【平行讲坛】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集

作者:李轩、田永林等
审校:王坤峰
本文介绍了来自中国科学院自动化研究所复杂系统管理与控制国家重点实验室的研究成果。针对交通视觉研究中存在的真实图像集获取和标注成本高、难以覆盖复杂自然环境、极端场景样本稀少、训练的模型适应性差等问题,中科院自动化所王飞跃研究员、王坤峰副研究员带领李轩、田永林、严岚等研究生开展了平行视觉研究。近期,他们发表了两篇论文,提出了构建人工场景和生成虚拟图像集ParallelEye的方法,并且以目标检测任务为例,验证了ParallelEye的有效性。
两篇论文的下载地址如下:
https://arxiv.org/abs/1712.08394

https://arxiv.org/abs/1712.08470

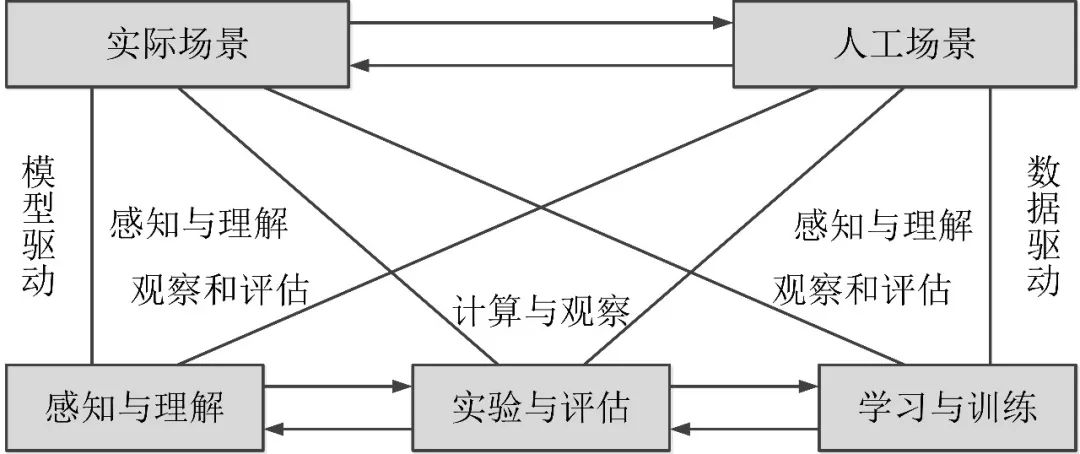
在视觉计算研究中,对复杂环境的适应能力通常决定了视觉算法能否实际应用,已经成为该领域的研究焦点之一。王坤峰、苟超、王飞跃将复杂系统建模与调控的ACP方法引入视觉计算领域,提出了平行视觉(Parallel Vision)理论。平行视觉利用人工场景来模拟和表示复杂挑战的实际场景,通过计算实验进行各种视觉模型的训练与评估,最后借助平行执行来在线优化视觉系统,实现对复杂环境的智能感知与理解。这一虚实互动的视觉计算方法结合了计算机图形学、虚拟现实、机器学习、知识自动化等技术,是视觉系统走向应用的有效途径和自然选择。平行视觉的框架结构如下图所示。
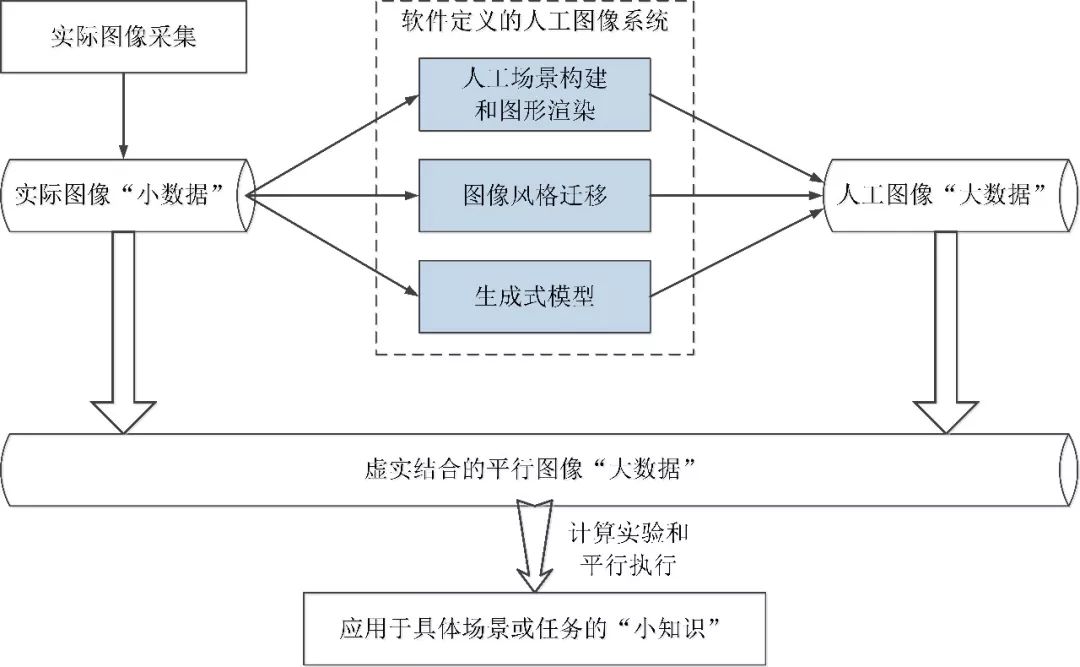
考虑到虚拟图像在视觉计算研究中的重要性,王坤峰、王飞跃等在平行视觉的基础上,又提出了一种新的图像生成理论框架——平行图像(Parallel Imaging)。平行图像是平行视觉的一个分支,提供平行视觉研究需要的图像数据。平行图像的核心单元是软件定义的人工图像系统。从实际场景中获取特定的图像“小数据”,输入人工图像系统,解析和吸纳实际图像的特点,加入外部信息,自动生成大量新的人工图像数据。这些人工图像数据和特定的实际图像数据一起构成解决复杂视觉问题所需要的平行图像“大数据”集合,用于视觉模型的学习与评估研究。总之,平行图像遵循实际图像“小数据”→平行图像“大数据”→特定“小知识”的技术流程,如下图所示。
当前主流的深度学习方法,主要是数据驱动的。这意味着,要想建立在复杂场景下可靠运行的视觉计算模型,需要依靠大规模多样化的训练数据。由于实际场景具有高度复杂、不可控、不可重复的特点,给数据的收集带来了极大的困难。例如,收集城市中不同路段在各种时段、季节、天气、路况下的交通图像,非常费时费力。同时,收集到的这些数据只是原始数据,对这些原始数据进行精确的标注,不但费时费力,并且容易出错。
针对上述问题,可否采用更加智能的方法,高效快捷地完成对大规模多样化交通图像的采集和标注?近些年,随着计算机图形学、虚拟现实、生成式模型等技术的持续发展,给研究人员提供了解决这一问题的新思路,即建立人工场景,根据具体需求来创建虚拟数据集。在人工场景中,可以对天气、光照、人流、车流等因素灵活设置,最大程度地满足视觉模型研究对数据多样性的需求,并且在生成数据的同时,自动获得详细且精确的标注信息,从而将研究人员从数据采集和标注的枯燥劳动中解放出来,大大节省了数据获取成本,把更多精力投入到算法的开发上。更进一步,利用虚拟数据生成过程的可重复性,可以通过固定生成过程的大多数参数,来对感兴趣的因素进行研究,有利于全面评价视觉模型的性能。
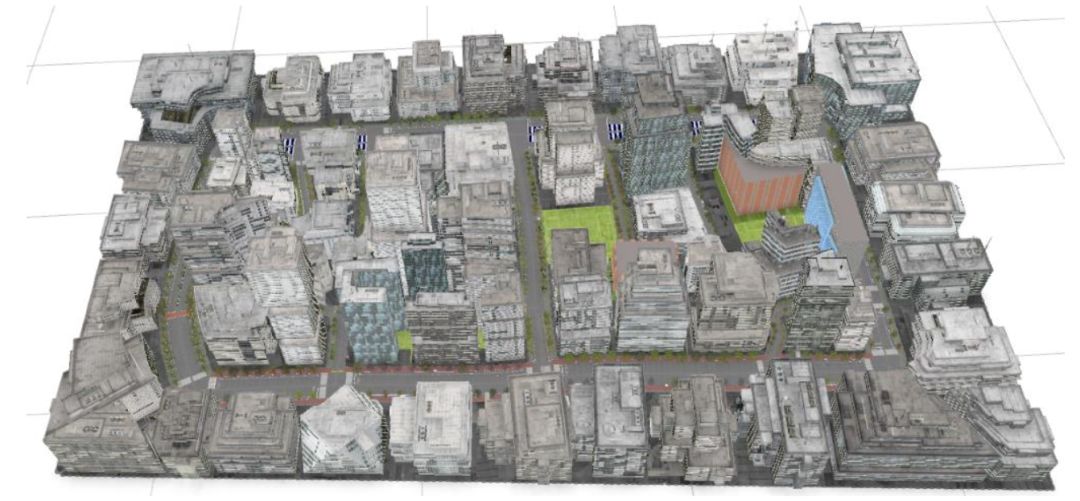
在两篇论文[1][2]中,李轩、田永林等利用OpenStreetMap、CityEngine、Unity3D等计算机图形学工具,在真实地图的基础上,构建了城市交通场景,导入车辆、行人、交通设施等模型,并通过程序定义虚拟世界的行为规则,建立了人工场景。在人工场景中,各类目标能够交互,例如车辆和行人感知红绿灯信息,采取等待或行进动作;车辆在感知前后方道路车流的情况下,采取加速或减速以及转弯动作。下图展示了他们构建的人工场景的一部分。在此基础上,他们在人工场景中设置虚拟摄像机,采集虚拟图像。虚拟摄像机可以安置在车内或道路两侧,通过调整摄像机的视角和焦距,来重复采集图像。
他们基于人工场景,创建和收集了新的虚拟图像数据集,命名为“平行眼”(ParallelEye)。该数据集由三个子集组成,分别是ParallelEye_01、ParallelEye_02和ParallelEye_03。在ParallelEye_01的建立过程中,摄像头观察角度与该车辆的移动方向一致,因此数据集中包含了较多的小目标。在ParallelEye_02中,摄像头视角被调整为与行进方向垂直,所以观察到的是摄像头所在车辆两旁的目标,相比于ParallelEye_01,目标尺寸较大。在建立ParallelEye_03的过程中,特意提高了道路上车辆的密度,来模拟严重遮挡的效果,还在每一帧中,对目标的颜色进行改变,丰富了数据的多样性。下图显示了三个子数据集中的样本图像。

为了模拟复杂环境条件,提高数据集的多样性,他们还为人工场景设计了阴、晴、雨、雪、雾等天气条件以及白天、日出、日落等不同光照时段。在不同环境条件下,生成的虚拟图像表现出极大的视觉差异,为分析和提高视觉计算模型的性能提供了有力支持。基于人工场景建立虚拟数据集的优势不仅在于设计灵活,而且还能很好地解决图像标注的问题。利用虚拟现实工具的内部机制,对场景各类目标信息进行处理,能够自动获得详细且精确的标注信息,包括深度、光流、目标边框、轨迹、像素级别的语义分割、实例分割等。使得ParallelEye数据集能够用于目标检测、跟踪、语义/实例分割等多种视觉计算任务中。下图显示了同一个人工场景模拟不同光照和天气条件的效果,以及自动生成的部分标注信息。

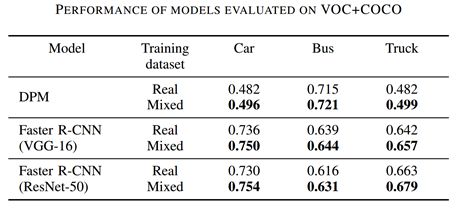
为了验证数据集的有效性,他们首先在MS COCO和PASCAL VOC上进行了实验。从两个数据集中抽取一定比例的包含car、bus和truck的图像,组成新的数据集VOC+COCO,并按照3:1的比例划分成训练集和测试集。他们训练了目标检测模型DPM和基于不同基础网络的Faster R-CNN模型,然后在真实的测试集上进行了测试,计算出了平均准确率(AP)。接着,他们在训练集中加入来自ParallelEye的虚拟数据,并对上述模型按照同样的方式进行重新训练,对训练结果在上述真实测试集上进行评测。下表对比了完全采用真实数据(Real)训练的模型和虚实结合(Mixed)训练模型的结果,可以看到,虚拟数据集的加入,为模型在三类目标上的检测性能均带来了一定提升。
然后,他们在KITTI数据集上针对car这一目标进行了实验,DPM的训练采用与VOC+COCO上的实验相同的方式。对Faster R-CNN的训练,他们采用了先在虚拟数据集上进行预训练,然后在真实数据集上微调的方式。从下表显示的实验结果可以看出,虚拟图像集ParallelEye可以在一定程度上提升模型的检测效果。
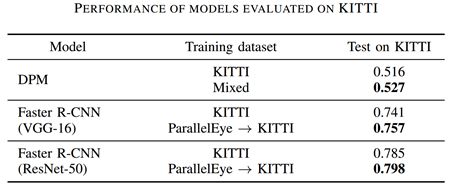
下图显示了部分测试图像的检测结果(上部图像对应真实数据训练的模型,下部图像对应虚实结合训练的模型)。可以看出,采用虚实结合的方式训练模型,在检测小目标和部分遮挡目标方面,有更好的效果。这和虚拟数据中对小目标和高遮挡目标有较充分的模拟有关。

利用人工场景在个性化设计数据集方面的突出优势,可以对已有模型进行针对性测试,从而获得对模型性能的更好认识。下面的实验证明了虚拟数据集在测试模型性能方面的有效性。
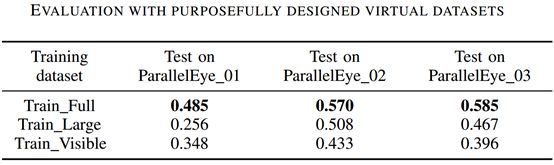
本实验以KITTI数据集中的car这一类目标为研究对象,在Faster R-CNN上进行了实验。他们将数据以1:1的比例划分成训练集和测试集。首先利用全部训练集训练了Faster R-CNN模型,命名为“Train_Full”;接着,分别删除训练集中的小目标(包含像素小于3600的目标)和被遮挡目标(相应标签中未被标记为“fully visible”的目标),利用剩余数据训练得到模型“Train_Large”和“Train_Visible”。在三个模型中,“Train_Full”得到了较好的训练,在本实验中用作baseline。而“Train_Large”和“Train_Visible”则分别代表了未在小目标和被遮挡目标上得到较好训练的模型。他们对这三个模型在ParallelEye_01、ParallelEye_02、ParallelEye_03进行了测试,结果如下表所示。
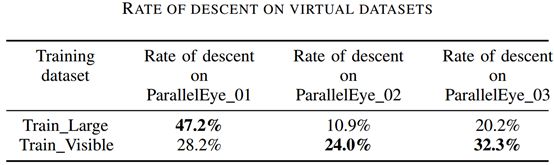
他们计算了“Train_Large”和“Train_Visible”这两个未得到充分训练的模型相比于“Train_Full”在三个虚拟测试集上的变坏程度(性能下降比例),结果见下表。可以看到“Train_Large”在ParallelEye_01上性能下降最多,而“Train_Visible”在ParallelEye_03上性能下降最多。这和ParallelEye_01及ParallelEye_03分别拥有较多的小尺寸目标和高遮挡率目标的事实一致,从而说明了个性化设计的虚拟数据集在进行模型性能评测时的价值。
两篇论文[1][2]在平行视觉理论框架下,利用计算机图形学和虚拟现实技术,构建了多样化的人工城市交通场景。在此基础上,有针对性地收集了虚拟图像集ParallelEye,并自动获得了多种视觉计算任务的标注信息。这种创建数据集的方式,在一定程度上解决了从实际场景中采集和标注大规模多样化数据的困难,还提高了数据采集的灵活性和标注的准确性。实验验证了虚拟图像集ParallelEye在提升目标检测模型性能和评测已有模型中的重要作用。
[1] Xuan Li, Kunfeng Wang, Yonglin Tian, Lan Yan, and Fei-Yue Wang. The ParallelEye Dataset: Constructing Large-Scale Artificial Scenes for Traffic Vision Research. arXiv: 1712.08394, 2017.
[2] Yonglin Tian, Xuan Li, Kunfeng Wang, and Fei-Yue Wang. Training and Testing Object Detectors with Virtual Images. arXiv: 1712.08470, 2017.

📚往期文章推荐

🔗澳门大学陈俊龙 | 宽度学习系统如何用横向扩展进行高效增量学习?
🔗PyTorch一周年 | 是否比TensorFlow来势凶猛?
🔗谷歌大脑2017总结 | Jeff Dean执笔,干货满满
🔗Science | 机器学习究竟将如何影响人类未来的工作?
🔗微软沈向洋 | 从Eliza到小冰,社交对话机器人的机遇和挑战
🔗征稿延期通知|第二届IEEE/IFAC区块链与知识自动化国际会议

点击“阅读原文”,快速进入峰会报名通道!




