自“彩票假设”理论被授予2019 ICLR 最佳论文后,该领域又有了哪些新的研究进展?
 编译
|
Mr Bear
编译
|
Mr Bear
在人们互相交流和信息传递的过程中,「隐喻」的作用极其重要。在1970年之前,当人们提起「桌面」这个单词,联想到的还都是放满了锅碗瓢勺的桌子。但是当天才计算机大师Alan Kay在 Xerox PARC 实验室设计了现代的 GUI 交互界面之后,桌面这个词可能更多的指代的就是配备各种图形化操作系统的电脑桌面了。
-
通过对过参数化的函数进行正则化处理,使剪枝后的模型具有较强的泛化能力。 -
能够找出原本庞大网络中性能优越的小型子网络(现有存储条件可满足),从而减少模型前向推理时的内存需求。 -
减少了模型所需的算力、耗电量、存储和延迟等需求,从而使其能够在移动设备部署。
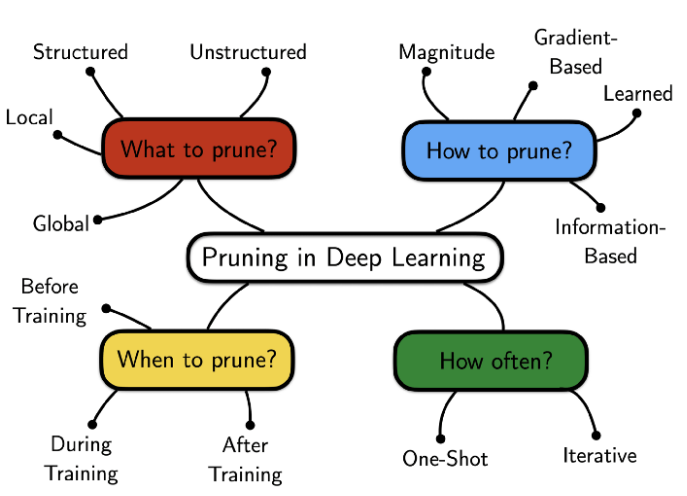 图 2:深度学习网络剪枝要考虑的因素:剪掉哪些部分、如何剪枝、何时剪枝、剪枝频率如何?
图 2:深度学习网络剪枝要考虑的因素:剪掉哪些部分、如何剪枝、何时剪枝、剪枝频率如何?
2
彩票假设(LTH)及其扩展方法
彩票假设:任何随机初始化的稠密的前馈网络都包含具有如下性质的子网络——在独立进行训练时,初始化后的子网络在至多经过与原始网络相同的迭代次数后,能够达到跟原始网络相近的测试准确率。
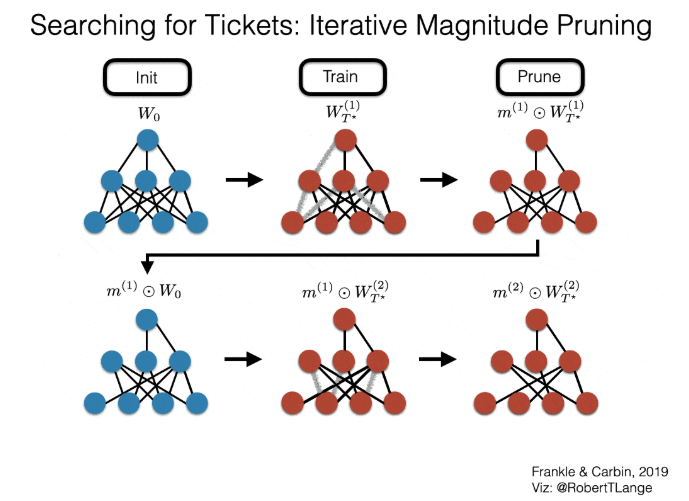 图 3:寻找「中奖网络」的过程
图 3:寻找「中奖网络」的过程
 图 4:IMP 与网络剪枝的核心问题
图 4:IMP 与网络剪枝的核心问题
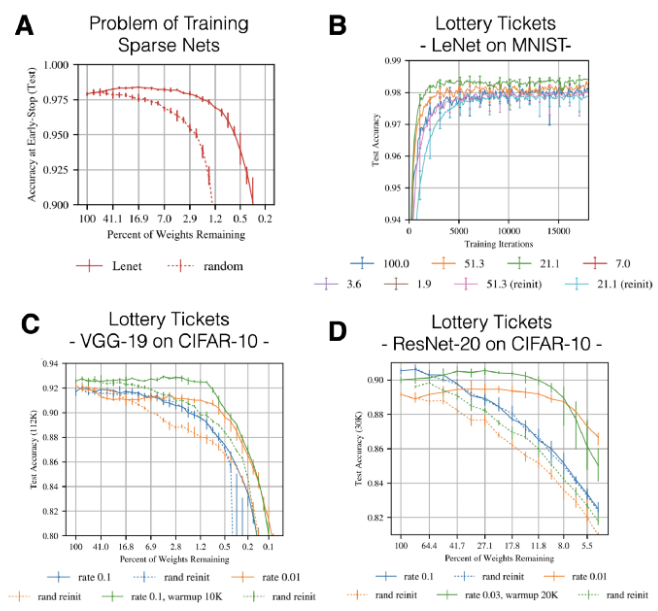 图 5:LTH 的关键性结果。
图 5:LTH 的关键性结果。
-
B 图:IMP 能够在不进行任何超参数调整的前提下,仅使用较少的迭代次数就能找出性能超越未修剪的稠密网络的稀疏子网络(图 B 中不同颜色的曲线代表不同的被剪掉的权值比例)。其中,中奖彩票的初始化和随机重初始化的最终性能之间的差异被称为「彩票效应」(Lottery Ticket Effect)。 -
图 C 和图 D:为了能够将原始的实验结果扩展到更加复杂的任务和网络架构中(如 CIFAR-10数据集,VGG19 和 Resnet20 等网络),Frankle 和 Carbin 不得不对学习率进行调整,并且引入「热身」规划机制,让模型在预定义的迭代集合内从 0 退火到最终的学习率上。请注意,根据经验,适合于 ResNet 的学习率远远小于适合于 VGG19 的学习率。
 图 6:带回放机制的彩票假设
图 6:带回放机制的彩票假设
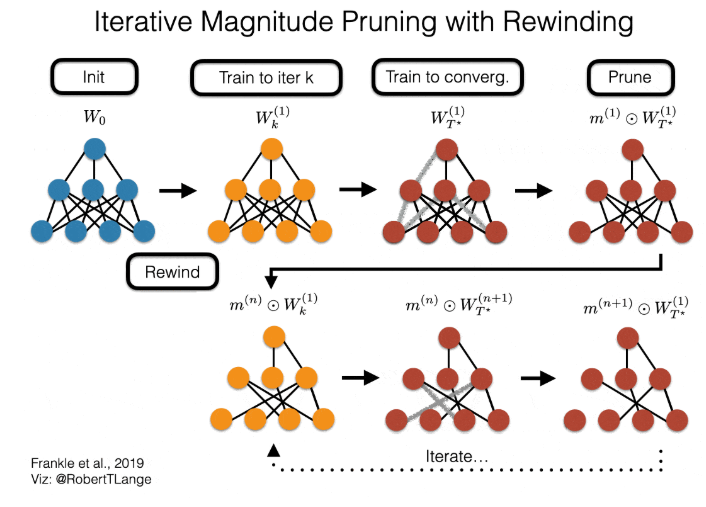
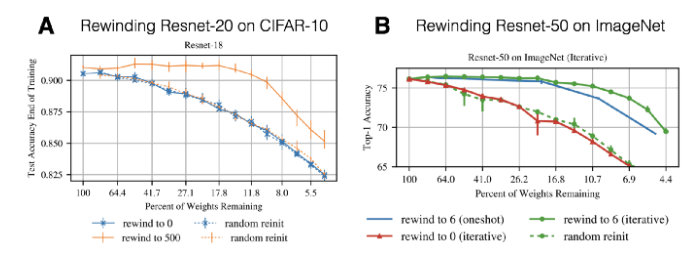 图 8:LTH 关键结论的放缩结果
图 8:LTH 关键结论的放缩结果
-
假设我们可以用无限的算力进行搜索,上述三种模型约简方法最终的准确率和参数效率(剪枝前后的压缩比)的表现和差异将如何? -
给定固定的用于搜索的算力预算时,上述三种模型约简方法最终的准确率和参数效率的表现和差异将如何?
-
在算力无限和给定固定算力预算的实验中,使用权值回放并重新训练的性能都明显优于简单的微调并再训练的方法。在结构化和非结构化剪枝的对比实验中,该结论也成立。 -
学习率回放方法的性能优于权值回放方法。此外,虽然权值回放法在 k=0 时可能效果不好,但将学习率回放到训练过程开始的状态往往是有效的。 -
在准确率、压缩比和搜索成本效率方面,权值回放 LTH 网络是目前性能最优的对初始网络进行剪枝的模型。
3
剖析彩票假设:鲁棒性与学习模式
Zhou et al. (2019) — Deconstructing lottery tickets: Zeros, signs, and the supermask
-
对比不同的选择被屏蔽权值的打分方式:保留那些最小的训练后权值;保留初始化时最大或者最小的权值,或者在权值空间中幅值变化最大或最小的权重。 -
分析如果不将权值回放到初始状态,是否仍然会得到中奖网络:Zhou 等人对比了随机重初始化、重新打乱保留的权值,以及恒定初始化等情况。 -
将被掩模屏蔽的值固定为初始化的值,而不是将它们设定为 0。
-
那些成比例地保留剩余权值与初始状态之间距离的评分标准,会得到与保留「最大权值」的标准相同的性能。 -
只要在执行回放时将权值的符号保持为初始权值的符号,就可以获得和执行经典的 IMP 方法时获得的相同的中奖网络(请注意:该结论在 Frankle 于 2020 年发表的论文「The Early Phase of Neural Network Training 」中无法复现)。 -
将权值屏蔽为 0 是很重要的。
Frankle et al. (2020a) — Linear Mode Connectivity & the Lottery Ticket Hypothesis
 图 9:线性模式连通性。
图 9:线性模式连通性。
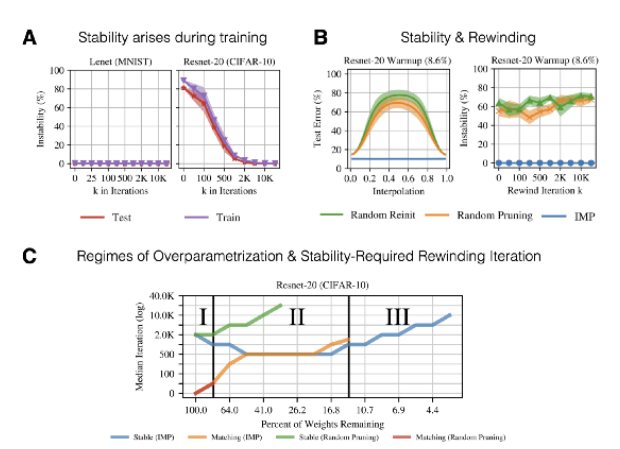 图 10:
不同实验设定下的线性模式连通性。
图 10:
不同实验设定下的线性模式连通性。
-
阶段 1:网络严重过参数化,以致于随机剪枝也能得到很好的效果。 -
阶段 2:随着我们剪掉了越来越多的权值参数,只有 IMP 得到了效果不错的稳定网络。 -
阶段 3:在剩下的权值十分稀疏时,尽管 IMP 仍然会得到稳定的网络,但是其它网络的性能较中奖网络就有较大差距了。
Frankle et al. (2020b) — The Early Phase of Neural Network Training
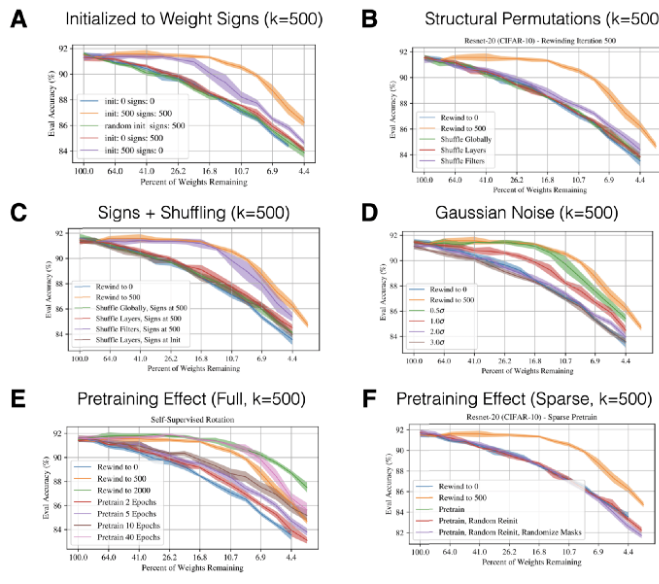
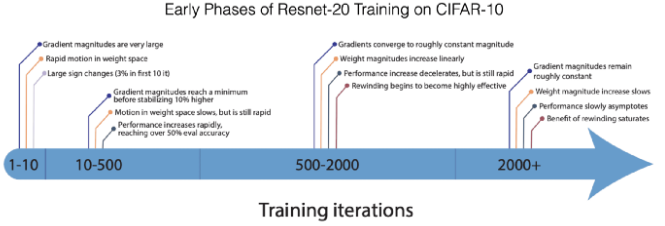 图 12:神经网络训练初期的情况
图 12:神经网络训练初期的情况
4
使用较少的计算量发现中奖网络
You et al. (2020) — Drawing Early-Bird Tickets: Towards more efficient training of deep networks
-
鲁棒的第一阶段:学习较低频/大奇异值的成分。 -
第二阶段:学习较高频/小奇异值的成分。

Tanaka et al. (2020) — Pruning neural networks without any data by iteratively conserving synaptic flow
 图 14:模型性能与突触流算法。
图 14:模型性能与突触流算法。
5
在不同的数据集、优化器和域上,彩票网络是否能泛化?
Morcos et al. (2019) — One ticket to win them all: Generalizing lottery ticket initializations across datasets and optimizers
-
在一个源数据集上使用 IMP 找到一个中奖网络。 -
在一个新的目标数据集上,通过训练源数据集上获得的中奖网络至收敛,对其进行再次的评估。
-
图 A 与图 B:将在一个小的源数据集上得到的 VGG-19 的中奖网络迁移到 ImageNet 上取得了很好的效果,但是其性能要弱于直接在目标数据集(ImageNet)上得到的中奖网络。另一方面,利用一个比目标数据集更大的数据集得到的中奖网络,甚至要比使用目标数据集得到的中奖网络有更好的性能。 -
图 C 与图 D:在 ResNet-50 上的情况与在 VGG-19 上的情况大致相同。但是我们可以看到,在 ResNet-50 上,其性能在剪枝程度更小时就已经开始下降了(性能下降地更快)。 图 15:在不同的数据集上迁移中奖网络。
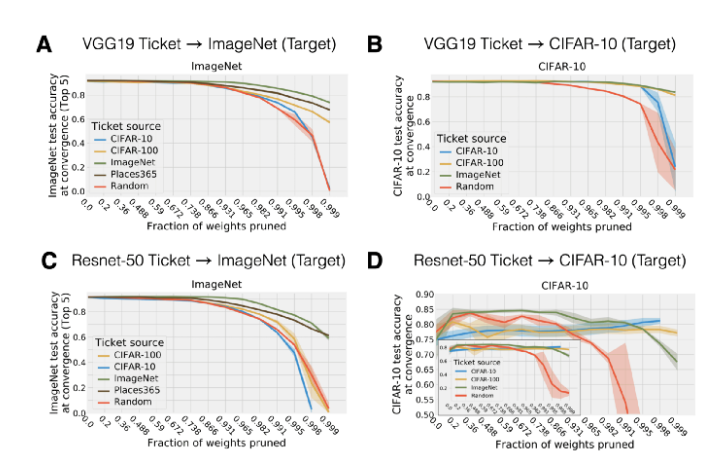
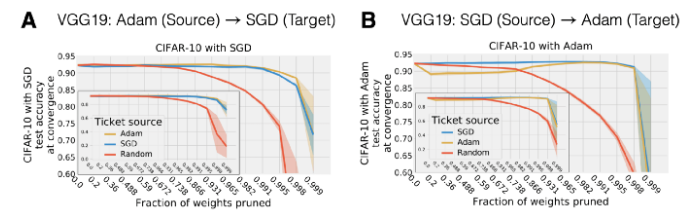 图 16:在不同的优化器之间迁移中奖网络。
图 16:在不同的优化器之间迁移中奖网络。
Yu et al. (2019) — Playing the lottery with rewards and multiple languages: lottery tickets in RL and NLP
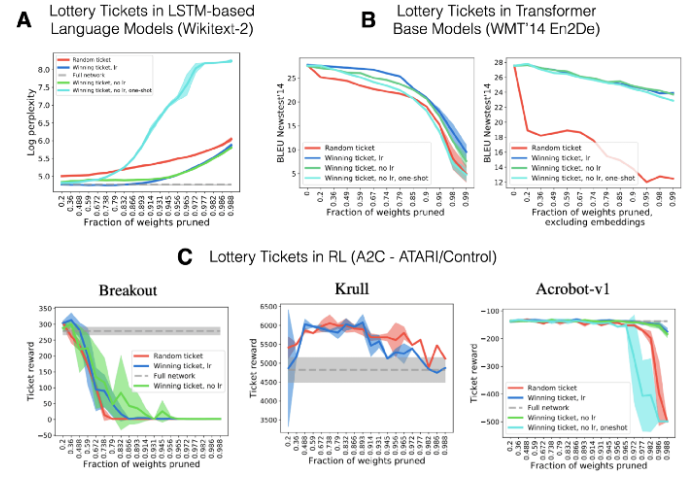 图 17:语言模型和强化学习领域的中奖网络。
图 17:语言模型和强化学习领域的中奖网络。
6
开放性的研究问题
-
能够找到中奖网络的高效初始化方案应该是怎样的?元学习是否可以在可计算的条件下找到这样的彩票网络?是否可以形式化定义能够利用中奖网络的优化算法?连通性和权值初始化的影响是否能够解耦?我们是否可以将找到中奖网络看做一种归纳偏置? -
使用一半训练数据预训练的权值进行初始化的网络,与使用完整的数据集训练的最终网络有泛化能力的差距(https://arxiv.org/abs/1910.08475)。换句话说,使用数据的子集进行预训练,比从随机初始化状态开始训练的网络性能更差。中奖彩票网络是否能解决这种热启动问题?沿着Morcos 等人在论文「One ticket to win them all: generalizing lottery ticket initializations across datasets and optimizers」中的思路,可以对该问题进行很好的扩展。 -
不同领域(视觉、语言、强化学习)和不同任务(分类、回归等)上的中奖网络有何不同?这些差异是损失平面的性质吗?我们能否直接从它们的掩模中提取出相应的规律?

登录查看更多
相关内容

专知会员服务
148+阅读 · 2019年12月28日



相关VIP内容
专知会员服务
148+阅读 · 2019年12月28日
相关资讯
相关论文