论文浅尝 | Language Models (Mostly) Know What They Know

笔记整理:程思源、梁孝转,浙江大学在读硕士,研究方向为知识图谱的表示学习,自然语言处理,预训练
对于一个语言模型,我们最终希望得到一个“诚实”的人工智能系统,即语言模型需要准确并且忠实地评估它们对于自己的知识和推理的置信水平。AI模型进行自我评估(self-evaluation),首先需要让语言AI在回答问题的时候校准(Calibration)自己的答案。校准就是让后验概率和经验概率相匹配,这样就可以对模型给出的概率误判风险有一个直接的判断。比如模型给出一个预测说这个样本出现的概率为0.3,那也就是说在100个样本中约有30个样例,如果模型预测出来的概率与现实发生频率相一致,那这个模型就是已经校准好的模型。
为了验证AI语言系统能否对自己的答案进行校准,作者设计了三个主要的问题形式:
1、多项选择问题

2、将多项选择题中的最后一个选项替换为”None of the above”

3、True/False问答

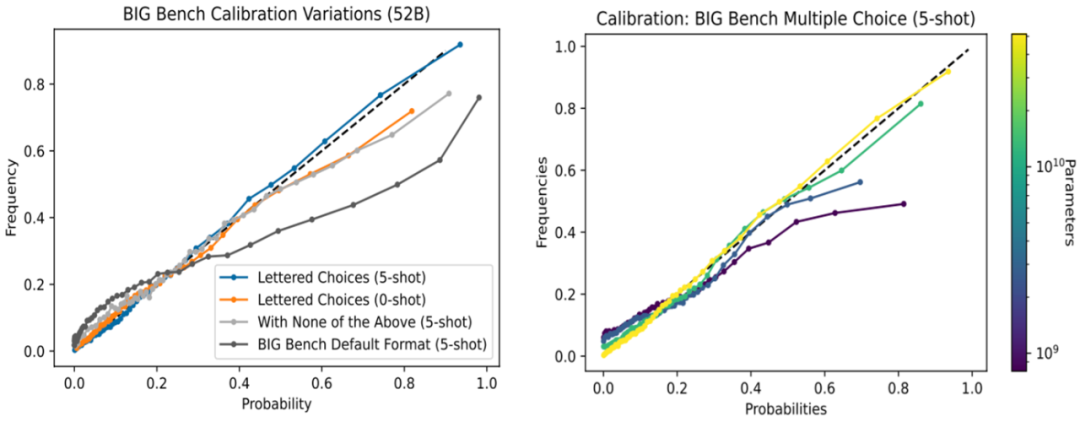
根据以上问题设定进行实验,看模型在以上三种情况下的校准情况。首先文章得出结论模型校准的好坏是与问题的设计形式是非常相关的,如左图所示,在BIG Bench任务下,设定任务1的效果就要比设定任务2的效果要好,如果对于问题设定进行改动,发现会很大程度上损害语言模型的校准能力。在增加了few-shot之后效果也有提升。右边的图中可以看出,模型校准的效果往往随着模型大小的增大,效果变得越好。
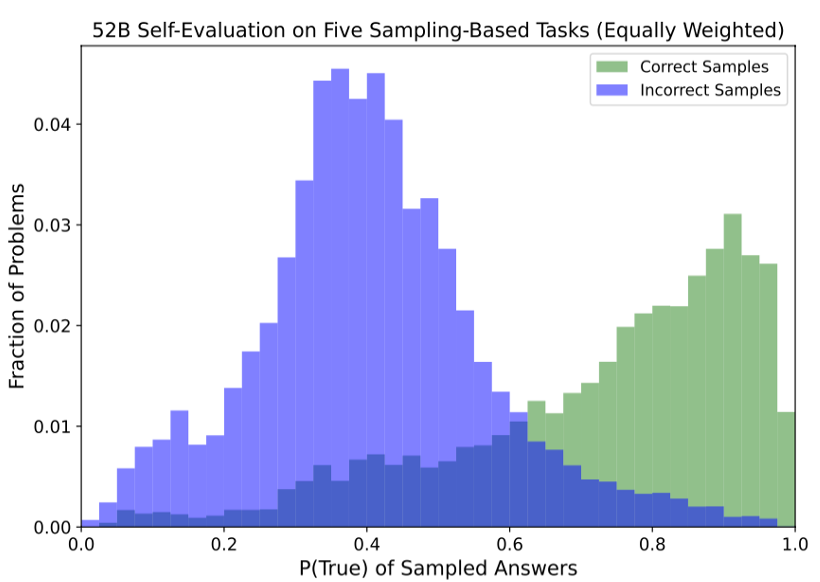
不经过Finetune让模型验证自己的输出:作者在TriviaQA、Lambada 、GSM8k 、Codex HumanEval、arithmetic problems等生成任务上进行验证,发现不经过finetune,通过一些少样本可以得到校准较好的self-evaluation模型,但是对于zero-shot的设定不太友好。在True/False任务中发现如果给模型展示T=1的samples可以有效的提升模型效果。
按现实情况来看语言模型往往是对自己的回答自信的,因为他选择的是自己预测最大概率输出,但是利用True/False模型依然能够将正确的samples和错误的samples给区分开来。
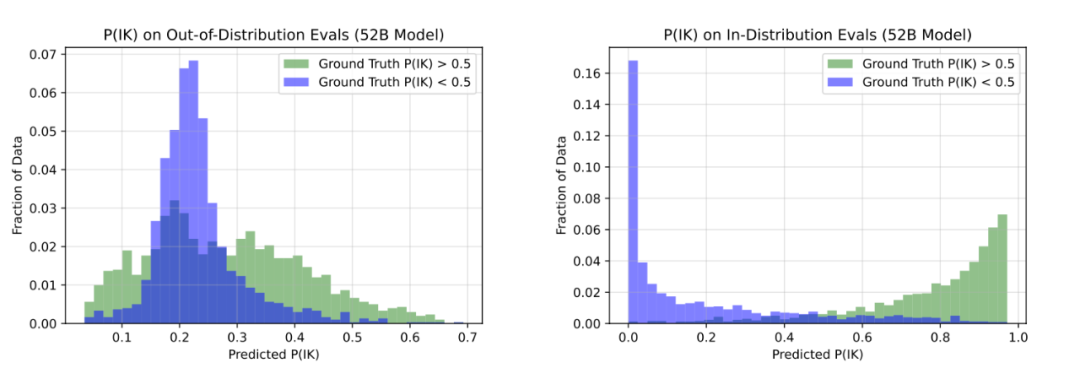
经过Finetuning让预测P(IK)“我知道这个答案的概率”,即询问模型你是否知道这个问题的答案,而不是简单去判断答案是否是正确的。实验挑选两种方式进行训练:
1、Value Head:把P(IK)训练成为一个额外的value head,再添加到模型的对数
2、Natural Language:这种方法就是要求AI模型从字面上回答“你知道这个答案的概率是多少”,同时输出一个百分比数据答案。
部分实验结果如图所示,可以看出在OOD设定下效果不理想(OOD实验设定是训练和验证的数据集是分开的)但是在所有训练集和测试集下面,模型就能很好划分开来。
文章中还对P(IK)实验中的一些example进行分析,结果如下:
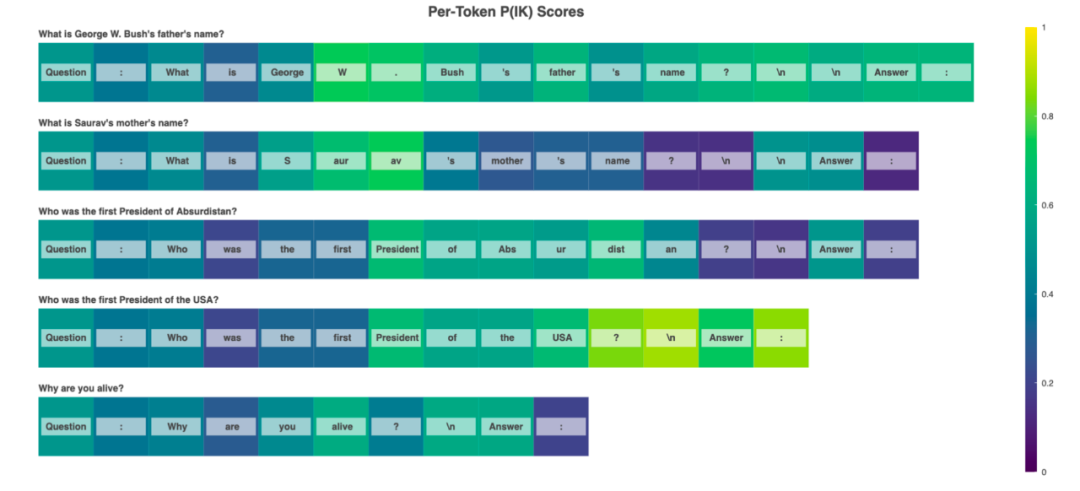
实验只针对最后一个token进行预测,可以发现对于越难的问题,P(IK)的值越低,说明模型能够知道哪些问题它能够很好回答,哪些是它回答不了的。
True/False问题:模型对于“none of the above”的选项是存在困惑的,所以作者采用另外一种问题设计形式,让模型判断给出的回答是否正确。作者利用多项选择任务中的答案选项。采样正确答案和随机选择的错误答案,创建一个包含两倍于之前多项选择问题的新评估集,要求模型确定每个答案是否正确。
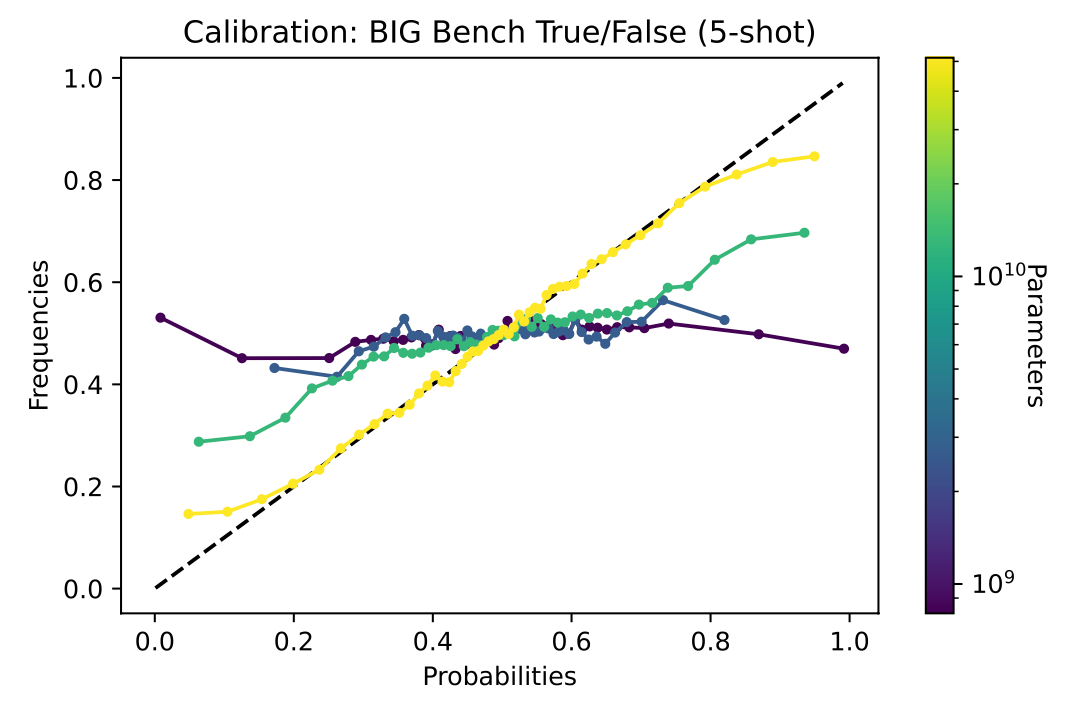
实验发现在模型住够大的情况下是存在很好的校准结果,但是在模型参数比较小的时候,发现模型并不具备很好的校准。
基于上述的结论,作者进一步探索了一个问题:语言模型能否判断自己的答案是否正确。作者首先让模型以生成的方式回答一个问题,并将问题与其回答的答案代入到True/False问题模版中,让模型判断自己的答案是否正确,并分析语言模型是否能做出有效的判断。
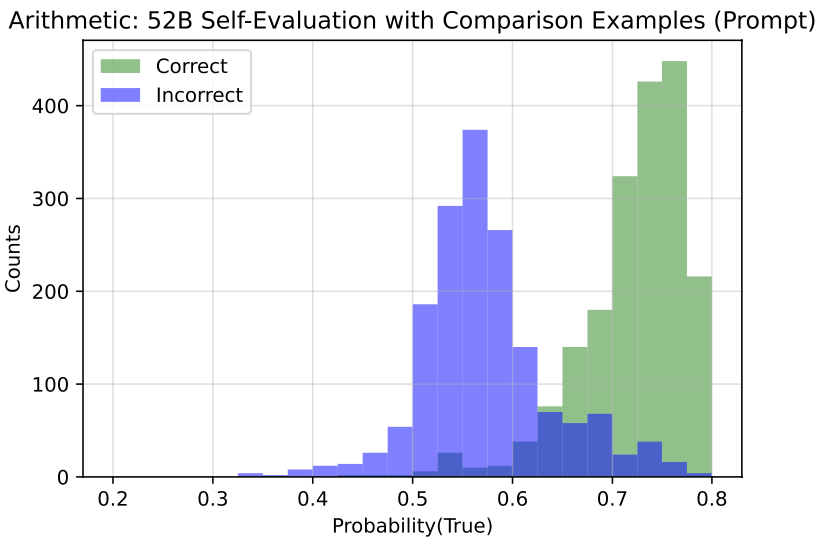
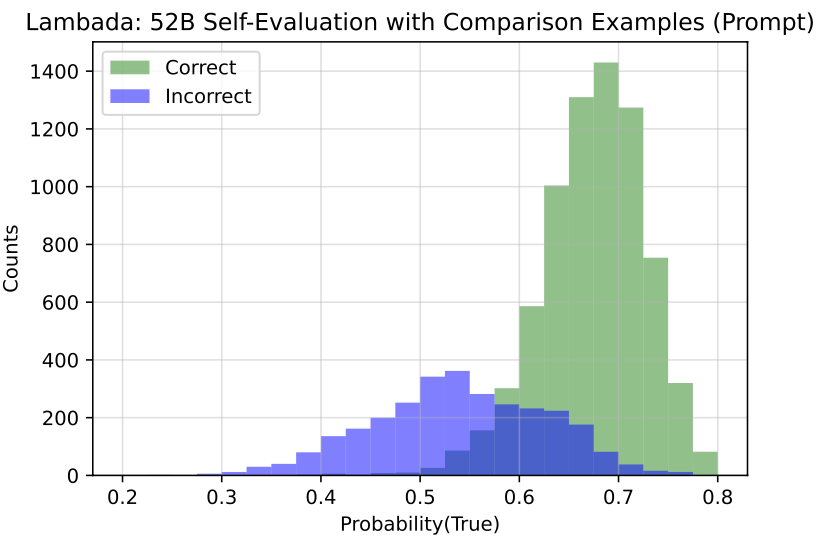
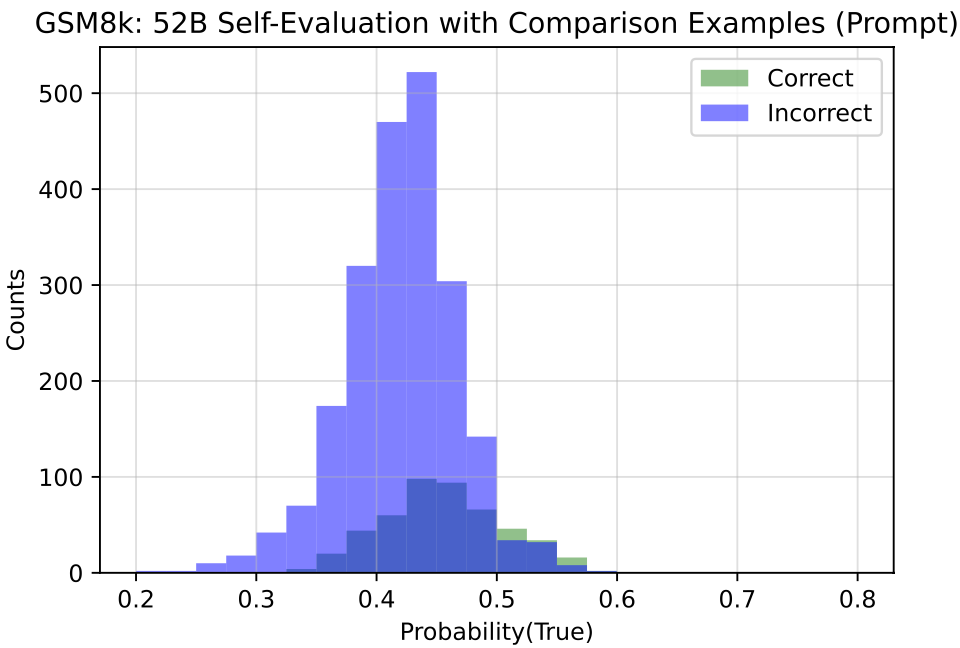
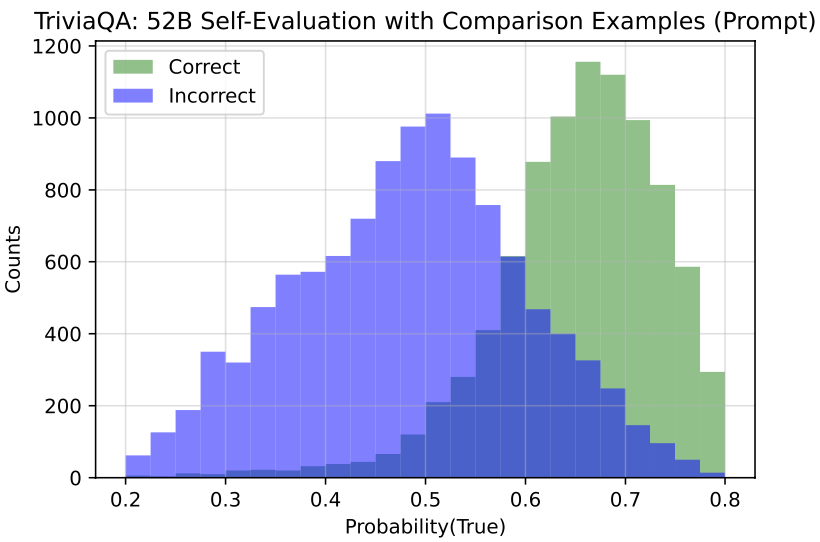
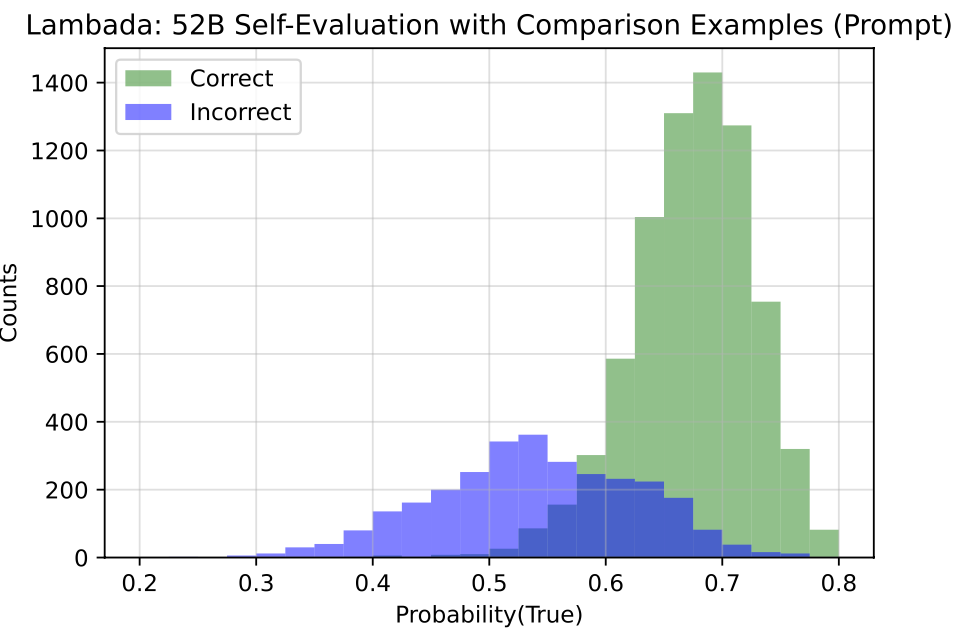
实验发现,在大规模语言模型上,预测为”真”的概率分布能提供一个显著的“正确回答“和“错误回答”的区分,即模型能比较好地判断自己生成的答案正确与否。同时,作者也发现语言模型并不具备比较好的校准能力,特别地,预测为“真”的概率在一些样本上通常会落在50%左右。此外作者发现提供更多的模型回答的答案,以下面的模版构建True/False问题样本,能够提升模型自我评估的能力。

最后,作者提出了一个问题:语言模型经过训练,能否预测自己是否能回答任何给定的问题。为此,作者提出了两种方式:一种是Value Head方式,即在语言模型的结构上额外训练一个分类器,预测能否给出正确的回答;一种是Natural Language方式,即引入类似” With what confidence could you answer this question?”的提示词,训练模型生成如0%, 10%, 20%, · · · 100%的回答作为预测的概率。
实验发现,后者在结合少样本提示的OOD泛化设定上并没有取得特别大的收益,故作者在后续实验中采用了前者。作者发现,经过训练的模型能比较好地预测自身能否正确回答给定的问题,并且在TrivalQA数据集上有比较好的校准效果。
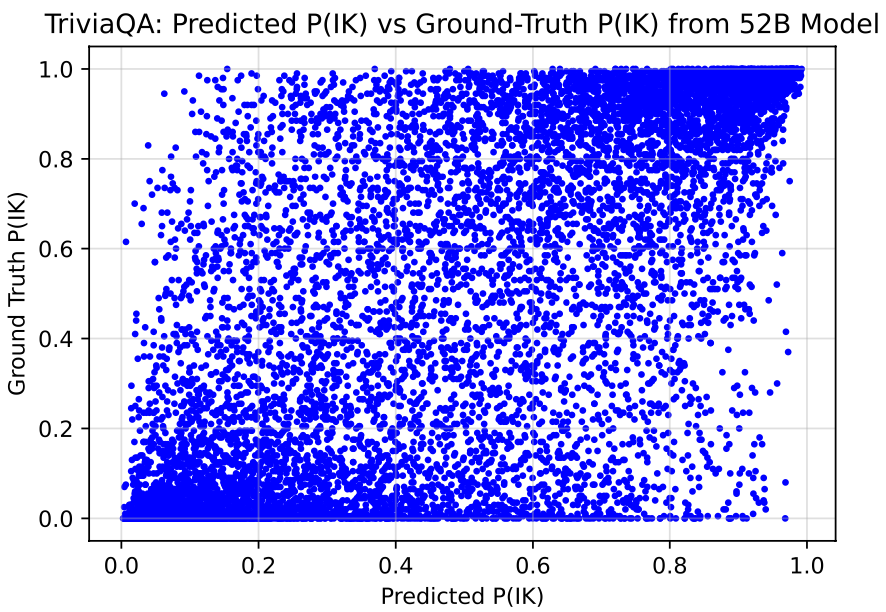
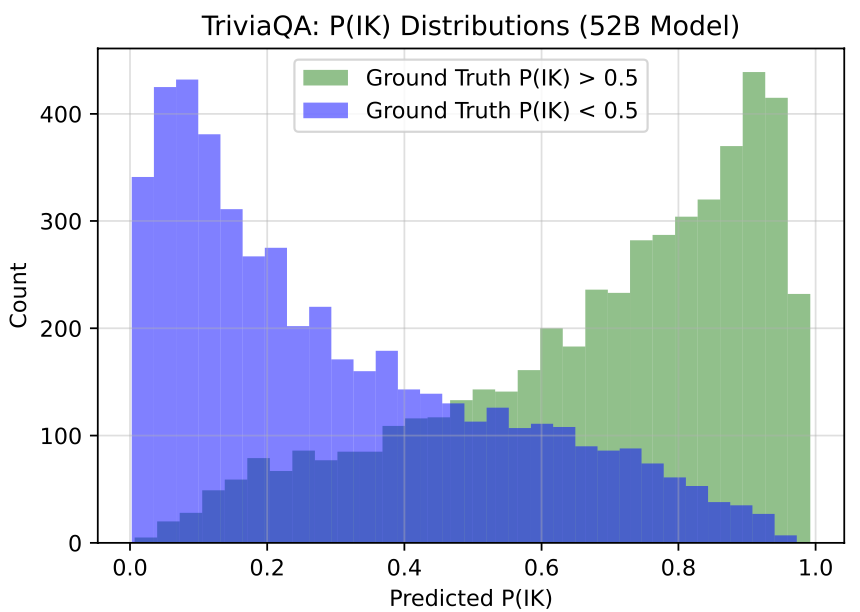
此外,作者还分析了上述训练得到的模型OOD泛化的能力。作者通过在TrivalQA数据集上训练,在另外几个数据集上测试的方式,验证了模型具备一定的泛化能力,结果如下:
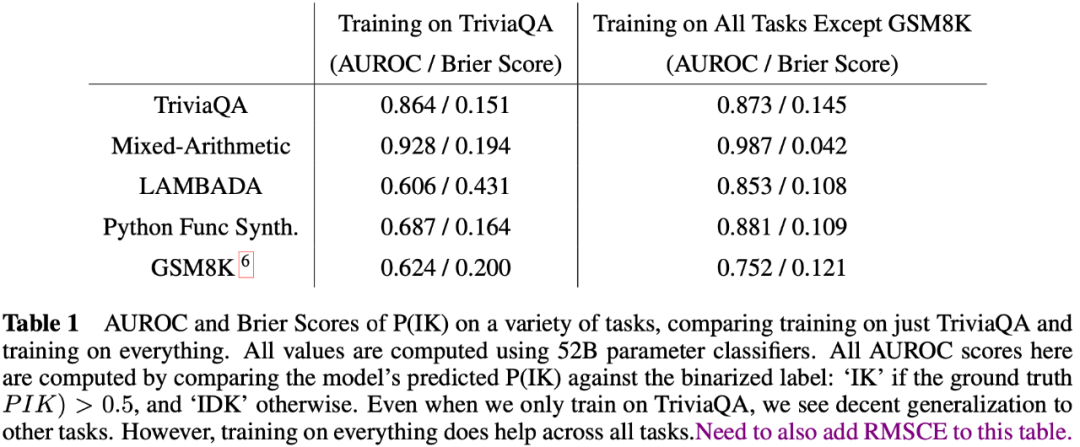
尽管在训练过程中没有引入提示材料(Materials/Hints),作者发现在测试的时候,在问题前面加上如下的提示信息,能够提升模型的效果。

OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。



