静态。LSTM网络也许能学习数据中的趋势并作出合理的预测。需要进行实验以观察LSTM是否能学习和有效预测留在数据中的暂时性独立结构,如趋势和季节性。
对比无状态。本教程使用的是有状态LSTM。应将结果与无状态LSTM结构作对比。
统计学意义。多次重复实验方案可以进一步延伸,加入统计学意义测试,证明均方根误差结果的样本群和不同结构间的差异是否具有统计学意义。
总 结
在本教程中,你学会了如何构建LSTM模型解决时间序列预测问题。
具体地说,你学会了:
如何为构建LSTM模型准备时间序列数据。
如何构建LSTM模型解决时间序列预测问题。
如何使用性能良好的测试工具评测LSTM模型。
原文链接
http://machinelearningmastery.com/time-series-forecasting-long-short-term-memory-network-python/
关注福利
关注AI科技大本营,进入公众号,回复对应关键词打包下载学习资料
回复:CCAI,下载《CCAI 2017嘉宾演讲PPT 》
回复:路径,下载深度学习Paper阅读路径(128篇论文,21大领域)
回复:法则,下载《机器学习的四十三条经验法则》
回复:美团,下载《深度学习在美团外卖的应用,NLP在美团点评的应用》,《NLP在美团点评的应用》pdf
回复:沙龙,下载CSDN学院7月15日线下沙龙PPT(蒋涛、孟岩、智亮)
回复:对抗,下载台大李宏毅老师关于生成对抗学习视频教程(附PPT)
回复:AI报告,下载麦肯锡、波士顿、埃森哲咨询公司AI报告
回复:银行,下载银行和证券公司的AI报告
回复:人才,下载 2017 领英《全球AI领域人才报告》
回复:发展,下载2017 全球人工智能发展报告_框架篇
回复:设计,下载人工智能与设计的未来
回复:1986,下载李开复1986年论文《评价函数学习的一种模式分类方法》和1990年论文《The Development of a World Class Othello Program》
回复:中美,下载《中美两国人工智能产业发展全面解读》(腾讯研究院)

人类感知外界信息,80%以上通过视觉得到。2015年,微软在ImageNet大赛中,算法识别率首次超越人类,视觉由此成为人工智能最为活跃的领域。为此,AI100特邀哈尔滨工业大学副教授、视觉技术研究室负责人屈老师,为大家介绍计算机视觉原理及实战。扫描上图二维码或加微信csdn02,了解更多课程信息。




