【推荐系统】BERT4Rec:使用Bert进行序列推荐
来自:Microstrong
今天给大家介绍一篇BERT用于推荐系统的文章,题目是《BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer》,文章作者都是出自阿里。
-
引用:Sun F, Liu J, Wu J, et al. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer[C]//Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 2019: 1441-1450. -
论文下载地址:https://arxiv.org/pdf/1904.06690.pdf
本文概览:
1. BERT4Rec简介
根据用户历史的行为,对用户动态的偏好进行建模,对于推荐系统来说是有挑战的和重要的。之前的算法使用序列神经网络从左向右地编码用户的历史交互信息为隐含表示,进而进行推荐,因此只利用了单向的信息进行建模。尽管它们是有效的,但由于存在以下限制,我们认为这种从左到右的单向模型是次优的:
-
单向结构限制了用户行为序列中隐藏表示的能力; -
之前的序列神经网络经常采用严格有序的序列,这并不总是可行的;
为了解决这些限制,我们提出了一个称为BERT4Rec的序列推荐模型,该模型采用深层的双向自注意力来对用户行为序列进行建模。为了避免信息泄漏并有效地训练双向模型,我们采用Cloze目标进行序列推荐,通过联合item左右的上下文来预测序列中随机masked item。用这种方式,我们学习了双向表示模型,允许用户历史行为中的每个item融合左右两侧的信息来作出推荐。在四个基准数据集上进行的大量实验表明,我们的模型始终优于各种最新的序列模型。
2. 背景
精确地捕捉用户的兴趣,是推荐系统的核心问题。在许多实际应用中,用户当前的兴趣本质上是动态变化的,受其历史行为的影响。例如,尽管在正常情况下不会购买游戏机配件,但在购买Nintendo Switch之后,你可能会很快购买配件(例如Joy-Con控制器)。
为了捕捉用户的偏好的动态变化,提出了许多根据用户历史交互信息的序列推荐算法,最早使用马尔科夫对用户序列进行建模,其中一些方法的强假设破坏了推荐系统的准确性。近期,一些序列神经网络在序列推荐问题中取得了不俗的效果。最基本的思想就是将用户的历史序列自左向右编码成一个向量,然后基于这个向量进行推荐。
尽管它们具有普遍性和有效性,但我们认为这样从左到右的单向模型不足以学习用户行为序列的最佳表示。主要因为这种单向模型限制了历史序列中items的隐藏表示的功能,其中每个item只能编码来自先前item的信息。另一个限制是,先前的单向模型最初是针对具有自然顺序的序列数据(例如,文本和时间序列数据)引入的。他们经常对数据采用严格的顺序排列,这对于现实应用程序中的用户行为并不总是正确的。实际上,由于各种不可观察的外部因素,用户的历史交互中的item选择可能不会遵循严格的顺序假设。在这种情况下,至关重要的是将两个方向的上下文合并到用户行为序列建模中。
为了解决上述限制,本篇文章的创新点:
-
提出了一种基于双向self-attention和Cloze task的用户行为序列建模方法。据我们所知,这是第一个将深度序列模型和Cloze task引入推荐系统的研究。 -
将我们的模型与最先进的方法进行了比较,并通过对四个基准数据集的定量分析,证明了本文算法的有效性。 -
我们进行了一项消融分析,分析了模型中关键部件的贡献。
3. BERT4Rec模型介绍
3.1 问题定义
定义, 为用户集合, 为物品集合, 为用户历史行为序列。我们的目标是预测下一时刻用户与每个候选物品交互的概率:
3.2 模型结构
如下图(b)所示,含有L层的Transformer,每一层利用前一层所有的信息。相比于图(d)基于RNN的推荐模型,self-attention可以捕获任意位置的信息。相比于基于CNN的推荐模型,可以捕获整个field的信息。相比于图(c)和图(d)的模型(都是left-to-right的单向模型),本文提出的双向模型可以解决现有模型的问题。
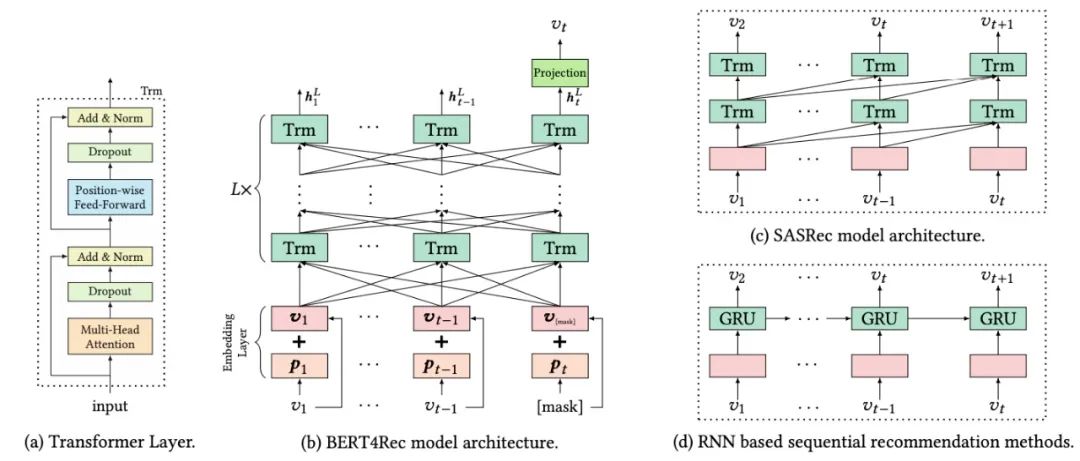
3.3 Transformer层
如图(a)所示,Transformer由两部分组成Multi-Head Self-Attention和Position-wise Feed-Forward network部分。
(1)Multi-Head Self-Attention
对于模型框架中的第 层Transformer,输入为 ,首先是Multi-Head Self-Attention过程:
其次是Dropout和Add & Norm过程,这里的Add就是Skip Connection操作,目的是反向传播时防止梯度消失的问题;而Norm是Layer Norm操作。
(2)Position-wise Feed-Forward Network
由于只有线性映射,为了使得模型具有非线性的性质,所以采用了Position-wise Feed-Forward Network。Position-wise的意思是说,每个位置上的向量分别输入到前向神经网络中,计算方式如下:
这里采用的激活函数是 Gaussian Error Linear Unit (GELU) ,而非RELU,其出自论文《Gaussian error linear units (gelus)》。GELU在RELU的基础上加入了统计的特性,在论文中提到的多个深度学习任务中都取得了较好的实验结果。
如果读者对Transformer或BERT的原理不熟悉,可以看一下我之前对于这些模型的详细解析:
3.4 Embedding层
在没有任何RNN或CNN模块的情况下,Transformer不知道输入序列的顺序。为了利用输入的顺序信息,我们在Transformer的Embedding层加入了位置嵌入,本文的位置向量是学到的,不是transformer中的正弦。位置向量矩阵可以给定任意位置的向量,但是要明确最大的长度,因此需要对输入序列进行截断。
对于给定的物品 ,其输入表示 是通过将相应的物品和位置Embedding求和来构造的:
3.5 Output层
经过 层的信息交换之后,我们得到输入序列中所有items的最终输出 。如上图(b)所示,我们在第 步掩盖掉物品 ,然后基于 预测被掩盖的物品 。这里使用两层带有GELU激活函数的前馈网络得到最终的输出:
这里需要注意,输出层的公式是推荐场景特有的,因此我来详细解释一下。 是前馈网络的权重矩阵; 和 是偏置项; 是item集合的embedding矩阵。BERT4Rec模型在输入层和输出层用了共享的物品embedding矩阵,目的是减轻过拟合和减少模型大小。
3.6 模型训练和预测
我们的目的是预测用户下一个要交互的物品 ,对于传统的序列推荐模型,如上图(d)中的RNN模型,输入是 ,转换为对应的输出为 ,那么我们自然可以拿最后一个时刻输出的物品进行推荐。而在BERT4Rec中,由于是双向模型,每一个item的最终输出表示都包含了要预测物品的信息,这样就造成了一定程度的信息泄漏。因此采用Cloze taske,也就是将输入序列中的p%的物品进行masked,然后根据上下文信息预测masked的物品。
在训练阶段,为了提升模型的泛化能力,让模型训练到更多的东西,同时也能够创造更多的样本,借鉴了BERT中的Masked Language Model的训练方式,随机的把输入序列的一部分掩盖(即变为[mask]标记),让模型来预测这部分盖住地方对应的物品:

采用这种训练方式,最终的损失函数为:
如上所述,我们在训练过程和最终的序列预测推荐任务之间是不匹配的。因为Cloze task的目的是预测当前被masked的物品,而序列预测推荐的目的是预测未来。为了解决这个问题,在预测阶段我们将masked附加到用户行为序列的末尾,然后根据该masked的最终隐藏表示来预测下一项。
为了更好地匹配序列推荐任务(即,预测最后一项),在训练过程中我们还生成了只mask输入序列中最后一项的样本。这个工作就像对序列推荐的微调一样,可以进一步提高推荐性能。
4. 实验
本论文的代码已开源,地址:https://github.com/FeiSun/BERT4Rec 。读者一定要亲自把论文读一遍,复现一下论文中的实验。我把实验部分总结如下:
-
首先,论文对比了BERT4Rec模型和一些Base模型在4个数据集上的表现,发现BERT4Rec模型相比于Base模型,其性能都有较大的提升。 -
其次,是对Embedding的长度 、训练时mask物品的比例和序列的最大长度 等参数的对比。结论为:Embedding长度越长,模型的效果更好;对于不同的数据集,最佳mask的比例并不相同;对于不同的训练集,最佳的序列长度也不相同。 -
最后,是对模型结构的一些对比实验,主要有是否使用PE(positional embedding),是否使用PFFN(position-wise feed-forward network),是否使用LN(layer normalization),是否使用RC(即Add操作,residual connection),是否使用Dropout,以及Transformer Layer的层数和Multi-head Attention中head的个数。
5. 个人感悟
总之,BERT4Rec就是把BERT用在推荐系统中,知道用户的播放(购买、点击、...)序列 item1, item2, item3,预测下一个播放的item问题。训练的时候使用Mask LM任务使用海量用户行为序列进行训练,模型评估时将序列的最后一个item进行masked,预测的时候在序列的最后插入一个“[mask]”,然后用“[mask]”增强后的embedding预测用户接下来会观看哪个item。整体来说,该篇论文为BERT在推荐系统领域的工业界落地提供了强有力的指导说明,但在推荐系统领域的学术界来说创新性就显得不是很大。
BERT4Rec对于实际工作,可以成为一个思路上的参考,对于具体的算法落地我提出两点思考:
-
BERT的训练和预测耗时耗资源,如何提高BERT的在线服务能力?这里腾讯开源了一个叫TurboTransformers的工具,对Transformer推理过程起到了加速作用,让线上推理引擎变得更加强大。开源地址:https://github.com/Tencent/TurboTransformers -
论文中没有使用物品、用户属性和场景的信息,只使用了行为信息,如何把额外的信息加入模型是值得重点探索的。
6. Reference
【1】Sun F, Liu J, Wu J, et al. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer[C]//Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 2019: 1441-1450.
【2】Hendrycks D, Gimpel K. Gaussian error linear units (gelus)[J]. arXiv preprint arXiv:1606.08415, 2016.
【3】RS Meet DL(六十一)-[阿里]使用Bert来进行序列推荐,https://mp.weixin.qq.com/s/y23s_Y8Der12NMVw9y2NEA
【4】BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer,https://blog.csdn.net/luoxiaolin_love/article/details/93192601
【5】BERT4REC:使用Bert进行推荐 - 魏晋的文章 - 知乎 https://zhuanlan.zhihu.com/p/97123417
【6】BERT在美团搜索核心排序的探索和实践,https://mp.weixin.qq.com/s/mFRhp9pJRa9yHwqc98FMbg
【7】微信也在用的Transformer加速推理工具 | 腾讯第100个对外开源项目,地址:https://mp.weixin.qq.com/s/3QBTccXceUhK47TlMcCllg
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套!
![]()
![]()
![]()
后台回复【五件套】
下载二:南大模式识别PPT
![]()
后台回复【南大模式识别】




由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!





