AI攒论文指日可待?Transformer生成论文摘要方法已出
选自arXiv
作者:Sandeep Subramanian等
机器之心编译
参与:Panda
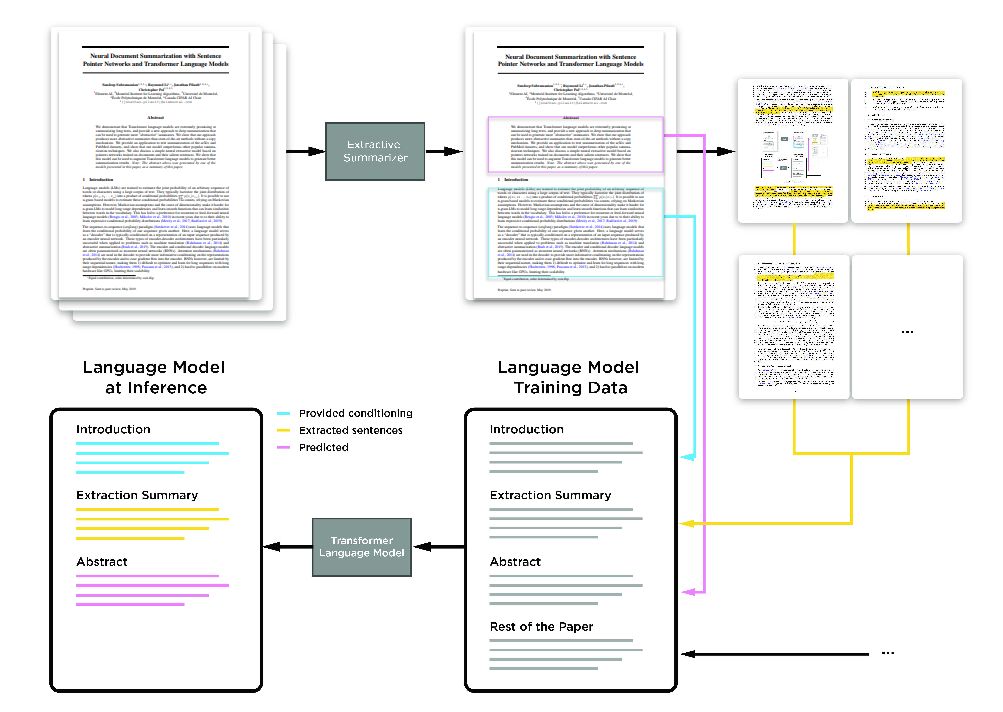
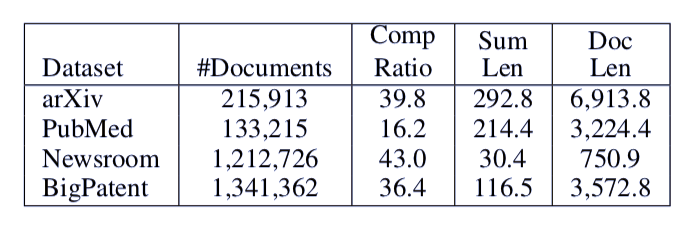
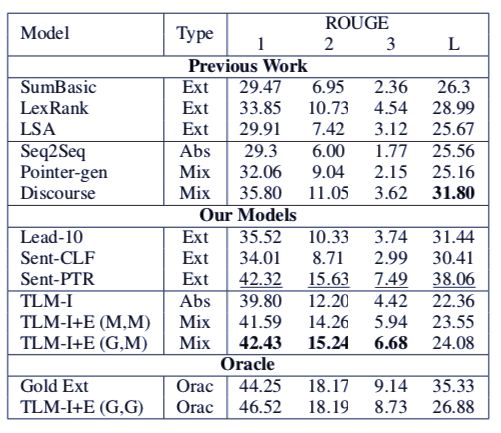
写论文是一件「痛并快乐着」的事情。 快乐的是可以将自己的研究公之于众,痛苦的是有大段大段的文本内容需要完成。 特别是摘要、引言、结论,需要不断重复说明论文的主要研究、观点和贡献。 现在,这样的工作可以依赖 AI 完成了。 Element AI 的研究者们提出了一种新的模型,使用 Transformer 架构,自动地生成论文的摘要。 AI 攒论文的进程又往前走了一步。



登录查看更多
相关内容



相关VIP内容
相关资讯
相关论文