导师实验室对学生影响有多大?
读博士导师非常重要,比你们想象得还要更重要。一个优秀的导师不仅在科研帮上很多忙,而且让你懂得怎么做科研,更重要的他教会你怎么做一个合格的学者。 跟这种导师工作,你会发现科研其实是一件非常有趣的事情,它带来的乐趣远超于你发了多少顶级会议的论文。
之前跟Max Welling教授工作过一段时间,我相信很多人都听说过这位大牛。当很多的学者都忙着发各种论文,把顶会论文数量看得很重的时候,他还是一如既往地深究属于自己的领域, 所以当人们提起MCMC的时候大部分人都会马上联想到这位教授。能够开辟属于自己的领域,而且在这个领域上不断地为别人“挖坑”是非常不容易的,这需要一种很强烈的信念。这不是在顶会论文数量上就能体现出来的。一个学者被很多人记住而且受到尊重,并不是因为他发过多少篇文章,而是他的一些工作(可能就是那么几篇论文)确实推动了整个学术界的发展。这就需要一个强烈的信念和对学术的追求。
Max Welling教授基本上每天8点之前会到办公室,下午5-6点回家,在学校里他的主要的工作就是读论文,对有些论文他也会自己做推导,跟学生讨论学术(多数情况下都是在白板上两个人一起边写边讨论)。工作当中我们都会把他当成一位同事,有问题一起讨论,他也会给出非常有建设性的意见。我还记得当时一起做科研的时候,我们俩仅在一周之内就有个100多封邮件的来往,就是在一起PK问题,想方法,给出解决方案,讨论过程中一个数学符号的错误也不会放过。这种过程回想起来特别有趣,很容易把人带进科研的乐趣当中。即使犯了一些错误,也会不断地去鼓励你。
另外,因为他是属于自己领域的权威,所以对下一步要做什么,往哪个方向发展非常清楚。所以他的学生也不会因为没有一个课题而苦恼,而且这种课题都非常具有针对性和创新性,使得学生都在解决一个难并且重要的问题,后来这些学生也都有属于自己的小领域。比如Kingma是Autoencoderr和Adam的作者,这也是在贝叶斯和深度学习领域一个开创性的工作。还有Cohen一直在研究Group invariant和深度学习的联系。在这个小领域做出了不少的贡献。Kipf是Graph Convolutional Network(图卷积网络)的作者,为邻域内带来了重大突破。
所以我也建议不要把发论文看得太重。首先要去想,你想解决什么问题,这个问题是不是值得去解决,如果值得那就现在就动手去做吧...
为了迎合时代的需求,我去年开设了《机器学习高端训练营》,这个训练营的目的很简单:想培养更多高端的人才,帮助那些即将或者目前从事科研的朋友,同时帮助已从事AI行业的提高技术深度。
在本期训练营(第四期)中我对内容做了大幅度的更新,一方面新增了对前沿主题的讲解如图神经网络(GCN,GAT等),另外一方面对核心部分(如凸优化、强化学习)加大了对理论层面上的深度。除此之外,也会包含科研方法论、元学习、解释性、Fair learning等系列主题。目前在全网上应该找不到类似体系化的课程。采用全程直播授课模式。
那什么样的人适合来参加高阶班呢?
从事AI行业多年,但技术上总感觉不够深入,感觉在技术上遇到了瓶颈;
停留在使用模型/工具上,很难基于业务场景来提出新的模型;
对于机器学习背后的优化理论、前沿的技术不够深入;
计划从事尖端的科研、研究工作、申请AI领域研究生、博士生;
打算进入最顶尖的AI公司比如Google,Facebook,Amazon, 阿里,头条等;
读ICML,IJCAI等会议文章比较吃力,似懂非懂感觉,无法把每个细节理解透;
从优化角度理解机器学习
优化技术的重要性
常见的凸优化问题
线性规划以及Simplex Method
Two-Stage LP
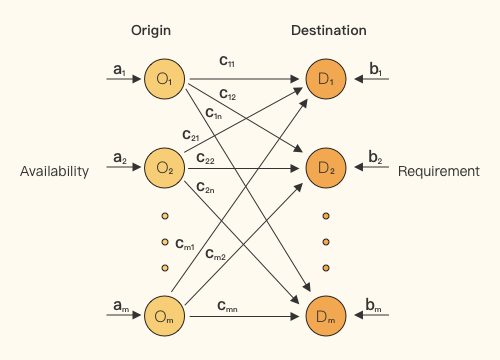
案例:运输问题讲解
凸集的判断
First-Order Convexity
Second-order Convexity
Operations Preserve Convexity
二次规划问题(QP)
案例:最小二乘问题
项目作业:股票投资组合优化
常见的凸优化问题类别
半定规划问题
几何规划问题
非凸函数的优化
松弛化(Relaxation)
整数规划(Integer Programming)
案例:打车中的匹配问题
拉格朗日对偶函数
对偶的几何意义
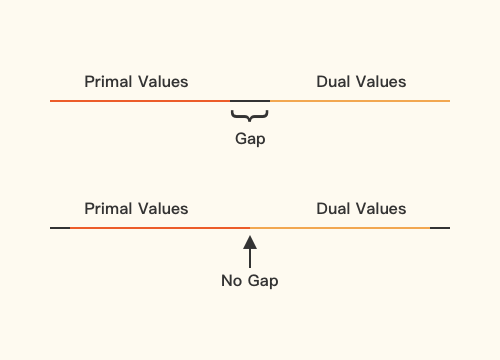
Weak and Strong Duality
KKT条件
LP, QP, SDP的对偶问题
案例:经典模型的对偶推导及实现
对偶的其他应用
一阶与二阶优化技术
Gradient Descent
Subgradient Method
Proximal Gradient Descent
Projected Gradient Descent
SGD与收敛
Newton's Method
Quasi-Newton's Method
向量空间和图论基础
Inner Product, Hilbert Space
Eigenfunctions, Eigenvalue
傅里叶变化
卷积操作
Time Domain, Spectral Domain
Laplacian, Graph Laplacian
卷积神经网络回归
卷积操作的数学意义
Graph Convolution
Graph Filter
ChebNet
CayleyNet
GCN
Graph Pooling
案例:基于GCN的推荐
Spatial Convolution
Mixture Model Network (MoNet)
注意力机制
Graph Attention Network(GAT)
Edge Convolution
空间域与谱域的比较
项目作业:基于图神经网络的链路预测
拓展1: Relative Position与图神经网络
拓展2:融入Edge特征:Edge GCN
拓展3:图神经网络与知识图谱: Knowledge GCN
拓展4:姿势识别:ST-GCN
案例:基于图的文本分类
案例:基于图的阅读理解
Markov Decision Process
Bellman Equation
三种方法:Value,Policy,Model-Based
Value-Based Approach: Q-learning
Policy-Based Approach: SARSA
Multi-Armed bandits
Epsilon-Greedy
Upper Confidence Bound (UCB)
Contextual UCB
LinUCB & Kernel UCB
案例:Bandits在推荐系统的应用案例
Monte-Carlo Tree Search
N-step learning
Approximation
Reward Shaping
结合深度学习:Deep RL
项目作业:强化学习在游戏中的应用案例
Seq2seq模型的问题
结合Evaluation Metric的自定义loss
结合aspect的自定义loss
不同RL模型与seq2seq模型的结合
案例:基于RL的文本生成
第十四周:贝叶斯方法论简介
贝叶斯定理
从MLE, MAP到贝叶斯估计
集成模型与贝叶斯方法比较
计算上的Intractiblity
MCMC与变分法简介
贝叶斯线性回归
贝叶斯神经网络
案例:基于Bayesian-LSTM的命名实体识别
第十五周:主题模型
生成模型与判别模型
隐变量模型
贝叶斯中Prior的重要性
狄利克雷分布、多项式分布
LDA的生成过程
LDA中的参数与隐变量
Supervised LDA
Dynamic LDA
LDA的其他变种
项目作业:LDA的基础上修改并搭建无监督情感分析模型
Detailed Balance
对于LDA的吉布斯采样
对于LDA的Collapsed吉布斯采样
Metropolis Hasting
Importance Sampling
Rejection Sampling
大规模分布式MCMC
大数据与SGLD
案例:基于分布式的LDA训练
变分法核心思想
KL散度与ELBo的推导
Mean-Field变分法
EM算法
LDA的变分法推导
大数据与SVI
变分法与MCMC的比较
Variational Autoencoder
Probabilistic Programming
案例:使用概率编程工具来训练贝叶斯模型
模型的可解释性
解释CNN模型
解释序列模型
Meta Learing
Fair Learning
技术前瞻

线性回归以及优化实现
Two-Stage随机线性规划一下优化实现
Mixed Integer Linear Programming
提供approximation bounds
SVM,LP等模型
对偶技术
KKT条件
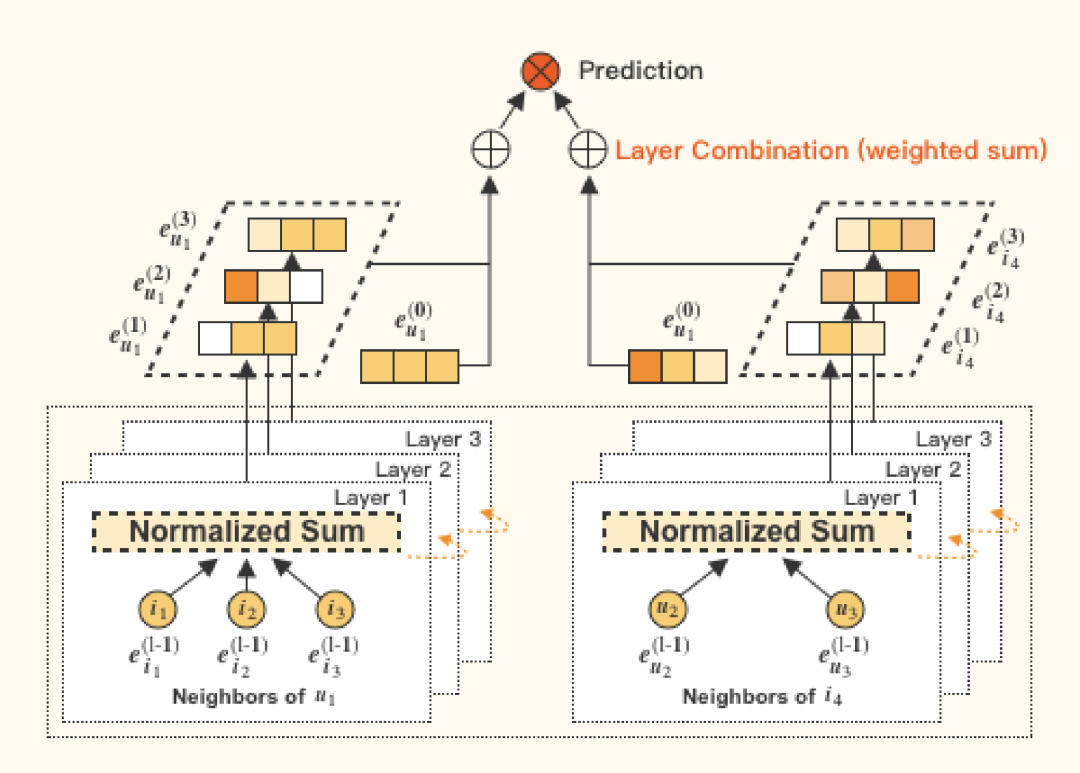
语法分析
图神经网络
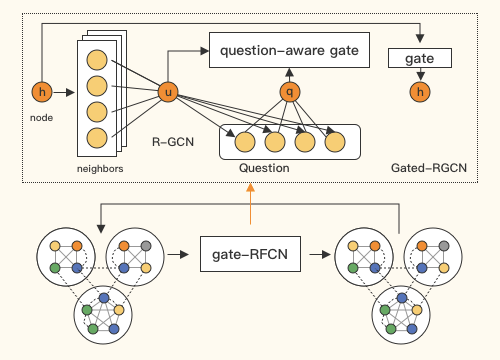
命名识别,关系抽取
图神经网络
Heterogeneous Graph
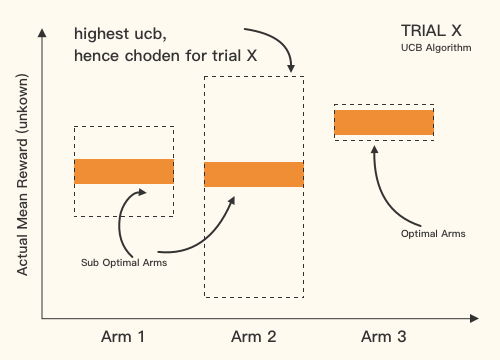
Exploration & Exploitation
Epsilon Greedy
Upper Confidential Bounder
LineUCB
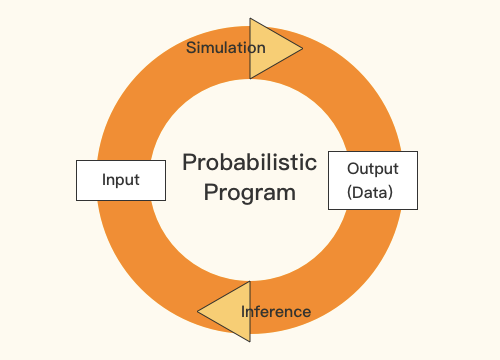
概率编程
主题模型
MCMC和变分法
二次规划
不同的正则使用
基于限制条件的优化
先验的引入
区别于劣质的PPT讲解,导师全程现场推导,让你在学习中有清晰的思路,深刻的理解算法模型背后推导的每个细节。更重要的是可以清晰地看到各种模型之间的关系!帮助你打通六脉!


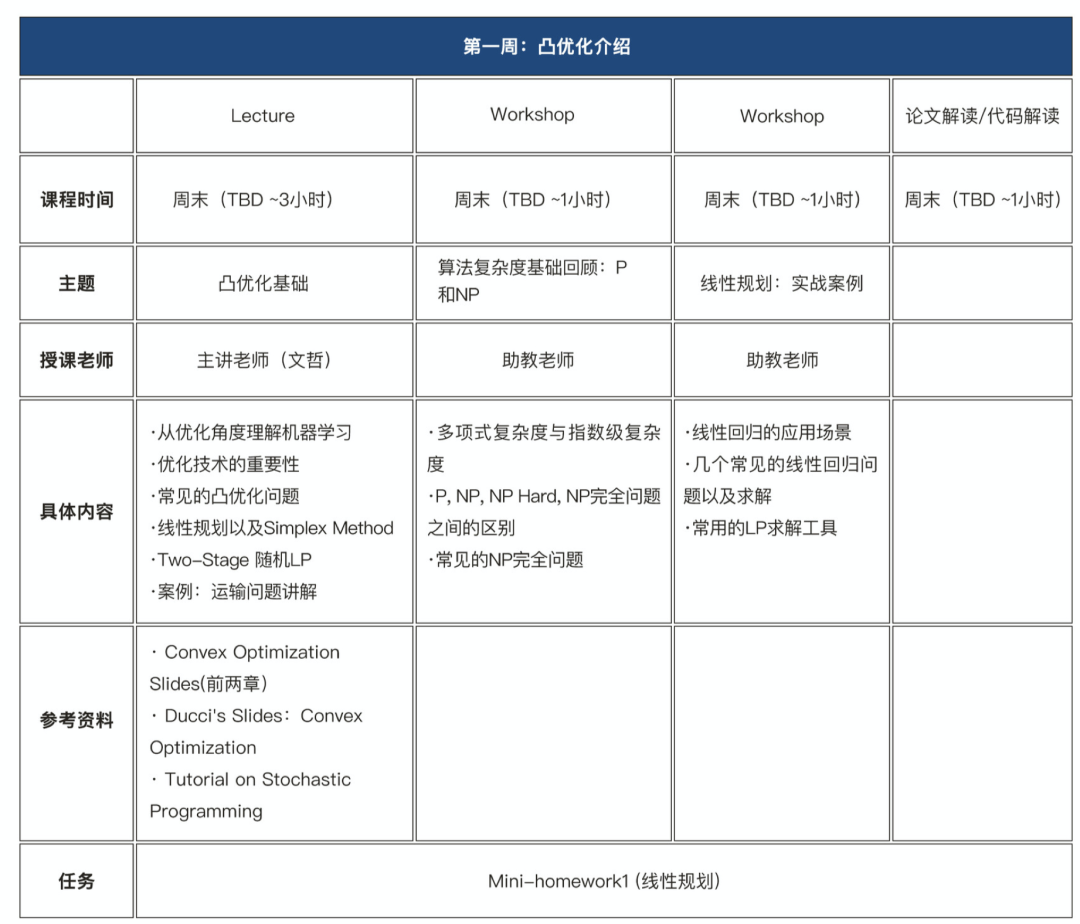
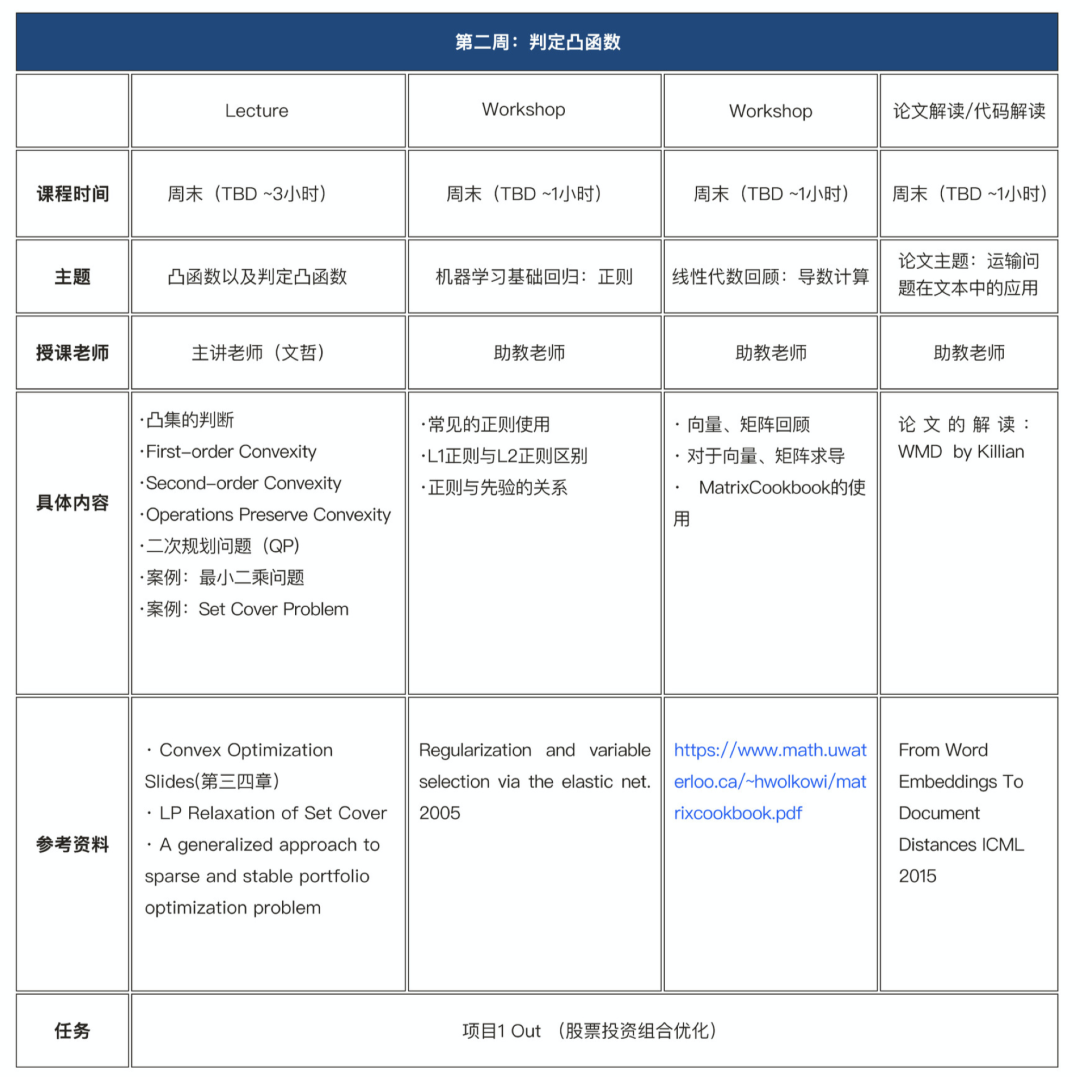
计算机相关专业的本科/硕士/博士生,需要具备一定的机器学习基础
希望能够深入AI领域,为科研或者出国做准备
想在步入职场前,深入AI领域,并把自己培养成T字形人才
目前从事AI相关的项目工作,具有良好的机器学习基础
希望打破技术上的天花板,能够有能力去做模型上的创新
以后往资深工程师、研究员、科学家的职业路径发展